
 商标分类
商标分类  商标转让
商标转让 
基音强调装置、其方法、程序、以及记录介质与流程
 2021-01-28 13:01:17|
2021-01-28 13:01:17| 308|
308| 起点商标网
起点商标网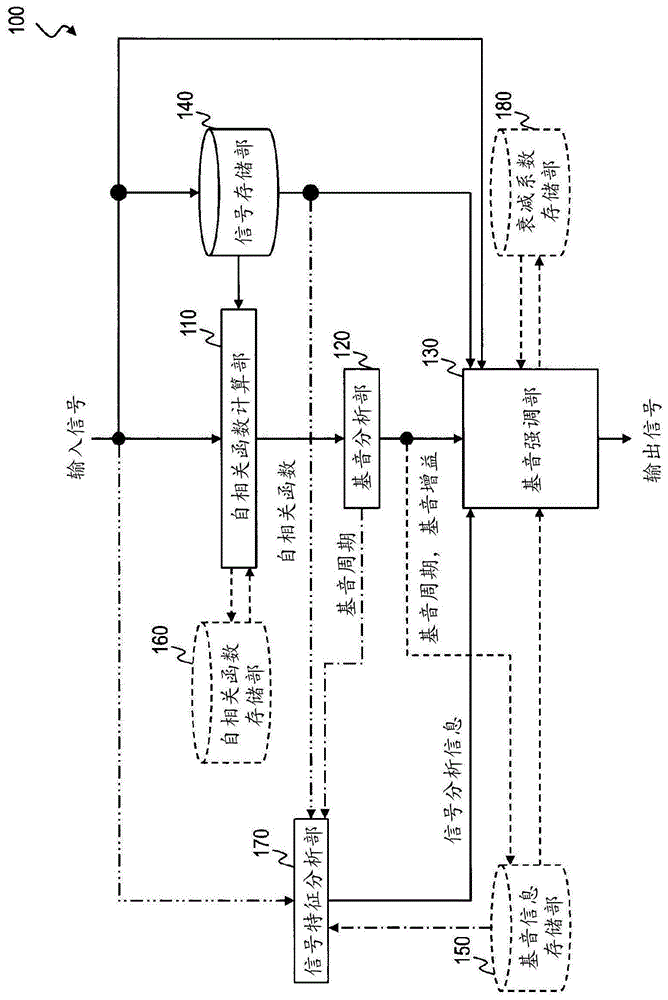
本发明涉及在声音信号的编码技术等信号处理技术中,对来源于声音信号的样本串,分析并强调其基音成分的技术。
背景技术:
一般来说,在将时间序列信号等样本串非可逆地进行了压缩编码的情况下,在解码时得到的样本串变为与原来的样本串不同的、有失真的样本串。特别是在声音信号的编码中,该失真大多包含如自然音中不存在的结构(pattern),有时在收听到解码后的声音信号时感到不自然。因此,以下技术被广泛使用,即着眼于大多数自然音包含在某固定区间中进行观测时与声音对应的周期成分,即基音的事实,通过对通过解码得到的声音信号的各样本,加上与基音周期对应的数量的过去的样本,进行强调基音成分的处理(基音强调处理)。通过该基音强调处理,变换为不适感更少的声音(例如非专利文献1)。
而且,例如专利文献1中记载的那样,还有以下技术,即,基于通过解码得到的声音信号是“语音”还是“非语音”的信息,在为“语音”的情况下进行强调基音成分的处理,在为“非语音”的情况下不进行强调基音成分的处理。
现有技术文献
非专利文献
非专利文献1:itu-trecommendationg.723.1(05/2006)pp.16-18,2006
专利文献
专利文献1:日本专利特开平10-143195号公报
技术实现要素:
发明要解决的课题
但是,在非专利文献1中记载的技术中存在以下课题:由于对不具有明确的基音构造的辅音部也进行强调基音成分的处理,在收听到辅音部时感到不自然。另一方面,在专利文献1中记载的技术中存在以下课题:即使在辅音部中作为信号而存在基音成分的情况下,也完全不进行强调基音成分的处理,所以在收听到辅音部时感到不自然。而且,在专利文献1中记载的技术中还存在以下课题:由于在元音的时间区间和辅音的时间区间中切换基音强调处理的有无,在声音信号中频繁地产生不连续,在收听时的不适感增加。
本发明是用于解决这些课题的发明,其目的是实现即使为辅音的时间区间不适感也少的基音强调处理,且即使在辅音的时间区间和除此以外的时间区间频繁地切换的情况下,基于不连续的收听时的不适感也少的基音强调处理。而且,辅音包含摩擦音、爆破音、半元音、鼻音、以及破擦音(参照参考文献1、参考文献2)。
(参考文献1)古井贞姬著,“音响·音声工学”,近代科学社,1992年,第99页(古井貞煕著、「音響·音声工学」、近代科学社、1992年、p.99)
(参考文献2)齐藤收三,中田和男,“音声信息处理的基础”,ohmsha,ltd.,1981年,第38-39页(斎藤収三、中田和男、「音声情報処理の基礎」、オーム社、1981年、p.38-39)
用于解决课题的手段
为了解决上述的课题,根据本发明的一个方式,基音强调装置对于来源于被输入的声音信号的信号,在每个时间区间实施基音强调处理而得到输出信号。基音强调装置包含基音强调部,作为基音强调处理进行以下处理:对被判定为信号为辅音的时间区间,对于该时间区间的各时刻,比该时刻早与该时间区间的基音周期对应的样本数t0的过去的时刻的信号、该时间区间的基音增益σ0、规定的常数b0、大于0且小于1的值进行相乘,将相乘后的信号与该时刻的信号进行相加,得到包含相加后的信号的信号作为输出信号,对被判定为信号不是辅音的时间区间,对于该时间区间的各时刻,将比该时刻早与该时间区间的基音周期对应的样本数t0的过去的时刻的信号、该时间区间的基音增益σ0、规定的常数b0进行相乘,将相乘后的信号与该时刻的信号进行相加,得到包含相加后的信号的信号作为输出信号。
为了解决上述的课题,根据本发明的另一方式,基音强调装置对于来源于被输入的声音信号的信号,在每个时间区间实施基音强调处理而得到输出信号。基音强调装置包含基音强调部,作为基音强调处理进行以下处理:对于各时间区间的各时刻n,将比该时刻n早与该时间区间的基音周期对应的样本数t0的过去的时刻的信号、该时间区间的基音增益σ0、如下的值进行相乘,将相乘后的信号与该时刻n的信号进行相加,得到包含相加后的信号的信号作为输出信号:所述值是随着该时间区间越像辅音则越小的值。
为了解决上述的课题,根据本发明的另一方式,基音强调装置对于来源于被输入的声音信号的信号,在每个时间区间实施基音强调处理而得到输出信号。基音强调装置包含基音强调部,作为基音强调处理进行以下处理:对于被判定为信号为辅音或者/以及信号的频谱包络是平坦的时间区间,对于该时间区间的各时刻,将比该时刻早与该时间区间的基音周期对应的样本数t0的过去的时刻的信号、该时间区间的基音增益σ0、规定的常数b0、大于0且小于1的值进行相乘,将相乘后的信号与该时刻的信号进行相加,得到包含相加后的信号的信号作为输出信号,对于成为除此以外的判定的时间区间,对于该时间区间的各时刻,将比该时刻早与该时间区间的基音周期对应的样本数t0的过去的时刻的信号、该时间区间的基音增益σ0、规定的常数b0进行相乘,将相乘后的信号与该时刻的信号进行相加,得到包含相加后的信号的信号作为输出信号。
为了解决上述的课题,根据本发明的另一方式,基音强调装置对于来源于被输入的声音信号的信号,在每个时间区间实施基音强调处理而得到输出信号。基音强调装置包含基音强调部,作为基音强调处理进行以下处理:对于各时间区间的各时刻n,将比该时刻n早与该时间区间的基音周期对应的样本数t0的过去的时刻的信号、该时间区间的基音增益σ0、如下的值进行相乘,将相乘后的信号与该时刻n的信号进行相加,得到包含相加后的信号的信号作为输出信号:所述值是随着该时间区间越像辅音则越小且随着该时间区间的频谱包络越平坦则越小的值。
发明的效果
根据本发明,产生以下效果,即可以实现在对通过解码处理得到的语音信号实施基音强调处理的情况下,即使是辅音的时间区间不适感也少,即使在辅音的时间区间与除此以外的时间区间频繁地切换的情况下,基于不连续的收听时的不适感也少的基音强调处理。
附图说明
图1是第一实施方式、第二实施方式、第三实施方式、以及它们的变形例的基音强调装置的功能框图。
图2是表示第一实施方式、第二实施方式、第三实施方式、以及它们的变形例的基音强调装置的处理流程的例子的图。
图3是其它的变形例的基音强调装置的功能框图。
图4是表示其它的变形例的基音强调装置的处理流程的例子的图。
具体实施方式
以下,对本发明的实施方式进行说明。而且,在以下的说明中使用的附图,对具有相同的功能的结构部或进行相同的处理的步骤标记同一标号,省略重复说明。在以下的说明中,以向量或矩阵的各要素单位进行的处理,只要不特别说明,设为对该向量或该矩阵的全部要素进行适用。
<第一实施方式>
图1表示第一实施方式的语音基音强调装置100的功能框图,图2表示其处理流程。
参照图1,说明第一实施方式的语音基音强调装置100的处理过程。第一实施方式的语音基音强调装置100分析被输入的信号,得到基音周期和基音增益,基于该基音周期和基音增益来强调基音。在本实施方式中,在对每个时间区间的被输入的声音信号,使用对与基音周期对应的基音成分乘以了基音增益的结果来实施基音强调处理时,使辅音的时间区间的基音成分的强调的程度,小于辅音以外的时间区间的基音成分的强调的程度。或者,使时间区间的基音成分的强调的程度随着越像辅音则越小。更具体地说,对于辅音的时间区间,使用对基音增益乘以小于1的值的结果,取代基音增益。第一实施方式的语音基音强调装置100具备:信号特征分析部170、自相关函数计算部110、基音分析部120、基音强调部130以及信号存储部140。进而,第一实施方式的语音基音强调装置100也可以还具备:基音信息存储部150、自相关函数存储部160和衰减系数存储部180。
