
 商标分类
商标分类  商标转让
商标转让 
一种音频数据处理方法、设备以及计算机可读存储介质与流程
 2021-01-28 13:01:05|
2021-01-28 13:01:05| 247|
247| 起点商标网
起点商标网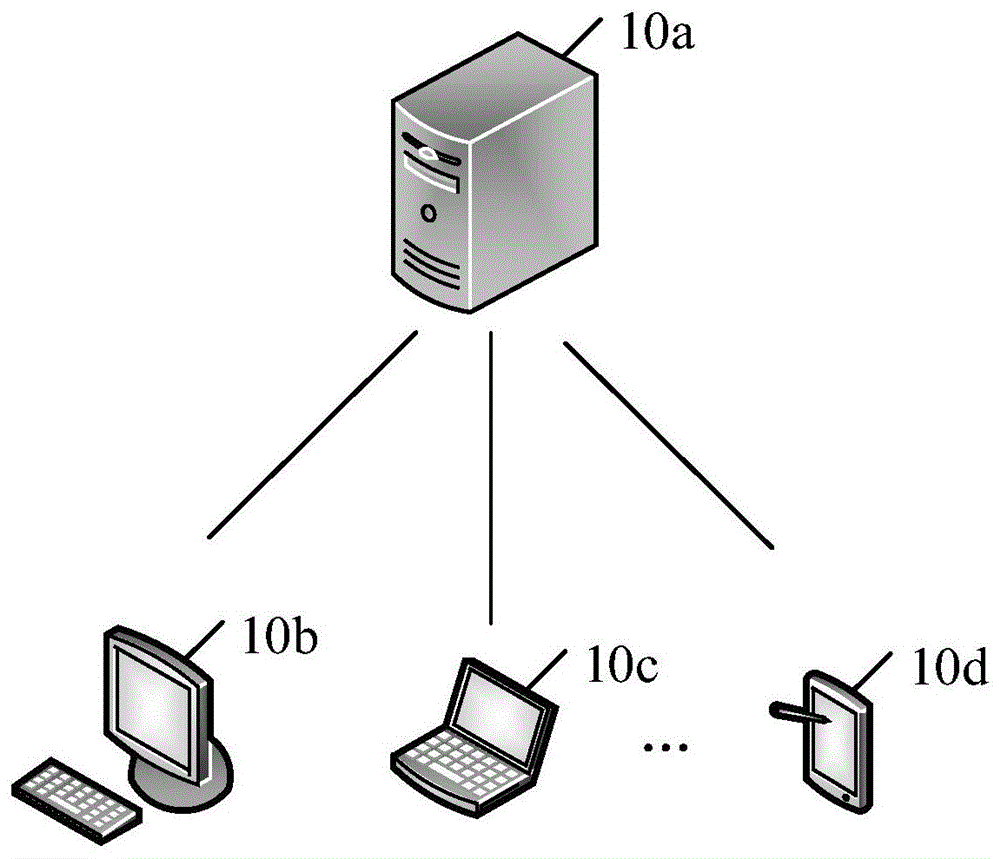
本申请涉及互联网技术领域,尤其涉及一种音频数据处理方法、设备以及计算机可读存储介质。
背景技术:
随着人工智能、机器感知以及语音技术的迅猛发展,语音分离技术在日常生活中得到广泛的应用,例如音视频会议系统、智能语音交互以及智能语音助手。
语音分离技术受启于“鸡尾酒会效应”,“鸡尾酒会效应”是人脑听觉具有的可以集中注意力在单个目标声音而忽略其他竞争声音的能力。现有的语音分离系统是基于监督学习构建的,尽管监督学习在单通道声音分离方面取得了很大进展,但是一旦单通道声音被噪声污染,系统性能会急剧下降,无法准确在嘈杂环境中识别目标语句或目标说话人,进而无法加强目标说话人的目标语句,减弱同一时间其他人的音量,因此分离出的语音中仍包含较多的干扰声音,即无法得到高准确率的重构声源音频。
技术实现要素:
本申请实施例提供一种音频数据处理方法、设备以及计算机可读存储介质,可以提高重构声源音频的准确率。
本申请实施例一方面提供一种音频数据处理方法,包括:
获取声源混合音频数据,基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;
将通用分离音频特征分别输入至第一注意力网络层以及第二注意力网络层;
在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;
在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;
根据至少一个分离优化音频特征,生成至少一个声源分别对应的重构声源音频。
本申请实施例一方面提供一种音频数据处理方法,包括:
从音频数据库中获取至少一个声源分别对应的目标样本音频,根据至少一个目标样本音频生成声源混合样本音频数据;
将声源混合样本音频数据输入音频分离初始模型;音频分离初始模型包括通用分离组件、第一注意力网络层以及第二注意力网络层;
基于通用分离组件对声源混合样本音频数据进行声源分离预处理,得到通用分离估计音频特征,将通用分离估计音频特征分别输入至第一注意力网络层以及第二注意力网络层;
在第一注意力网络层中,根据目标分离估计音频特征以及通用分离估计音频特征,生成至少一个声源分别对应的上下文目标估计音频特征,将上下文目标估计音频特征输入至第二注意力网络层;目标分离估计音频特征是通过对通用分离估计音频特征进行特征提取后所得到的特征;
在第二注意力网络层中,根据上下文目标估计音频特征以及通用分离估计音频特征,生成至少一个分离优化估计音频特征;至少一个分离优化估计音频特征用于重构至少一个声源分别对应的估计声源音频;
根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,对音频分离初始模型中的模型参数进行调整,生成音频分离模型,基于音频分离模型对声源混合音频数据进行声源音频分离处理。
本申请实施例一方面提供一种音频数据处理装置,包括:
第一生成模块,用于获取声源混合音频数据,基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;
第一输入模块,用于将通用分离音频特征分别输入至第一注意力网络层以及第二注意力网络层;
第二输入模块,用于在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;
第二生成模块,用于在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;
第三生成模块,用于根据至少一个分离优化音频特征,生成至少一个声源分别对应的重构声源音频。
其中,第一注意力网络层包括第一分离组件以及嵌入组件;
第二输入模块,包括:
第一处理单元,用于通过第一分离组件,对通用分离音频特征进行特征提取处理,得到目标分离音频特征,将目标分离音频特征输入至嵌入组件;
第二处理单元,用于通过嵌入组件,对目标分离音频特征进行特征映射处理,生成至少一个声源分别对应的上下文初始音频特征;
第一生成单元,用于根据上下文初始音频特征以及通用分离音频特征,生成至少一个声源分别对应的第一注意力分布参数;
第二生成单元,用于根据第一注意力分布参数以及上下文初始音频特征,生成上下文目标音频特征。
其中,第一注意力网络层包括第一注意力机制组件;
第一生成单元,包括:
第一生成子单元,用于对通用分离音频特征进行降维处理,得到期望分离音频特征;
第一输入子单元,用于将上下文初始音频特征以及期望分离音频特征输入至第一注意力机制组件;上下文初始音频特征包括上下文初始音频特征yj,至少一个声源包括声源sj,其中,j为正整数,且j小于或等于至少一个声源的声源总数量;
第二生成子单元,用于在第一注意力机制组件中,根据上下文初始音频特征yj以及期望分离音频特征,生成声源sj对应的第一注意力分布参数cj;
则第二生成单元具体用于根据第一注意力分布参数cj以及上下文初始音频特征yj,生成声源sj对应的上下文目标音频特征zj。
其中,第二注意力网络层包括第二分离组件kb以及第二分离组件kb+1,其中,b为正整数,且b小于第二注意力网络层中第二分离组件的总数量;
第二生成模块,包括:
第三处理单元,用于在第二注意力网络层的第二分离组件kb中,对输入特征进行隐藏特征提取处理,得到分离隐藏音频特征gb;若第二分离组件kb为第二注意力网络层中的首个第二分离组件,则输入特征为通用分离音频特征;若第二分离组件kb不为第二注意力网络层中的首个第二分离组件,则输入特征为第二分离组件kb的上一个第二分离组件所输出的分离过渡音频特征;
第三生成单元,用于根据上下文目标音频特征以及分离隐藏音频特征gb,在第二分离组件kb中输出分离过渡音频特征,将第二分离组件kb所输出的分离过渡音频特征作为第二分离组件kb+1的输入特征;
第四处理单元,用于对第二分离组件kb+1的输入特征进行隐藏特征提取处理,得到分离隐藏音频特征gb+1;
第四生成单元,用于若第二分离组件kb+1不为第二注意力网络层中的最后一个第二分离组件,则根据上下文目标音频特征以及分离隐藏音频特征gb+1,在第二分离组件kb+1中输出分离过渡音频特征,将第二分离组件kb+1所输出的分离过渡音频特征作为下一个第二分离组件的输入特征;
第四生成单元,还用于若第二分离组件kb+1为第二注意力网络层中的最后一个第二分离组件,则根据上下文目标音频特征以及分离隐藏音频特征gb+1,生成分离优化音频特征。
其中,第二分离组件kb包括第二注意力机制组件;
第三生成单元,包括:
第二输入子单元,用于将上下文目标音频特征以及分离隐藏音频特征gb,输入至第二注意力机制组件;上下文目标音频特征包括上下文目标音频特征zj,分离隐藏音频特征gb包括分离隐藏音频特征gjb,声源包括声源sj,其中,j为正整数,且j小于或等于至少一个声源的声源总数量;
第三生成子单元,用于在第二注意力机制组件中,根据上下文目标音频特征zj以及分离隐藏音频特征gjb,生成声源sj对应的第二注意力分布参数djb;
第四生成子单元,用于根据第二注意力分布参数djb、上下文目标音频特征zj以及分离隐藏音频特征gjb,生成声源sj对应的分离过渡音频特征xjb。
其中,第一生成模块,包括:
第五生成单元,用于获取声源混合音频数据,对声源混合音频数据进行编码处理,生成混合时间序列,将混合时间序列输入至通用分离组件;
第五处理单元,用于在通用分离组件中,对混合时间序列进行分割处理,得到n个长度为l的时间块;其中,n为正整数,l为正数;
第六生成单元,用于组合n个长度为l的时间块,得到初始混合音频特征,对初始混合音频特征进行声源分离预处理,得到通用分离音频特征。
其中,所述至少一个声源包括目标声源;第二注意力网络层包括拼接组件;
第三生成模块,包括:
第六处理单元,用于根据目标声源,从至少一个分离优化音频特征中确定待处理分离优化音频特征;
第六处理单元,还用于将待处理分离优化音频特征输入至拼接组件;
转换特征单元,用于在拼接组件中,基于块长度以及块数量,将待处理分离优化音频特征转换为分离时间序列;
第七生成单元,用于对混合时间序列以及分离时间序列进行序列融合处理,生成目标时间序列;
第七生成单元,还用于对目标时间序列进行解码处理,得到目标声源对应的重构声源音频。
本申请实施例一方面提供一种音频数据处理装置,包括:
第一生成模块,用于从音频数据库中获取至少一个声源分别对应的目标样本音频,根据至少一个目标样本音频生成声源混合样本音频数据;
第一输入模块,用于将声源混合样本音频数据输入音频分离初始模型;音频分离初始模型包括通用分离组件、第一注意力网络层以及第二注意力网络层;
第二输入模块,用于基于通用分离组件对声源混合样本音频数据进行声源分离预处理,得到通用分离估计音频特征,将通用分离估计音频特征分别输入至第一注意力网络层以及第二注意力网络层;
第三输入模块,用于在第一注意力网络层中,根据目标分离估计音频特征以及通用分离估计音频特征,生成至少一个声源分别对应的上下文目标估计音频特征,将上下文目标估计音频特征输入至第二注意力网络层;目标分离估计音频特征是通过对通用分离估计音频特征进行特征提取后所得到的特征;
第二生成模块,用于在第二注意力网络层中,根据上下文目标估计音频特征以及通用分离估计音频特征,生成至少一个分离优化估计音频特征;至少一个分离优化估计音频特征用于重构至少一个声源分别对应的估计声源音频;
第三生成模块,用于根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,对音频分离初始模型中的模型参数进行调整,生成音频分离模型,基于音频分离模型对声源混合音频数据进行声源音频分离处理。
其中,第三生成模块,包括:
第一确定单元,用于根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的模型损失值;
第二确定单元,用于根据模型损失值对音频分离初始模型中的模型参数进行调整,当调整后的音频分离初始模型满足模型收敛条件时,将调整后的音频分离初始模型确定为音频分离模型。
其中,上下文样本音频特征包括第一上下文样本音频特征以及第二上下文样本音频特征;第一上下文样本音频特征是指至少一个目标样本音频分别对应的特征,第二上下文样本音频特征是指音频数据库中除了至少一个目标样本音频之外的样本音频对应的特征;
第一确定单元,包括:
第一确定子单元,用于根据第一上下文样本音频特征、上下文目标估计音频特征以及上下文样本音频特征,确定音频分离初始模型的特征全局损失值;
第二确定子单元,用于根据第一上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的特征双重损失值;
第三确定子单元,用于根据上下文样本音频特征以及上下文目标估计音频特征,确定音频分离初始模型的特征归一化损失值;
第四确定子单元,用于根据第一上下文样本音频特征以及第二上下文样本音频特征,确定音频分离初始模型的特征正则化损失值;
第五确定子单元,用于根据特征全局损失值、特征双重损失值、特征归一化损失值以及特征正则化损失值,确定模型损失值。
