
 商标分类
商标分类  商标转让
商标转让 
基于用户评论中上下文的语音识别测试数据生成方法与流程
 2021-01-28 13:01:52|
2021-01-28 13:01:52| 264|
264| 起点商标网
起点商标网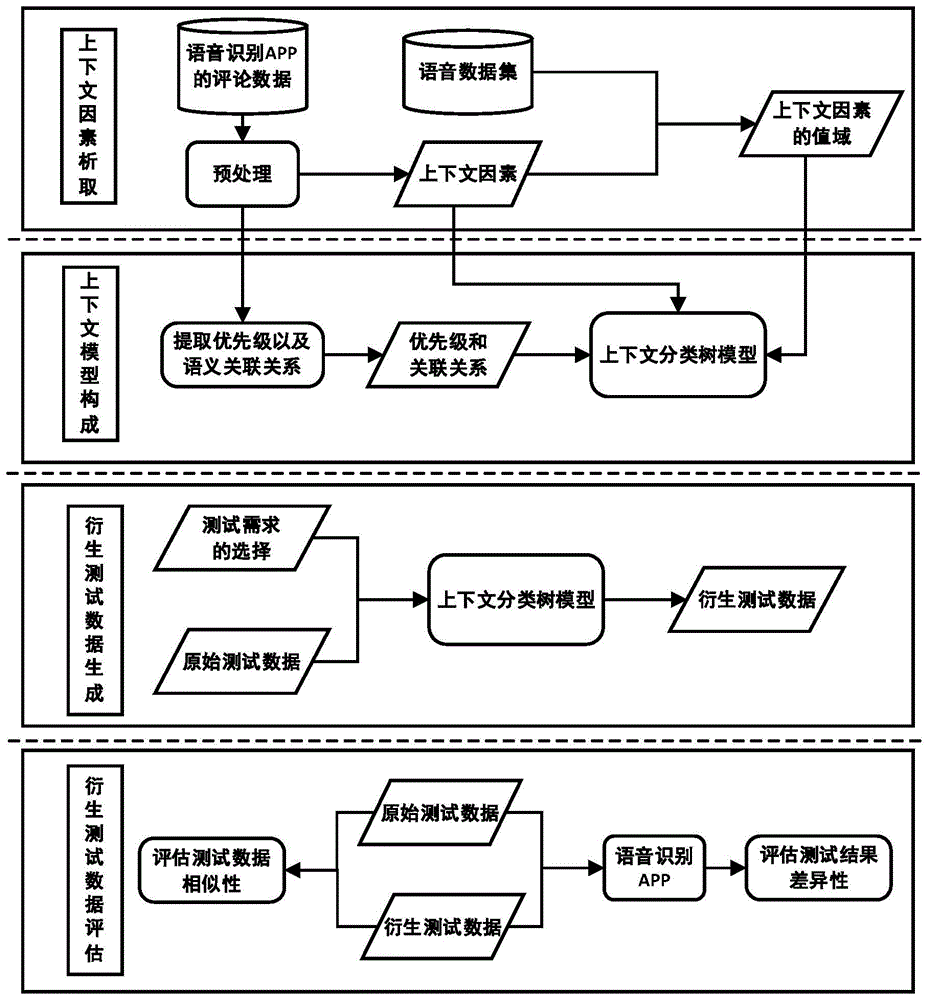
本发明属于智能软件测试
技术领域:
,具体涉及一种基于用户评论中上下文的语音识别测试数据生成方法。
背景技术:
:随着人工智能和大数据技术的发展,市场上涌现出越来越多基于人工智能的产品,例如人脸识别、语音识别、机器翻译等等。智能软件在传统软件的基础上,融入了智能功能属性,这无疑给智能软件的测试带来很多新问题和困难,同时也对智能软件的测试提出较大的市场需要和研究需求。当前快速迭代的智能软件普遍存在测试数据偏少、可信性不足等问题,难以满足测试需求。同时,现有的测试数据生成方法生成的测试数据不能模拟真实场景。语音识别作为智能系统之一,在实际应用中的应用越来越多,对新系统的需求也越来越大。从各语音识别app的用户评论出发,利用语音数据集中数据的真实性,来构造语音识别的测试上下文分类树模型,引导语音测试数据的增强,从而,缓解语音识别测试数据不充分和不真实的问题,帮助开发和测试人员进一步维护和改进智能系统的功能,对于频繁版本演化过程中智能软件的质量保证具有重要的研究意义和应用价值。目前,已有一些工作集中在通过一些智能优化算法来生成测试数据,主要利用遗传算法、粒子群优化算法、蚁群优化算法等智能优化算法。智能优化算法在搜索过程存在随机性,产生了大量冗余的测试用例,缺乏测试的针对性。另外,由于智能软件测试具有测试判定的问题,并且语音识别的功能通常嵌入在各个软件中,因此,针对语音识别测试的相关研究还比较少。futoshi等人于2019年提出了一个针对asr系统的基本识别能力的测试方法,该方法根据asr-sut的语言模型生成测试句子,并使用多个tts合成器对每个测试句子合成一组音频数据文件,使asr-sut能够识别集合中的每个音频数据文件,以获得一组识别结果,并验证所产生的词序列是否等于原始测试句子。但此方法存在结果有效性方面的威胁,如可能会出现tts模块不完整,从而无法得知测试结果是否对其它asr系统有效。du等人提出的deepcruiser能够根据覆盖范围反馈生成具有高覆盖率的测试用例,并有效地对基于rnn的自动语音识别系统进行缺陷检测。与上述方法不同的是,本发明从用户的角度为语音识别功能生成更多真实的语音测试数据,更有利于语音识别功能的测试。近年来,由于机器学习和深度学习的广泛应用,计算机对于自然语言的处理能力更上了一个新的台阶。此时,如果采用这些智能化的技术,对一定数量的app评论文本进行统计分析,生成语音识别系统的上下文因素以及之间的关系,并从数据集中提取真实的上下文因素值,更有利于生成真实世界中的测试数据,为语音识别的测试提供了支持,有利于语音识别的测试工作更便捷、更高效的完成。技术实现要素:针对于上述现有技术的不足,本发明的目的在于提供一种基于用户评论中上下文的语音识别测试数据生成方法,以克服已有测试数据不足和现有方法生成测试数据不真实的问题;本发明充分利用语音识别相关app的用户评论,挖掘语音识别中的上下文因素以及之间的关系,并通过数据集提取上下文因素的值来构建测试上下文分类树模型,从而指导语音测试数据的生成,对于频繁版本演化过程中语音识别软件的质量保证具有重要的研究意义和应用价值。