语音基音强调装置100例如是在具有中央运算处理装置(cpu:centralprocessingunit,中央处理单元)、主存储装置(ram:randomaccessmemory,随机存取存储器)等的公知或者专用的计算机中读入特别的程序而构成的特别的装置。语音基音强调装置100例如在中央运算处理装置的控制下执行各处理。被输入到语音基音强调装置100的数据或在各处理中得到的数据例如被存储在主存储装置中,主存储装置中存储的数据根据需要被读出至中央运算处理装置,被其它处理利用。语音基音强调装置100的各处理部的至少一部分也可以由集成电路等硬件构成。语音基音强调装置100所具有的各存储部例如可以由ram(randomaccessmemory)等主存储装置、或者继关系数据库或键值存储等中间件构成。但是,各存储部不需要一定配置在语音基音强调装置100的内部,也可以由通过硬盘或光盘或者闪存(flashmemory)那样的半导体存储器元件构成的辅助存储装置来构成,也可以设为在语音基音强调装置100的外部具有的结构。
第一实施方式的语音基音强调装置100进行的主要的处理是自相关函数计算处理(s110)、基音分析处理(s120)、信号特征分析处理(s170)和基音强调处理(s130)(参照图2)。这些处理是语音基音强调装置100所具有的多个硬件资源合作进行的处理,所以以下对于自相关函数计算处理(s110)、基音分析处理(s120)、信号特征分析处理(s170)、基音强调处理(s130)的每一个,与相关联的处理一起进行说明。
[自相关函数计算处理(s110)]
首先,对语音基音强调装置100进行的自相关函数计算处理和与其关联的处理进行说明。
在自相关函数计算部110中,被输入时间区域的声音信号(输入信号)。该声音信号例如是将语音信号等音响信号在编码装置中压缩编码而得到代码,在与该编码装置对应的解码装置中将代码解码而得到的信号。在自相关函数计算部110中,以规定的时间长度的帧(时间区间)为单位,输入被输入到语音基音强调装置100的当前帧的时间区域的声音信号的样本串。若将表示1帧的样本串的长度的正整数设为n,则在自相关函数计算部110中,输入构成当前帧的时间区域的声音信号的样本串的n个时间区域的声音信号样本。自相关函数计算部110计算包含被输入的n个时间区域的声音信号样本的最新的l个(l为正整数)的声音信号样本的样本串中的时间差0的自相关函数r0以及对于多个(m个,m为正整数)规定的时间差τ(1),…,τ(m)的每一个的自相关函数rτ(1),…,rτ(m)。即,自相关函数计算部110计算包含当前帧的时间区域的声音信号样本的最新的声音信号样本的样本串中的自相关函数。
而且,在以下也将在当前帧的处理中自相关函数计算部110计算出的自相关函数,即,包含当前帧的时间区域的声音信号样本的最新的声音信号样本的样本串中的自相关函数称为“当前帧的自相关函数”。同样,在将过去的某帧设为帧f时,也将在帧f的处理中自相关函数计算部110所计算出的自相关函数,即,包含帧f的时间区域的声音信号样本的帧f的时刻的最新的声音信号样本的样本串中的自相关函数称为“帧f的自相关函数”。而且,有时“自相关函数”也仅称为“自相关”。在l为大于n的值的情况下,为了在自相关函数的计算中使用最新的l个声音信号样本,在语音基音强调装置100内具备信号存储部140,使得信号存储部140可以存储被输入到前一帧的最新的至少l-n个声音信号样本。然后,在当前帧的n个时间区域的声音信号样本已被输入时,自相关函数计算部110读出信号存储部140中存储的最新的l-n个声音信号样本作为x0,x1,…,xl-n-1,通过将被输入的n个时间区域的声音信号样本设为xl-n,xl-n+1,…,xl-1,获得最新的l个声音信号样本x0,x1,…,xl-1。
然后,自相关函数计算部110使用最新的l个声音信号样本x0,x1,…,xl-1,计算时间差0的自相关函数r0、以及对于多个规定的时间差τ(1),…,τ(m)各个的自相关函数rτ(1),…,rτ(m)。若将τ(1),…,τ(m)或0等时间差设为τ,则自相关函数计算部110例如通过以下的式(1)计算自相关函数rτ。
[数1]
自相关函数计算部110将计算出的自相关函数r0,rτ(1),…,rτ(m)输出到基音分析部120。
而且,该时间差τ(1),…,τ(m)是后述的基音分析部120求出的当前帧的基音周期t0的候选。例如,在以采样频率32khz的语音信号为主的声音信号的情况下,作为语音的基音周期的候选,考虑将优选的从75至320的整数值设为τ(1),…,τ(m)等实现。而且,也可以取代式(1)的rτ,求将式(1)的rτ除以r0后的归一化自相关函数rτ/r0。但是,在将l设为8192等、相对作为基音周期t0的候选的从75至320足够大的值的情况下等,与取代自相关函数rτ而求归一化自相关函数rτ/r0相比,通过以下说明的抑制了运算量的方法来计算自相关函数rτ较好。
自相关函数rτ虽然可以通过式(1)本身计算,但是也可以通过其它计算方法计算与式(1)中所求出的值相同的值。例如,在语音基音强调装置100内具备自相关函数存储部160,在自相关函数存储部160中预先存储在计算前1帧(前一帧)的自相关函数的处理中得到的自相关函数(前一帧自相关函数)rτ(1),…,rτ(m)。自相关函数计算部110也可以通过对从自相关函数存储部160读出的前一帧的处理中得到的自相关函数(前一帧自相关函数)rτ(1),…,rτ(m)的每一个,进行新输入的当前帧的声音信号样本的贡献分的加法、最过去的帧的贡献分的减法,计算当前帧的自相关函数rτ(1),…,rτ(m)。由此,与通过式(1)本身进行计算相比,能够抑制自相关函数的计算中所需要的运算量。在该情况下,若将τ(1),…,τ(m)的每一个设为τ,则自相关函数计算部110通过对在前一帧的处理中得到的自相关函数rτ(前一帧的自相关函数rτ)加上在以下的式(2)中得到的差分δrτ+,在前一帧中减去在式(3)中得到的差分δrτ-,得到当前帧的自相关函数rτ。
[数2]
而且,也可以不使用被输入的声音信号的最新的l个声音信号样本本身,而使用通过对该l个声音信号样本进行下采样或样本的稀疏等减少了样本数的信号,通过与上述同样的处理计算自相关函数,从而节约运算量。在该情况下,m个时间差τ(1),…,τ(m)例如在将样本数减半时用一半的样本数表现。例如,在将上述的采样频率32khz的8192个声音信号样本下采样至采样频率16khz的4096个样本的情况下,作为基音周期t的候选的τ(1),…,τ(m)只要设为从75至320的大约一半即从37至160即可。
而且,信号存储部140中存储的声音信号样本也可以被用于后述的信号特征分析处理。具体地说,在后述的信号特征分析处理中使用信号存储部140中存储的j-n个(j为正整数)的声音信号样本。即,若将l和j中较大的值设为k(若设为k=max(l,j)),则需要将被输入至前1帧的最新的至少k-n个声音信号样本存储在信号存储部140中。因此,在语音基音强调装置100结束了直至对于当前帧的后述的基音强调部130的处理后,信号存储部140更新存储内容,使得在该时刻预先存储最新的k-n个声音信号样本。具体地说,例如在k>2n的情况下,信号存储部140删除被存储的k-n个声音信号样本中最早的n个声音信号样本xr0,xr1,…,xrn-1,将xrn,xrn+1,…,xrk-n-1设为xr0,xr1,…,xrk-2n-1,被输入的当前帧的n个时间区域的声音信号样本新存储为xrk-2n,xrl-2n+1,…,xrk-n-1。而且,在k≤2n的情况下,信号存储部140删除被存储的k-n个声音信号样本xr0,xr1,…,xrk-n-1,将被输入的当前帧的n个时间区域的声音信号样本中最新的k-n个声音信号样本新存储为xr0,xr1,…,xrk-n-1。而且,在k≤n的情况下,在语音基音强调装置100内不需要具备信号存储部140。
而且,自相关函数存储部160在自相关函数计算部110结束了对于当前帧的自相关函数的计算后,更新存储内容,使得预先存储计算出的当前帧的自相关函数rτ(1),…,rτ(m)。具体地说,自相关函数存储部160删除被存储的rτ(1),…,rτ(m),新存储计算出的当前帧的自相关函数rτ(1),…,rτ(m)。
而且,在上述的说明中,以最新的l个声音信号样本包含当前帧的n个声音信号样本(即l≥n)作为前提,但是不一定需要是l≥n,也可以是l<n。在该情况下,自相关函数计算部110使用在当前帧的n个中包含的连续的l个声音信号样本x0,x1,…,xl-1,计算时间差0的自相关函数r0、以及对于多个规定的时间差τ(1),…,τ(m)的每一个的自相关函数rτ(1),…,rτ(m)即可。
[基音分析处理(s120)]
接着,对语音基音强调装置100进行的基音分析处理进行说明。