其中,第一确定子单元,具体用于确定第一上下文样本音频特征以及上下文目标估计音频特征之间的第一互信息值;
第一确定子单元,具体用于确定上下文样本音频特征以及上下文目标估计音频特征之间的第二互信息值;
第一确定子单元,具体用于根据第一互信息值以及第二互信息值,确定音频分离初始模型的特征全局损失值。
其中,第二确定子单元,具体用于统计音频分离初始模型的迭代次数,若迭代次数小于或等于迭代次数阈值,则获取至少一个目标样本音频以及至少一个估计声源音频之间的第一分离损失值;
第二确定子单元,具体用于根据第一分离损失值,确定第一上下文样本音频特征以及上下文目标估计音频特征之间的第一上下文损失值;
第二确定子单元,具体用于根据第一分离损失值以及第一上下文损失值确定音频分离初始模型的特征双重损失值;
第二确定子单元,具体用于若迭代次数大于迭代次数阈值,则获取第一上下文样本音频特征以及上下文目标估计音频特征之间的第二上下文损失值;
第二确定子单元,具体用于根据第二上下文损失值,确定至少一个目标样本音频以及至少一个估计声源音频之间的第二分离损失值;
第二确定子单元,具体用于根据第二分离损失值以及第二上下文损失值确定音频分离初始模型的特征双重损失值。
其中,至少一个目标样本音频包括目标样本音频hi以及目标样本音频hi+1,其中,i为正整数,且i小于至少一个目标样本音频的总数量;至少一个估计声源音频包括估计声源音频fj以及估计声源音频fj+1,其中,j为正整数,且j小于至少一个估计声源音频的总数量;
第二确定子单元,具体用于获取目标样本音频hi以及估计声源音频fj之间的第一相似度d(i,j),获取目标样本音频hi+1以及声源音频fj+1之间的第一相似度d(i+1,j+1);
第二确定子单元,具体用于根据第一相似度d(i,j)以及第一相似度d(i+1,j+1),确定至少一个目标样本音频以及至少一个估计声源音频之间的第一初始损失值;
第二确定子单元,具体用于获取目标样本音频hi以及估计声源音频fj+1之间的第二相似度d(i,j+1),获取目标样本音频hi+1以及声源音频fj之间的第二相似度d(i+1,j);
第二确定子单元,具体用于根据第二相似度d(i,j+1)以及第二相似度d(i+1,j),确定至少一个目标样本音频以及至少一个估计声源音频之间的第二初始损失值;
第二确定子单元,具体用于从第一初始损失值以及第二初始损失值中确定最小初始损失值,将最小初始损失值确定为第一分离损失值。
本申请一方面提供了一种计算机设备,包括:处理器、存储器、网络接口;
上述处理器与上述存储器、上述网络接口相连,其中,上述网络接口用于提供数据通信功能,上述存储器用于存储计算机程序,上述处理器用于调用上述计算机程序,以执行本申请实施例中的方法。
本申请实施例一方面提供了一种计算机可读存储介质,上述计算机可读存储介质存储有计算机程序,上述计算机程序包括程序指令,上述程序指令被处理器执行时,以执行本申请实施例中的方法。
本申请实施例一方面提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中;计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行本申请实施例中的方法。
本申请实施例在获取声源混合音频数据之后,首先基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;然后将通用分离音频特征分别输入至第一注意力网络层以及即第二注意力网络层,在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,然后将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;至少一个分离优化音频特征用于重构至少一个声源分别对应的声源音频。上述可知,本申请实施例提出两个独立的网络层(即第一注意力网络层以及第二注意力网络层),其中,第一注意力网络层通过自下而上的通用分离音频特征,学习声源混合音频数据中目标说话人的音频特征,得到上下文目标音频特征;第二注意力网络层除了通过自下而上的通用分离音频特征,还通过融合自上而下的上下文目标音频特征,即可生成高准确率的分离优化音频特征,进而提高重构声源音频的准确率。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1a是本申请实施例提供的一种系统架构示意图;
图1b是本申请实施例提供的一种音频数据处理的场景示意图;
图2是本申请实施例提供的一种音频数据处理方法的流程示意图;
图3a是本申请实施例提供的一种音频分离模型的结构示意图;
图3b是本申请实施例提供的一种音频数据处理的场景示意图;
图3c是本申请实施例提供的一种音频数据处理的场景示意图;
图3d是本申请实施例提供的一种分离单元的结构示意图;
图3e是本申请实施例提供的一种音频数据处理的场景示意图;
图4是本申请实施例提供的一种音频数据处理方法的流程示意图;
图5是本申请实施例提供的一种分离单元的结构示意图;
图6是本申请实施例提供的一种音频数据处理装置的结构示意图;
图7是本申请实施例提供的一种音频数据处理装置的结构示意图;
图8是本申请实施例提供的一种计算机设备的结构示意图;
图9是本申请实施例提供的一种计算机设备的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
为了便于理解,首先对部分名词进行以下简单解释:
人工智能(artificialintelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
语音技术(speechtechnology)的关键技术有自动语音识别技术(asr)和语音合成技术(tts)以及声纹识别技术。让计算机能听、能看、能说、能感觉,是未来人机交互的发展方向,其中语音成为未来最被看好的人机交互方式之一。
自然语言处理(naturelanguageprocessing,nlp)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系。自然语言处理技术通常包括文本处理、语义理解、机器翻译、机器人问答、知识图谱等技术。
本申请实施例提供的方案涉及人工智能的语音技术、自然语言处理以及深度学习等技术,具体过程通过如下实施例进行说明。
请参见图1a,图1a是本申请实施例提供的一种系统架构示意图。如图1a所示,该系统可以包括服务器10a以及用户终端集群,用户终端集群可以包括:用户终端10b、用户终端10c、...、用户终端10d,其中,用户终端集群之间可以存在通信连接,例如用户终端10b与用户终端10c之间存在通信连接,用户终端10b与用户终端10d之间存在通信连接。同时,用户终端集群中的任一用户终端可以与服务器10a存在通信连接,例如用户终端10b与服务器10a之间存在通信连接,用户终端10c与服务器10a之间存在通信连接。其中,上述的通信连接不限定连接方式,可以通过有线通信方式进行直接或间接地连接,也可以通过无线通信方式进行直接或间接地连接,还可以通过其他方式,本申请在此不做限制。
服务器10a通过通信连接功能为用户终端集群提供服务,当用户终端(可以是用户终端10b、用户终端10c或用户终端10d)获取到声源混合音频数据,并需要对声源混合音频数据进行处理时,例如对声源混合音频数据进行多声源音频分离,或者提取声源混合音频数据中目标说话人的目标音频数据,用户终端可以将声源混合音频数据发送至服务器10a,可以理解的是,该声源混合音频数据可以是包含多个声源混合的音频数据,也可以是只包括目标说话人的音频数据,此时,该音频数据携带噪声,使得人们无法清楚地听见目标说话人的目标音频。请一并参见图1b,图1b是本申请实施例提供的一种音频数据处理的场景示意图。如图1b所示,主播a利用用户终端10b在直播职业篮球赛事讲解,直播过程中,当其说到“职业篮球比赛汇总,进一球最高能得几分”时,一个小男孩在主播a的身边,大声说“妈妈,我想和哥哥出去玩”,然后,小男孩妈妈回复“哥哥在忙了,你别吵”。明显地,用户终端10b会录制到上述3个人的对话,即录制到一段声源混合音频数据,若用户终端10b或服务器10a不对声源混合音频数据进行恰当的处理,直接将声源混合音频数据发送给主播a的观众,那么观众通过用户终端10c听到的就是一段声源混合音频数据,在噪声过大的情况下,观众极有听不清主播a的讲解,因此需要对声源混合音频数据进行处理,生成一段清晰的音频数据,该清晰的音频数据只包括主播a的讲解,或可以包括主播a的讲解、小男孩的声音以及小男孩妈妈的声音,但小男孩的声音以及小男孩妈妈的声音不会影响到主播a的讲解,此处不限定,可以根据实际应用确定。
用户终端10b先将上述声源混合音频数据发送至服务器10a。服务器10a接收到用户终端10b发送的声源混合音频数据后,基于提前训练好的音频分离模型对声源混合音频数据进行特征提取,得到目标说话人(即主播a)的目标音频数据,具体过程如下所述:服务器10a先对声源混合音频数据进行编码,得到声源混合音频数据对应的混合高维表征;然后将高维表征输入音频分离网络,音频分离网络包括通用分离组件、第一注意力网络层以及第二注意力网络层;在通用分离组件中,先对高维表征进行分割处理,得到一个3维张量,然后对3维张量进行音频特征提取处理,得到通用分离音频特征;服务器10a将通用分离音频特征输入至第一注意力网络层以及第二注意力网络层,第一注意力网络层通过自下而上的通用分离音频特征,学习声源混合音频数据中目标说话人的音频特征,得到上下文目标音频特征;第二注意力网络层除了通过自下而上的通用分离音频特征,从声源混合音频数据中分离出目标说话人的目标音频数据,还通过自上而下的上下文目标音频特征,不断优化提取到的针对目标说话人的目标音频数据,生成高准确率的分离优化音频特征,然后对分离优化音频特征进行特征重叠相加(overlap-add)处理,转换为一个优化高维表征,将上述的混合高维表征以及优化高维表征进行表征融合,得到目标高维表征,最后对目标高维表征进行解码处理,得到重构声源音频,即针对目标说话人的目标音频数据。如图1b所示,在经过上述的处理后,观众可以清晰的听见主播a的讲解。
后续,服务器10a将生成的目标音频数据返回至用户终端(可以包括图1b中的用户终端10b以及用户终端10c),用户终端接收到服务器10a发送的目标音频数据后,可以在其对应的播放器上清晰地播放目标说话人的目标语音。服务器10a还可以将声源混合音频数据、上下文目标音频特征、分离优化音频特征以及目标音频数据关联存储至数据库中,当再次获取到包含该目标说话人的待处理声源混合音频数据时,服务器10a可以根据上下文目标音频特征,通过线下方式,直接优化待处理声源混合音频数据中的分离音频数据。上述数据库可视为电子化的文件柜——存储电子文件(本申请可以指声源混合音频数据、上下文目标音频特征、分离优化音频特征以及目标音频数据)的处所,服务器10a可以对文件进行新增、查询、更新、删除等操作。所谓“数据库”是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。
可选的,若用户终端的本地存储了训练好的音频分离模型,则用户终端可以在本地上对声源混合音频数据做多声源分离任务,得到需要的音频数据。其中,由于训练音频分离初始模型涉及到大量的离线计算,因此用户终端本地的音频分离模型可以是由服务器10a训练完成后发送至用户终端的。
