
 商标分类
商标分类  商标转让
商标转让 
跨数据、信息、知识模态的内容编解码方法及组件与流程
 2021-01-28 13:01:11|
2021-01-28 13:01:11| 274|
274| 起点商标网
起点商标网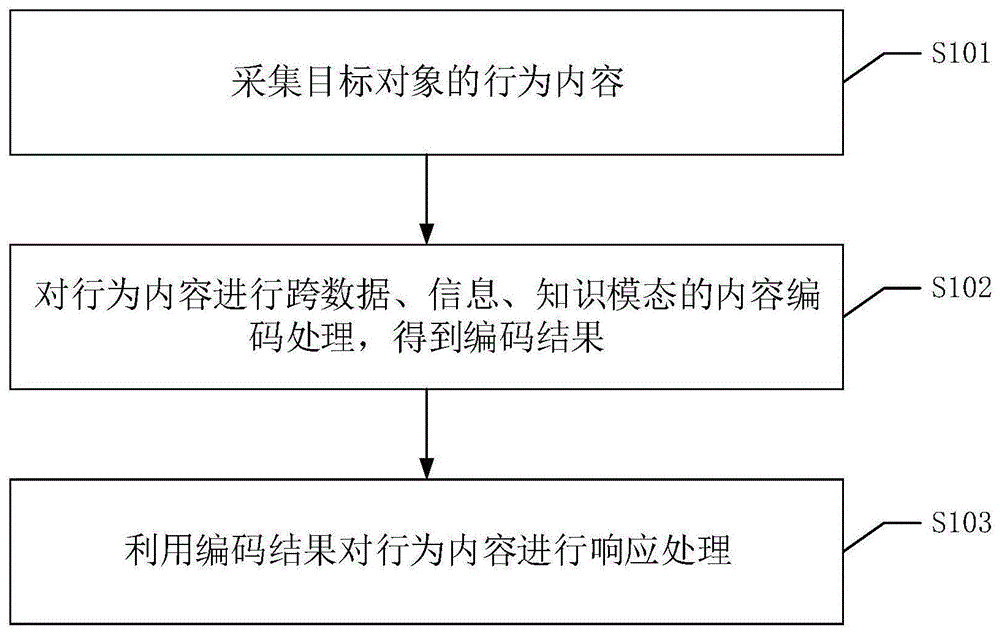
本发明涉及人机交互技术领域,特别是涉及一种跨数据、信息、知识模态的内容编解码方法、装置、设备及可读存储介质。
背景技术:
人机交互指人与机器的交互,本质上是人与计算机的交互。或者从更广泛的角度理解:人机交互指人与含有计算机的机器的交互。例如,计算机对人的行为进行分析并反馈,或根据用户的行为进行响应处理。目前,人机交互用户与含有计算机机器之间的双向通信,以一定的符号和动作来实现,如击键,移动鼠标,显示屏幕上的符号/图形等。人机交互过程:识别交互对象-理解交互对象-把握对象情态-信息适应与反馈等。但是,现有的人机交互往往需要用户控制特定的如键盘、鼠标、触摸屏等输入设备,无法脱离输入设备的限制。
综上所述,如何有效地解决人机交互过程中让用户摆脱输入设备的限制等问题,是目前本领域技术人员急需解决的技术问题。
技术实现要素:
本发明的目的是提供一种跨数据、信息、知识模态的内容编解码方法、装置、设备及可读存储介质,以在人机交互过程中,让用户摆脱输入设备的限制,也能实现有效的人机交互。
为解决上述技术问题,本发明提供如下技术方案:
一种跨数据、信息、知识模态的内容编解码方法,包括:
采集目标对象的行为内容;所述行为内容包括运动内容和/或声音内容;
对所述行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果;
利用所述编码结果对所述行为内容进行响应处理。
优选地,利用所述编码结果对所述行为内容进行响应处理,包括:
生成与所述编码结果对应的目标指令,并执行所述目标指令;
或,将所述编码结果传输至目标设备,以便所述目标设备对所述行为内容进行响应处理。
优选地,所述生成与所述编码结果对应的目标指令,并执行所述目标指令,包括:
生成与所述编码结果对应的设备控制指令;所述设备控制指令包括光标控制指令、功能开关控制指令;
执行所述设备控制指令。
优选地,利用所述编码结果对所述行为内容进行响应处理,包括:
对所述编码结果进行跨数据、信息、知识模态的内容解码处理,得到解码结果;
利用所述解码结果对所述行为内容进行响应处理。
优选地,对所述编码结果进行跨数据、信息、知识模态的内容解码处理,得到解码结果,包括:
若解码目标为数据资源,则转化所述编码结果中的数据资源或信息资源,得到所述解码结果;
若解码目标为信息资源,则转化所述编码结果中的信息资源,得到所述解码结果。
优选地,若解码目标为数据资源,相应地,转化所述编码结果中的数据资源或信息资源,得到所述解码结果,包括:
若所述编码结果与所述解码目标的模态相同,则按照同态映射,对所述编码结果进行映射处理,得到所述解码结果;其中,所述模态相同包括类型和维度均相同;
若所述编码结果与所述解码目标的模态不同,则对所述编码结果进行跨模态映射,得到与所述解码目标同模态的中间结果;按照同态映射,对所述中间结果进行映射处理,得到所述解码结果。
优选地,若所述行为内容为运动内容,所述编码结果包括数据资源和信息资源,所述数据资源包括标量数据资源和矢量数据资源;
相应地,对所述行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果,包括:
将所述行为内容中连续形式的数值直接赋予所述标量数据资源;
将所述行为内容中离散形式的数值按照与阈值的对应关系,确定为所述标量数据资源;
将所述行为内容中绝对形式的方向或位置,直接赋予所述矢量数据资源;
将所述行为内容中相对形式的方向或位置,根据相应的基方向或基位置,得到相对方向或相对位置,并赋予所述矢量数据资源;
将所述行为内容中至少一个部位运动表达信息确定为所述信息资源。
优选地,还包括:
对不同的所述标量数据资源进行相互转换,对所述标量数据资源进行补充;
对不同的所述矢量数据资源进行相互转换,对所述矢量数据资源进行补充;
对所述矢量数据资源和所述标量数据资源进行相互转换,以补充所述数据资源。
优选地,若所述行为内容为声音内容,所述编码结果包括数据资源和信息资源,所述数据资源包括音调数据资源、音色数据资源和音量数据资源;
相应地,对所述行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果,包括:
获取所述声音内容的音频频率,将所述音频频率作为所述音调数据资源;
获取所述声音内容的音频波形,将所述音频波形作为所述音色数据资源;
获取所述声音内容的音频响度,将所述音频响度作为所述音量数据资源;
识别所述声音内容的语音内容,将所述语音内容作为所述信息资源。
优选地,还包括:
对所述行为内容进行预处理,得到剔除无效内容的所述行为内容。
优选地,还包括:
获取所述目标对象的反馈内容,利用所述反馈内容对所述内容编码处理和/或所述内容解码处理进行调优。
一种跨数据、信息、知识模态的内容编解码装置,包括:
行为内容采集模块,用于采集目标对象的行为内容;所述行为内容包括运动内容和/或声音内容;
内容编码模块,用于对所述行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果;
响应处理模块,用于利用所述编码结果对所述行为内容进行响应处理。
一种跨数据、信息、知识模态的内容编解码设备,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序时实现上述跨数据、信息、知识模态的内容编解码方法的步骤。
一种可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述跨数据、信息、知识模态的内容编解码方法的步骤。
应用本发明实施例所提供的方法,采集目标对象的行为内容;行为内容包括运动内容和/或声音内容;对行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果;利用编码结果对行为内容进行响应处理。
在本方法中,首先采集得到目标对象的行为内容,该行为内容可以具体为运动内容和声音内容中的至少一种。然后,对行为内容进行跨数据、信息、知识模态的内容编码处理,可以得到编码结果。最终,根据编码结果对行为内容进行响应处理。如此,便可避免用户必须对类似键盘、鼠标这种输入设备的限制,通过比划一个动作,发出一个声音便可实现人机交互,提升用户体验。
相应地,本发明实施例还提供了与上述跨数据、信息、知识模态的内容编解码方法相对应的跨数据、信息、知识模态的内容编解码装置、设备和可读存储介质,具有上述技术效果,在此不再赘述。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中一种跨数据、信息、知识模态的内容编解码方法的实施流程图;
图2为本发明实施例中一种跨数据、信息、知识模态的内容编解码装置的结构示意图;
图3为本发明实施例中一种跨数据、信息、知识模态的内容编解码设备的结构示意图;
图4为本发明实施例中一种跨数据、信息、知识模态的内容编解码设备的具体结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面结合附图和具体实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参考图1,图1为本发明实施例中一种跨数据、信息、知识模态的内容编解码方法的流程图,该方法包括以下步骤:
s101、采集目标对象的行为内容。
其中,行为内容包括运动内容和/或声音内容。
其中,目标对象可以具体为参与人机交互的用户。
在本实施例中,可以仅采集运动内容,也可仅采集声音内容,也可采集运动内容和声音内容。
其中,运动内容指一切用户在运动过程中产生的内容。该内容不仅仅局限于用户整体的运动(如跑步,游泳),也包括用户单个部位如手、脚、头部等的运动以及多个部位组合的运动(如拍手、弯腰捡东西)。运动内容观测及捕捉方式包括:一种是通过可穿戴式设备直接记录人体各个部位的运动内容;另一种是通过摄像头采集运动的影像资料,再对运动内容进行识别。
声音内容指一切用户在发声过程中产生的内容。该内容不仅仅局限于例如对话这样带有意义的语音,也包括无实际意义但例如纯音乐歌唱,蕴含不同音调、音色和响度的声音。对于声音内容的观测和捕捉可基于麦克风等设备直接记录音频内容。
s102、对行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果。
对行为内容进行内容编码处理即对进行跨数据、信息和知识的编码处理,得到最终的编码结果。具体的,可以针对行为内容中的数据进行编码处理,得到对应的数据、信息或知识;可以针对行为内容中的信息进行编码处理,得到对应的数据、信息或知识;可以针对行为内容中的知识进行编码处理,得到对应的数据、信息或知识。例如,在行为内容中有当前速度和加速度的情况下,可计算出未来某时刻的速度。
也就是说,在本实施例中,编码指将所采集的行为内容从一种形式或格式转换为另一种形式的过程。
一般地,编码结果可以为数据资源、信息资源中的至少一种资源。也就是说,编码结果可以为对行为内容进行编码处理后得到的数据,也可以为对行为内容进行编码处理后得到的信息。
考虑到行为内容包括运动内容和/或声音内容。下面分别针对运动内容、声音内容,对编码过程进行详细说明。
关于运动内容编码:
若行为内容为运动内容,编码结果包括数据资源和信息资源,数据资源包括标量数据资源和矢量数据资源,具体的,运动内容中可以包含多种数据资源,按照观测的部位可以分为:手部运动数据资源dhand,脚部运动数据资源dfeet,头部运动数据资源dhead,身体运动数据资源dbody等等。按照数据资源类型主要可以分为标量数据资源dscalar和矢量数据资源dvector两种。标量数据资源包括并不限于距离ddistance、速度dspeed、加速度dacceleration等等。采集标量数据资源时可分为连续和离散两种形式。矢量数据资源包括并不限于运动的方向ddirection,以及运动的地点dlocation等等。采集矢量数据资源时可分为绝对和相对两种形式。
相应地,步骤s102对行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果,包括:
步骤s102-01、将行为内容中连续形式的数值直接赋予标量数据资源。
连续形式是指将观测到的数值不作任何处理直接赋予该标量数据资源。
ddistance(continuity)=distanceobserverd
dspeed(continuity)=speedobserverd
...
步骤s102-02、将行为内容中离散形式的数值按照与阈值的对应关系,确定为标量数据资源。
离散形式时指设定某一阈值k,当观测的数值超过该阈值时,设定标量数据资源为某一数值,否则设置为另一数值。
...
步骤s102-03、将行为内容中绝对形式的方向或位置,直接赋予矢量数据资源。
绝对形式是指将观测到的方向或位置不经过任何处理,直接赋予该矢量数据资源。
ddirection(absolute)=directionobserved
dlocation(absolute)=locationobserved
...
步骤s102-04、将行为内容中相对形式的方向或位置,根据相应的基方向或基位置,得到相对方向或相对位置,并赋予矢量数据资源。
相对形式是指设定一个基方向或基位置,根据基方向或基位置结合观测到的矢量数据资源得到相对方向或相对位置。
ddirection(relative)=directionobserved-directionmeta
dlocation(relative)=locationobserved-locationmeta
...
步骤s102-05、将行为内容中至少一个部位运动表达信息确定为信息资源。
运动内容中也包含诸多信息资源。信息资源可以由检测到的数据资源带有目的的组合后得到。其中可以是由单一部位运动表达的信息资源,也可以是由多个部位的运动组合表达的信息资源。这些信息资源既可以是普遍认可的运动信息如:微笑、打响指、拍手等等,也可以是由用户自主定义的运动信息,比如某个特定的手势或某种舞蹈等等。
单一部位表达:例如,微笑:ismile,嘴部运动表达的信息资源。即当检测到嘴角运动的方向为斜上方,同时运动的距离约为1厘米时,可以判定用户嘴角上扬,表达微笑这一信息资源。
ddirection=(lip|tdirection(angle_upward))
ddistance=(lip|tdistance(1cm))
ismile=rcombine(ddirection,ddistance)
多个部位组合表达:例如,拍手:iclap,由左手和右手的运动共同表达的信息资源。当检测到左手向右运动,右手向做运动,同时左手和右手最后的位置相同,可以判断用户左右手相撞,表达拍手这一信息资源。
在本发明的一种具体实施例方式中,在编码过程中,还可以对资源进行补充,具体实现过程包括:
步骤一、对不同的标量数据资源进行相互转换,对标量数据资源进行补充。
标量数据资源之间可以互相转化。例如,速度可以由距离除以时间得到,加速度可以由速度的变化量除以时间得到等等。
步骤二、对不同的矢量数据资源进行相互转换,对矢量数据资源进行补充。
矢量数据资源之间也可以相互转化,例如由位置的变化可以得到运动的方向。
步骤三、对矢量数据资源和标量数据资源进行相互转换,以补充数据资源。
矢量数据资源与标量数据资源之间也可以相互转化,例如由两个地点dlocation的位置差异可以得到目标之间的距离ddistance。
关于声音内容编码:
若行为内容为声音内容,编码结果包括数据资源和信息资源,数据资源包括音调数据资源、音色数据资源和音量数据资源。具体的,声音内容中可以包含多种数据资源,按照声音的特征可以分为:音调数据资源dpitch对应于音频的频率,音色数据资源dtimbre对应于音频的波形,音量数据资源dvolume对应于音频的响度等等。采集声音数据资源时可分为连续和离散两种形式。
相应地,步骤s102对行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果,包括:
步骤s102-21、获取声音内容的音频频率,将音频频率作为音调数据资源。
步骤s102-22、获取声音内容的音频波形,将音频波形作为音色数据资源。
步骤s102-23、获取声音内容的音频响度,将音频响度作为音量数据资源。
步骤s102-24、识别声音内容的语音内容,将语音内容作为信息资源。
为便于描述,下面将上述四个步骤结合起来进行说明。
连续形式指将观测到的数值不作任何处理直接赋予该声音数据资源。
dpitch(continuity)=pitchobserverd
dvolume(continuity)=volumeobserverd
...
离散形式时指设定某一阈值k,当观测的数值超过该阈值时,设定数据资源为某一数值,否则设置为另一数值。
...
声音内容中也包含多种信息资源。对于有具体意义的语音内容,言语中自然蕴含着多种信息资源,通过语音识别即可获得,在此不过多讨论。
抛开语音的具体语义,从声音的特征中也可以表达出不同的信息资源。例如,若识别到声音的音调较高,音量较高,同时音色和往常有很大差别。则可以判定用户情绪出现了较大波动,声音可能表达愤怒这一信息资源:
dpitch=(user,tpitch(high))
dvolume=(user,tvolume(high))
dtimbre=(user,ttimbre(different))
iangry=rcombine(dtimbre,rcombine(dpitch,dvolume))
完成编码处理后,便可执行步骤s103的操作。
s103、利用编码结果对行为内容进行响应处理。
该编码结果即具体为数据资源、信息资源中的至少一种。基于该编码结果便可针对行为内容进行响应。具体的响应方式可以直接向用户反馈信息,如在显示界面对应输出某个信息,或语音播放一个具体内容。例如,显示用户的当前运动强度,或基于声音内容,输出对话式的应答声音。当然,还可将编码结果传递给其他设备,以便其他设备对行为内容进行响应处理。
特别地,对于一些编码结果可能无法进行直接使用,可通过对编码结果进行解码的方式,得到可以直接使用的解码结果。也就是说,步骤s103可包括:
步骤s103-1、对编码结果进行跨数据、信息、知识模态的内容解码处理,得到解码结果。
需要说明的是,在实施例中,解码并非编码的逆处理,而是指对编码结果进行深入的分析处理。
对编码结果进行解密,不局限与同模态资源的分析,还可进行跨模态分析。具体的,解码过程,包括:
步骤一、若解码目标为数据资源,则转化编码结果中的数据资源或信息资源,得到解码结果。
在本发明的一种具体实施例方式中,若解码目标为数据资源,相应地,步骤一转化编码结果中的数据资源或信息资源,得到解码结果,包括:
步骤1、若编码结果与解码目标的模态相同,则按照同态映射,对编码结果进行映射处理,得到解码结果;其中,模态相同包括类型和维度均相同。
若转化双方的模态相同,即类型和维度相同。则转化过程可以看作一个同态映射f:由编码得到的数据资源映射到目标数据资源。
例如,假设编码得到的数据资源draw和目标数据资源dpurpose均为一维连续的参数,且draw的取值范围为0到10000,dpurpose的取值范围为0到100。则对draw进行百分之一的缩放变换,即转化成了目标可用数据资源dpurpose。
draw=(tnum)
dpurpose=(tnum)
f:tnum→tnum
f(draw)=dpurpose
步骤2、若编码结果与解码目标的模态不同,则对编码结果进行跨模态映射,得到与解码目标同模态的中间结果;按照同态映射,对中间结果进行映射处理,得到解码结果。
对于不同模态的数据资源之间的转化,转化过程可以看作先对编码得到的数据资源draw进行跨模态隐射g,得到与目标数据资源dpurpose相同模态的数据资源(即中间结果),再进行同态映射f得到目标数据资源。模态不同的情形具体可分为数据类型不同和数据维度不同两类。
对于数据类型不同的情况,需要进行类型转化。若编码得到的数据资源draw是数值类型,解码的目标数据资源dpurpose是逻辑类型,则可以设定一个阈值k,将数值大于k的draw设定为true,数值小于等于k的draw设定为false,从而完成由数值型数据向逻辑型数据的转化。
draw=(tnum)
dpurpose=(tlogic)
g:tnum→tlogic
f:tlogic→tlogic
f(g(draw))=dpurpose
对于维度不同的情况,需要进行维度压缩或扩展。若编码得到的数据资源draw是三维数据,而解码对应目标数据资源dpurpose是二维数据。则可以设计由三维空间映射至二维空间的映射g,来完成由draw向dpurpose的维度压缩。
draw=(tnum(dimension=3))
dpurpose=(tnum(dimension=2))
g:r3→r2
g(x,y,z)=(g1(x,y,z),g2(x,y,z))
g1(x,y,z)=x+y+z
g2(x,y,z)=x*y*z
f:tnum→tnum
f(g(draw))=dpurpose
特别地,由解码得到的信息资源也可以转化为解码对应的目标数据资源。目标数据资源按照类型可分为逻辑型数据资源和数值型数据资源。针对这两类情形分别进行讨论。
若目标数据资源为逻辑型数据资源,则可以关联特定的信息资源与特定的逻辑表达,例如信息资源笑代表true,信息资源哭代表false。通过这种信息资源和逻辑表达之间的关联,可以完成由信息资源向目标逻辑型数据资源的转化。
f:i→dlogic
f(iraw)=dpurpose
若目标数据资源为数值型数据资源,则可以关联特定信息资源与某一特定数值。例如,信息资源拍手代表10,拍两次手就代表20。通过这种信息资源和数值之间的关联,可以完成由信息资源向目标逻辑型数据资源的转化。
f:i→dnum
f(i)=10(i=iclap)
f(iraw)=dpurpose
步骤二、若解码目标为信息资源,则转化编码结果中的信息资源,得到解码结果。
若解码的目标为信息资源,可由编码得到的信息资源转化得到。
对于信息资源之间的转化,需要在编码得到的信息资源和目标信息资源之间建立关联。例如,在信息资源中的打响指和目标信息资源中的完成某一操作之间建立联系,则可以完成由信息资源向目标信息资源的转化。
f:i→i
f(i)=ispecified(i=isnap)
f(iraw)=ipurpose
步骤s103-2、利用解码结果对行为内容进行响应处理。
基于解码结果对行为内容进行响应处理,可参照基于编码结果进行响应处理的具体实现方式。
在本发明的一种具体实施方式中,步骤s103可具体包括以下方式的响应处理方式:
方式1:将编码结果传输至目标设备,以便目标设备对行为内容进行响应处理。即将编码结果传递给目标设备,以便目标设备进行响应处理。其中,目标设备可以为其他具体应答能力的设备,如vr设备、智能移动终端、计算等。
方式2:生成与编码结果对应的目标指令,并执行目标指令。即立即针对编码结果进行响应。
关于方式1,可具体包括:
步骤1、生成与编码结果对应的设备控制指令;设备控制指令包括光标控制指令、功能开关控制指令。
其中,功能开关控制指令可具体为耳机的音量开关、歌曲切换开关,vr设备的启动开关、场景缩放开关等。
步骤2、执行设备控制指令。
下面以设备控制指令具有为光标控制指令为例,对上述2个步骤进行详细说明,对于功能开关控制指令的具体实现也可参照与此。
鼠标作为一个计算机输入设备,用于实现用户与计算机交互。用户通过移动鼠标,使计算机屏幕上的光标到达用户希望的位置,再通过点击鼠标按键进行操作(operation)。通俗地来说,就是用户告诉计算机:在哪儿(数据资源),做什么事(信息资源)。不难看出,在这个过程中鼠标并非是不可替代的。利用触摸屏、激光笔等设备,计算机可以直接通过压力感应或光感应获取位置数据和操作信息,以完成用户希望的指令。所以其实不一定仅局限于对由手对鼠标进行操作得到的内容进行解码,任何一种可被观测,可被捕捉的行为都可以生成一段内容,而只要能够对该内容进行解码得到相应的位置数据资源和操作信息资源,就可以实现向计算机传达用户的指令。
关于位置数据资源解码:为了控制光标的位置,需要确定光标移动的方向(矢量数据资源)和移动的距离(标量数据资源)。以下针对这两类数据资源分别讨论其解码方式。
确定光标的移动方向是为了能让光标移动到用户希望的地方。而有两种可以达成此目的的光标移动方向的形式。一种是将光标的移动方向看作是一个连续的角度,也可以看成是由离散的上下左右四个方向的适当组合得到的。对于前者,解码需要得到一个连续数据资源。后者则只需要有确定的四个离散数据资源即可。
由于眼球可以在眼眶中自由旋转,眼球在眼眶中的相对位置(静态)的角度是一个连续的值,可以和光标的移动方向的角度作一一映射,直接转化为光标移动方向数据资源。
f:dnum→dnum
f(x)=x
deye=(tdirection)
f(deye)=ddirection
同理,对于头部来说,其在肩上的相对位置(静态)的角度也是连续的值,可以和光标的移动方向的角度作一一映射,因此可以实现向光标移动方向数据资源的转化。
f:dnum→dnum
f(x)=x
dhead=(tdirection)
f(dhead)=ddirection
对于四肢来说,不同于眼球和头部基本上只能在二维平面上运动,并且无法离开其原有位置。四肢可以在三维空间中运动,并且能够进行大范围活动,所以除了其相对位置(静态)的角度之外、其运动方向(动态)的角度也是一个连续的值。而光标的移动是二维的,因此需要对四肢的运动方向(动态)或相对位置(静态)进行降维处理。可以忽略四肢在垂直空间中的运动,将运动方向(动态)或相对位置(静态)映射至水平平面,或者忽略四肢在纵向空间中的运动,将运动方向(动态)或相对位置(静态)映射至横向垂直平面。映射至二维平面后的运动方向(动态)或相对位置(静态)可以和光标移动方向相对应,因此可以实现向光标移动方向数据资源的转化。
f:r3→r2
f(x,y,z)=(f1(x,y,z),f2(x,y,z))
f1(x,y,z)=x
f2(x,y,z)=y
dlimb=(tnum(dimmension=3))
g:r2→tdirection
g(f(dlimb))=ddirection
离散情形:可以对音调或音量进行范围划分。比如音调在c3以下代表方向:上;在c3到c4之间代表方向:下;在c4到c5之间代表方向:左;在c5以上代表方向:右。即,通过声音音调的范围即可确定光标移动方向。
f:dcontinuity→ddispersed
g:ddispersed→tdirection
g(f(dpitch))=ddirection
距离:光标移动距离可以看成一个连续的值,而连续的值可以通过由连续的值进行映射直接得到,或者由离散的值在一定精度内对其进行逼近。
由连续值得到距离:速度、加速度、路程、距离都是连续的值。四肢的运动、头部和眼球的旋转都可以产生包含其中若干种连续的值的信息。而由可穿戴式运动捕捉设备或者是运动影像记录设备均可观测到人体某一特定部位在运动中产生的以上相关数值。可选取其中一种,对其值进行映射和缩放,对应于光标的移动距离。
f:dnum→dnum
f(x)=k*x
f(dspeed)=ddistance
音调、音量都可以看成是连续的值。可选取其中一种,对其值进行映射和缩放,对应于光标的移动距离。
f:dnum→dnum
f(x)=k*x
f(dvolume)=ddistance
由离散值逼近距离:可以定义用户的某一动作代表光标向指定方向移动某一离散值的距离。比如用户拍一下手,光标就移动1cm。在实际应用中可以定义多个动作代表多个不同的移动的离散值,只要其中最小的离散值小于光标的点击范围,就可以在光标的点击范围精度内移动到用户希望移动到的位置。同时任何可被观测并被识别的动作都可以被定义为代表光标移动某一特定离散距离。从而将离散运动转化为光标移动距离的信息。
f:i→dnum
f(iaction)=ddistance
可以定义声音的音调或音量超过或低于某一阈值代表光标向指定方向移动某一离散值的距离。比如音量超过80分贝,光标就移动1cm。
f:dnum→dnum
f(dvolume)=ddistance
对于操作信息资源解码。一般地,传统鼠标能传达的操作信息非常有限,基本仅限于单击左键、单击右键、双击、长按四种。在本实施例中,对于单击左键、单击右键、双击这三种操作选取动态的行为,比如拍一下手代表单击左键,连续拍两下手代表双击,跺一下脚代表单击右键等等。而长按操作可选取静态的行为,比如以手攥拳代表长按。除了传统鼠标表达的几种操作信息之外,用户还可以自定义新的操作。比如说打一个响指代表删除选定的文件等等。
f:i→i
f(iaction)=ioperation
应用本发明实施例所提供的方法,采集目标对象的行为内容;行为内容包括运动内容和/或声音内容;对行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果;利用编码结果对行为内容进行响应处理。
在本方法中,首先采集得到目标对象的行为内容,该行为内容可以具体为运动内容和声音内容中的至少一种。然后,对行为内容进行跨数据、信息、知识模态的内容编码处理,可以得到编码结果。最终,根据编码结果对行为内容进行响应处理。如此,便可避免用户必须对类似键盘、鼠标这种输入设备的限制,通过比划一个动作,发出一个声音便可实现人机交互,提升用户体验。
需要说明的是,基于上述实施例,本发明实施例还提供了相应的改进方案。在优选/改进实施例中涉及与上述实施例中相同步骤或相应步骤之间可相互参考,相应的有益效果也可相互参照,在本文的优选/改进实施例中不再一一赘述。
在本发明的一种具体实施方式中,考虑到行为内容采集过程,可能会采集到一些与人机交互无关的内容,为避免产生错误的响应,还可对行为内容进行预处理,得到剔除无效内容的行为内容。
具体的,用户的行为内容收集过程中可具体包括对目标使用主体的识别以及对该主体产生的内容的收集。
对主体的识别的目的是为了排除非主体产生的内容误加入到编码和解码过程中产生的干扰。从运动内容和声音内容两方面讨论其主体识别的方法。
对于运动内容来说,若是通过可穿戴式设别进行收集,则运动内容的接收范围被限制在了可穿戴设备的使用者上,也就不会存在其它个体产生的运动内容被误收集的情况。
若是通过摄像头采集运动的影像资料,再对运动内容进行识别,则需要确保只识别目标个体的运动内容。可以通过人脸识别技术,在使用前提前录入用户面部资料,在用户使用过程中,只对影像中与录入用户面部资料相符的个体产生的运动内容进行收集。
对于声音内容来说,通过麦克风进行收集,需要确保只对目标用户产生的声音内容进行编码处理。可以利用声音识别技术,在使用前提前录入用户的声音资料,在用户使用过程中,只对与录入声音资料相符的声音内容进行编码处理。
在内容收集过程中需要对收集到的用户内容进行预处理,确保用户无意识的微动作或是不经意间发出的声音不会对编码过程产生干扰。
基于运动的幅度判断运动内容是用户有意进行的,还是无意识的微动作。运动幅度scope是运动距离与运动部位大小的比值:
例如,对于手指来说,由于运动部位较小,运动几厘米就会产生较大的幅度;而对于身体来说,需要运动更长的距离才能产生同等程度的幅度。基于运动幅度这个概念,将收集到的运动内容中幅度小于0.05厘米的运动内容判定为微动作,不进行编码处理。
基于声音内容的音量判断声音是不经意发出的还是有意发出的。将收集到的声音内容中音量小于15分贝的声音内容判定为不经意发出的,不进行编码处理。
在本发明的一种具体实施方式中,为了更好地进行人机交互,还可对编码过程,解码过程进行优化,即在上述实施例的基础上,还可获取目标对象的反馈内容,利用反馈内容对内容编码处理和/或内容解码处理进行调优。
在完成对用户内容的编码和解码后,可将解码结果显示在显示屏上。若结果和用户预想一致,则给予系统正向反馈;若结果不一致,则由用户手动输入目标结果给予系统负反馈。用户反馈的结果应用到下一个阶段的系统学习过程中。
学习模式通过对未能满足用户的表达意愿情形的用户反馈的分析处理,对编码模式和解码模式进行调整,以达到满足用户需要的目的。
在编码过程中,若未能正确识别某一特定动作,如打响指:isnap。根据用户的反馈ifeedback:该动作实际为打响指,将记录的该动作的数据资源标记后加入识别打响指行为的算法的训练数据集中,从而提高对用户打响指行为识别的准确率。
ifeedback=rrepresent(iaction,isnap)
algorithm(snap).dataset.append(iaction)
在解码过程中,若对编码得到的数值型数据资源进行缩放时未能达到用户预想的效果,则根据正确结果适当调整缩放的比例。
例如,若编码得到的数值型数据资源dnum=50cm,解码时的缩放系数
knew=k+α*(kpurpose-k)
可以计算出新的缩放系数
相应于上面的方法实施例,本发明实施例还提供了一种跨数据、信息、知识模态的内容编解码装置,下文描述的跨数据、信息、知识模态的内容编解码装置与上文描述的跨数据、信息、知识模态的内容编解码方法可相互对应参照。
参见图2所示,该装置包括以下模块:
行为内容采集模块101,用于采集目标对象的行为内容;行为内容包括运动内容和/或声音内容;
内容编码模块102,用于对行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果;
响应处理模块103,用于利用编码结果对行为内容进行响应处理。
应用本发明实施例所提供的装置,采集目标对象的行为内容;行为内容包括运动内容和/或声音内容;对行为内容进行跨数据、信息、知识模态的内容编码处理,得到编码结果;利用编码结果对行为内容进行响应处理。
在本装置中,首先采集得到目标对象的行为内容,该行为内容可以具体为运动内容和声音内容中的至少一种。然后,对行为内容进行跨数据、信息、知识模态的内容编码处理,可以得到编码结果。最终,根据编码结果对行为内容进行响应处理。如此,便可避免用户必须对类似键盘、鼠标这种输入设备的限制,通过比划一个动作,发出一个声音便可实现人机交互,提升用户体验。
在本发明的一种具体实施方式中,响应处理模块103,具体用于生成与编码结果对应的目标指令,并执行目标指令;或,将编码结果传输至目标设备,以便目标设备对行为内容进行响应处理。
在本发明的一种具体实施方式中,响应处理模块103,具体用于生成与编码结果对应的设备控制指令;设备控制指令包括光标控制指令、功能开关控制指令;执行设备控制指令。
在本发明的一种具体实施方式中,响应处理模块103,具体包括:
解码单元,用于对编码结果进行跨数据、信息、知识模态的内容解码处理,得到解码结果;
响应单元,用于利用解码结果对行为内容进行响应处理。
在本发明的一种具体实施方式中,解码单元,具体用于若解码目标为数据资源,则转化编码结果中的数据资源或信息资源,得到解码结果;若解码目标为信息资源,则转化编码结果中的信息资源,得到解码结果。
在本发明的一种具体实施方式中,若解码目标为数据资源,相应地,解码单元,具体用于若编码结果与解码目标的模态相同,则按照同态映射,对编码结果进行映射处理,得到解码结果;其中,模态相同包括类型和维度均相同;若编码结果与解码目标的模态不同,则对编码结果进行跨模态映射,得到与解码目标同模态的中间结果;按照同态映射,对中间结果进行映射处理,得到解码结果。
在本发明的一种具体实施方式中,若行为内容为运动内容,编码结果包括数据资源和信息资源,数据资源包括标量数据资源和矢量数据资源;
相应地,内容编码模块102,具体用于将行为内容中连续形式的数值直接赋予标量数据资源;将行为内容中离散形式的数值按照与阈值的对应关系,确定为标量数据资源;将行为内容中绝对形式的方向或位置,直接赋予矢量数据资源;将行为内容中相对形式的方向或位置,根据相应的基方向或基位置,得到相对方向或相对位置,并赋予矢量数据资源;将行为内容中至少一个部位运动表达信息确定为信息资源。
在本发明的一种具体实施方式中,还包括:
资源补充模块,用于对不同的标量数据资源进行相互转换,对标量数据资源进行补充;对不同的矢量数据资源进行相互转换,对矢量数据资源进行补充;对矢量数据资源和标量数据资源进行相互转换,以补充数据资源。
在本发明的一种具体实施方式中,若行为内容为声音内容,编码结果包括数据资源和信息资源,数据资源包括音调数据资源、音色数据资源和音量数据资源;
相应地,内容编码模块102,具体用于获取声音内容的音频频率,将音频频率作为音调数据资源;获取声音内容的音频波形,将音频波形作为音色数据资源;获取声音内容的音频响度,将音频响度作为音量数据资源;识别声音内容的语音内容,将语音内容作为信息资源。
在本发明的一种具体实施方式中,还包括:
预处理模块,用于对行为内容进行预处理,得到剔除无效内容的行为内容。
在本发明的一种具体实施方式中,还包括:
调优模块,用于获取目标对象的反馈内容,利用反馈内容对内容编码处理和/或内容解码处理进行调优。
相应于上面的方法实施例,本发明实施例还提供了一种跨数据、信息、知识模态的内容编解码设备,下文描述的一种跨数据、信息、知识模态的内容编解码设备与上文描述的一种跨数据、信息、知识模态的内容编解码方法可相互对应参照。
参见图3所示,该跨数据、信息、知识模态的内容编解码设备包括:
存储器332,用于存储计算机程序;
处理器322,用于执行计算机程序时实现上述方法实施例的跨数据、信息、知识模态的内容编解码方法的步骤。
具体的,请参考图4,图4为本实施例提供的一种跨数据、信息、知识模态的内容编解码设备的具体结构示意图,该跨数据、信息、知识模态的内容编解码设备可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(centralprocessingunits,cpu)322(例如,一个或一个以上处理器)和存储器332,存储器332存储有一个或一个以上的计算机应用程序342或数据344。其中,存储器332可以是短暂存储或持久存储。存储在存储器332的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对数据处理设备中的一系列指令操作。更进一步地,中央处理器322可以设置为与存储器332通信,在跨数据、信息、知识模态的内容编解码设备301上执行存储器332中的一系列指令操作。
跨数据、信息、知识模态的内容编解码设备301还可以包括一个或一个以上电源326,一个或一个以上有线或无线网络接口350,一个或一个以上输入输出接口358,和/或,一个或一个以上操作系统341。
上文所描述的跨数据、信息、知识模态的内容编解码方法中的步骤可以由跨数据、信息、知识模态的内容编解码设备的结构实现。
相应于上面的方法实施例,本发明实施例还提供了一种可读存储介质,下文描述的一种可读存储介质与上文描述的一种跨数据、信息、知识模态的内容编解码方法可相互对应参照。
一种可读存储介质,可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述方法实施例的跨数据、信息、知识模态的内容编解码方法的步骤。
该可读存储介质具体可以为u盘、移动硬盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、磁碟或者光盘等各种可存储程序代码的可读存储介质。
本领域技术人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