为达到上述目的,本发明采用的技术方案如下:本发明的一种基于用户评论中上下文的语音识别测试数据生成方法,包括步骤如下:1)上下文因素的析取:收集有关语音识别app的评论文本信息,对所述评论文本信息进行预处理和关键词提取,筛选关键词构建上下文因素;根据上下文因素,从开源的语音数据集中提取各上下文因素的值,生成上下文因素的值域;2)上下文模型的构成:构建上下文因素评论数据集,获取评论数据集中上下文因素之间的优先级和语义关联关系,联合上下文因素和上下文因素的值域,构成上下文分类树模型;3)衍生测试数据的生成:将原始测试数据作为上下文分类树模型的输入,同时,选择相应的测试需求,生成对应的衍生测试数据;4)衍生测试数据的评估:通过两种方法对测试数据进行评估,第一种是通过计算原始测试数据与衍生测试数据的相似度,第二种是将原始测试数据和衍生测试数据输入到被测的语音识别app中,比较二者输出结果的差异性。优选地,所述步骤1)具体包括:11)收集移动应用商店中语音识别app的用户评论以及包含语音识别功能的app下有关语音识别的评论文本信息,利用自然语言处理技术对评论文本信息进行预处理和关键词提取,筛选关键词构造上下文因素;12)充分利用开源的语音数据集,对所述的语音数据集进行特征提取,提取出各上下文因素的值,构造上下文因素的值域。优选地,所述步骤2)具体包括:21)构建上下文因素评论数据集,通过计算评论数据集中上下文因素出现的频率来计算各上下文因素的优先级,同时,通过apriori算法(关联规则算法)挖掘评论文本中上下文因素之间的语义关联关系;22)由步骤1)得到的上下文因素和上下文因素的值域以及步骤21)得到的优先级和关联关系,共同构成上下文分类树模型。优选地,所述步骤4)具体包括:41)利用dtw算法计算原始测试数据与步骤3)得到的衍生测试数据之间的相似度,相似度值越高,则表明衍生语音数据越真实可靠;42)将原始测试数据和步骤3)所得到的衍生测试数据共同输入到语音识别app中,通过评估测试结果的差异性来判断衍生测试数据生成的有效性。本发明的有益效果:本发明充分利用了app评论文本的词语权重和语义,将非结构化的文本文档统一表示成向量的形式,并利用语音数据集,构建了语音识别的测试上下文分类树模型,通过模型为待测的需求提供对应的真实测试数据,有利于开发者对系统性能的了解,并提供更有针对性的升级与更新。具体说,主要有以下优点:(1)本发明充分从用户角度出发,通过分析移动应用商店中有关语音识别app的用户评论,抽取用户评论中语音识别的上下文信息,分析语音识别功能使用的具体上下文环境,更有利于帮助开发和测试人员从用户角度理解移动应用语音识别功能的实际使用场景,以此来辅助分析和理解缺陷。(2)本发明避免了测试效率低下以及测试输入的各种组合引起的搜索空间无限放大的问题,充分利用了评论文本信息挖掘出各上下文因素的优先级和关联关系,减少了测试的工作量,提高了测试效率。本发明利用了自然语言形式的文本,对评论文本进行了大量的特征提取过程,包括词语权重特征以及语义特征,从多个维度来充分挖掘文本文档中所包含的信息。通过计算关键词的词频,来计算上下文因素的优先级,并将上下文因素之间的关联关系表示成集合的形式。将非结构化的自然语言评论文本转化为更有利于上下文模型构建的形式。(3)本发明提出了面向语音识别测试数据生成的上下文分类树模型,可对语音识别软件更全面、更有针对性的进行测试,衍生的测试数据是在语音数据集中提取出的值域中生成,更有真实性。附图说明图1为本发明的方法架构图。图2为本发明方法的具体实施原理图。图3为本发明中所构建的语音识别的测试上下文分类树模型的示例图。