可以理解的是,本申请实施例所提供的方法可以由计算机设备执行,计算机设备包括但不限于终端或服务器,本申请实施例中的服务器10a可以为计算机设备,用户终端集群中的用户终端也可以为计算机设备,此处不限定。上述服务器可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn、以及大数据和人工智能平台等基础云计算服务的云服务器。上述终端可以是智能手机、平板电脑、笔记本电脑、台式计算机、智能音箱、智能手表等,但并不局限于此。终端以及服务器可以通过有线或无线通信方式进行直接或间接地连接,本申请在此不做限制。
其中,图1a中的服务器10a、用户终端10b、用户终端10c以及用户终端10d可以包括手机、平板电脑、笔记本电脑、掌上电脑、智能音响、移动互联网设备(mid,mobileinternetdevice)、pos(pointofsales,销售点)机、可穿戴设备(例如智能手表、智能手环等)等。
进一步地,请参见图2,图2是本申请实施例提供的一种音频数据处理方法的流程示意图,该方法由图1a中所述的计算机设备执行,即可以为图1a中的服务器10a,也可以为图1a中的用户终端集群(也包括用户终端10b、用户终端10c以及用户终端10d)。如图2所示,该音频数据处理过程包括如下步骤:
步骤s101,获取声源混合音频数据,基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征。
具体的,获取声源混合音频数据,对声源混合音频数据进行编码处理,生成混合时间序列,将混合时间序列输入至通用分离组件;在通用分离组件中,对混合时间序列进行分割处理,得到n个长度为l的时间块;其中,n为正整数,l为正数;组合n个长度为l的时间块,得到初始混合音频特征,对初始混合音频特征进行声源分离预处理,得到通用分离音频特征。
可以理解的是,获取声源混合音频数据的方式可以是在线实时方式,也可以是预先离线存储方式,还可以是将多种干净的音频数据混合生成的方式,此处不限定。
获取到声源混合音频数据后,将其输入至已训练好的音频分离模型,请一并参见图3a,图3a是本申请实施例提供的一种音频分离模型的结构示意图。由图3a可知,音频分离模型可以包括编码器、分离网络以及解码器。声源混合音频数据30a首先输入至编码器,编码器对包含至少一个(图3a示例2个)声源的混合波形信号(即声源混合音频数据30a)进行转化,得到混合时间序列
步骤s102,将通用分离音频特征分别输入至第一注意力网络层以及第二注意力网络层。
具体的,本申请实施例针对多声源分离任务提出了基于注意力机制的自监督方法,该方法设置了同时学习说话人知识和语音信号刺激两个独立空间,即第一注意力网络层以及第二注意力网络层,在这两个空间之间,信息通过交叉注意力机制和双重注意力机制相互投射,从而模仿了人类的鸡尾酒会效应中的自下而上和自上而下的过程。
请一并参见图3c,图3c是本申请实施例提供的一种音频数据处理的场景示意图。本申请提出多任务空间的自监督和基于注意力的特征融合,通过交叉注意力机制(crossattention)和双重注意力机制(dualattention),在多个空间之间进行自下而上和自上而下的信息转换和融合。为了便于叙述以及理解,本申请实施例使用8个分离单元,其中用于提取音频特征的分离单元有b=4个,被设置于通用分离组件中,用于学习说话人上下文知识的分离单元有b1=2个,被设置于第一注意力网络层,用于分离音频特征的分离单元有b2=2个,被设置于第二注意力网络层。其中,通用分离组件中第一个分离单元的输入为步骤s101中初始混合音频特征30c,然后第一分离单元的输出作为第二个分离单元的输入,…,直至通用分离组件中第四个分离单元输出通用分离音频特征x(b+1),如图3c所示,将通用分离音频特征x(b+1)分别输入至第一注意力网络层以及第二注意力网络层。
下面示例叙述分离单元,在本申请实施例中采用了双路径循环神经网络(dual-pathrecurrentneuralnetworks,dprnn),此时可以将分离单元看作分离块,在通用分离组件中,由4个dprnn块堆叠构成。请一并参见图3d,图3d是本申请实施例提供的一种分离单元的结构示意图。如图3d所示,每个dprnn块由递归连接的两个rnn组成,每个rnn均包括归一化层、全连接层以及双向循环神经网络层。在每个dprnn块的内部并行地应用“块内”双向rnn,以处理块内的局部信息;而在dprnn块与dprnn块之间,则应用“块间”rnn来捕捉全局依赖信息。多个dprnn块堆叠起来构成深度网络(即分离单元)。由上述可知,每个dprnn块的输入是一个3维张量x∈rd×n×l(包括上述初始混合音频特征30c)。也可以理解成,每个dprnn块由分别在l和n两种不同维度上递归连接的两个rnn组成,在每个dprnn块的内部并行地应用在“块内”,即l维度上的双向rnn,以处理块内的局部信息;而在块与块之间,即在n维度上,则应用“块间”rnn来捕捉全局依赖信息。
步骤s103,在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征。
具体的,第一注意力网络层包括第一分离组件以及嵌入组件;通过第一分离组件,对通用分离音频特征进行特征提取处理,得到目标分离音频特征,将目标分离音频特征输入至嵌入组件;通过嵌入组件,对目标分离音频特征进行特征映射处理,生成至少一个声源分别对应的上下文初始音频特征;根据上下文初始音频特征以及通用分离音频特征,生成至少一个声源分别对应的第一注意力分布参数;根据第一注意力分布参数以及上下文初始音频特征,生成上下文目标音频特征。
第一注意力网络层包括第一注意力机制组件;其中,根据上下文初始音频特征以及通用分离音频特征,生成至少一个声源分别对应的第一注意力分布参数,包括:对通用分离音频特征进行降维处理,得到期望分离音频特征;将上下文初始音频特征以及期望分离音频特征输入至第一注意力机制组件;上下文初始音频特征包括上下文初始音频特征yj,至少一个声源包括声源sj,其中,j为正整数,且j小于或等于至少一个声源的声源总数量;在第一注意力机制组件中,根据上下文初始音频特征yj以及期望分离音频特征,生成声源sj对应的第一注意力分布参数cj;则根据第一注意力分布参数以及上下文初始音频特征,生成上下文目标音频特征,包括:根据第一注意力分布参数cj以及上下文初始音频特征yj,生成声源sj对应的上下文目标音频特征zj。
请再参见图3c,第一注意力网络层包括2个分离单元(即第一分离组件),例如图3d中所述的2个dprnn块,该分离单元与通用分离组件中的4个分离单元的功能无差别,用来提取音频特征,得到目标分离音频特征。将目标分离音频特征输入至嵌入组件,通过嵌入组件,对目标分离音频特征进行特征映射处理,生成至少一个声源分别对应的上下文初始音频特征yj∈rd×n,j=1,2,...,a,a表示至少一个声源的总数量,根据步骤s101以及图3a可知,本申请实施例示例2种声源,故生成2个上下文初始音频特征,如图3c中所示的上下文初始音频特征y1以及上下文初始音频特征y2。
将上下文初始音频特征y1、上下文初始音频特征y2以及通用分离音频特征x(b+1)输入至第一注意力机制组件,首先对通用分离音频特征x(b+1)∈rd×n×l在l维度上求平均,得到期望分离音频特征
其中,query(·),key(·)和下文提及的value(·)表示第一注意力网络层中的投影函数,投影函数将相应的输入向量(如
为了简化符号,本申请实施例省略了所有时间轴索引,最后,根据该注意力分布attn_cj对上下文初始音频特征yj进行加权求和,得到上下文目标音频特征zj∈rd,如公式(2)所示。
zj=σσattn_cj·value(yj)(2)
将上下文目标音频特征z1以及上下文目标音频特征z2输入至第二注意力网络层中的第二注意力机制组件中。
步骤s104,在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征。
具体的,第二注意力网络层包括第二分离组件kb以及第二分离组件kb+1,其中,b为正整数,且b小于第二注意力网络层中第二分离组件的总数量;在第二注意力网络层的第二分离组件kb中,对通用分离音频特征进行隐藏特征提取处理,得到分离隐藏音频特征gb,根据上下文目标音频特征以及分离隐藏音频特征gb,生成分离过渡音频特征,将分离过渡音频特征输入至第二分离组件kb+1;在第二分离组件kb+1中,对分离过渡音频特征进行隐藏特征提取处理,得到分离隐藏音频特征gb+1;根据上下文目标音频特征以及分离隐藏音频特征gb+1,生成分离优化音频特征。
第二分离组件kb包括第二注意力机制组件;其中,根据上下文目标音频特征以及分离隐藏音频特征gb,生成分离过渡音频特征,包括:将上下文目标音频特征以及分离隐藏音频特征gb,输入至第二注意力机制组件;上下文目标音频特征包括上下文目标音频特征zj,分离隐藏音频特征gb包括分离隐藏音频特征gjb,声源包括声源sj,其中,j为正整数,且j小于或等于至少一个声源的声源总数量;在第二注意力机制组件中,根据上下文目标音频特征zj以及分离隐藏音频特征gjb,生成声源sj对应的第二注意力分布参数djb;根据第二注意力分布参数djb、上下文目标音频特征zj以及分离隐藏音频特征gjb,生成声源sj对应的分离过渡音频特征xjb。
第二注意力网络层用于分离混合信号并重建源信号的深度语音表征,该层中最后一个分离单元的输出将传递到图3a中的解码器,以重建源信号(即重构声源音频)。自上而下的引导是从第一注意力网络层中提出的,通过双重注意力机制将上下文目标音频特征zj投射到第二注意力网络层上。明显地,双重注意力机制同时应用于第二注意力网络层自下而上的分离隐藏音频特征gb(与在标准的自注意层中的处理相同),以及自上而下的上下文目标音频特征zj。第二注意力机制组件使用听觉记忆中的特定对象表示来模仿神经过程,以增强自上而下的注意过程中的感知精度。
由步骤s102可知,第二注意力网络层包括2个分离单元,即2个第二分离组件,为了便于叙述,将2个第二分离组件分别称作分离组件k5以及分离组件k6(因为连接在通用分离组件中的4个分离单元后)。分离组件k5的输入为通用分离音频特征,对通用分离音频特征进行隐藏特征提取处理,得到分离隐藏音频特征g5,可以理解的是,由于分离组件k5生成的分离隐藏音频特征gj5均是根据通用分离音频特征所得,所以分离隐藏音频特征g15等于分离隐藏音频特征g25。将上下文目标音频特征zj以及分离隐藏音频特征gj5(j=1,2)输入至第二注意力机制组件(需要理解的是,此处的第二注意力机制组件是分离组件k5的内部组件),根据公式(3)确定第二注意力分布参数dj5(即公式3中的双重注意力分布attn_dj)。
attn_dj=softmax(query(g(b))t·key(r(zj)⊙g(b)+h(zj)))(3)
最后,根据双重注意力分布attn_dj对向量key(r(zj)⊙g(b)+h(zj))进行加权求和,得到分离过渡音频特征
上述过程是分离组件k5生成分离过渡音频特征
请再参见图3c,可以理解的是,图3c中的g1b、g2b可以表示上面叙述的分离隐藏音频特征gj5以及分离隐藏音频特征gj6(j=1,2),若第一注意力网络层包括3个第二分离组件,则图3c中的g1b、g2b可以表示分离隐藏音频特征gj5、分离隐藏音频特征gj6以及分离隐藏音频特征gj7(j=1,2),若第一注意力网络层包括其他数量的第二分离组件,亦按照上述理解。同理,图3c中的
步骤s105,根据至少一个分离优化音频特征,生成至少一个声源分别对应的重构声源音频。
具体的,至少一个声源包括目标声源;第二注意力网络层包括拼接组件;根据目标声源,从至少一个分离优化音频特征中确定待处理分离优化音频特征;将待处理分离优化音频特征输入至拼接组件;在拼接组件中,基于块长度以及块数量,将待处理分离优化音频特征转换为分离时间序列;对混合时间序列以及分离时间序列进行序列融合处理,生成目标时间序列;对目标时间序列进行解码处理,得到目标声源对应的重构声源音频。
第二注意力网络层的分离组件k6的输出为3维张量,其数量等于2,表示分离出2个干净的音频数据,若存在目标声源,则根据目标声源或是目标声源对应的上下文样本音频特征,从两个分离优化音频特征中确定待处理分离优化音频特征,请一并参见图3e,图3e是本申请实施例提供的一种音频数据处理的场景示意图。如图3e所示,对待处理分离优化音频特征进行特征重叠相加处理,得到分离时间序列,该分离时间序列的大小与图3b中的混合时间序列的大小一致,均为rd×i。请再参见图3a,对混合时间序列以及分离时间序列进行序列融合处理,生成目标时间序列;对目标时间序列进行解码处理,得到目标声源对应的重构声源音频30b。
可选的,若不存在目标声源,则将两个分离优化音频特征均确定为待处理分离优化音频特征,后续过程与上述一致,最终生成两个重构声源音频。
步骤s101-步骤s105的过程可以应用到音视频会议系统、智能语音交互、智能语音助手、在线语音识别系统、音乐分离、音乐推荐、车载语音交互系统等多个项目和产品应用中,可在复杂的具有高度可变性的真实声学环境中显著地改善人类听觉的可懂度以及机器自动语音识别系统的准确率,从而提升用户体验。
综上所述,本申请实施例仅通过软注意力机制来促成两个网络层(两个空间)的通信。因此,这两个空间(说话人知识空间和语音信号刺激空间)之间的交互仅通过概率分布来调节。将上下文目标音频特征zj作为引导向量,锚定回原始的知识空间中,将语音特征投射到说话人嵌入表征上,可以有效的自上而下引导语音信号刺激空间,这是一种正则化形式,它将上下文目标音频特征zj限制为唯一的说话人知识空间中的引导向量,从而允许下游应用自我监督。
本申请实施例的另一个优点在于它在不同应用模式中可以灵活部署,通常,“离线”模式收集目标说话人的注册语音,因此与“在线”模式相比,说话人的嵌入表征可以预先离线存储。本申请实施例可以使用可变长度的说话人嵌入表征序列(例如,图3c中的上下文初始音频特征y1和上下文初始音频特征y2可以和在线观察序列的长度不一致),其集中在最关键的部分,而较少关注序列里面无关的、噪音大的、或冗余的片段。通过在线推断得到的说话人知识(模拟短期记忆),或通过离线积累和预先计算得到的说话人知识(模拟长期持久的记忆和经验),本申请提出的自下而上的模型均可以通过查询提取出其中最相关的信息。然后,自上而下的查询将集成检索到的信息,通过语音刺激空间(即第二注意力网络层)中的dprnn块堆栈迭代地计算语音表征。以上基于注意力机制的操作均是直接从数据中推断出来的,无需进行任何强监督的操作。
本申请实施例在获取声源混合音频数据之后,首先基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;然后将通用分离音频特征分别输入至第一注意力网络层以及即第二注意力网络层,在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,然后将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;至少一个分离优化音频特征用于重构至少一个声源分别对应的声源音频。上述可知,本申请实施例提出两个独立的网络层(即第一注意力网络层以及第二注意力网络层),其中,第一注意力网络层通过自下而上的通用分离音频特征,学习声源混合音频数据中目标说话人的音频特征,得到上下文目标音频特征;第二注意力网络层除了通过自下而上的通用分离音频特征,还通过融合自上而下的上下文目标音频特征,即可生成高准确率的分离优化音频特征,进而提高重构声源音频的准确率。
进一步地,请参见图4,图4是本申请实施例提供的一种音频数据处理方法的流程示意图。如图4所示,该音频数据处理过程包括如下步骤:
步骤s201,从音频数据库中获取至少一个声源分别对应的目标样本音频,根据至少一个目标样本音频生成声源混合样本音频数据。
具体的,本申请实施例提出一种网络框架,该框架通过执行一种“声音掩膜模型”(maskedaudiomodel,mam)来进行自监督训练,该训练通过将不同上下文(context)的声音信号随机混合来互相形成掩膜。上述的上下文可以有不同的定义,例如:1)不同的说话人对应的声纹的上下文;2)不同乐器对应的上下文;3)不同声学场景或声学事件对应的上下文,例如海边、火车上、烟火、狗吠等。
本申请实施例提出的mam本质上是在模拟现实世界中的“鸡尾酒会问题”。为了尽量模拟现实世界中的多样性,对于每个训练轮回(epoch),随机混频器(randommixer)都会从上下文训练语料库(即音频数据库)中随机抽取q种上下文的音频样本,其中一种上下文的样本作为正样本,而用剩余的(q-1)种上下文的样本作为负样本。从而,在每个批训练中,都有一个s={..,[sj1+,sj1-,sj2-,...}的集合,其中,sj1+表示正样本,包含来自同一类声源的"batch_size"的正样本,其余表示(q-1)种负样本,来自随机干扰声源的(q-1)种"batch_size"的随机负样本。在给定的信干比(signal-to-interferenceratio,sir)条件下,例如,从0db到5db随机采样,在随机起始位置处将正源样本与负源样本混合,生成声源混合样本音频数据。
步骤s202,将声源混合样本音频数据输入音频分离初始模型;音频分离初始模型包括通用分离组件、第一注意力网络层以及第二注意力网络层。
具体的,本申请实施例提供的自监督训练框架(即音频分离初始模型)在大规模的公开数据集librispeech上进行了评估。librispeech是由2484个说话人组成的982.1小时语料库。在本申请实施例中,将语料库分为(1)训练集,包括来自2411个说话人的12055句话语(划分为每人5句15秒的语音),(2)验证集,包括来自相同2411个说话人的另外7233话语(划分为每人收录3句15秒的语音),以及(3)测试集,包含来自其余73个说话人的4380语音(划分为每人60句4秒的语音)。同时,实验中也使用了另一个基准数据集wsj0-2mix,用于与最新的语音分离系统进行比较。wsj0-2mix包括了由来自101个说话人的20000句话语组成的30小时训练集,由来自相同的101个说话人的5000句话语组成的10小时验证集,以及由来自不同的18个说话人的3000句话语组成的5小时测试数据。
为了进行公平比较,图3a中编码器和解码器的结构以及音频分离初始模型的超参数设置都是从dprnn块的设置中继承而来的,并未针对本申请建议的模型进行微调(请注意,通过微调可以预期进一步的性能改进)。本申请实施例使用了8个dprnn单元,其中用于特征提取的dprnn单元有b=4个,用于说话人上下文知识空间(即第一注意力网络层)的单元有b1=2个,用于信号刺激空间(即第二注意力网络层)的单元有b2=2个,其中,b与b1是连续连接的,且b与b2是连续连接的。
本申请实施例把深度表征的维度,信号段的大小和减少后的信号段分别设置为d=128,l=128,q=16,将两个加权因子分别设置为γ=3,λ=10,其中γ是正则化损失中的加权因子,λ是欧几里得损失中的加权因子,具体参见下述的公式(7)和公式(9),全局学习率ε设置为0.05,学习率μ设置为初始值0.001,并在每两个训练epoch衰减0.96,优化使用adam算法。在每个训练epoch中,通过使用与随机开始位置处的同一训练集不同的随机言语掩盖训练集中的每个干净话语,在线生成持续4秒的混合信号,混合信噪比是0至5db。如果连续10个训练epoch中都没有出现更低的验证损失,则确认训练已经收敛。而在测试中,会预先随机地把测试集中的样本以0至5db的信噪比混合。
在图2步骤s102对应的实施例中,是以双路径循环神经网络作为分离单元示例,在本步骤中,以一种新型的全局关注和局部递归(globally-attentiveandlocally-recurrent,galr)网络为例叙述,请一并参见图5,图5是本申请实施例提供的一种分离单元的结构示意图。如图5所示,galr块可以包括组归一化层、线性层、双向长短期记忆网络层、归一化层以及注意力层,注意力层可以包括多头自注意力层、正则化层以及归一化层。其中,组归一化层为groupnorm组成,归一化层由layernorm组成,正则化层由dropout组成。同图3d中dprnn块一样,每个galr块的输出均为一个3维张量x∈rd×n×l,与其输入的张量形状相同。依此,经过每个galr块时,都经过局部到全局再到局部(在时间轴上,从细颗粒到粗颗粒度,再到细颗粒度)的特征传递。多个galr块堆叠起来构成深度网络,galr块堆叠在一起以完成所有空间(包括通用分离组件、第一注意力网络层以及第二注意力网络层)中的特征提取任务。
步骤s203,基于通用分离组件对声源混合样本音频数据进行声源分离预处理,得到通用分离估计音频特征,将通用分离估计音频特征分别输入至第一注意力网络层以及第二注意力网络层。
步骤s204,在第一注意力网络层中,根据目标分离估计音频特征以及通用分离估计音频特征,生成至少一个声源分别对应的上下文目标估计音频特征,将上下文目标估计音频特征输入至第二注意力网络层;目标分离估计音频特征是通过对通用分离估计音频特征进行特征提取后所得到的特征。
步骤s205,在第二注意力网络层中,根据上下文目标估计音频特征以及通用分离估计音频特征,生成至少一个分离优化估计音频特征;至少一个分离优化估计音频特征用于重构至少一个声源分别对应的估计声源音频。
具体的,步骤s203-步骤s205的具体实现过程请参见上述图2中步骤s101-步骤s104,此处不再进行赘述。
步骤s206,根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,对音频分离初始模型中的模型参数进行调整,生成音频分离模型,基于音频分离模型对声源混合音频数据进行声源音频分离处理。
具体的,上下文样本音频特征包括第一上下文样本音频特征以及第二上下文样本音频特征;第一上下文样本音频特征是指至少一个目标样本音频分别对应的特征,第二上下文样本音频特征是指音频数据库中除了至少一个目标样本音频之外的样本音频对应的特征;根据第一上下文样本音频特征、上下文目标估计音频特征以及上下文样本音频特征,确定音频分离初始模型的特征全局损失值;根据第一上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的特征双重损失值;根据上下文样本音频特征以及上下文目标估计音频特征,确定音频分离初始模型的特征归一化损失值;根据第一上下文样本音频特征以及第二上下文样本音频特征,确定音频分离初始模型的特征正则化损失值;根据特征全局损失值、特征双重损失值、特征归一化损失值以及特征正则化损失值,确定模型损失值。根据模型损失值对音频分离初始模型中的模型参数进行调整,当调整后的音频分离初始模型满足模型收敛条件时,将调整后的音频分离初始模型确定为音频分离模型。