在基音分析部120中被输入自相关函数计算部110输出的当前帧的自相关函数r0,rτ(1),…,rτ(m)。
基音分析部120求出对于规定的时间差的当前帧的自相关函数rτ(1),…,rτ(m)中的最大值。基音分析部120得到自相关函数的最大值与时间差0的自相关函数r0之比作为当前帧的基音增益σ0,而且,得到自相关函数为最大值的时间差作为当前帧的基音周期t0,将它们分别输出至基音强调部130。
[信号特征分析处理(s170)]
接着,对语音基音强调装置100进行的信号特征分析处理进行说明。
在信号特征分析部170中被输入来源于时间区域的声音信号的信息。该声音信号是与被输入到自相关函数计算部110的声音信号相同的信号。
例如,在信号特征分析部170中,以规定的时间长度的帧(时间区间)为单位,输入被输入到语音基音强调装置100的当前帧的时间区域的声音信号的样本串。即,在信号特征分析部170中,被输入构成当前帧的时间区域的声音信号的样本串的n个时间区域的声音信号样本。在该情况下,信号特征分析部170使用包含被输入的n个时间区域的声音信号样本的最新的j个(j为正整数)的声音信号样本的样本串,得到表示当前帧是否为辅音的信息、或者当前帧的辅音相似度的指标值,作为信号分析信息i0输出至基音强调部130。即,在该情况下,“来源于时间区域的声音信号的信息”是当前帧的时间区域的声音信号的样本串(图1中,用双点划线表示)。
而且,例如,在信号特征分析部170中,以规定的时间长度的帧(时间区间)为单位,输入从当前帧的基音周期t0至过去ε个的帧的基音周期t-ε。在该情况下,信号特征分析部170使用从当前帧的基音周期t0至过去ε个的帧的基音周期t-ε,得到表示当前帧是否为辅音的信息,或者当前帧的辅音相似度的指标值,作为信号分析信息i0输出至基音强调部130。即,在该情况下,“来源于时间区域的声音信号的信息”是从当前帧的基音周期t0至过去ε个的帧的基音周期t-ε(图1中,用点划线表示)。在该情况下,语音基音强调装置100还具有基音信息存储部150,在基音信息存储部150中预先存储从前1帧至过去ε个的帧的基音周期t-1,...,t-ε。然后,信号特征分析部170使用从基音分析部120输入的当前帧的基音周期t0、和从基音信息存储部150读出的从过去1个的帧至过去ε个的帧的基音周期t-1,...,t-ε。但是,这里从当前帧看,将s个之前的帧(过去s个的帧)的基音周期记述为t-s,ε是预先决定的正整数。而且,基音信息存储部150更新存储内容,使得可以将当前帧的基音周期作为以后的帧的信号特征分析部170的处理中过去的帧的基音周期使用。
信号特征分析部170例如通过下记的例子1至例5的信号特征分析处理得到信号分析信息i0。
(信号特征分析处理的例子1:将辅音相似度的指标值设为信号分析信息的例子其1)
在该例中,信号特征分析部170使用从被输入的当前帧的基音周期t0至过去ε个的帧的基音周期t-ε,得到随着基音周期的不连续性越大则值越大的指标值(为了方便,也称为“辅音相似度的第1-1的指标值”),作为当前帧的辅音相似度的指标值,输出得到的第1-1的指标值作为信号分析信息i0:。
信号特征分析部170例如使用从基音分析部120输入的基音周期t0和从基音信息存储部150读出的从过去1个的帧至过去ε个的帧的基音周期t-1,...,t-ε,通过式(4)求第1-1的指标值δ。
δ=(|t0-t-1|+|t-1-t-2|+...+|t-(ε-1)-t-ε|)/ε(4)
在元音的情况下,基音周期有连续性,连续的基音周期间的差分变为接近0的值,δ的值也有变小的趋势。另一方面,在辅音的情况下,在基音周期中没有连续性,δ的值有变大的趋势。因此,在该例中,根据该趋势,利用第1-1的指标值δ作为辅音相似度的指标值。而且,ε希望设为大至可得到用于判定的足够的信息的程度、且小至在与t0~t-ε对应的时间区间中不混合辅音和元音的程度的值。
(信号特征分析处理的例子2:将辅音相似度的指标值设为信号分析信息的例子其2)
在该例中,信号特征分析部170使用包含被输入的n个时间区域的声音信号样本的最新的j个声音信号样本的样本串,得到摩擦音相似度的指标值(为了方便,也称为“辅音相似度的第1-2的指标值”)作为当前帧的辅音相似度的指标值,输出得到的第1-2的指标值作为信号分析信息i0。
信号特征分析部170例如求出包含被输入的n个时间区域的声音信号样本的最新的j个声音信号样本的样本串的零交叉点数(参照参考文献3)作为摩擦音相似度的指标值即辅音相似度的第1-2的指标值。
(参考文献3)l.r.rabbiner等人,铃木久树译,“语音的数字信号处理(1)”,coronapublishingco.,ltd,1983年,第132-137页(l.r.ラビナー他著、鈴木久喜訳、「音声のディジタル信号処理(上)」、株式会社コロナ社、1983年、p.132-137)
而且,信号特征分析部170例如通过修正离散余弦变换(mdct)等,将包含被输入的n个时间区域的声音信号样本的最新的j个声音信号样本的样本串变换为频谱序列。接着,信号特征分析部170求出随着频谱序列中位于高域侧的样本的平均能量对于频谱序列中位于低域侧的样本的平均能量的比越大则值越大的指标值,作为摩擦音相似度的指标值即辅音相似度的第1-2的指标值。
如前所述,辅音包含摩擦音(参照参考文献1、参考文献2)。因此在该例中,利用摩擦音相似度的指标值作为辅音相似度的指标值。
(信号特征分析处理的例子3:将组合了多个指标值的指标值设为信号分析信息的例子)
在该例中,信号特征分析部170首先使用从被输入的当前帧的基音周期t0至过去ε个的帧的基音周期t-ε,通过与例1相同的方法,得到当前帧的辅音相似度的第1-1的指标值(step(步骤)3-1)。而且,信号特征分析部170使用包含被输入的n个时间区域的声音信号样本的最新的j个声音信号样本的样本串,通过与例2相同的方法,得到当前帧的辅音相似度的第1-2的指标值(step3-2)。信号特征分析部170进一步通过对在step3-1中得到的第1-1的指标值和在step3-2中得到的第1-2的指标值进行加权相加等,获得如下值作为当前帧的辅音相似度的指标值(为了方便,也称为“辅音相似度的第1-3的指标值”),输出得到的第1-3的指标值作为信号分析信息i0:所述第1-3的指标值是随着第1-1的指标值变大而变大、且随着第1-2的指标值变大而变大的值(step3-3)。
如前所述,第1-1的指标值和第1-2的指标值是表示辅音相似度的指标。在该例中,通过将两个指标值组合,可以更灵活地设定辅音相似度的指标值。
在信号特征分析处理的例1~例3中说明了将辅音相似度的指标值设为信号分析信息的例子。从这里开始,说明将表示是否为辅音的信息设为信号分析信息的例子。
(信号特征分析处理的例子4:将表示是否为辅音的信息设为信号分析信息的例子其1)
在该例中,信号特征分析部170首先通过与从例1至例3的任意一个相同的方法,得到当前帧的辅音相似度的第1-1~1-3的指标值的任意一个。接着,信号特征分析部170在得到的指标值(即,第1-1~1-3的指标值的任意一个)为预先决定的阈值以上或者超过阈值的情况下,将表示当前帧为辅音的信息(为了方便,也将表示与“第1-1的指标值”~“第1-3的指标值”对应的“表示当前帧是否为辅音的信息”分别称为“第1-1的信息”~“第1-3的信息”)输出作为信号分析信息i0,在并非如此的情况下,将表示当前帧不是辅音的第1-1~第1-3的信息的任意一个输出作为信号分析信息i0。
(信号特征分析处理的例子5:将表示是否为辅音的信息设为信号分析信息的例子其2)
在该例中,信号特征分析部170首先通过与例1相同的方法,得到当前帧的辅音相似度的第1-1的指标值(step5-1)。接着,信号特征分析部170在step5-1中得到的第1-1的指标值为预先决定的阈值以上或者超过阈值的情况下,得到表示当前帧为辅音的第1-1的信息,在并非如此的情况下,得到表示当前帧不是辅音的第1-1的信息(step5-2)。而且,信号特征分析部170通过与例2相同的方法,得到当前帧的辅音相似度的第1-2的指标值(step5-3)。信号特征分析部170在step5-3中得到的第1-2的指标值为预先决定的阈值以上或者超过阈值的情况下,得到表示当前帧为辅音的第1-2的信息,在并非如此的情况下,得到表示当前帧不是辅音的第1-2的信息(step5-4)。进而,信号特征分析部170在step5-2中得到的第1-1的信息表示为辅音、并且在step5-4中得到的第1-2的信息表示为辅音的情况下,将表示当前帧为辅音的信息(为了方便,也称为“第1-4的信息”)输出作为信号分析信息i0,在并非如此的情况下,将表示当前帧不是辅音的第1-4的信息输出作为信号分析信息i0(step5-5)。
而且,信号特征分析部170也可以取代上述的step5-5,在step5-2中得到的第1-1的信息表示为辅音或者在step5-4中得到的第1-2的信息表示为辅音的情况下,将表示当前帧为辅音的第1-4的信息输出作为信号分析信息i0,在并非如此的情况下,将表示当前帧不是辅音的第1-4的信息输出作为信号分析信息i0(step5-5')。
通过这样的处理,信号特征分析部170将辅音相似度的指标值或者表示是否为辅音的信息输出作为信号分析信息i0。
[基音强调处理(s130)]
接着,对语音基音强调装置100进行的基音强调处理进行说明。
基音强调部130接受基音分析部120输出的基音周期和基音增益、信号特征分析部170输出的信号分析信息、以及被输入到语音基音强调装置100的当前帧的时间区域的声音信号(输入信号)。基音强调部130对当前帧的声音信号样本串,输出将与当前帧的基音周期t0对应的基音成分以基于基音增益σ0的强调的程度在辅音的帧小于辅音以外的帧的方式进行强调而得到的输出信号的样本串。
以下,说明具体例。
基音强调部130使用被输入的当前帧的基音增益σ0、被输入的当前帧的基音周期t0、被输入的当前帧的信号分析信息i0,进行对于当前帧的声音信号的样本串的基音强调处理。具体地说,基音强调部130对于构成被输入的当前帧的声音信号的样本串的各样本xn(l-n≤n≤l-1),通过以下的式(8)得到输出信号xnewn,由此得到n个样本xnewl―n,…,xnewl―1的当前帧的输出信号的样本串。
[数3]
其中,在信号分析信息i0为表示是否为辅音的信息的情况下,衰减系数γ0在当前帧的信号分析信息i0表示是辅音的情况下为大于0且小于1的预先决定的值(0<γ0<1),在当前帧的信号分析信息i0表示不是辅音的情况下为1(γ0=1)。
而且,在当前帧的信号分析信息i0是辅音相似度的指标值的情况下,衰减系数γ0是根据当前帧的信号分析信息i0决定的值,辅音相似度的指标值i0越大则衰减系数γ0是越小的值。更具体地说,例如,辅音相似度的指标值i0越大则衰减系数γ0是越小的值,并且,设为在辅音相似度的指标值i0为该指标值可取的最小值的情况下为γ0=1,并且,在辅音相似度的指标值i0为该指标值可取的最大值的情况下为γ0=0那样的、通过规定的函数γ0=f(i0)求的值即可。
而且,式(8)的a是通过下记的式(9)求的振幅校正系数。
[数4]
而且,b0是预先决定的值,例如为3/4。
式(8)的基音强调处理是不仅考虑基音周期,还考虑基音增益的强调基音成分的处理,并且对于是辅音的帧的基音成分,与不是辅音的帧的基音成分相比以较小的强调的程度强调基音成分的处理。
即,在信号分析信息i0表示是否为辅音的情况下,在基音强调部130中,对判定为是辅音的帧(时间区间),对该帧中的各时刻n,将比时刻n早与该帧的基音周期对应的样本数t0的过去的时刻n-t0的信号xn-t_0、该帧的基音增益σ0、规定的常数b0、大于0且小于1的值进行相乘,将相乘后的信号、时刻n的信号xn进行相加,得到包含相加后的信号的信号作为输出信号xnewn。而且,在基音强调部130中,对被判定为不是辅音的帧(时间区间),对该帧中的各时刻n,将比时刻n早与该帧的基音周期对应的样本数t0的过去的时刻n-t0的信号xn-t_0、该帧的基音增益σ0、规定的常数b0进行相乘,将相乘后的信号(b0σ0xn-t_0)(该信号与式(8)的右边的括号内的第2项中γ0=1对应)、时刻n的信号xn进行相加,得到包含相加后的信号(xn+b0σ0xn-t_0)的信号作为输出信号xnewn。
而且,在信号分析信息i0为辅音相似度的指标值的情况下,在基音强调部130中,对该帧中的各时刻n,将比时刻n早与包含信号xn的帧的基音周期对应的样本数t0的过去的时刻n-t0的信号xn-t_0、该帧的基音增益σ0、如下的值b0γ0进行相乘,将相乘后的信号(b0σ0γ0xn-t_0)、时刻n的信号xn进行相加,得到包含相加后的信号(xn+b0γ0σ0xn-t_0)的信号作为输出信号xnewn:所述值b0γ0是随着该帧越像辅音则越小的值。
通过该基音强调处理,可以得到即使是辅音的帧也降低不适感,而且,即使在辅音的帧与除此以外的帧频繁切换的情况下,降低帧间的基音成分的强调的程度的变动造成的不适感的效果。
[基音强调处理(s130)的第1变形例]
接着,对语音基音强调装置100进行的基音强调处理的第1变形例和与其关联的处理进行说明。
第1变形例的语音基音强调装置100还具备基音信息存储部150。而且,在信号特征分析处理(s170)中利用基音信息存储部150的情况下,也可以共用。
基音强调部130接受基音分析部120输出的基音周期和基音增益、信号特征分析部170输出的信号分析信息、以及被输入到语音基音强调装置100的当前帧的时间区域的声音信号。基音强调部130对当前帧的声音信号样本串,输出将与当前帧的基音周期t0对应的基音成分、与过去的帧的基音周期对应的基音成分强调而得到的输出信号的样本串。这时,基音强调部130对于与当前帧的基音周期t0对应的基音成分,以基于当前帧的基音增益σ0的强调的程度在辅音的帧比辅音以外的帧小的方式进行强调。而且,在以下的说明中,将从当前帧看s个之前的帧(过去s个的帧)的基音周期以及基音增益分别记述为t-s以及σ-s。
在基音信息存储部150中,存储从前1帧至过去α个的帧的基音周期t-1,...,t-α和基音增益σ-1,...,σ-α。其中,α是预先决定的正整数,例如为1。而且,如前所述,在信号特征分析处理(s170)和基音强调处理(s130)中也可以共用基音信息存储部150。可以是ε>α,也可以是ε<α,也可以设为ε=α而最大限度共用重复的部分。
基音强调部130使用被输入的当前帧的基音增益σ0、从基音信息存储部150读出的过去α个的帧的基音增益σ-α、被输入的当前帧的基音周期t0、从基音信息存储部150读出的过去α个的帧的基音周期t-α、被输入的当前帧的信号分析信息i0,进行对于当前帧的声音信号的样本串的基音强调处理。
以下,说明具体例。
(基音强调处理的第1变形例的具体例1)
在该具体例中,基音强调部130的构成被输入的当前帧的声音信号的样本串的各样本xn(l-n≤n≤l-1),通过以下的式(10)得到输出信号xnewn,由此得到n个样本xnewl―n,…,xnewl―1的当前帧的输出信号的样本串。
[数5]
其中,在信号分析信息i0为表示是否是辅音的信息的情况下,衰减系数γ0在当前帧的信号分析信息i0表示是辅音的情况下为大于0且小于1的预先决定的值(0<γ0<1),在当前帧的信号分析信息i0表示不是辅音的情况下为1(γ0=1)。
而且,在当前帧的信号分析信息i0为辅音相似度的指标值的情况下,衰减系数γ0为根据当前帧的信号分析信息i0决定的值,且辅音相似度的指标值i0越大则衰减系数γ0是越小的值。更具体地说,例如,辅音相似度的指标值i0越大则衰减系数γ0是越小的值,并且,设为在辅音相似度的指标值i0为该指标值可取的最小值的情况下为γ0=1,并且,在辅音相似度的指标值i0为该指标值可取的最大值的情况下为γ0=0那样的、通过规定的函数γ0=f(i0)求的值即可。
而且,式(10)的a是通过下记的式(11)求的振幅校正系数。
[数6]
而且,b0和b-α是预先决定的小于1的值,例如是3/4和1/4。
(基音强调处理的第1变形例的具体例2)
在该具体例中,基音强调部130对构成被输入的当前帧的声音信号的样本串的各样本xn(l-n≤n≤l-1),通过以下的式(12)得到输出信号xnewn,由此得到n个样本xnewl―n,…,xnewl―1的当前帧的输出信号的样本串。
[数7]
其中,衰减系数γ0与具体例1相同,衰减系数γ-α是过去α个的帧的衰减系数。在该具体例中使用过去α个的帧衰减系数γ-α,所以该具体例的语音基音强调装置100还具有衰减系数存储部180。在衰减系数存储部180中,存储从前1帧至过去α个的帧的衰减系数γ-1,...,γ-α。
