
 商标分类
商标分类  商标转让
商标转让 
语音识别系统的制作方法
 2021-01-28 13:01:08|
2021-01-28 13:01:08| 244|
244| 起点商标网
起点商标网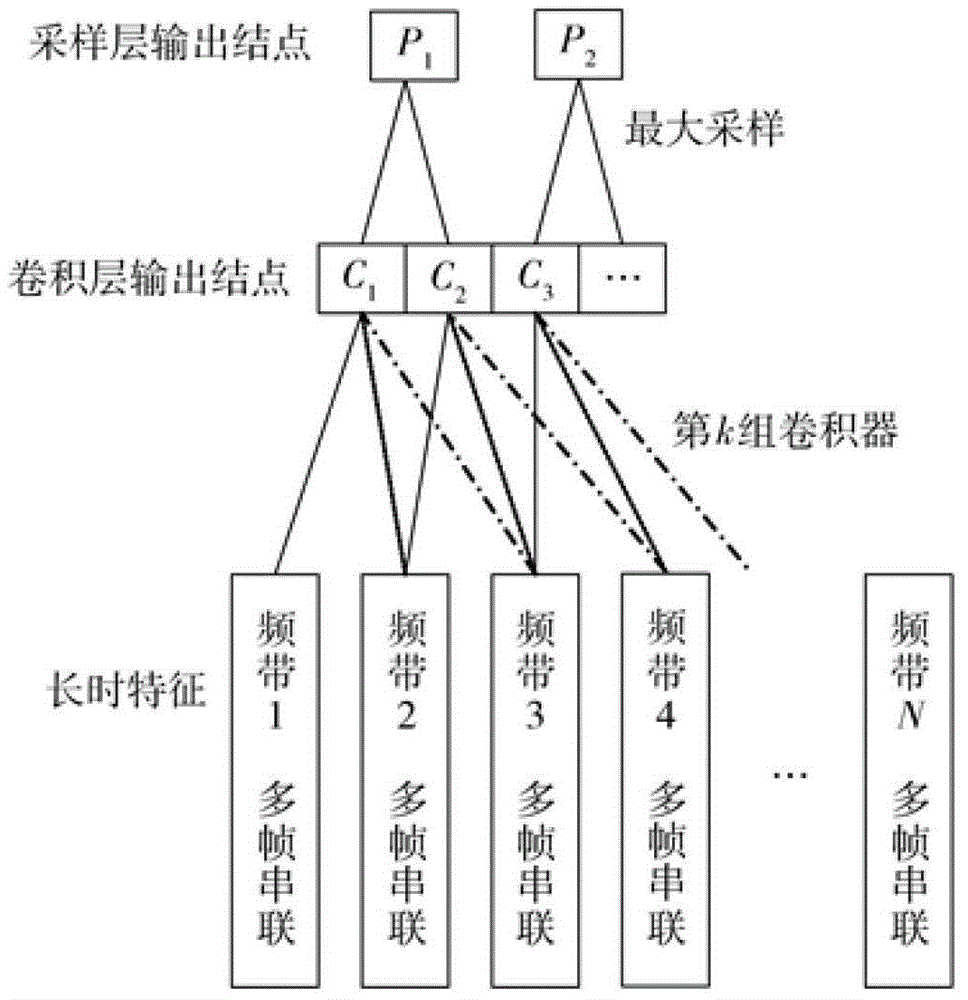
本发明涉及人机交互技术领域,尤其涉及一种语音识别系统。
背景技术:
语音识别是人机交互的一项关键技术,在过去的几十年里取得了飞速的进展。传统的声学建模方式基于隐马尔科夫框架,采用混合高斯模型(gaussianmixturemodel,gmm)来描述语音声学特征的概率分布。由于隐马尔科夫模型属于典型的浅层学习结构,仅含单个将原始输入信号转换到特定问题空间特征的简单结构,在海量数据下其性能受到限制。人工神经网络(artificialneuralnetwork,ann)是人们为模拟人类大脑存储及处理信息的一种计算模型。近年来,微软利用上下文相关的深层神经网络(contextdependentdeepneuralnetwork,cd--dnn)进行声学模型建模,并在大词汇连续语音识别上取得相对于经鉴别性训练hmm系统有句错误率相对下降23.2%的性能改善。掀起了深层神经网络在语音识别领域复兴的热潮。
因此,如何基于神经网络进行语音识别以提高语音识别的准确度,是亟需解决的技术问题。
技术实现要素:
本发明提供的语音识别系统,能够实现基于神经网络的语音识别,提高语音识别的准确度。
第一方面,本发明提供一种语音识别系统,包括:
前端模块,用于对来自外部应用程序的音频信号输入进行处理以便输出特征流;
解码器模块,用于根据来自于所述前端模块的特征流和来自于语言专家模块的搜索图,输出结果对象的实例;
语言专家模块,用于为所述解码器模块提供所需的各种层次的知识组成的搜索图。
可选地,所述解码器模块包括搜索管理模块,所述搜索管理模块用于对给定数量的特征流进行识别,返回结果对象的实例。
可选地,所述搜索管理模块提供两种搜索管理:并行搜索管理和标记搜索管理,所述并行搜索管理在所述前端模块使用并行特征流时所使用,所述标记搜索管理在非并行特征流的情况下使用。
可选地,所述语言专家模块包括声学模型子模块、语言模型子模块和字典子模块,所述声学模型子模块作为一个接口,所述语言模型子模块用于提供词级层次的语言结构信息,所述字典子模块用于提供语言模型中词的发音。
可选地,所述语言模型子模块用于基于卷积神经网络的语言模型提供词级层次的语言结构信息。
可选地,所述基于卷积神经网络的语言模型包括前馈神经网络语言模型和循环神经网络语言模型。
可选地,所述语言模型子模块的实现包括语法规则的实现和统计语言模型的实现。
可选地,所述解码器模块所需的各种层次的知识包括词级层次的知识、音素级层次的知识和子音素级层次的知识。
本发明实施例提供的语音识别系统,包括用于对来自外部应用程序的音频信号输入进行处理以便输出特征流的前端模块,用于根据来自于所述前端模块的特征流和来自于语言专家模块的搜索图,输出结果对象的实例的解码器模块,以及用于为所述解码器模块提供所需的各种层次的知识组成的搜索图的语言专家模块,所述语言专家模块包括的语言模型子模块用于基于卷积神经网络的语言模型提供词级层次的语言结构信息,能够大幅度降低模型的复杂度,实现基于神经网络的语音识别,提高语音识别的准确度。
附图说明
图1为卷积神经网络的模型图;
图2为前馈神经网络语言模型图;
图3为循环神经网络语言模型的结构图;
图4为本发明实施例提供的语音识别系统的结构示意图;
图5为本发明实施例提供的前端模块的框架图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
首先对卷积神经网络进行介绍。
与深层神经网络相比,卷积神经网络的关键在于引入了卷积和聚合的概念。卷积神经网络通过卷积实现对语音特征局部信息的抽取,再通过聚合加强模型对特征的鲁棒性。相比深层神经网络,卷积神经网络能够在保证识别性能的同时,大幅度降低模型的复杂度。
卷积神经网络由一组或多组卷积层+聚合层构成。一个卷积层中包含若干个不同的卷积器,这些卷积器对语音的各个局部特征进行观察。聚合层通过对卷积层的输出结点做固定窗长的聚合,减少下一层的输入结点数,从而控制模型的复杂度。一般聚合层采用最大聚合算法(maxpooling),即对固定窗长内的结点选取最大值进行输出。最后,通过全网络层将聚合层输出值综合起来,得到最终的分类判决结果。这种结构在图像处理中获得了较优的性能。卷积神经网络相比深层神经网络等神经网络结构,引入三个重要的概念——局部卷积、聚合和权值共享。将语音看作二维特征输入时,第一维是时域维度,第二维是频域维度,这两维的物理意义完全不同。由于深层神经网络上实验证明,多帧串联的长时特征对模型性能的提高非常重要,在卷积神经网络的输入特征上,也保留了该方法,将当前帧的前后几帧串联起来构成长时特征。考虑到差分特征对静态特征的补充关系,实验中将差分特征一起串联在长时特征中,这样构成的特征作为卷积神经网络的第一维特征。在卷积神经网络的另一维——频域维度上,一般采用梅尔域的滤波带系数(filterbank)作为参数(如图1中选择n个滤波频带)。卷积神经网络中卷积层的物理意义可以看做:通过卷积器对局部频域的特征观察,抽取出局部的有用信息(局部卷积)。这里,将同一种卷积器作用在不同的滤波带上,每个滤波带包含有当前帧该滤波带的系数,以及该滤波带上的长时特征,通过下式计算得到卷积器的输出:
ci,k=θ(σb=11wb,kvtb+i+ak)(1)
其中,vtb+i为第i组输入特征矢量,wb,k为第k个卷积器的权值参数,s为卷积器的宽度,ak为网络偏置。通过将第i组输入和第k个卷积器做加权平均后,通过非线性函数θ得到卷积层的一个输出结点值,θ一般选择反正切函数或sigmoid函数。
由此得到的输出为该种卷积器对局部特征的观察结果。由于使用的是相同的卷积器,其卷积参数完全相同,存储时只需保留一组卷积参数(权值共享)。另一方面,由于一种卷积器所能观察的信息有限,所以一般会使用多种不同的卷积器从不同视角上进行观察,从而得到更多的信息量。最终的存储量仅为各种卷积器的自由参数量之和,相比深层神经网络全网络连接结构,大大减少了模型的存储规模。同时,卷积运算的一个重要特点就是,通过卷积运算,可以使原信号特征增强,并且降低噪音,这也使得基于卷积运算的卷积神经网络模型有着更好的抗噪性能。
在卷积层之后,紧跟着的是聚合层。在语音识别中,采用最大聚合算法(聚合)。以上图为例,从c1和c2这两个卷积层输出结点中选择最大值作为聚合层的输出p1。这样做的好处:一是可以减少输出结点数,控制模型的计算量;二是通过对几个结点选最大值进行输出,增加模型对语音特征的鲁棒性。
到目前为止,卷积神经网络的信息都还是停留在局部观察的结果。要得到最终的分类结果,需要将这些信息综合起来。所以在卷积层之后,通过一个全网络层,将聚合层的各个输出综合起来,最后通过输出层得到各个状态的分类后验概率。
基于神经网络的语言模型能够解决在语言模型训练时所出现的数据稀疏的问题。数据稀疏一直是语言模型训练所存在着问题,一般采用平滑或回退算法来解决,而神经网络语言模型是通过把离散域映射到连续域的手段来解决此问题的。根据神经网络语言模型所采用的不同的神经网络结构,神经网络语言模型可以分为:前馈神经网络语言模型、循环神经网络语言模型等。在此仅对这两种神经网络语言模型进行简要的介绍。
原始的前馈神经网络语言模型是由bengio提出的。此模型的基本描述如下:设n元神经网络语言模型的输入为确定的前n1个历史词(或场景词),其中每一个词使用长度为v即训练库词汇量的大小的矢量来表示,矢量是用0或1来表示的,其中值为0的位置表示此位置上词不存在,为1则表示其存在,通过把所有的词都映射到词汇量表中的相应位置,再查看映射表及每个词相应位置上的值来确定相应的词。如设词汇量的大小为5,所使用的为3元神经网络语言模型,则前n1即2个历史词的编码可以写为(0,1,0,0,0)和(1,0,0,0,0),其中的1对应的是词汇表中位置上的词,并且历史词的编码中仅有一个位置上的值为1,其它位置上的值都是0。此n1个输入被线性映射到一个低维定的空间中,映射使用了一个共享的矩阵c,矩阵c也称之为映射矩阵被神经网络输入的n1历史词所共享。在一般的例子中,设训练语料库中的词汇量大约为50个词,如此对于一个5元神经网络语言模型来说,输入层包含200个二进制变量,然而在给定的时间内只有其中的4个被设置为1,其它的都为0。映射就是把输入映射到所需的低维空间,设低维空间的维度为30,对于此例子,则被映射的输入层的维度为30乘以4等于120。经过映射层后,存在着一个非线性活动函数的隐藏层,活动函数使用的一般是s型函数,接下来的是一个输出层,其长度等于词汇量表中的长度,当网络经过训练后,5元神经网络的输出层表示的是p(wt|wt4,wt3,wt2,wt1)的概率分布。
本发明实施例采用了前馈神经网络语言模型。其n元神经网络模型学习问题被分解成2歩:1,学习一个2元神经网络语言模型即仅仅有一个历史词被编码的输入层。2,训练一个n元神经网络语言模型此语言模型把来自于n元语言模型的历史词映射到被已经训练好的2元神经网络语言模型所使用的低为维度空间中。这两个模型都是简单的只有一个隐藏层的前馈神经网络语言模型,如此比原始的模型更加容易实现和理解。它提供和原始语言模型相同的结果。前馈神经网络语言模型如图2所示。
循环神经网络语言模型与前馈神经网络语言模型主要的不同在于对历史词的表示,对于前馈神经网络语言模型的表示而言,历史或场景仍然仅仅是前几个词,而对于循环神经网络模型,历史或场景的有效表示是通过在训练中学习到的。循环神经网络的隐藏层表示的是所有的历史而非仅仅是前n1个历史词,如此理论上循环神经网络能够表示更长的场景模型。
循环神经网络语言模型相比于前馈神经网络语言模型的另一个优点是其更能够表示在序列数据中的高级模式。例如在场景或历史中的依赖于某些词的模式可以在可变的位置上发生,这样的模式用循环神经网络能够有效编码的表示,因为循环神经网络能够简单的记住在隐藏层的状态中的一些特定的词。然而前馈神经网络需要为在历史中的每一个特定的位置上的词使用参数才行。此不但会增加在模型中所使用参数的数量,而且训练语料库中需要有此模式的样例存在才行。循环神经网络语言模型的结构如图3所示。
卷积神经网络通过卷积器对局部特征进行分析,通过聚合层加强抽取出来的特征鲁棒性,最后通过全网络层建立模型得到最后的分类结果。在这个过程中,由于卷积器肩负了直接对输入原始特征的分析、抽取过程,使得卷积器的设计成为卷积神经网络的重点。卷积器的参数有两个:卷积器个数和卷积器形状。下面分别从这两个方面分析不同参数对分类性能的最终影响。
上表为在timit测试集上不同卷积器个数的卷积神经网络性能对比,分别给出了各个模型的验证集帧正确率和测试集的音素正确率。在这组实验中,除了卷积器个数不同以外,所有卷积神经网络的其他参数都保持一致:卷积器形状33×5,聚合层1×4,全连接单隐层1024,输出分类183类。随着卷积器个数从50个逐步上升到200个,帧正确率和音素正确率都有稳步的提升,特别是当卷积器从50个上升到100个时,性能有超过1%的提高,再继续增加卷积器个数到200个时,性能基本没有变化。实验现象表明:不同卷积器可以从不同的角度提取出不同的信息,如果个数太少,则会导致提取的信息量受限,卷积神经网络的建模性能也就受到影响,所以在卷积神经网络中,要想更好地表征语音特性,卷积器的个数不能太少(同时也不宜太多。太多会增加计算量,并且性能已经基本饱和)。
上表为在timit测试集上不同卷积器形状的卷积神经网络性能对比。卷积器的形状主要是指对局部多大范围的特征进行观察,理论上观察得越细越有可能发现局部的有用信息,但同时也可能会牺牲模型的泛化能力,使得在识别非匹配语音时效果变差。在这组实验中,除了卷积器形状不同以外,所有卷积神经网络的其他参数都保持一致:卷积器个数100,聚合层1×3,全连接单隐层1024,输出分类183类。表中对比了33×a的卷积器形状对性能的最终影响。之所以固定卷积器第一维参数为33,是考虑到输入的特征是11帧串联,包含有0、1和2共三阶差分信息,这样构成了33维参数。真正需要卷积器细节观察的应该是不同频带上的特征分布。实验中选择40个频带的特征输入,当卷积器的第二维参数为a时,则表示这40个频带上每连续a个频带作为一个观察窗,送入卷积器抽取出相应信息(频带窗移为1个频带的长度,也就是相邻两个观察窗有a-1的长度的频带交叠)。从结果中看到,虽然随着卷积器形状的逐步细化,音素正确率有所提高,但是幅度微弱。这说明卷积器的形状对性能的影响相对不明显,同时为了得到更好的泛化性,一般选择比较适中的卷积器形状。
除卷积层以外,聚合层也是卷积神经网络结构的特点之一,聚合是为了加强模型的鲁棒性。通常语音识别系统的性能会在不同环境、不同说话人等情况下受到影响,主要是由于不同的环境或说话人会使得频谱特征发生偏移。由于聚合本身是对相邻几个观察窗的输出做最大值选择,相当于模糊语音特征,即使发生偏移,也不影响最大值的选择,从而加强模型的鲁棒性。
上表给出了卷积器形状为33×5时不同聚合参数下卷积神经网络性能。聚合层为1×1,表示不进行聚合,每个观察窗的输出都将作为下层的输入送入训练。相比表中的1×m(m>1)的聚合结构,不聚合的最终识别性能明显变差(>2%),这个结果充分说明聚合对性能保证的必要性。在使用聚合的结构中,m的选择对最终的音素识别率影响非常微弱。考虑到m越大,聚合层输出结点数就越少,全网络层的计算量和规模也越小。为了有效控制模型的规模,实际中一般m不会选的太小。
语言模型为语音识别系统中最为重要的模块之一,其好坏会严重影响到语音识别结果的好坏。系统对语言模型的支持,将会间接的影响的识别效果的好坏,在语言模型使用时,首先所要做的就是对系统进行分析以确定系统所支持的语言模型的类别。此情况对于声学模型的使用也是一样的。
如图4所示,本发明实施例提供的语音识别系统最主要的三个部分为前端模块、解码器模块和语言专家模块。前端模块是用来把音频信号转化为特征流。解码器模块主要是对来自前端的特征流和来自语言专家的搜索图进行处理,产生结果result类的对象实例。语言专家模块主要是包含声学模型、语言模型和字典。
前端模块对来自外部应用程序(application)的输入(input)进行处理以便输出特征(feature)。一般对于语音识别来说外部的输入为音频信号,被前端处理后生成为特征流,特征流是被用来在解码器中进行声学打分用的。一般语音识别系统的前端所采用的是软件工程设计中的push设计模式,而对于前端所采用的是pull设计模式。pull设计模式是一种与push设计模式完全相反的设计模式,对于push设计模式来说,对输入的音频信号的处理不是由正在处理此音频信号的处理者来决定是否对音频信号进行处理的,而pull设计模式对音频信号的处理只有在处理者本身需要处理音频信号时才处理。相比于push设计模式,pull设计模式使得其有更多的主动权。对于它的前端来说,除了其在软件设计模式的特色外,其还有一大特色就是模块化。它在前端模块中把对信号的每一歩处理进行了模块化,如预加重、加窗、滤波等。这些能够对信号进行处理的单元称为数据处理器(dataprocessor),在其源代码中dataprocessor是一个接口,任何实现了此接口的对象都可以看作是数据处理器。为了能够产生所需的特征流,一般需要做的就是对多个数据处理器进行有序的组合。在前端模块中,每一个有序的组合对象被当作成一个管道(pipeout),并且前端是可以有多个管道的。每个管道之间是并行的关系。管道中的数据处理器之间是使用实现了data接口的对象来通信的。其前端模块的框架如图5所示。
解码器模块是的语音识别系统中最重要的模块,它根据来自于前端模块的特征和来自于语言专家的搜索图,输出result对象的实例。分别为一般解码器(decoder)和帧解码器(framedecoder)。相比于一般的解码器,帧解码器并没有使用常用的pull模式,帧解码器每次仅仅解码单独的一个特征帧。对于这两个解码器来说存在一个十分重要的模块即搜索管理模块,搜索管理模块是解码模块中最为核心的模块,它对给定的数量的特征流进行识别,返回的result对象实例。提供了2两种搜索管理,分别为并行搜索管理(parallelsearchmanager)和标记搜索管理(tokensearchmanager)。并行搜索管理是在当系统的前端模块使用并行特征流时所使用,而标记搜索管理是在非并行特征流的情况下使用。标记搜索管理存在着多个具体的搜索管理对象。如simplebreadthfirstsearchmanager、wordpruningbreadthfirstsearchmanager、tokenheapsearchmanager等具体的搜索管理。一般搜索管理的操作流程是在语言专家所提供的搜索图的指导下,采用token标记传播框架根据声学模型和语言模型来实现声学和语言的打分,并且在token标记传播过程中采用静态或者动态剪枝算法来限制token标记传播的广度,token传播完成后会生成token标记活动列表,最终通过token标记活动列表来生成result对象的实例。提供了一个简单剪枝的类simplepruner和tokenscorepruner来实现剪枝对token标记活动列表的剪枝,剪枝的实现主要是依靠对相关beam的设置来实现。提供了对acousticscorer打分接口来实现声学打分,提供了result的类和接口,以便对result进行操作,可以通过result生成网格,或者直接通过result来获得最终的识别结果,或进行map解码,以及进行重打分等操作。
语言专家模块是各种知识的集合。语言专家模块包括声学模型、语言模型和字典3个子模型。语言专家就是此3者的集合,它包括了在解码器模块中所需用的到各种层次的知识,如词级层次的知识、音素级层次的知识、子音素(senones)级层次的知识等。这些知识被有机的组成搜索图来指导解码器的解码。语言专家在引擎中是一个接口,它并没有规定具体的实现过程。提供了实现了此linguist接口的一些类,以便使用,提供的类有:
flatlinguist:此类一般是在小词汇量识别任务中使用的,它不是采用动态的方法来生成搜索图的,因此不能用于大词汇量识别任务中。
parallelsimplelinguist:此类继承于flatlinguist,相比于flatlinguist来说,此是专门为多特征流的而创建的。
dynamicflatlinguist:此是flatlinguist的动态生成搜索图的版本。
lextreelinguist:此是专门为大词汇量的语音识别任务而准备的。它有着动态性、树型拓扑结构等优点。
声学模型是语言专家模块中的一个子模块,其在系统中作为一个接口而存在。在一般的语音识别系统中声学模型的使用和训练是分开的,系统一般仅负责模型的使用,而不负责模型的训练,模型的训练被委托给其的训练工具来实现,如sphinxtrain。sphinx-4语音识别系统也是一样的。提供了装载sphinx-3的声学模型的类sphinx3loader和装载htk的声学模型的类htkloader,以便使用训练好的声学模型。
字典是语言专家模块中的一个子模块,所提供的是语言模型中词的发音。它把词分解成在声学模型中所能够找到的子词单元。提供了装载词典文件的类,以便创建字典对象,一般的词典的装载有两种方式:静态的方式和动态的方式。静态方式是在使用之前必须全部装载的,而动态则是按需来实现的。
语言模型是语言专家模块中的一个子模块,提供的是词级层次的语言结构信息。在语言模型的实现可以分为两种不同的实现方法:其一是语法规则的实现,其二是统计语言模型的实现。语法规则的实现一般是采用图的方式来实现的,提供了jsgfgrammar、fstgrammar等具体的实现语法类,以便在使用时按需选择。在统计语言方面,它提供了一些统计的n元语言模型的具体实现类,如simplengrammodel、largengrammodel等,同时也提供了对基于类的语言模型的支持。
本发明实施例提供的语音识别系统,包括用于对来自外部应用程序的音频信号输入进行处理以便输出特征流的前端模块,用于根据来自于所述前端模块的特征流和来自于语言专家模块的搜索图,输出结果对象的实例的解码器模块,以及用于为所述解码器模块提供所需的各种层次的知识组成的搜索图的语言专家模块,所述语言专家模块包括的语言模型子模块用于基于卷积神经网络的语言模型提供词级层次的语言结构信息,能够大幅度降低模型的复杂度,实现基于神经网络的语音识别,提高语音识别的准确度。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