其中,根据第一上下文样本音频特征、上下文目标估计音频特征以及上下文样本音频特征,确定音频分离初始模型的特征全局损失值,包括:确定第一上下文样本音频特征以及上下文目标估计音频特征之间的第一互信息值;确定上下文样本音频特征以及上下文目标估计音频特征之间的第二互信息值;根据第一互信息值以及第二互信息值,确定音频分离初始模型的特征全局损失值。
其中,根据第一上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的特征双重损失值,包括:统计音频分离初始模型的迭代次数,若迭代次数小于或等于迭代次数阈值,则获取至少一个目标样本音频以及至少一个估计声源音频之间的第一分离损失值;根据第一分离损失值,确定第一上下文样本音频特征以及上下文目标估计音频特征之间的第一上下文损失值;根据第一分离损失值以及第一上下文损失值确定音频分离初始模型的特征双重损失值;若迭代次数大于迭代次数阈值,则获取第一上下文样本音频特征以及上下文目标估计音频特征之间的第二上下文损失值;根据第二上下文损失值,确定至少一个目标样本音频以及至少一个估计声源音频之间的第二分离损失值;根据第二分离损失值以及第二上下文损失值确定音频分离初始模型的特征双重损失值。
可选的,至少一个目标样本音频包括目标样本音频hi以及目标样本音频hi+1,其中,i为正整数,且i小于至少一个目标样本音频的总数量;至少一个估计声源音频包括估计声源音频fj以及估计声源音频fj+1,其中,j为正整数,且j小于至少一个估计声源音频的总数量;获取目标样本音频hi以及估计声源音频fj之间的第一相似度d(i,j),获取目标样本音频hi+1以及声源音频fj+1之间的第一相似度d(i+1,j+1);根据第一相似度d(i,j)以及第一相似度d(i+1,j+1),确定至少一个目标样本音频以及至少一个估计声源音频之间的第一初始损失值;获取目标样本音频hi以及估计声源音频fj+1之间的第二相似度d(i,j+1),获取目标样本音频hi+1以及声源音频fj之间的第二相似度d(i+1,j);根据第二相似度d(i,j+1)以及第二相似度d(i+1,j),确定至少一个目标样本音频以及至少一个估计声源音频之间的第二初始损失值;从第一初始损失值以及第二初始损失值中确定最小初始损失值,将最小初始损失值确定为第一分离损失值。
在本申请实施例中,上述空间表征的训练过程,除了需要标注q种上下文类别的正样本信号源的弱监督过程,其它所有的训练都是一个自我监督的过程,因为训练过程中不使用其它标签,而是利用源之间彼此互相掩膜,并预测自己作为目标。
在第一注意力网络层中学习一种表征,该表征可以代表同一个说话人的不同语音信号中的共享信息,这种表征具有复杂的层次结构,例如音素、音节和单词,而且冗长,高维和可变长度序列。首先,给定一个正样本信号源hj+,在正样本信号源hj+与其对应的目标说话人矢量ejt(即上述的第一上下文样本音频特征)之间,利用公式(5)对它们的互信息建模:
其中,t表示第t个声源混合样本音频数据,zj表示上下文目标估计音频特征,本申请在负干扰和噪声对比估计损失的环境下进行训练,根据公式(6)定义特征全局损失值,如下所示:
其中,k为正整数,k小于或等于音频数据库中至少一个样本音频的总数量w。
在信号刺激空间(即第二注意力网络层)中执行信号重建,并同时在说话人上下文知识空间(即第一注意力网络层)中进行对比预测。由于采用了双重注意力机制,如果得到了一个空间中针对目标源的说话人输出排列,则也能确定另一空间中的对应说话人排列。请参见公式(7),根据公式(7)定义特征双重损失值。
其中,
可选的,从使用句子级置换不变训练(utterancelevelpermutationinvarianttraining,u-pit)的第一阶段开始以sisnr损失作为信号刺激空间中的目标损失,直到说话人矢量e达到相对稳定的状态,以此自监督(self-supervised)训练出说话人表征(即上下文目标估计音频特征)。然后,进入到如公式(7)中的第二阶段,换句话说,使用由说话人知识空间确定的说话人输出排列来“操纵”信号重建,同时,第二阶段免除了信号重建的pit带来的计算负担。
另外,希望学习到具有鉴别性的类间差异和尽量小的类内差异的深度表征,如公式(7)中所示,ll是具有可学习尺度α和偏差β的余弦相似度损失,它鼓励深度表征接近相应的目标说话人表征。
此外,本申请实施例采用了归一化损失函数求特征归一化损失值,如公式(8)所示,
归一化损失函数用于计算每个输出深度表征(即上下文目标估计音频特征zj)和所有训练目标说话人表征(上下文样本音频特征en)之间的整体余弦相似度。
此外,本申请实施例采用了正则化损失函数求特征正则化损失值,如公式(9)所示,
正则化损失函数用于避免训练得到全零的简单解,其中γ是其加权因子。
本申请实施例不具体限定损失函数的数学定义。例如,公式(7)中计算特征双重损失值时,采用了余弦距离(或类似欧几里得距离)计算ll,使学习到的深度表征接近相应的潜在目标说话人表征,可选的,采用其它类型的损失函数,包括但不限于采用对比(contrastive)损失,三元组(triplet)损失,人脸识别(sphereface)损失等损失函数。同理,为重建信号采用的sisnr损失函数,也可以根据实际应用目标调整为其它类型的重建损失函数。
仅为了比较的目的,图3a所示的框架图中编码器和解码器采用了跟时域音频分离网络(time-domainaudioseparationnetwork,tasnet)一致的模型结构和网络配置,但本申请实施例所述的方法支持其它网络类型的编码器以及解码器模型结构,例如实现傅立叶变换的encoder和实现反傅立叶变换的decoder,包括支持处理输入时域波形的信号和输入频域的信号类型的encoder。
同时,本申请不具体限定深度神经网络的模型类型和拓扑结构,可以替换为各种其它有效的新型的模型结构。图2以及图4所使用到的深度神经网络的网络结构和超参配置,可以替代为其它优化的网络结构和超参配置,例如闸控卷积神经网络、时延网络等,且可以根据实际应用对模型内存占用的限制和对字错误率的要求,对示例的深度神经网络的拓扑结构加以拓展或简化。
为了研究本申请提出的自监督学习框架(核心为图3c)对深度表征的泛化性能,我们将其与监督学习进行比较,在监督学习的参考系统tune-id中,说话人身份(w个标记符)被标记为训练数据的标签。对比时,采用可学习的嵌入查找表,该方法已广泛应用于自然语言处理(naturallanguageprocessing,nlp)和语音领域。可学习的嵌入查找表能固定w个说话人的嵌入表征,因此,与本申请提及的自监督学习系统tune-ince采用的目标说话人表征et不同,tune-id采用说话人的嵌入表征eid作为目标说话人的标签。事实证明,自监督学习绕过了让模型直接学习预测说话人身份信息的任务,反而令其学习到具有实质判别力和泛化能力的深度说话人表征。
另外,也利用了本申请实施例中所述的框架进行说话人验证的实验,以验证所学到的深度说话人表征的判别力和泛化能力。基于sincnet的高级标准模型1实验中被用作本申请实施例的参考系统。首先,将第一个参考模型,标注为“sincnet-clean”,“sincnet-clean”是在干净的librispeech训练集中进行了训练;而另一个参考模型,标注为“sincnet-masked”,在与本申请提出的系统一样,在线上混合的librispeech训练集上进行训练。结果实验表明本申请提出的采用自监督方法的tune-ince模型优于上述的“sincnet-clean”。
最后,本申请评估了用于语音分离任务的自监督tune-in模型。本申请所述的模型(核心为图3c)和最新的dprnn模型具有相同的设置,并且编码器窗口大小同样设置为8个样本,以进行公平比较。如下表所示,所有系统均根据sdri和si-snri进行了评估。“tune-inonline”模型可以在线学习说话人的深度表征和引导向量,并同时进行语音分离。请一并参见表1,表1是本申请实施例提供的一种实验评估表。
表1
其中,tdaa是指自上而下的听觉注意(top-downauditoryattention)模型,bilstm-tasnet是双向长短期记忆网络以及时域音频分离网络,conv-tasnet是常用卷积-时域音频分离网络,tune-inautopilot、tune-inoffline以及tune-inonline为本申请实施例提出的网络,tune-inautopilot可以应用于自动驾驶仪中,tune-inoffline可以应用于离线学习场景中,tune-inonline可以应用于在线学习场景中,由表1可知,本申请实施例提供的系统均优于现有技术。
本申请实施例在获取声源混合音频数据之后,首先基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;然后将通用分离音频特征分别输入至第一注意力网络层以及即第二注意力网络层,在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,然后将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;至少一个分离优化音频特征用于重构至少一个声源分别对应的声源音频。上述可知,本申请实施例提出两个独立的网络层(即第一注意力网络层以及第二注意力网络层),其中,第一注意力网络层通过自下而上的通用分离音频特征,学习声源混合音频数据中目标说话人的音频特征,得到上下文目标音频特征;第二注意力网络层除了通过自下而上的通用分离音频特征,还通过融合自上而下的上下文目标音频特征,即可生成高准确率的分离优化音频特征,进而提高重构声源音频的准确率。
进一步地,请参见图6,图6是本申请实施例提供的一种音频数据处理装置的结构示意图。上述音频数据处理装置可以是运行于计算机设备中的一个计算机程序(包括程序代码),例如该音频数据处理装置为一个应用软件;该装置可以用于执行本申请实施例提供的方法中的相应步骤。如图6所示,该音频数据处理装置1可以包括:第一生成模块11、第一输入模块12、第二输入模块13、第二生成模块14以及第三生成模块15。
第一生成模块11,用于获取声源混合音频数据,基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;
第一输入模块12,用于将通用分离音频特征分别输入至第一注意力网络层以及第二注意力网络层;
第二输入模块13,用于在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;
第二生成模块14,用于在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;
第三生成模块15,用于根据至少一个分离优化音频特征,生成至少一个声源分别对应的重构声源音频。
其中,第一生成模块11、第一输入模块12、第二输入模块13第二输入模块13、第二生成模块14以及第三生成模块15的具体功能实现方式可以参见上述图2对应实施例中的步骤s101-步骤s105,这里不再进行赘述。
再请参见图6,第一注意力网络层包括第一分离组件以及嵌入组件;
第二输入模块13可以包括:第一处理单元131、第二处理单元132、第一生成单元133以及第二生成单元134。