而且,式(12)的a是通过下记的式(13)求出的振幅校正系数。
[数8]
而且,b0和b-α是预先决定的小于1的值,例如是3/4和1/4。
(基音强调处理的第1变形例的具体例3)
在该具体例中,基音强调部130构成被输入的当前帧的声音信号的样本串的各样本xn(l-n≤n≤l-1),通过以下的式(14)得到输出信号xnewn,由此得到n个样本xnewl―n,…,xnewl―1的当前帧的输出信号的样本串。
[数9]
其中,衰减系数γ0与具体例1或2相同。
而且,式(14)的a是通过下记的式(15)求的振幅校正系数。
[数10]
而且,b0和b-α是预先决定的小于1的值,例如是3/4和1/4。
该具体例是取代具体例2的过去α个的帧的衰减系数γ-α,而使用当前帧的衰减系数γ0的结构。通过设为该结构,语音基音强调装置100可以不具有衰减系数存储部180即可。
第1变形例的基音强调处理是不仅考虑基音周期,还考虑基音增益的强调基音成分的处理,并且,是对于是辅音的帧的基音成分,以比不是辅音的帧的基音成分小的强调的程度强调基音成分的处理,并且是一边强调与当前帧的基音周期t0对应的基音成分,一边还以比该基音成分稍小的强调的程度强调与过去的帧中的基音周期t-α对应的基音成分的处理。通过第1变形例的基音强调处理,即使在每个短的时间区间(帧)实施基音强调处理的情况下,也可以得到降低帧间的基音周期的变动导致的不连续性的效果。
而且,在信号分析信息i0是表示是否为辅音的信息的情况下,优选在式(10)中设为b0γ0>b-α,优选在式(12)中设为b0γ0>b-αγ-α,优选在式(14)中设为b0>b―α。但是,即使在式(10)中设为b0γ0≤b-α,或在式(12)中设为b0γ0≤b-αγ-α,或在式(14)中设为b0≤b―α,也可以产生降低帧间的基音周期的变动造成的不连续性的效果。
而且,在信号分析信息i0为辅音相似度的指标值的情况下,优选在式(10)、式(12)、式(14)中设为b0>b―α。但是,即使设为b0≤b-α,也可以产生降低帧间的基音周期的变动造成的不连续性的效果。
而且,通过式(11)、式(13)和式(15)求的振幅校正系数a,在假定为当前帧的基音周期t0和过去α个的帧的基音周期t-α为足够近的值时,基音成分的能量在基音强调前后被保存。
而且,基音信息存储部150更新存储内容,使得可以将当前帧的基音周期和基音增益,在以后的帧的基音强调部130的处理中作为过去的帧的基音周期和基音增益使用。
而且,在具备衰减系数存储部180的情况下,更新存储内容,使得可以将当前帧的衰减系数在以后的帧的基音强调部130的处理中作为过去的帧的衰减系数使用。
[基音强调处理(s130)的第2变形例]
在第1变形例中,对当前帧的声音信号样本串,将与当前帧的基音周期t0对应的基音成分、与过去的一个帧的基音周期对应的基音成分强调而得到了输出信号的样本串,但是也可以强调与过去的多个(2个以上)的帧的基音周期对应的基音成分。以下,作为强调与过去的多个帧的基音周期对应的基音成分的一例,对强调与过去的两个帧的基音周期对应的基音成分的例子,说明与第1变形例的不同点。
在基音信息存储部150中预先存储由当前帧至过去β个的帧的基音周期t-1,...,t-α,...,t-β和基音增益σ-1,...,σ-α,...,σ-β。其中,β是大于α的预先决定的正整数。例如,α为1,β为2。而且,如前所述,也可以在信号特征分析处理(s170)和基音强调处理(s130)中共用基音信息存储部150。可以是ε>β,可以是ε<β,也可以设为ε=β而最大限度共用重复的部分。
基音强调部130使用被输入的当前帧的基音增益σ0、从基音信息存储部150读出的过去α个的帧的基音增益σ-α、从基音信息存储部150读出的过去β个的帧的基音增益σ-β、被输入的当前帧的基音周期t0、从基音信息存储部150读出的过去α个的帧的基音周期t-α、从基音信息存储部150读出的过去β个的帧的基音周期t-β、以及被输入的当前帧的信号分析信息i0,进行对于当前帧的声音信号的样本串的基音强调处理。
以下,说明具体例。
(基音强调处理的第2变形例的具体例1)
在该具体例中,基音强调部130对构成被输入的当前帧的声音信号的样本串的各样本xn(l-n≤n≤l-1),通过以下的式(16)得到输出信号xnewn,从而得到n个样本xnewl―n,…,xnewl―1的当前帧的输出信号的样本串。
[数11]
其中,在信号分析信息i0为表示是否为辅音的信息的情况下,衰减系数γ0在当前帧的信号分析信息i0表示是辅音的情况下为大于0且小于1的预先决定的值(0<γ0<1),在当前帧的信号分析信息i0表示不是辅音的情况下为1(γ0=1)。
而且,在当前帧的信号分析信息i0为辅音相似度的指标值的情况下,衰减系数γ0是根据当前帧的信号分析信息i0决定的值,且辅音相似度的指标值i0越大则衰减系数γ0是越小的值。更具体地说,例如,辅音相似度的指标值i0越大则衰减系数γ0是越小的值,并且设为在辅音相似度的指标值i0为该指标值可取的最小值的情况下变为γ0=1,并且,在辅音相似度的指标值i0为该指标值可取的最大值的情况下变为γ0=0那样,通过规定的函数γ0=f(i0)求出即可。
而且,式(16)的a为通过下记的式(17)求的振幅校正系数。
[数12]
其中、
e=2b0b-ασ0σ-αγ0
f=2b0b-βσ0σ-βγ0
g=2b-αb-βσ-ασ-β
而且,b0、b-α和b-β是预先决定的小于1的值,例如是3/4、3/16和1/16。
(基音强调处理的第2变形例的具体例2)
在该具体例中,基音强调部130对构成被输入的当前帧的声音信号的样本串的各样本xn(l-n≤n≤l-1),通过以下的式(18)得到输出信号xnewn,由此得到n个样本xnewl―n,…,xnewl―1的当前帧的输出信号的样本串。
[数13]
其中,衰减系数γ0与具体例1相同,衰减系数γ-α是过去α个的帧的衰减系数,衰减系数γ-β是过去β个的帧的衰减系数。在该具体例中使用过去α个的帧衰减系数γ-α和过去β个的帧衰减系数γ-β,所以该具体例的语音基音强调装置100还具有衰减系数存储部180。在衰减系数存储部180中,存储从前1帧至过去β个的帧的衰减系数γ-1,...,γ-β。
而且,式(18)的a是通过下记的式(19)求出的振幅校正系数。
[数14]
其中、
e=2b0b-ασ0σ-αγ0γ-α
f=2b0b-βσ0σ-βγ0γ-β
g=2b-αb-βσ-ασ-βγ-αγ-β
而且,b0、b-α和b-β是预先决定的小于1的值,例如是3/4、3/16和1/16。
(基音强调处理的第2变形例的具体例3)
在该具体例中,基音强调部130对构成被输入的当前帧的声音信号的样本串的各样本xn(l-n≤n≤l-1),通过以下的式(20)得到输出信号xnewn,由此得到n个样本xnewl―n,…,xnewl―1的当前帧的输出信号的样本串。
[式15]
其中,衰减系数γ0与具体例1或2相同。
而且,式(20)的a是通过下记的式(21)求的振幅校正系数。
[数16]
其中、
而且,b0、b-α和b-β是预先决定的小于1的值,例如是3/4、3/16和1/16。
该具体例是取代具体例2的过去α个的帧的衰减系数γ-α和过去β个的帧的衰减系数γ-β而使用当前帧的衰减系数γ0的结构。通过设为该结构,可以使得语音基音强调装置100不具有衰减系数存储部180即可。
第2变形例的基音强调处理也与第1变形例的基音强调处理一样,是不仅考虑基音周期还考虑了基音增益的强调基音成分的处理,并且,是对于是辅音的帧的基音成分以小于不是辅音的帧的基音成分的强调的程度强调基音成分的处理,并且是一边强调与当前帧的基音周期t0对应的基音成分,一边还与该基音成分相比,以稍小的强调的程度对与过去的帧中的基音周期对应的基音成分进行强调的处理。通过第2变形例的基音强调处理,即使在对较短的每个时间区间(帧)实施基音强调处理的情况下,也可以得到降低帧间的基音周期的变动造成的不连续性的效果。
而且,在信号分析信息i0是表示是否为辅音的信息的情况下,在式(16)中优选设为b0γ0>b-α>b-β,在式(18)中优选设为b0γ0>b-αγ-α>b-βγ-β,在式(20)中优选设为b0>b―α>b-β。但是,即使在式(16)中设为b0γ0≤b-α或b0γ0≤b-β或b-α≤b-β,或者在式(18)中设为b0γ0≤b-αγ-α或b0γ0≤b-βγ-β或b-αγ-α≤b-βγ-β,或者在式(20)中设为b0≤b―α或b0≤b-β或b-α≤b-β,也可以产生降低帧间的基音周期的变动造成的不连续性的效果。
而且,在信号分析信息i0为辅音相似度的指标值的情况下,在式(16)、式(18)、式(20)中优选设为b0>b-α>b-β。但是,即使不满足该大小关系,也可以产生降低帧间的基音周期的变动造成的不连续性的效果。
而且,通过式(17)、式(19)、式(21)求的振幅校正系数a是,在假定了当前帧的基音周期t0和过去α个的帧的基音周期t-α和过去β个的帧的基音周期t-β为足够近的值时,基音成分的能量在基音强调前后被保存的系数。
(基音强调处理的其它的变形例)
而且,振幅校正系数a也可以不是通过式(9)、式(11)、式(13)、式(15)、式(17)、式(19)、或式(21)求出的值,而使用预先决定的1以上的值。在将振幅校正系数a设为1的情况下,基音强调部130也可以通过不包含得到上述的输出信号xnewn的式中的1/a(即,式(8)、式(10)、式(12)、式(14)、式(16)、式(18)或式(20)的1/a)那样的式子得到输出信号xnewn。
而且,可以取代对被输入的声音信号的各样本相加的基于相当于各基音周期之前的样本的值,例如使用通过了低通滤波器的声音信号中的相当于各基音周期之前的样本,也可以进行与低通滤波器等效的处理。
而且,在基音增益小于规定的阈值的情况下,也可以进行不包含该基音成分的基音强调处理。例如,也可以设为在当前帧的基音增益σ0小于规定的阈值的情况下,不将与当前帧的基音周期t0对应的基音成分包含在输出信号中,在过去的帧的基音增益小于规定的阈值的情况下,不将与该过去的帧的基音周期对应的基音成分包含在输出信号中的结构。
而且,也可以设为在信号特征分析部170中得到辅音相似度的指标值,作为信号分析信息i0输出到基音强调部130,在基音强调部130中,根据辅音相似度的指标值和阈值的大小关系使强调程度(衰减系数γ0的大小)在2阶段不同的结构。
<第二实施方式>
以与第一实施方式不同的部分为中心进行说明。
在本实施方式中,取代在第一实施方式中说明的辅音相似度的指标值,得到频谱包络的平坦程度的指标值,作为辅音相似度的指标值。与元音相比,辅音的频谱有频谱包络变得平坦的性质。在本实施方式中,利用该性质,使用频谱包络的平坦程度的指标值作为辅音相似度的指标值。
信号特征分析处理(s170)的内容与第一实施方式不同。
[信号特征分析处理(s170)]
在信号特征分析部170中,与第一实施方式一样被输入来源于时间区域的声音信号的信息。
信号特征分析部170得到表示当前帧是否为辅音的信息、或者当前帧的辅音相似度的指标值,作为信号分析信息i0输出到基音强调部130。而且,在本实施方式中,如前所述,使用当前帧的频谱包络的平坦程度的指标值作为当前帧的辅音相似度的指标值。而且,在本实施方式中,使用表示当前帧的频谱包络是否平坦的信息作为表示当前帧是否为辅音的信息。
信号特征分析部170例如通过下记的例子2-1至例2-7的信号特征分析处理得到信号分析信息i0。
(信号特征分析处理的例子2-1:将频谱包络的平坦程度的指标值设为信号分析信息的例子其1)
在该例中,信号特征分析部170首先从包含被输入的n个时间区域的声音信号样本的最新的j个声音信号样本的样本串得到t次的lsp参数θ[1],θ[2],…,θ[t](step2-1-1)。信号特征分析部170接着使用在step2-1-1中得到的t次的lsp参数θ[1],θ[2],…,θ[t],得到下记的指标q作为当前帧的频谱包络的平坦程度的指标值(为了方便,也称为“辅音相似度的第2-1的指标值”)(step2-1-2)。
[数17]
其中、
(信号特征分析处理的例子2-2:将频谱包络的平坦程度的指标值设为信号分析信息的例子其2)
在该例中,信号特征分析部170首先从包含被输入的n个时间区域的声音信号样本的最新的j个声音信号样本的样本串得到t次的lsp参数θ[1],θ[2],…,θ[t](step2-2-1)。信号特征分析部170接着使用在step2-2-1中得到的t次的lsp参数θ[1],θ[2],…,θ[t],得到相邻的lsp参数的间隔的最小值,即,下记的指标q',作为当前帧的频谱包络的平坦程度的指标值(为了方便,也称为“辅音相似度的第2-2的指标值”)(step2-2-2)。
[数18]
(信号特征分析处理的例子2-3:将频谱包络的平坦程度的指标值设为信号分析信息的例子其3)
在该例中,信号特征分析部170首先从包含被输入的n个时间区域的声音信号样本的最新的j个声音信号样本的样本串得到t次的lsp参数θ[1],θ[2],…,θ[t](step2-3-1)。信号特征分析部170接着使用在step2-3-1中得到的t次的lsp参数θ[1],θ[2],…,θ[t],得到相邻的lsp参数的间隔的值与最低次的lsp参数的值中的最小值,即,下记的指标q”,作为当前帧的频谱包络的平坦程度的指标值(为了方便,也称为“辅音相似度的第2-3的指标值”)(step2-3-2)。
[数19]
(信号特征分析处理的例子2-4:将频谱包络的平坦程度的指标值设为信号分析信息的例子其4)
在该例中,信号特征分析部170首先从包含被输入的n个时间区域的声音信号样本的最新的j个声音信号样本的样本串得到p次的parcor系数k[1],k[2],…,k[p](step2-4-1)。信号特征分析部170接着使用在step2-4-1中得到的p次的parcor系数k[1],k[2],…,k[p],得到下记的指标q”'作为当前帧的频谱包络的平坦程度的指标值(为了方便,也称为“辅音相似度的第2-4的指标值”)(step2-4-2)。
[数20]
(信号特征分析处理的例子2-5:将组合了多个指标值的指标值设为信号分析信息的例子)
在该例中,信号特征分析部170通过例2-1~例2-4的方法,得到辅音相似度的第2-1~第2-4的指标值(step2-5-1)。信号特征分析部170进一步通过对step2-5-1中得到的辅音相似度的第2-1~第2-4的指标值进行加权相加,得到如下的值作为当前帧的频谱包络的平坦程度的指标值(为了方便,也称为“辅音相似度的第2-5的指标值”),输出得到的第2-5的指标值作为信号分析信息i0:所述第2-5的指标值是随着第2-1的指标值变大而变大、且随着第2-2的指标值变大而变大、且随着第2-3的指标值变大而变大、且随着第2-4的指标值变大而变大的值(step2-5-2)。
如前所述,辅音相似度的第2-1~第2-4的指标值分别是表示频谱包络的平坦程度的指标。在该例中,通过将4个指标值组合,可以更灵活地设定表示频谱包络的平坦程度的指标值。
而且,信号特征分析部170也可以得到辅音相似度的第2-1~第2-4的指标值中的至少2个(step2-5-1')。在该情况下,信号特征分析部170也可以通过对在step2-5-1'中得到的至少2个辅音相似度的指标值进行加权加法,得到如下的值作为当前帧的辅音相似度的第2-5的指标值,输出得到的第2-5的指标值作为信号分析信息i0:所述第2-5的指标值是分别随着step2-5-1'中得到的指标值变大而变大的值(step2-5-2')。
在信号特征分析处理的例子2-1~例2-5中,说明了将辅音相似度的指标值(频谱包络的平坦程度的指标值)设为信号分析信息的例子。从这里开始,说明将表示是否为辅音的信息(表示频谱包络是否平坦的信息)设为信号分析信息的例子。
(信号特征分析处理的例子2-6:将表示频谱包络是否平坦的信息设为信号分析信息的例子其1)
在该例中,信号特征分析部170首先通过与例2-1~例2-5的任意一个相同的方法,得到当前帧的辅音相似度的第2-1~第2-5的指标值的任意一个(step2-6-1)。信号特征分析部170接着在step2-6-1中得到的指标值为预先决定的阈值以上或者超过阈值的情况下,将表示当前帧为辅音的信息(为了方便,也将与“第2-1的指标值”~“第2-5的指标值”对应的“表示当前帧是否为辅音的信息”分别称为“第2-1的信息”~“第2-5的信息”)作为信号分析信息i0输出,在并非如此的情况下,将表示当前帧不是辅音的第2-1~第2-5的信息任意一个作为信号分析信息i0输出(step2-6-2)。