具体实施方式为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说明,实施方式提及的内容并非对本发明的限定。参照图1、图2所示,本发明的一种基于用户评论中上下文的语音识别测试数据生成方法,包括步骤如下:1)上下文因素的析取:收集移动应用商店(示例中为googleplaystore,也可以为其他应用商店)中有关语音识别app(包括语音识别的app及具有语音识别功能的app,例如:语音翻译)的评论文本信息,对所述评论文本信息进行预处理和关键词提取,筛选关键词构建上下文因素;根据上下文因素,从开源的语音数据集中提取各上下文因素的值,生成上下文因素的值域;其中,11)有关语音识别app主要指语音识别app(livetranscribe、listnote、samsungvoicerecorder、speechnotes等),以及包含语音识别功能app的用户评论,例如语音翻译(voicetranslatorfree等)、语音搜索(voicesearch等)。利用爬虫的方法爬取相关语音识别app的用户评论,选取提交时间范围为2019年7月至2020年7月的文本。对收集到的评论数据进行自然语言处理,包括表情过滤、非英文文本过滤、缩写改正、过滤掉少于3个单词的评论等预处理操作,形成统一的用户评论数据集。利用textrank算法对用户评论数据集进行关键词提取,并结合人工评估,筛选出有关使用语音识别场景的关键词,构建上下文因素库,表1所示为语音识别的上下文因素;如下:表11音量2音调3音速4噪音5混响6回声7口音8语调12)获得上下文因素后,提取语音数据集的上下文因素值,将所有的值加入到各个上下文因素的值域中。对于不能直接提取到的上下文因素,通过映射关系,将上下文因素映射到相对应的物理量上,例如,音调是听觉分辨声音高低时用于描述这种感觉的一种特性,客观上用频率表示音调,主观上感觉音调的单位是采用美(mel)标度。一般来说,频率低,音调低,频率高,音调则高,但音调和频率不成正比关系,其还与声音的强度及波形有关。但音调和频率之间有关系,因此,可以通过提取音频的频率,从而计算音调的高低,计算公式(1)如下:tmel=2595lg(1+f/700)(1)。2)上下文模型的构成:构建上下文因素评论数据集,提取评论数据集中的上下文因素之间的优先级和语义关联关系,联合上下文因素和上下文因素的值域,构成上下文分类树模型;其中,21)利用余弦函数从用户评论中筛选出与上下文因素相关的评论,构建上下文因素评论数据集;首先,对每一条评论文本进行关键词提取,然后利用余弦函数计算该评论与上下文因素的文本相似度,如公式(2)所示:其中,|rk|表示每一条评论文本的关键词数量,|rk∩rl|表示该评论与上下文因素库所共有的关键词数量,sk表示该评论与上下文因素中信息的文本相似度。当sk大于某一界定θ(根据经验0.7-0.8较为合适)时,即认为该评论是与上下文因素相关的评论。22)对于上下文因素评论数据集中的每一条评论文本,利用tf-idf算法计算每一个上下文因素在评论数据集中的权重kt,得到上下文因素的优先级;利用apriori频繁项集方法挖掘上下文因素之间的语义关联关系,每一个上下文因素对应一个项,0个或多个上下文因素的集合,称为项集x,x={r1,r2,r3,...},每一条评论文本都是项的集合,上下文因素的关联规则为ri→rj,通过两个重要的度量值来衡量上下文因素的关联关系,支持度(support)表示评论数据集中同时包含ri和rj的评论数与所有评论数之比,如公式(3)所示:置信度(confidence)表示包含ri和rj的评论数与包含ri的评论数之比,如公式(4)所示:设置最小置信阈值为80%,最小支持阈值为20%;最终,上下文因素的频繁项集以集合的方式呈现。