第一处理单元131,用于通过第一分离组件,对通用分离音频特征进行特征提取处理,得到目标分离音频特征,将目标分离音频特征输入至嵌入组件;
第二处理单元132,用于通过嵌入组件,对目标分离音频特征进行特征映射处理,生成至少一个声源分别对应的上下文初始音频特征;
第一生成单元133,用于根据上下文初始音频特征以及通用分离音频特征,生成至少一个声源分别对应的第一注意力分布参数;
第二生成单元134,用于根据第一注意力分布参数以及上下文初始音频特征,生成上下文目标音频特征。
其中,第一处理单元131、第二处理单元132、第一生成单元133以及第二生成单元134的具体功能实现方式可以参见上述图2对应实施例中的步骤s103,这里不再进行赘述。
再请参见图6,第一注意力网络层包括第一注意力机制组件;
第一生成单元133可以包括:第一生成子单元1331、第一输入子单元1332以及第二生成子单元1333。
第一生成子单元1331,用于对通用分离音频特征进行降维处理,得到期望分离音频特征;
第一输入子单元1332,用于将上下文初始音频特征以及期望分离音频特征输入至第一注意力机制组件;上下文初始音频特征包括上下文初始音频特征yj,至少一个声源包括声源sj,其中,j为正整数,且j小于或等于至少一个声源的声源总数量;
第二生成子单元1333,用于在第一注意力机制组件中,根据上下文初始音频特征yj以及期望分离音频特征,生成声源sj对应的第一注意力分布参数cj;
则第二生成单元134具体用于根据第一注意力分布参数cj以及上下文初始音频特征yj,生成声源sj对应的上下文目标音频特征zj。
其中,第一生成子单元1331、第一输入子单元1332、第二生成子单元1333以及第二生成单元134的具体功能实现方式可以参见上述图2对应实施例中的步骤s103-步骤s104,这里不再进行赘述。
再请参见图6,第二注意力网络层包括第二分离组件kb以及第二分离组件kb+1,其中,b为正整数,且b小于第二注意力网络层中第二分离组件的总数量;
第二生成模块14可以包括:第三处理单元141、第三生成单元142、第四处理单元143以及第四生成单元144。
第三处理单元141,用于在第二注意力网络层的第二分离组件kb中,对输入特征进行隐藏特征提取处理,得到分离隐藏音频特征gb;若第二分离组件kb为第二注意力网络层中的首个第二分离组件,则输入特征为通用分离音频特征;若第二分离组件kb不为第二注意力网络层中的首个第二分离组件,则输入特征为第二分离组件kb的上一个第二分离组件所输出的分离过渡音频特征;
第三生成单元142,用于根据上下文目标音频特征以及分离隐藏音频特征gb,在第二分离组件kb中输出分离过渡音频特征,将第二分离组件kb所输出的分离过渡音频特征作为第二分离组件kb+1的输入特征;
第四处理单元143,用于对第二分离组件kb+1的输入特征进行隐藏特征提取处理,得到分离隐藏音频特征gb+1;
第四生成单元144,用于若第二分离组件kb+1不为第二注意力网络层中的最后一个第二分离组件,则根据上下文目标音频特征以及分离隐藏音频特征gb+1,在第二分离组件kb+1中输出分离过渡音频特征,将第二分离组件kb+1所输出的分离过渡音频特征作为下一个第二分离组件的输入特征;
第四生成单元144,还用于若第二分离组件kb+1为第二注意力网络层中的最后一个第二分离组件,则根据上下文目标音频特征以及分离隐藏音频特征gb+1,生成分离优化音频特征。
其中,第三处理单元141、第三生成单元142、第四处理单元143以及第四生成单元144的具体功能实现方式可以参见上述图2对应实施例中的步骤s104,这里不再进行赘述。
再请参见图6,第二分离组件kb包括第二注意力机制组件;
第三生成单元142可以包括:第二输入子单元1421、第三生成子单元1422以及第四生成子单元1423。
第二输入子单元1421,用于将上下文目标音频特征以及分离隐藏音频特征gb,输入至第二注意力机制组件;上下文目标音频特征包括上下文目标音频特征zj,分离隐藏音频特征gb包括分离隐藏音频特征gjb,声源包括声源sj,其中,j为正整数,且j小于或等于至少一个声源的声源总数量;
第三生成子单元1422,用于在第二注意力机制组件中,根据上下文目标音频特征zj以及分离隐藏音频特征gjb,生成声源sj对应的第二注意力分布参数djb;
第四生成子单元1423,用于根据第二注意力分布参数djb、上下文目标音频特征zj以及分离隐藏音频特征gjb,生成声源sj对应的分离过渡音频特征xjb。
其中,第二输入子单元1421、第三生成子单元1422以及第四生成子单元1423的具体功能实现方式可以参见上述图2对应实施例中的步骤s104,这里不再进行赘述。
再请参见图6,第一生成模块11可以包括:第五生成单元111、第五处理单元112以及第六生成单元113。
第五生成单元111,用于获取声源混合音频数据,对声源混合音频数据进行编码处理,生成混合时间序列,将混合时间序列输入至通用分离组件;
第五处理单元112,用于在通用分离组件中,对混合时间序列进行分割处理,得到n个长度为l的时间块;其中,n为正整数,l为正数;
第六生成单元113,用于组合n个长度为l的时间块,得到初始混合音频特征,对初始混合音频特征进行声源分离预处理,得到通用分离音频特征。
其中,第五生成单元111、第五处理单元112以及第六生成单元113的具体功能实现方式可以参见上述图2对应实施例中的步骤s101,这里不再进行赘述。
再请参见图6,至少一个声源包括目标声源;第二注意力网络层包括拼接组件;
第三生成模块15可以包括:第六处理单元151、转换特征单元152以及第七生成单元153。
第六处理单元151,用于根据目标声源,从至少一个分离优化音频特征中确定待处理分离优化音频特征;
第六处理单元151,还用于将待处理分离优化音频特征输入至拼接组件;
转换特征单元152,用于在拼接组件中,基于块长度以及块数量,将待处理分离优化音频特征转换为分离时间序列;
第七生成单元153,用于对混合时间序列以及分离时间序列进行序列融合处理,生成目标时间序列;
第七生成单元153,还用于对目标时间序列进行解码处理,得到目标声源对应的重构声源音频。
其中,第六处理单元151、转换特征单元152以及第七生成单元153的具体功能实现方式可以参见上述图2对应实施例中的步骤s105,这里不再进行赘述。
本申请实施例在获取声源混合音频数据之后,首先基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;然后将通用分离音频特征分别输入至第一注意力网络层以及即第二注意力网络层,在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,然后将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;至少一个分离优化音频特征用于重构至少一个声源分别对应的声源音频。上述可知,本申请实施例提出两个独立的网络层(即第一注意力网络层以及第二注意力网络层),其中,第一注意力网络层通过自下而上的通用分离音频特征,学习声源混合音频数据中目标说话人的音频特征,得到上下文目标音频特征;第二注意力网络层除了通过自下而上的通用分离音频特征,还通过融合自上而下的上下文目标音频特征,即可生成高准确率的分离优化音频特征,进而提高重构声源音频的准确率。
进一步地,请参见图7,图7是本申请实施例提供的一种音频数据处理装置的结构示意图。上述音频数据处理装置可以是运行于计算机设备中的一个计算机程序(包括程序代码),例如该音频数据处理装置为一个应用软件;该装置可以用于执行本申请实施例提供的方法中的相应步骤。如图7所示,该音频数据处理装置2可以包括:第一生成模块21、第一输入模块22、第二输入模块23、第三输入模块24、第二生成模块25以及第三生成模块26。
第一生成模块21,用于从音频数据库中获取至少一个声源分别对应的目标样本音频,根据至少一个目标样本音频生成声源混合样本音频数据;
第一输入模块22,用于将声源混合样本音频数据输入音频分离初始模型;音频分离初始模型包括通用分离组件、第一注意力网络层以及第二注意力网络层;
第二输入模块23,用于基于通用分离组件对声源混合样本音频数据进行声源分离预处理,得到通用分离估计音频特征,将通用分离估计音频特征分别输入至第一注意力网络层以及第二注意力网络层;
第三输入模块24,用于在第一注意力网络层中,根据目标分离估计音频特征以及通用分离估计音频特征,生成至少一个声源分别对应的上下文目标估计音频特征,将上下文目标估计音频特征输入至第二注意力网络层;目标分离估计音频特征是通过对通用分离估计音频特征进行特征提取后所得到的特征;
第二生成模块25,用于在第二注意力网络层中,根据上下文目标估计音频特征以及通用分离估计音频特征,生成至少一个分离优化估计音频特征;至少一个分离优化估计音频特征用于重构至少一个声源分别对应的估计声源音频;
第三生成模块26,用于根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,对音频分离初始模型中的模型参数进行调整,生成音频分离模型,基于音频分离模型对声源混合音频数据进行声源音频分离处理。
其中,第一生成模块21、第一输入模块22、第二输入模块23、第三输入模块24、第二生成模块25以及第三生成模块26的具体功能实现方式可以参见上述图4对应实施例中的步骤s201-步骤s206,这里不再进行赘述。
再请参见图7,第三生成模块26可以包括:第一确定单元261以及第二确定单元262。
第一确定单元261,用于根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的模型损失值;
第二确定单元262,用于根据模型损失值对音频分离初始模型中的模型参数进行调整,当调整后的音频分离初始模型满足模型收敛条件时,将调整后的音频分离初始模型确定为音频分离模型。
其中,第一确定单元261以及第二确定单元262的具体功能实现方式可以参见上述图4对应实施例中的步骤s206,这里不再进行赘述。
再请参见图7,上下文样本音频特征包括第一上下文样本音频特征以及第二上下文样本音频特征;第一上下文样本音频特征是指至少一个目标样本音频分别对应的特征,第二上下文样本音频特征是指音频数据库中除了至少一个目标样本音频之外的样本音频对应的特征;
第一确定单元261可以包括:第一确定子单元2611、第二确定子单元2612、第三确定子单元2613、第四确定子单元2614以及第五确定子单元2615。
第一确定子单元2611,用于根据第一上下文样本音频特征、上下文目标估计音频特征以及上下文样本音频特征,确定音频分离初始模型的特征全局损失值;
第二确定子单元2612,用于根据第一上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的特征双重损失值;
第三确定子单元2613,用于根据上下文样本音频特征以及上下文目标估计音频特征,确定音频分离初始模型的特征归一化损失值;
第四确定子单元2614,用于根据第一上下文样本音频特征以及第二上下文样本音频特征,确定音频分离初始模型的特征正则化损失值;
第五确定子单元2615,用于根据特征全局损失值、特征双重损失值、特征归一化损失值以及特征正则化损失值,确定模型损失值。
其中,第一确定子单元2611、第二确定子单元2612、第三确定子单元2613、第四确定子单元2614以及第五确定子单元2615的具体功能实现方式可以参见上述图4对应实施例中的步骤s206,这里不再进行赘述。
再请参见图7,第一确定子单元2611,具体用于确定第一上下文样本音频特征以及上下文目标估计音频特征之间的第一互信息值;
第一确定子单元1611,具体用于确定上下文样本音频特征以及上下文目标估计音频特征之间的第二互信息值;
第一确定子单元2611,具体用于根据第一互信息值以及第二互信息值,确定音频分离初始模型的特征全局损失值。
其中,第一确定子单元2611的具体功能实现方式可以参见上述图4对应实施例中的步骤s206,这里不再进行赘述。
再请参见图7,第二确定子单元2612,具体用于统计音频分离初始模型的迭代次数,若迭代次数小于或等于迭代次数阈值,则获取至少一个目标样本音频以及至少一个估计声源音频之间的第一分离损失值;
第二确定子单元2612,具体用于根据第一分离损失值,确定第一上下文样本音频特征以及上下文目标估计音频特征之间的第一上下文损失值;
第二确定子单元2612,具体用于根据第一分离损失值以及第一上下文损失值确定音频分离初始模型的特征双重损失值;
第二确定子单元2612,具体用于若迭代次数大于迭代次数阈值,则获取第一上下文样本音频特征以及上下文目标估计音频特征之间的第二上下文损失值;
第二确定子单元2612,具体用于根据第二上下文损失值,确定至少一个目标样本音频以及至少一个估计声源音频之间的第二分离损失值;
第二确定子单元2612,具体用于根据第二分离损失值以及第二上下文损失值确定音频分离初始模型的特征双重损失值。
其中,第二确定子单元2612的具体功能实现方式可以参见上述图4对应实施例中的步骤s206,这里不再进行赘述。
再请参见图7,至少一个目标样本音频包括目标样本音频hi以及目标样本音频hi+1,其中,i为正整数,且i小于至少一个目标样本音频的总数量;至少一个估计声源音频包括估计声源音频fj以及估计声源音频fj+1,其中,j为正整数,且j小于至少一个估计声源音频的总数量;
第二确定子单元2612,具体用于获取目标样本音频hi以及估计声源音频fj之间的第一相似度d(i,j),获取目标样本音频hi+1以及声源音频fj+1之间的第一相似度d(i+1,j+1);
第二确定子单元2612,还具体用于根据第一相似度d(i,j)以及第一相似度d(i+1,j+1),确定至少一个目标样本音频以及至少一个估计声源音频之间的第一初始损失值;
第二确定子单元2612,还具体用于获取目标样本音频hi以及估计声源音频fj+1之间的第二相似度d(i,j+1),获取目标样本音频hi+1以及声源音频fj之间的第二相似度d(i+1,j);
第二确定子单元2612,还具体用于根据第二相似度d(i,j+1)以及第二相似度d(i+1,j),确定至少一个目标样本音频以及至少一个估计声源音频之间的第二初始损失值;
第二确定子单元2612,还具体用于从第一初始损失值以及第二初始损失值中确定最小初始损失值,将最小初始损失值确定为第一分离损失值。
其中,第二确定子单元2612的具体功能实现方式可以参见上述图4对应实施例中的步骤s206,这里不再进行赘述。
本申请实施例在获取声源混合音频数据之后,首先基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;然后将通用分离音频特征分别输入至第一注意力网络层以及即第二注意力网络层,在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,然后将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;至少一个分离优化音频特征用于重构至少一个声源分别对应的声源音频。上述可知,本申请实施例提出两个独立的网络层(即第一注意力网络层以及第二注意力网络层),其中,第一注意力网络层通过自下而上的通用分离音频特征,学习声源混合音频数据中目标说话人的音频特征,得到上下文目标音频特征;第二注意力网络层除了通过自下而上的通用分离音频特征,还通过融合自上而下的上下文目标音频特征,即可生成高准确率的分离优化音频特征,进而提高重构声源音频的准确率。
进一步地,请参见图8,图8是本申请实施例提供的一种计算机设备的结构示意图。如图8所示,上述计算机设备1000可以包括:处理器1001,网络接口1004和存储器1005,此外,上述计算机设备1000还可以包括:用户接口1003,和至少一个通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。其中,用户接口1003可以包括显示屏(display)、键盘(keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是非易失性的存储器(non-volatilememory),例如至少一个磁盘存储器。存储器1005可选的还可以是至少一个位于远离前述处理器1001的存储装置。如图8所示,作为一种计算机可读存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及设备控制应用程序。
在图8所示的计算机设备1000中,网络接口1004可提供网络通讯功能;而用户接口1003主要用于为用户提供输入的接口;而处理器1001可以用于调用存储器1005中存储的设备控制应用程序,以实现:
获取声源混合音频数据,基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;
将通用分离音频特征分别输入至第一注意力网络层以及第二注意力网络层;
在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;
在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;
根据至少一个分离优化音频特征,生成至少一个声源分别对应的重构声源音频。
在一个实施例中,第一注意力网络层包括第一分离组件以及嵌入组件;
上述处理器1001在执行根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征时,具体执行以下步骤:
通过第一分离组件,对通用分离音频特征进行特征提取处理,得到目标分离音频特征,将目标分离音频特征输入至嵌入组件;
通过嵌入组件,对目标分离音频特征进行特征映射处理,生成至少一个声源分别对应的上下文初始音频特征;
根据上下文初始音频特征以及通用分离音频特征,生成至少一个声源分别对应的第一注意力分布参数;
根据第一注意力分布参数以及上下文初始音频特征,生成上下文目标音频特征。
在一个实施例中,第一注意力网络层包括第一注意力机制组件;
上述处理器1001在执行根据上下文初始音频特征以及通用分离音频特征,生成至少一个声源分别对应的第一注意力分布参数时,具体执行以下步骤:
对通用分离音频特征进行降维处理,得到期望分离音频特征;
将上下文初始音频特征以及期望分离音频特征输入至第一注意力机制组件;上下文初始音频特征包括上下文初始音频特征yj,至少一个声源包括声源sj,其中,j为正整数,且j小于或等于至少一个声源的声源总数量;
在第一注意力机制组件中,根据上下文初始音频特征yj以及期望分离音频特征,生成声源sj对应的第一注意力分布参数cj;
则上述处理器1001在执行根据第一注意力分布参数以及上下文初始音频特征,生成上下文目标音频特征时,具体执行以下步骤:
根据第一注意力分布参数cj以及上下文初始音频特征yj,生成声源sj对应的上下文目标音频特征zj。
在一个实施例中,第二注意力网络层包括第二分离组件kb以及第二分离组件kb+1,其中,b为正整数,且b小于第二注意力网络层中第二分离组件的总数量;
上述处理器1001在执行在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征时,具体执行以下步骤:
在第二注意力网络层的第二分离组件kb中,对输入特征进行隐藏特征提取处理,得到分离隐藏音频特征gb;若第二分离组件kb为第二注意力网络层中的首个第二分离组件,则输入特征为通用分离音频特征;若第二分离组件kb不为第二注意力网络层中的首个第二分离组件,则输入特征为第二分离组件kb的上一个第二分离组件所输出的分离过渡音频特征;
根据上下文目标音频特征以及分离隐藏音频特征gb,在第二分离组件kb中输出分离过渡音频特征,将第二分离组件kb所输出的分离过渡音频特征作为第二分离组件kb+1的输入特征;
对第二分离组件kb+1的输入特征进行隐藏特征提取处理,得到分离隐藏音频特征gb+1;
若第二分离组件kb+1不为第二注意力网络层中的最后一个第二分离组件,则根据上下文目标音频特征以及分离隐藏音频特征gb+1,在第二分离组件kb+1中输出分离过渡音频特征,将第二分离组件kb+1所输出的分离过渡音频特征作为下一个第二分离组件的输入特征;
若第二分离组件kb+1为第二注意力网络层中的最后一个第二分离组件,则根据上下文目标音频特征以及分离隐藏音频特征gb+1,生成分离优化音频特征。
在一个实施例中,第二分离组件kb包括第二注意力机制组件;
上述处理器1001在执行在第二注意力网络层的第二分离组件kb中,对输入特征进行隐藏特征提取处理,得到分离隐藏音频特征gb时,具体执行以下步骤:
将上下文目标音频特征以及分离隐藏音频特征gb,输入至第二注意力机制组件;上下文目标音频特征包括上下文目标音频特征zj,分离隐藏音频特征gb包括分离隐藏音频特征gjb,声源包括声源sj,其中,j为正整数,且j小于或等于至少一个声源的声源总数量;
在第二注意力机制组件中,根据上下文目标音频特征zj以及分离隐藏音频特征gjb,生成声源sj对应的第二注意力分布参数djb;
根据第二注意力分布参数djb、上下文目标音频特征zj以及分离隐藏音频特征gjb,生成声源sj对应的分离过渡音频特征xjb。
在一个实施例中,上述处理器1001在执行获取声源混合音频数据,基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征时,具体执行以下步骤:
获取声源混合音频数据,对声源混合音频数据进行编码处理,生成混合时间序列,将混合时间序列输入至通用分离组件;
在通用分离组件中,对混合时间序列进行分割处理,得到n个长度为l的时间块;其中,n为正整数,l为正数;
组合n个长度为l的时间块,得到初始混合音频特征,对初始混合音频特征进行声源分离预处理,得到通用分离音频特征。
在一个实施例中,至少一个声源包括目标声源;第二注意力网络层包括拼接组件;
上述处理器1001在执行根据至少一个分离优化音频特征,生成至少一个声源分别对应的重构声源音频时,具体执行以下步骤:
根据目标声源,从至少一个分离优化音频特征中确定待处理分离优化音频特征;
将待处理分离优化音频特征输入至拼接组件;
在拼接组件中,基于块长度以及块数量,将待处理分离优化音频特征转换为分离时间序列;
对混合时间序列以及分离时间序列进行序列融合处理,生成目标时间序列;
对目标时间序列进行解码处理,得到目标声源对应的重构声源音频。
本申请实施例在获取声源混合音频数据之后,首先基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;然后将通用分离音频特征分别输入至第一注意力网络层以及即第二注意力网络层,在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,然后将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;至少一个分离优化音频特征用于重构至少一个声源分别对应的声源音频。上述可知,本申请实施例提出两个独立的网络层(即第一注意力网络层以及第二注意力网络层),其中,第一注意力网络层通过自下而上的通用分离音频特征,学习声源混合音频数据中目标说话人的音频特征,得到上下文目标音频特征;第二注意力网络层除了通过自下而上的通用分离音频特征,还通过融合自上而下的上下文目标音频特征,即可生成高准确率的分离优化音频特征,进而提高重构声源音频的准确率。
进一步地,请参见图9,图9是本申请实施例提供的一种计算机设备的结构示意图。如图9所示,上述计算机设备2000可以包括:处理器2001,网络接口2004和存储器2005,此外,上述计算机设备2000还可以包括:用户接口2003,和至少一个通信总线2002。其中,通信总线2002用于实现这些组件之间的连接通信。其中,用户接口2003可以包括显示屏(display)、键盘(keyboard),可选用户接口2003还可以包括标准的有线接口、无线接口。网络接口2004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器2005可以是高速ram存储器,也可以是非易失性的存储器(non-volatilememory),例如至少一个磁盘存储器。存储器2005可选的还可以是至少一个位于远离前述处理器2001的存储装置。如图9所示,作为一种计算机可读存储介质的存储器2005中可以包括操作系统、网络通信模块、用户接口模块以及设备控制应用程序。
在图9所示的计算机设备2000中,网络接口2004可提供网络通讯功能;而用户接口2003主要用于为用户提供输入的接口;而处理器2001可以用于调用存储器2005中存储的设备控制应用程序,以实现:
从音频数据库中获取至少一个声源分别对应的目标样本音频,根据至少一个目标样本音频生成声源混合样本音频数据;
将声源混合样本音频数据输入音频分离初始模型;音频分离初始模型包括通用分离组件、第一注意力网络层以及第二注意力网络层;
基于通用分离组件对声源混合样本音频数据进行声源分离预处理,得到通用分离估计音频特征,将通用分离估计音频特征分别输入至第一注意力网络层以及第二注意力网络层;
在第一注意力网络层中,根据目标分离估计音频特征以及通用分离估计音频特征,生成至少一个声源分别对应的上下文目标估计音频特征,将上下文目标估计音频特征输入至第二注意力网络层;目标分离估计音频特征是通过对通用分离估计音频特征进行特征提取后所得到的特征;
在第二注意力网络层中,根据上下文目标估计音频特征以及通用分离估计音频特征,生成至少一个分离优化估计音频特征;至少一个分离优化估计音频特征用于重构至少一个声源分别对应的估计声源音频;
根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,对音频分离初始模型中的模型参数进行调整,生成音频分离模型,基于音频分离模型对声源混合音频数据进行声源音频分离处理。
在一个实施例中,上述处理器2001在执行根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,对音频分离初始模型中的模型参数进行调整,生成音频分离模型时,具体执行以下步骤:
根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的模型损失值;
根据模型损失值对音频分离初始模型中的模型参数进行调整,当调整后的音频分离初始模型满足模型收敛条件时,将调整后的音频分离初始模型确定为音频分离模型。
在一个实施例中,上下文样本音频特征包括第一上下文样本音频特征以及第二上下文样本音频特征;第一上下文样本音频特征是指至少一个目标样本音频分别对应的特征,第二上下文样本音频特征是指音频数据库中除了至少一个目标样本音频之外的样本音频对应的特征;
上述处理器2001在执行根据音频数据库中的所有样本音频对应的上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的模型损失值时,具体执行以下步骤:
根据第一上下文样本音频特征、上下文目标估计音频特征以及上下文样本音频特征,确定音频分离初始模型的特征全局损失值;
根据第一上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的特征双重损失值;
根据上下文样本音频特征以及上下文目标估计音频特征,确定音频分离初始模型的特征归一化损失值;
根据第一上下文样本音频特征以及第二上下文样本音频特征,确定音频分离初始模型的特征正则化损失值;
根据特征全局损失值、特征双重损失值、特征归一化损失值以及特征正则化损失值,确定模型损失值。
在一个实施例中,上述处理器2001在执行根据第一上下文样本音频特征、上下文目标估计音频特征以及上下文样本音频特征,确定音频分离初始模型的特征全局损失值时,具体执行以下步骤:
确定第一上下文样本音频特征以及上下文目标估计音频特征之间的第一互信息值;
确定上下文样本音频特征以及上下文目标估计音频特征之间的第二互信息值;
根据第一互信息值以及第二互信息值,确定音频分离初始模型的特征全局损失值。
在一个实施例中,上述处理器2001在执行根据第一上下文样本音频特征、上下文目标估计音频特征、至少一个目标样本音频以及至少一个估计声源音频,确定音频分离初始模型的特征双重损失值时,具体执行以下步骤:
统计音频分离初始模型的迭代次数,若迭代次数小于或等于迭代次数阈值,则获取至少一个目标样本音频以及至少一个估计声源音频之间的第一分离损失值;
根据第一分离损失值,确定第一上下文样本音频特征以及上下文目标估计音频特征之间的第一上下文损失值;
根据第一分离损失值以及第一上下文损失值确定音频分离初始模型的特征双重损失值;
若迭代次数大于迭代次数阈值,则获取第一上下文样本音频特征以及上下文目标估计音频特征之间的第二上下文损失值;
根据第二上下文损失值,确定至少一个目标样本音频以及至少一个估计声源音频之间的第二分离损失值;
根据第二分离损失值以及第二上下文损失值确定音频分离初始模型的特征双重损失值。
在一个实施例中,至少一个目标样本音频包括目标样本音频hi以及目标样本音频hi+1,其中,i为正整数,且i小于至少一个目标样本音频的总数量;至少一个估计声源音频包括估计声源音频fj以及估计声源音频fj+1,其中,j为正整数,且j小于至少一个估计声源音频的总数量;
上述处理器2001在执行获取至少一个目标样本音频以及至少一个估计声源音频之间的第一分离损失值时,具体执行以下步骤:
获取至少一个目标样本音频以及至少一个估计声源音频之间的第一分离损失值,包括:
获取目标样本音频hi以及估计声源音频fj之间的第一相似度d(i,j),获取目标样本音频hi+1以及声源音频fj+1之间的第一相似度d(i+1,j+1);
根据第一相似度d(i,j)以及第一相似度d(i+1,j+1),确定至少一个目标样本音频以及至少一个估计声源音频之间的第一初始损失值;
获取目标样本音频hi以及估计声源音频fj+1之间的第二相似度d(i,j+1),获取目标样本音频hi+1以及声源音频fj之间的第二相似度d(i+1,j);
根据第二相似度d(i,j+1)以及第二相似度d(i+1,j),确定至少一个目标样本音频以及至少一个估计声源音频之间的第二初始损失值;
从第一初始损失值以及第二初始损失值中确定最小初始损失值,将最小初始损失值确定为第一分离损失值。
本申请实施例在获取声源混合音频数据之后,首先基于通用分离组件对声源混合音频数据进行声源分离预处理,得到通用分离音频特征;然后将通用分离音频特征分别输入至第一注意力网络层以及即第二注意力网络层,在第一注意力网络层中,根据目标分离音频特征以及通用分离音频特征,生成至少一个声源分别对应的上下文目标音频特征,然后将上下文目标音频特征输入至第二注意力网络层;目标分离音频特征是通过对通用分离音频特征进行特征提取后所得到的特征;在第二注意力网络层中,根据上下文目标音频特征以及通用分离音频特征,生成至少一个分离优化音频特征;至少一个分离优化音频特征用于重构至少一个声源分别对应的声源音频。上述可知,本申请实施例提出两个独立的网络层(即第一注意力网络层以及第二注意力网络层),其中,第一注意力网络层通过自下而上的通用分离音频特征,学习声源混合音频数据中目标说话人的音频特征,得到上下文目标音频特征;第二注意力网络层除了通过自下而上的通用分离音频特征,还通过融合自上而下的上下文目标音频特征,即可生成高准确率的分离优化音频特征,进而提高重构声源音频的准确率。
本申请实施例还提供一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序包括程序指令,该程序指令被处理器执行时实现图2和图4中各个步骤所提供的音频数据处理方法,具体可参见上述图2和图4各个步骤所提供的实现方式,在此不再赘述。
上述计算机可读存储介质可以是前述任一实施例提供的音频数据处理装置或者上述计算机设备的内部存储单元,例如计算机设备的硬盘或内存。该计算机可读存储介质也可以是该计算机设备的外部存储设备,例如该计算机设备上配备的插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)等。进一步地,该计算机可读存储介质还可以既包括该计算机设备的内部存储单元也包括外部存储设备。该计算机可读存储介质用于存储该计算机程序以及该计算机设备所需的其他程序和数据。该计算机可读存储介质还可以用于暂时地存储已经输出或者将要输出的数据。
本申请实施例的说明书和权利要求书及附图中的术语“第一”、“第二”等是用于区别不同对象,而非用于描述特定顺序。此外,术语“包括”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、装置、产品或设备没有限定于已列出的步骤或模块,而是可选地还包括没有列出的步骤或模块,或可选地还包括对于这些过程、方法、装置、产品或设备固有的其他步骤单元。
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
本申请实施例提供的方法及相关装置是参照本申请实施例提供的方法流程图和/或结构示意图来描述的,具体可由计算机程序指令实现方法流程图和/或结构示意图的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。这些计算机程序指令可提供到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或结构示意图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或结构示意图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或结构示意一个方框或多个方框中指定的功能的步骤。
以上所揭露的仅为本申请较佳实施例而已,当然不能以此来限定本申请之权利范围,因此依本申请权利要求所作的等同变化,仍属本申请所涵盖的范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