(信号特征分析处理的例子2-7:将表示频谱包络是否平坦的信息设为信号分析信息的例子其2)
在该例中,信号特征分析部170首先通过与例2-1~例2-4相同的方法,得到当前帧的辅音相似度的第2-1~第2-4的指标值(step2-7-1)。接着,信号特征分析部170根据在step2-7-1中得到的4个辅音相似度的第2-1~第2-4的指标值的每一个与预先决定的阈值的大小关系,对各辅音相似度的第2-1~第2-4的指标值,得到表示当前帧为辅音的信息、或者表示当前帧不是辅音的信息(step2-7-2)。而且,阈值设为对4个第2-1~第2-4的指标值的每一个进行设定,也将与第2-1~第2-4的指标值对应的表示当前帧是否为辅音的信息分别称为第2-1~第2-4的信息。例如,在第2-1的指标值为预先决定的阈值以上或者超过阈值的情况下,得到表示当前帧为辅音的第2-1的信息,在并非如此的情况下,得到表示当前帧不是辅音的第2-1的信息。同样,根据第2-2~第2-4的指标值与预先决定的阈值的大小关系得到第2-2~第2-4的信息。
信号特征分析部170根据4个第2-1~第2-4的信息的逻辑运算,得到表示当前帧为辅音的信息(为了方便,也称为“第2-6的信息”)、或者表示当前帧不是辅音的第2-6的信息(step2-7-3)。
(逻辑运算的例子1)
例如,信号特征分析部170在第2-1~第2-4的信息全都表示是辅音的情况下,输出表示当前帧为辅音的第2-6的信息作为信号分析信息i0,在并非如此的情况下,输出表示当前帧不是辅音的第2-6的信息作为信号分析信息i0。
(逻辑运算的例子2)
而且,例如,信号特征分析部170在第2-1~第2-4的信息的任意一个表示是辅音的情况下,输出表示当前帧为辅音的第2-6的信息作为信号分析信息i0,在并非如此的情况下,输出表示当前帧不是辅音的第2-6的信息作为信号分析信息i0。
(逻辑运算的例子3)
而且,例如,信号特征分析部170在第2-1~第2-2的信息的任意一个表示是辅音、并且,第2-3~第2-4的信息的任意一个表示是辅音的情况下(使用“或”和“与”的组合的情况下),输出表示当前帧为辅音的第2-6的信息作为信号分析信息i0,在并非如此的情况下,输出表示当前帧不是辅音的第2-6的信息作为信号分析信息i0。
而且,第2-1~第2-4的信息的逻辑运算不限于上述的逻辑运算的例子1~3,只要适当设定,使得解码后的声音信号被更自然地感受即可。
而且,信号特征分析部170也可以得到辅音相似度的第2-1~第2-4的指标值中的至少2个(step2-7-1')。在该情况下,信号特征分析部170也可以根据在step2-7-1'中得到的至少2个辅音相似度的指标值的每一个与预先决定的阈值的大小关系,对各辅音相似度的指标值,得到表示当前帧为辅音的信息、或者表示当前帧不是辅音的至少2个信息(step2-7-2')。进而,信号特征分析部170也可以根据在step2-7-2'中得到的至少2个信息的逻辑运算,得到表示当前帧为辅音的第2-6的信息、或者表示当前帧不是辅音的第2-6的信息(step2-7-3')。
通过这样的处理,信号特征分析部170输出辅音相似度的指标值或者表示是否为辅音的信息作为信号分析信息i0。
<基音强调部130>
基音强调部130中的基音强调处理(s130)与第一实施方式相同。
即,本实施方式的基音强调部130在信号分析信息i0表示频谱包络是否平坦(是否为辅音)的情况下,对判定为频谱包络(更相信地说,包含信号xn的帧的频谱包络)是平坦(为辅音)的帧(时间区间),对帧的各时刻n,将比时刻n早与该帧的基音周期对应的样本数t0的过去的时刻n-t0的信号xn-t_0、该帧的基音增益σ0、规定的常数b0、大于0且小于1的值进行相乘,将相乘后的信号与时刻n的信号xn进行相加,得到包含相加后的信号的信号作为输出信号xnewn。而且,基音强调部130对于被判定为频谱包络是不平坦(不是辅音)的帧(时间区间),对帧的各时刻n,将比时刻n早与该帧的基音周期对应的样本数t0的过去的时刻n-t0的信号xn-t_0、该帧的基音增益σ0、规定的常数b0进行相乘,将相乘后的信号(b0σ0xn-t_0)(该信号在式(8)的右边的括号内的第2项中与γ0=1对应)与时刻n的信号xn进行相加,得到包含相加后的信号(xn+b0σ0xn-t_0)的信号作为输出信号xnewn。
而且,在基音强调部130中,在信号分析信息i0为频谱包络的平坦程度的指标值(辅音相似度的指标值)的情况下,对帧的各时刻n,将比时刻n早与包含信号xn的帧的基音周期对应的样本数t0的过去的时刻n-t0的信号xn-t_0、该帧的基音增益σ0、和如下的值b0γ0进行相乘,将相乘后的信号(b0σ0γ0xn-t_0)和时刻n的信号xn进行相加,得到包含相加后的信号(xn+b0γ0σ0xn-t_0)的信号作为输出信号xnewn:所述值b0γ0是随着该帧的频谱包络越平坦(帧越像辅音)则越小的值。
<效果>
通过上述的结构,可以得到与第1实施方式同样的效果。
<第三实施方式>
以与第一实施方式不同的部分为中心进行说明。
在本实施方式中,除了在第一实施方式中说明的辅音相似度的指标值,还使用在第二实施方式中说明的频谱包络的平坦程度的指标值,得到辅音相似度的指标值或者表示是否为辅音的信息。
信号特征分析处理(s170)的内容与第一实施方式不同。在以下,为了方便,将在第一实施方式中说明的辅音相似度的第1-1~第1-3的指标值的任意一个称为辅音相似度的第1指标值,将在第二实施方式中说明的频谱包络的平坦程度的指标值即辅音相似度的第2-1~第2-5的指标值的任意一个称为第2指标值,将使用辅音相似度的第1指标值和辅音相似度的第2指标值在信号特征分析处理(s170)中得到辅音相似度的指标值称为辅音相似度的第3指标值。
[信号特征分析处理(s170)]
信号特征分析部170根据在第一实施方式中说明的辅音相似度的指标值和在第二实施方式中说明的频谱包络的平坦程度的指标值,得到辅音相似度的指标值或者表示是否为辅音的信息,作为信号分析信息输出到基音强调部130。信号特征分析部170例如通过下记的例子3-1至例3-4的信号特征分析处理得到信号分析信息i0。
(信号特征分析处理的例子3-1:将辅音相似度的第1指标值和频谱包络的平坦程度的指标值(辅音相似度的第2指标值)组合后的指标值设为辅音相似度的第3指标值,将第3指标值本身设为信号分析信息的例子)
在该例中,信号特征分析部170首先通过与在第一实施方式中说明的例1至3的任意一个相同的方法,得到当前帧的辅音相似度的第1指标值(step3-1-1)。而且,信号特征分析部170通过在第二实施方式中说明的例2-1至例2-5的任意一个方法,得到当前帧的频谱包络的平坦程度的指标值(辅音相似度的第2指标值)(step3-1-2)。信号特征分析部170进一步通过对在step3-1-1中得到的辅音相似度的第1指标值和在step3-1-2中得到的频谱包络的平坦程度的指标值(辅音相似度的第2指标值)进行加权相加等,得到如下值作为当前帧的辅音相似度的第3指标值,输出得到的辅音相似度的第3指标值作为信号分析信息i0:所述第3指标值是随着辅音相似度的第1指标值变大而变大、且随着频谱包络的平坦程度的指标值(辅音相似度的第2指标值)变大而变大的值(step3-1-3)。
(信号特征分析处理的例子3-2:将对辅音相似度的第1指标值和频谱包络的平坦程度的指标值(辅音相似度的第2指标值)组合后的第3指标值进行阈值判定而得到的信息设为信号分析信息的例子)
在该例中,信号特征分析部170首先通过与例3-1相同的方法,得到当前帧的辅音相似度的第3指标值(step3-2-1)。信号特征分析部170接着在step3-2-1中得到的辅音相似度的第3指标值为预先决定的阈值以上或者超过阈值的情况下,输出表示当前帧为辅音的第3信息作为信号分析信息i0,在并非如此的情况下,输出表示当前帧不是辅音的第3信息作为信号分析信息i0。
(信号特征分析处理的例子3-3:将表示是否为辅音或者频谱包络是否平坦的信息设为信号分析信息的例子)
在该例中,信号特征分析部170首先通过与在第一实施方式中说明的例1至例3的任意一个相同的方法,得到当前帧的辅音相似度的第1指标值(step3-3-1)。信号特征分析部170在step3-3-1中得到的第1指标值为预先决定的阈值以上或者超过阈值的情况下,得到表示当前帧为辅音的第1信息,在并非如此的情况下,得到表示当前帧不是辅音的第1信息(step3-3-2)。而且,信号特征分析部170通过在第二实施方式中说明的例2-1至例2-5的任意一个方法,得到当前帧的频谱包络的平坦程度的指标值(辅音相似度的第2指标值)(step3-3-3)。信号特征分析部170在step3-3-3中得到的第2指标值为预先决定的阈值以上或者超过阈值的情况下,得到表示当前帧的频谱包络是平坦(为辅音)的第2信息,在并非如此的情况下,得到表示当前帧的频谱包络不平坦(不是辅音)的第2信息(step3-3-4)。信号特征分析部170进一步在step3-3-2中得到的第1信息表示是辅音或者在step3-3-4中得到的第2信息表示频谱包络是平坦(为辅音)的情况下,输出表示当前帧为辅音的第3信息作为信号分析信息i0,在并非如此的情况下,输出表示当前帧不是辅音的第3信息作为信号分析信息i0。
(信号特征分析处理的例子3-4:将表示是辅音并且频谱包络是否平坦的信息设为信号分析信息的例子)
在该例中,信号特征分析部170首先通过与在第一实施方式中说明的例1至例3的任意一个相同的方法,得到当前帧的辅音相似度的第1指标值(step3-4-1)。信号特征分析部170在step3-4-1中得到的指标值为预先决定的阈值以上或者超过阈值的情况下,得到表示当前帧为辅音的第1信息,在并非如此的情况下,得到表示当前帧不是辅音的第1信息(step3-4-2)。而且,信号特征分析部170通过在第二实施方式中说明的例2-1至例2-5的任意一个方法,得到当前帧的频谱包络的平坦程度的指标值(辅音相似度的第2指标值)(step3-4-3)。信号特征分析部170在step3-4-3中得到的指标值为预先决定的阈值以上或者超过阈值的情况下,得到表示当前帧的频谱包络是平坦(为辅音)的第2信息,在并非如此的情况下,得到表示当前帧的频谱包络不平坦(不是辅音)的第2信息(step3-4-4)。信号特征分析部170进一步在step3-4-2中得到的第1信息表示是辅音并且在step3-4-4中得到的第2信息表示频谱包络是平坦的情况下,将表示当前帧为辅音的第3信息作为信号分析信息i0输出,在并非如此的情况下,将表示当前帧不是辅音的第3信息作为信号分析信息i0输出。
<基音强调部130>
基音强调部130中的基音强调处理(s130)与第一实施方式相同。
即,本实施方式的基音强调部130在信号分析信息i0表示是否为辅音的情况下(第3信息的情况下),对于判定为是辅音或者/以及信号xn的频谱包络是平坦的帧(时间区间),对该帧的各时刻n,将比时刻n早与该帧的基音周期对应的样本数t0的过去的时刻n-t0的信号xn-t_0、该帧的基音增益σ0、规定的常数b0、大于0且小于1的值进行相乘,将相乘后的信号与时刻n的信号xn进行相加,得到包含相加后的信号的信号作为输出信号xnewn。而且,基音强调部130对成为除此以外的判定的帧,对该帧的各时刻n,将比时刻n早与该帧的基音周期对应的样本数t0的过去的时刻n-t0的信号xn-t_0、该帧的基音增益σ0、规定的常数b0进行相乘,将相乘后的信号(b0σ0xn-t_0)(该信号与式(8)的右边的括号内的第2项中γ0=1对应)和时刻n的信号xn进行相加,得到包含相加后的信号(xn+b0σ0xn-t_0)的信号作为输出信号xnewn(与例3-3,3-4对应)。而且,在例3-2中,对将辅音相似度的第1指标值和频谱包络的平坦程度的指标值(辅音相似度的第2指标值)组合后的第3指标值进行阈值判定,该阈值判定相当于判定是否为辅音,或者/以及,信号xn的频谱包络是否平坦。
而且,在基音强调部130中,在信号分析信息i0为辅音相似度的指标值的情况下(第3指标值的情况下),对帧的各时刻n,将比时刻n早与包含信号xn的帧的基音周期对应的样本数t0的过去的时刻n-t0的信号xn-t_0、该帧的基音增益σ0、如下的值b0γ0进行相乘,将相乘后的信号(b0σ0γ0xn-t_0)和时刻n的信号xn进行相加,得到包含相加后的信号(xn+b0γ0σ0xn-t_0)的信号作为输出信号xnewn:所述b0γ0是随着该帧越像辅音则越小且该帧的频谱包络越平坦则越小的值(与例3-1对应)。
<效果>
通过设为这样的结构,可以得到与第一实施方式同样的效果。进而,在本实施系方式中,通过除了考虑第1指标值,还考虑第2指标值(频谱包络的平坦程度的指标值),可以得到更合适的辅音相似度的指标值。
<其它的变形例>
在通过语音基音强调装置100以外进行的解码处理等得到各帧的基音周期、基音增益和信号分析信息的情况下,也可以将语音基音强调装置100设为图3的结构,更加语音基音强调装置100以外得到的基音周期、基音增益和信号分析信息强调基音。图4表示该处理流程。在该情况下,不需要具有第一实施方式、第二实施方式、第三实施方式、以及它们的变形例的语音基音强调装置100所具有的自相关函数计算部110、基音分析部120、信号特征分析部170、自相关函数存储部160,基音强调部130不需要使用基音分析部120输出的基音周期、基音增益和信号特征分析部170输出的信号分析信息,只要使用被输入到语音基音强调装置100的基音周期、基音增益和信号分析信息进行基音强调处理(s130)即可。若设为这样的结构,则语音基音强调装置100自身的运算处理量能够比第一实施方式、第二实施方式、第三实施方式、以及它们的变形例少。但是,第一实施方式、第二实施方式、第三实施方式、以及它们的变形例的语音基音强调装置100不依赖于得到语音基音强调装置100以外的基音周期、基音增益和信号分析信息的频率而可以获得基音周期、基音增益和信号分析信息,所以能够进行以非常短的时间长度的帧为单位的基音强调处理。若为上述的采样频率32khz的例子,则若将n例如设为32,则可以以1ms的帧为单位进行基音强调处理。
而且,在以上的说明中,以对声音信号本身实施基音强调处理作为前提,但是也可以适用本发明,作为非专利文献1中记载的那样的对线性预测残差进行基音强调处理后进行线性预测合成的结构中的、对于线性预测残差的基音强调处理。即,也可以不是对声音信号本身,而是对于对声音信号进行分析或加工而得到的信号等来源于声音信号的信号适用本发明。
本发明不限于上述的实施方式以及变形例。例如,上述的各种处理不仅按照记载而时间序列地被执行,也可以根据执行处理的装置的处理能力或者需要并行地或者单独地被执行。此外,在不脱离本发明的宗旨的范围中能够适当变更。
<程序以及记录介质>
而且,也可以通过计算机实现在上述的实施方式以及变形例中说明的各装置中的各种处理功能。在该情况下,通过程序记述各装置应有的功能的处理内容。然后,通过由计算机执行该程序,在计算机上实现上述各装置中的各种处理功能。
记述了该处理内容的程序可以记录在计算机可读取的记录介质中。作为计算机可读取的记录介质,例如可以是磁记录装置、光盘、光磁记录介质、半导体存储器等任何介质。
而且,该程序的流通例如通过销售、转让、租借等记录了该程序的dvd、cd-rom等便携式记录介质来进行。进而,也可以将该程序存储在服务器计算机的存储装置中,经由网络,通过将该程序从服务器计算机转发到其它计算机,使该程序流通。
执行这样的程序的计算机例如首先将便携式记录介质中记录的程序或者从服务器计算机转发的程序暂时存储在自己的存储装置中。然后,在执行处理时,该计算机读取自己的记录装置中存储的程序,执行按照读取的程序的处理。而且,作为该程序其它执行方式,计算机也可以从便携式记录介质直接读取程序,执行按照该程序的处理,进而,也可以在每次从服务器计算机对该计算机转发程序时,逐次执行按照接受的程序的处理。而且,也可以设为通过不进行从服务器计算机向该计算机的程序的转发,仅通过该执行指令和结果取得来实现处理功能的、所谓asp(applicationserviceprovider,应用服务提供商)型的服务,执行上述的处理的结构。而且,本方式中的程序中,包含供电子计算机的处理用的信息即基于程序的信息(虽然不是对于计算机的直接的指令,但是具有规定计算机的处理的性质的数据等)。
而且,通过在计算机上执行规定的程序来构成本装置,但是也可以硬件性地实现这些处理内容的至少一部分。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