23)步骤11)得到的上下文因素和步骤22)得到的上下文因素值域、上下文因素的关联关系,共同构成上下文分类树模型。参照图3所示,上下文分类树是一个非循环图模型,由节点和边组成,语音识别功能的测试上下文分类树gct定义为gct=(nct,ect,rct,cct),其中,nct是一组有限的非空节点,nct包含三种类型的节点:根节点(nr)、中间节点(ni)和叶节点(nl)。根节点nr代表语音识别的测试上下文,其子节点ni表示所有的测试上下文因素,例如:音量、音调、音速、噪音等。中间节点ni都有对应的子节点,即叶子节点nl,其表示每一种测试上下文因素的值域,比如中间节点音量大小对应的叶子节点是数据集中音量大小的值域,分为大、中、小三段。ect是一组无序的顶点对,称为边。rct表示节点间的语义关系,语义关系有四种:and,xor,select-1和select-m。cct表示挖掘出的测试上下文因素之间的关联关系,主要用集合表示。其中,测试上下文因素ni节点按照优先级降序排列。3)将原始测试数据作为测试上下文分类树模型的输入,同时,选择相应的测试需求,生成对应的衍生测试数据;31)对提取的上下文因素在值域内进行改动,对上下文因素的变换方法如表2所示:表21音量通过sox库对音量大小进行变换2音调通过sox库对音调高低进行变换3语速通过sox库对音速快慢进行变换4噪音通过添加噪声库中的各种噪音5混响通过sox库对音频加混响6回声通过sox库对音频加回声7口音通过修改共振峰对语音口音进行转换8语调通过时域基音同步叠加修改语调32)对提取出的上下文因素的关联关系对上下文因素进行组合,降低组合空间,提高缺陷发现率。4)衍生测试数据的评估:通过两种方法对测试数据进行评估,其一是通过计算原始测试数据和衍生测试数据的相似度,其二是将原始测试数据和衍生测试数据输入到被测的语音识别app中,比较两者输出结果的差异性;其中,41)对测试数据生成的真实性进行评估,通过计算原始测试数据和衍生测试数据之间的相似度。通过dtw(dynamictimewarping)算法计算两段语音之间的相似度,相似度的在[0~100%]的范围内,该值越高则表明两段语音之间的相似度越高,则真实性越强;42)通过将原始测试数据和衍生测试数据分别输入到语音识别app中,通过公式(5)来比较两者输出结果的差异性。对两个识别结果分别做分词操作,并进行编码,分别为a,b两个集合,rd表示两个识别结果的不相似度,rd值越高,原始测试数据和衍生测试数据的结果越不一致;另外,针对测试错误的语音识别结果计算字错误率wer来衡量系统的性能,wer可以为0,其取值越小,表示asr系统识别效果越好。wer的计算评估依据为asr系统识别出的词序列与给定的标准需要完全一致,因此,识别出来的词序列在标准序列基础上的插入词(insertion)、替换词(substitution)和删除词(deletion)的个数均要计入其中,然后计算这三类词的总数占标准序列词个数(记为n)中的百分比,即可得出wer的数值,关于wer的具体计算公式如下:本发明具体应用途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进,这些改进也应视为本发明的保护范围。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips