
 商标分类
商标分类  商标转让
商标转让 
异常音检测系统、伪音生成系统及伪音生成方法与流程
 2021-01-28 13:01:30|
2021-01-28 13:01:30| 256|
256| 起点商标网
起点商标网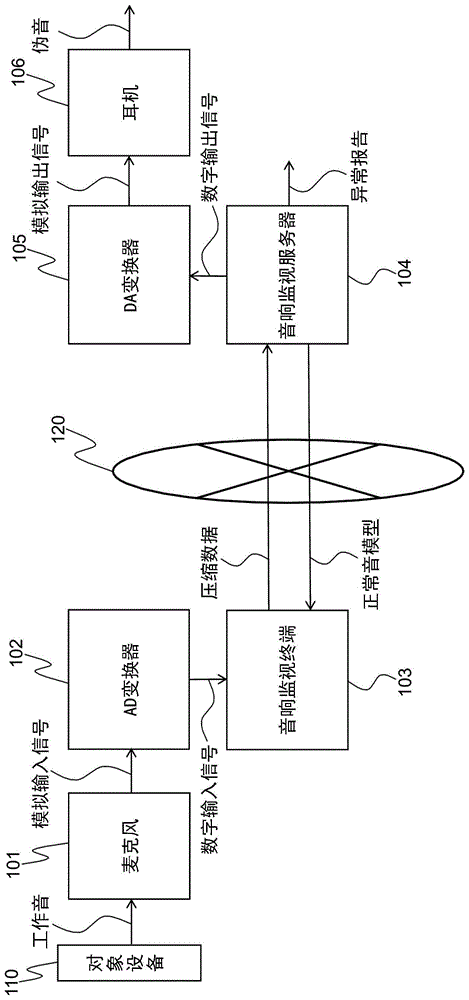
本发明涉及异常音检测系统、伪音生成系统及伪音生成方法。
背景技术:
机械、设备的异常及故障预兆等的状态多数情况下表现在声音。所以,以设备维护等的目的,为了掌握设备的状态而基于设备的工作音进行诊断是重要的。在外部电源供给较困难的环境中,采用如下结构:设置于各设备的具备麦克风的终端通过长期间的电池驱动来间歇性地进行录音和异常检测,将有无异常的结果发送给远程地的服务器。但是,即使仅将异常有无向服务器侧报告并储存,事后用户也不能听取并确认在各时刻发生了怎样的声音。
由于通过长期间的电池驱动能够发送的通信量非常微小,所以也不能发送原始的声音数据及通常的压缩形式的声音数据。例如,作为将声音通信的方法,有日本特开2012-138826号公报(专利文献1)。在该公报中,记载有“具有:视频接收部,接受从外部周边设备输入的输入信号;视频编码器,接受从视频接收部输出的影像信号,形成图像压缩信号;音频编码器,接受从视频接收部输出的声音信号,形成声音压缩信号;第1stc计数器值生成部,接受从视频接收部输出的74.25mhz的视频时钟,形成第1stc计数器值;以及pcr生成部,接受第1stc计数器值而生成pcr。第1stc计数器值生成部进行在视频时钟的每11个周期进行4次递增的计数器动作,生成stc计数器值。”
专利文献1:日本特开2012-138826号公报
如上述那样,通过电池驱动能够发送的通信量非常有限,所以也不能传送原始的声音数据及通常的压缩形式的声音数据。在由专利文献1公开的发明中,记载了“形成声音压缩信号的音频编码器”,但在长期间的电池驱动中不能使用。通常的音频编码器进行高速傅里叶变换(fft)及离散余弦变换(dct),通过按每个频率以不同的量化比特数进行量化而压缩。但是,其发送数据的通信量不得不超过通过电池驱动能够发送的通信量。
技术实现要素:
所以,本发明的目的是即使能够发送的声音数据的通信量微小也能够判定异常音等的对象的声音。
在本发明的异常音检测系统的优选的例子中,是判定声音数据中包含的异常音的异常音检测系统,构成为,上述异常音检测系统具有终端和服务器;上述终端具有:对数梅尔频谱计算部,以上述声音数据为输入,计算对数梅尔频谱;统计量计算部,根据对数梅尔频谱及其时间差分信号的组,计算表示各频率的振幅时间序列的直流成分、交流成分、噪声成分各自的大小的统计量的组;以及统计量发送部,发送上述统计量的组;上述服务器具有:统计量接收部,接收上述统计量的组;特征量向量生成部,从根据上述统计量的组生成的伪对数梅尔频谱及其时间差分信号的组,提取特征量向量;以及正常音模型学习部,使用上述特征量向量学习正常音模型;上述终端从上述对数梅尔频谱及其时间差分信号的组中提取特征量向量,从上述服务器接收正常音模型,计算上述特征量向量由上述正常音模型生成的概率,如果该概率小于规定的概率,则判定为包含异常音,向上述服务器报告。
此外,作为本发明的另一特征,在上述异常音检测系统中,在上述终端的上述对数梅尔频谱计算部的前级,还具备非稳定成分除去部,该非稳定成分除去部从根据所输入的上述声音数据生成的功率谱除去非稳定音,提取周期稳定的声音。
此外,作为本发明的再另一特征,在上述异常音检测系统的上述服务器中,基于事先从诊断对象设备录音的非压缩的工作音及根据该工作音计算出的表示各频率的振幅时间序列的直流成分、交流成分、噪声成分各自的大小的统计量的组,学习从统计量的组向非压缩的声音的频谱的映像;还具备基于学习的映像,根据服务器接收到的统计量的组生成伪功率谱的伪频谱直接复原部。
在本发明的伪音生成系统的优选的例子中,上述伪音生成系统具有终端和服务器;上述终端具有:对数梅尔频谱计算部,以声音数据为输入,计算对数梅尔频谱;统计量计算部,根据对数梅尔频谱及其时间差分信号的组,计算表示各频率的振幅时间序列的直流成分、交流成分、噪声成分各自的大小的统计量的组;以及统计量发送部,发送上述统计量的组;上述服务器具有:统计量接收部,接收上述统计量的组;伪频谱复原部,对根据上述统计量的组生成的伪对数梅尔频谱乘以梅尔滤波器组的伪逆矩阵而计算伪功率谱;频域-时域变换部,对于上述伪功率谱生成各频率的相位成分并组合,输出时域的数字输出信号;以及伪音再现部,再现上述时域的数字输出信号。
在本发明的伪音生成方法的优选的例子中,特征在于,具备麦克风、ad变换器的终端进行以下处理:根据所输入的音响信号计算功率谱,根据上述功率谱计算对数梅尔频谱,根据上述对数梅尔频谱及其时间差分信号的组,计算表示各频率的振幅时间序列的直流成分、交流成分、噪声成分各自的大小的统计量的组,将上述统计量的组向服务器发送;上述服务器进行以下处理:从上述终端接收上述统计量的组,根据上述统计量的组生成伪对数梅尔频谱,对上述伪对数梅尔频谱乘以梅尔滤波器组的伪逆矩阵而计算伪功率谱,对于上述伪功率谱生成各频率的相位成分并组合而生成时域的数字输出信号,将上述时域的数字输出信号作为伪音进行再现。
发明效果
根据本发明,即使可发送的通信量微小,也能够通过从终端向服务器发送所需的足够的数据并再现根据接收到的数据生成的伪音,也能够确认声音。
附图说明
图1是表示具备伪音生成功能的异常音检测系统的硬件结构的框图。
图2是表示实施例1的音响监视终端和音响监视服务器的处理的结构的框图。
图3是表示实施例2的音响监视终端和音响监视服务器的处理的结构的框图。
图4是表示实施例3的音响监视终端和音响监视服务器的处理的结构的框图。
图5是表示对根据统计量的组将功率谱进行复原的映像进行学习的处理的结构的图。
图6是表示伪频谱直接复原部的内部结构的图。
图7是表示实施例4的音响监视终端和音响监视服务器的处理的结构的框图。
标号说明
101麦克风
102ad变换器
103音响监视终端
104音响监视服务器
105da变换器
106耳机
110对象设备
120网络
201音响信号录音部
202频率变换部
203功率计算部
204对数梅尔频谱计算部
205δ(时间差分)计算部
206统计量计算部
207统计量发送部
208统计量接收部
209时间戳-统计量db
210伪对数梅尔频谱生成部
211伪频谱复原部
212频域-时域变换部
213伪音再现部
214δ(时间差分)计算部
215特征量向量制作部
216正常音模型学习部
217特征量向量制作部
218异常检测部
219异常通知部
220异常显示部
301非稳定成分除去部
401伪频谱直接复原部
402对数梅尔频谱计算部
501振幅时间序列相位的提取
601随机相位生成部
701伪对数梅尔频谱生成部
702δ(时间差分)计算部
具体实施方式
以下,使用附图说明实施例。
[实施例1]
图1是表示具备伪音生成功能的异常音检测系统的硬件结构的框图。
麦克风101将所设置的对象设备110的工作音例如按照每个规定的周期或按照用户指定的每个时刻,作为输入而将模拟输入信号传送给ad变换器102。
ad变换器102将被输入的模拟输入信号变换为数字输入信号,传送给音响监视终端103。
音响监视终端103以数字输入信号为输入,变换为各频率的振幅时间序列的直流成分、周期成分及独立同分布成分各自的统计量(压缩数据),经由包括无线网络的网络120传送给远程地的音响监视服务器104。
音响监视服务器104以上述统计量为输入,将模拟了对象设备的工作音的伪音作为数字输出信号传送给da变换器105。
da变换器105将被输入的数字输出信号变换为模拟输出信号,传送给耳机106,从耳机106输出伪音。
音响监视终端103能够构成于具备电池和无线通信部的通用的计算机终端上,此外,音响监视服务器104能够构成于通用的计算机上,通过将存储在各自的存储部中的异常音检测程序装载到ram并用cpu执行,分别实现以下的各功能部。
图2是表示本实施例的处理的结构的框图。本实施例的处理分为音响监视终端103侧的处理和音响监视服务器104侧的处理。
首先,在音响监视终端103侧,音响信号录音部201通过麦克风101取得工作音,将由ad变换器102将模拟输入信号变换为数字输入信号的音响信号以fft帧尺寸单位向存储器保存。
频率变换部202将数字输入信号按每个帧进行分割,对该帧乘以窗函数,对乘以窗函数后的信号施以短时间傅里叶变换,输出频域信号。如果帧尺寸是n,则频域信号是1个复数与(n/2+1)=k个频率窗口(frequencybin)分别对应的k个复数的组。
功率计算部203根据频域信号计算功率谱x{x其纵轴表示频率,横轴表示时间。是将由按每个帧尺寸(单位期间)制作的频谱(由被分为k个频率窗口的各频率的强度(振幅)的成分构成)排列在各列中,在横轴(时间轴)方向上在解析期间t中按时间序列配置的k行×t列的矩阵。}并输出。
对数梅尔(mel)频谱计算部204根据功率谱x计算对数梅尔频谱y并输出。
这里,通常人的耳朵不是原样听到实际的频率的声音,而发生偏差,接近于可听域的上限的声音听起来比实际的声音偏低。将把该偏差调整为测量人感知的声音的高度的尺度而得到的频率称作梅尔(尺度)频率。将以梅尔尺度仅提取等间隔的特定的频带的滤波器即梅尔滤波器组(bank)适用于功率谱x,计算对数梅尔频谱y。
即,对数梅尔频谱计算部204对于功率谱x施加梅尔滤波器组的各滤波,通过将滤波后的功率相加并取对数,平滑化为对数梅尔频谱y,该对数梅尔频谱y是将下限频率到上限频率通过梅尔(尺度)频率以等间隔分割为m个梅尔频率窗口数而得到的m行×t列的矩阵。
另外,对数梅尔频谱计算部204计算的y,也可以代替对数梅尔频谱而计算倍频带(octaveband)频谱、1/3倍频带频谱、伽马通(gammatone)频谱等的表示频率功率特性的任意的频谱。
δ(时间差分)计算部205根据对数梅尔频谱y计算其时间差分信号δ,输出对数梅尔频谱y和δ的组。
如果将作为m行×t列矩阵的对数梅尔频谱y的各成分值表示为y(m,t),则其时间差分信号δ为m行×(t-1)列的矩阵,计算其成分值δy(m,t)=y(m,t)-y(m,t-1)。
统计量计算部206根据对数梅尔频谱y与时间差分信号δ的组计算各梅尔频率窗口m的统计量的组并输出。
统计量的组例如是梅尔频率窗口m的行的对数梅尔频谱y的各成分值y(m,t)的平均值μ(m)、标准偏差σ(m)、以及时间差分信号δ的梅尔频率窗口m的行的各成分值δy(m,t)的标准偏差σδ(m)。平均值μ(m)表示振幅时间序列的直流成分,标准偏差σ(m)表示独立同分布成分。σδ(m)/σ(m)表示振幅时间序列的周期成分。
统计量发送部207将统计量的组变换为通信包并发送。
接着,在音响监视服务器104侧,统计量接收部208将接收到的通信包变换为统计量的组,例如与作为接收到的日期时间的时间戳一起保存到时间戳-统计量db209中。
伪对数梅尔频谱生成部210从时间戳-统计量db209中读出与用户指定的时刻对应的时间戳的统计量的组,根据读出的统计量的组(μ(m),σ(m),σδ(m))计算伪对数梅尔频谱z并输出。如果假定为设备的工作音是周期稳定的声音,则伪对数梅尔频谱z的各成分z(m,t)可以用数式(1)计算。其中,γ是0~1的常数参数,ω=2sin^-1(0.5σδ(m)/σ(m)),
[数式1]
此外,统计量计算部206也可以根据对数梅尔频谱y,不经由δ(时间差分)计算部205而计算各梅尔频率窗口m的统计量的组并输出。
在此情况下,统计量的组例如是梅尔频率窗口m的行的对数梅尔频谱y的各成分值y(m,t)的平均值μ(m)、通过对y(m,t)的时间t方向的傅里叶变换得到的振幅波谱为最大的交流成分的角频率ω(m)、其振幅a(m)、以及残差e(m,t)的标准偏差σ_e(m)。其中,残差e(m,t)由数式(2)表示。
[数式2]
在此情况下,伪对数梅尔频谱z的各成分z(m,t)可以用数式(3)计算。
[数式3]
其中,
伪频谱复原部211根据伪对数梅尔频谱z计算伪功率谱^x并输出。例如,通过对伪对数梅尔频谱z乘以梅尔滤波器组的伪逆矩阵来计算伪功率谱^x。
频域-时域变换部212以伪功率谱^x为输入,生成其不拥有的各频率的相位成分,将伪功率谱^x与所生成的相位成分组合而输出时域的数字输出信号。在相位成分的生成中,例如使用griffin-lim算法。
这里,伪功率谱^x是频域信号电平,由于相位成分消失,所以使用griffin-lim算法生成相位成分,将时域的音响信号(时域伪音)复原。
伪音再现部213将数字输出信号(时域伪音)通过da变换器105变换为模拟输出信号,从耳机106输出。
在如上述那样能够发送的通信量微小的情况下,由于不能将原始的声音数据或通常的压缩形式的声音数据从终端向服务器传送,所以不能使用它进行用于异常检测的正常音模型的学习。能得到原始的声音数据的仅是初始设置时·初始校正时的录音。所以,以往仅使用初始设置时·初始校正时的声音数据学习了正常音模型。但是,本实施例由于收发的只是统计量的组,所以在通常时也能够持续地储存伪音。并且,能够基于该伪音或根据它计算的特征量向量来学习正常音模型。例如,这样的逐次的学习带来即使有季节变动也不发生异常检测的错误的效果。此外,由于能够使用大量数据进行学习,所以带来使精度显著提高的效果。以下表示带来该效果的一系列的处理。
首先,在音响监视服务器104侧,δ(时间差分)计算部214根据伪对数梅尔频谱z计算其时间差分信号δ,将伪对数梅尔频谱z和δ的组输出。
如果将作为m行×t列的矩阵的伪对数梅尔频谱z的各成分值表示为z(m,t),则其时间差分信号δ成为m行×(t-1)列的矩阵,计算为其成分值δz(m,t)=z(m,t)-z(m,t-1)。
特征量向量制作部215以伪对数梅尔频谱z(梅尔频率窗口m个m×t维)和δ(梅尔频率窗口m个m×(t-1)维)的组为输入,构成将它们在行方向(上下方向)上连结而得到的2m×(t-1)维的矩阵。例如,将伪对数梅尔频谱z的1列(t=0)去掉,作为m×(t-1)维的矩阵而与δ的列数加在一起,将这2个矩阵在行方向(上下方向)上连结而构成2m×(t-1)维的矩阵。
并且,从该2m×(t-1)维的矩阵中,一边一列列地错移,一边提取(t-l)个{在此情况下,例如是(t-l)种}2m×l维的特征量向量。
正常音模型学习部216使用多个特征量向量,学习表示正常状态的分布的正常音模型,将学习后的正常音模型向音响监视终端103的异常检测部218发送。在学习中,为了避免过度学习,不仅使用从一个伪对数梅尔频谱z提取了(t-l)个的特征量向量,还使用从多个伪对数梅尔频谱z{根据从音响监视终端103传送来的统计量的组,随时尽量多地制作伪对数梅尔频谱z,并使用于正常音模型的学习。}提取出的特征量向量。
作为正常音模型,可以使用混合高斯分布(gmm)、1类支持向量分类器、部分空间法、局部部分空间法、k-means分类、deepneuralnetwork(dnn,深度神经网络)autoencoder(自编码器)、convolutionalneuralnetwork(cnn,卷积沉静网络)autoencoder、longshorttermmemory(lstm,长短时记忆)autoencoder、variationalautoencoder(vae,变分自编码器)等。
对于各正常音模型,已知有适合于各个模型的算法而使用该算法。例如,如果是gmm,则通过em算法,进行通过预先设定的群集数的个数的高斯分布的组合进行的拟合。所学习的正常音模型由计算出的模型参数规定。将该模型参数全部保存在未图示的正常音模型数据库中。
保存于正常音模型数据库的模型参数例如在gmm的情况下是q个各群集q=1、…q的平均向量(2m×l维)μq、各群集的协方差矩阵(2m×l×2m×l维)γq、各群集的权重系数(1维)πq。
当由音响监视终端103的异常检测部218执行异常检测处理时,从正常音模型数据库读出相应的正常音模型并发送。
接着,在音响监视终端103中,特征量向量制作部217以从δ(时间差分)计算部205输入的对数梅尔频谱y(梅尔频率窗口m个m×t维)和δ(梅尔频率窗口m个m×(t-1)维)的组为输入,作为将它们在行方向(上下方向)上连结的2m×(t-1)维的矩阵{例如将对数梅尔频谱y的1列(t=0)去掉,作为m×(t-1)维的矩阵而与δ的列数加在一起,将这2个矩阵在行方向(上下方向)上连结而构成2m×(t-1)维的矩阵。},从该2m×(t-1)维的矩阵中,一边一列列地错移,一边提取(t-l)个{有(t-l)种}2m×l维的特征量向量v。
异常检测部218从音响监视服务器104的正常音模型数据库(没有图示)读出事先学习的正常音模型,判定从特征量向量制作部217输入的特征量向量v是属于正常还是属于异常。即,判定根据被输入的工作音制作出的特征量向量v是否能够从正常音模型以充分的概率生成。
例如,在正常音模型是gmm的情况下,通过数式(4)计算根据正常音模型(模型参数θ=((μ1,γ1,π1),…(μq,γq,πq),(μq,γq,πq))生成2m×l维的特征量向量v的概率p(v|θ)。
[数式4]
这里,
[数式5]
如果该概率p(v|θ)例如是规定的概率以上,则异常检测部218判定为诊断对象的机械设备的工作音(音响信号)是正常音。例如如果该概率小于规定的概率,则判定为包含异常音。
在作为正常音模型而使用deepneuralnetwork(dnn)autoencoder的情况下,当通过sgd、momentumsgd、adagrad、rmsprop、adadelta、adam等优化算法输入了正常音的特征量向量时,内部参数被优化为,使输入的特征量向量与输出的特征量向量之间的距离变小。在输入了异常音的特征量向量的情况下,由于可期待其之间的距离变大,所以只要该距离小于规定的值,就判定为包含异常音。
异常通知部219在异常检测部218判定为诊断对象的机械设备的工作音(音响信号)包含异常音的情况下,向音响监视服务器104进行异常报告。
音响监视服务器104的异常显示部220将诊断对象的机械设备发出异常音的情况显示在未图示的显示部上而报告,并且或向外部的监视系统通知。或者,也可以作为包含异常音的概率(异常概率)输出。
具备本实施例的伪音生成功能的异常音检测系统即使能够发送的通信量微小,也能够通过计算输入音的各频率的振幅时间序列的直流成分、周期成分及独立同分布成分各自的统计量并发送的终端、和接收来自终端的上述统计量并基于上述统计量来再现伪音,来事后用户能够听取并确认是怎样的工作音。进而,由于在通常时也能够持续地储存伪音,所以通过逐次的学习,带来即使有季节变动也不发生异常检测的错误的效果。此外,由于能够使用大量数据进行学习,所以带来使精度显著地提高的效果。
[实施例2]
在实施例2中,公开一种具备即使在周围的噪声等的非稳定的声音混入的情况下也能够高精度地生成伪音的具备伪音生成功能的异常音检测系统的例子。与本实施例的实施例1的差异是,通过具备在音响监视终端中的处理流程中将非稳定音除去的非稳定成分除去部,仅提取周期稳定的声音,根据该声音高精度地推测统计量的组,根据该统计量的组高精度地生成伪音。
图3是表示实施例2的结构的框图。
非稳定成分除去部301从由功率计算部203传送来的功率谱x中除去非稳定音,仅提取周期稳定的声音,向对数梅尔频谱计算部204传送。作为具体的处理方法,可以使用harmonic/percussivesoundseparation(hpss,谐波乐器/打击乐器声音分离)及nearestneighborfilter(nnfilter,近邻滤波器)。
hpss是将被输入的功率谱x分解为时间变化平缓的成分和时间变化急剧的成分的算法。被分解为时间变化急剧的成分的声音是要除去的非稳定音,时间变化平缓的成分是接近于希望的周期稳定的声音。进而,将通过hpss提取出的时间变化平缓的成分分解为由nnfilter在功率谱x中反复发生的成分和仅很少地发生的成分。将反复发生的成分判断为希望的周期稳定的声音。
在使用麦克风阵列的情况下,也可以通过由延迟和阵列、mdvr束形成器、gev束形成器仅提取对象设备的方向的声音,来仅提取对象设备的声音。此外,能够根据基于由nnfilter输出的周期稳定的成分和其以外的成分的sn比的时间频率掩模来对mdvr束形成器、gev束形成器的自适应进行控制。通过采用这样的结构,即使在残响较大的环境下也能够由mdvr束形成器、gev束形成器高精度地仅提取对象设备的声音,还能够高精度地仅提取周期稳定的声音,根据该声音高精度地推测统计量的组,根据该统计量的组高精度地生成伪音。
[实施例3]
在实施例3中,公开了具备即使是具有微细的调波构造的工作音也能够高精度地生成伪音的伪音生成功能的异常音检测系统的例子。与本实施例的实施例1的差异是,基于初始设置时·初始校正时的录音预先学习根据统计量的组将频谱复原的映像,音响监视服务器具有使用该映像根据统计量的组将频谱复原的伪频谱直接复原部。
图4是表示实施例3的结构的框图。
伪频谱直接复原部401从时间戳-统计量db209读出与用户指定的时刻对应的时间戳的统计量的组,根据读出的统计量的组(μ(m),σ(m),σδ(m))计算伪功率谱^x并输出。
在实施例1中,在伪频谱复原部211中,对伪对数梅尔频谱z乘以梅尔滤波器组的伪逆矩阵,复原伪功率谱^x。但是,由于是未知的变量的个数(功率谱的频率窗口的个数k)比已知的变量的个数(对数梅尔频谱的梅尔频率窗口的个数m)多的不良设定问题,所以本来不能复原。如果对象设备的工作音不具有微细的调波构造,则即使这样也能够生成充分有用的伪音。但是,在对象设备的工作音具有微细的调波构造的情况下是不充分的。在实施例3中,为了消除该问题,着眼于在初始设置时·初始校正时能够录音非压缩的原始的声音{例如,在音响监视终端103中将评价对象设备的工作音录音到记录介质中,将该记录介质与音响监视服务器104连接而执行学习处理。},基于该原始的声音,预先学习根据统计量的组将功率谱复原的映像。该映像能够补偿在不良设定问题中不足的信息。
对数梅尔频谱计算部402与对数梅尔频谱计算部204同样,根据从伪频谱直接复原部401传送来的伪功率谱^x,计算(伪)对数梅尔频谱z,将计算出的(伪)对数梅尔频谱z向δ计算部214输出。
图5表示对根据统计量的组将功率谱复原的映像进行学习的处理的结构。学习处理由音响监视服务器进行。将在初始设置时·初始校正时录音的非压缩的原始的声音变换为功率谱,施以与音响监视终端同样的对数梅尔频谱计算204、δ计算205、统计量计算206,得到统计量的组(μ(m),σ(m),σδ(m))。与此并行,振幅时间序列相位的提取501对于功率谱的各频率k提取振幅时间序列的相位。具体而言,对于各频率k,对x(k,:)施以fft,得到最大峰值的频率的相位
上述的映像例如能够通过多层神经网络进行模型化。准备以统计量的组(μ(m),σ(m),σδ(m))为输入、输出伪功率谱^x(k,t)那样的多层神经网络。其中,在中间层中分支为各频率k,用与分支的后方的层的各k对应的单元受理
图6表示伪频谱直接复原部401的内部结构。也同时表示了伪频谱直接复原部401的外侧的处理,以便容易与图5比较。对结束了学习的多层神经网络输入统计量的组(μ(m),σ(m),σδ(m))。此外,随机相位生成部601随机地生成各频率k的相位
本实施例的具备伪音生成功能的异常音检测系统即使是具有微细的调波构造的对象设备的工作音也能够高精度地生成伪音。此外,由于一系列的学习处理和复原处理都由音响监视服务器进行,所以有音响监视终端的功耗不增加的优点。此外,由于在正常音模型的学习中使用与压缩前的原始的声音接近的声音,所以有异常检测的精度提高的优点。
[实施例4]
在实施例4中,公开一种具备即使在周围的噪声等的非稳定的声音混入的情况下也能够进行异常检测的伪音生成功能的异常音检测系统的例子。与本实施例的实施例1的差异是,不仅在音响监视服务器侧的伪音生成,在音响监视终端侧的异常检测中也使用根据统计量的组生成的伪音(伪对数梅尔频谱)。
图7是表示实施例4的结构的框图。
伪对数梅尔频谱生成部701根据从统计量计算部206传送来的统计量的组(μ(m),σ(m),σδ(m))计算伪对数梅尔频谱z,向δ(时间差分)计算部702输出。如果假定设备的工作音是周期稳定的声音,则伪对数梅尔频谱z的各成分z(m,t)能够用数式(1)计算。
其中,γ是0~1的常数参数,ω=2sin^-1(0.5σδ(m)/σ(m)),
δ(时间差分)计算部702根据从伪对数梅尔频谱生成部701传送来的伪对数梅尔频谱计算其时间差分信号δ,将伪对数梅尔频谱和δ的组向特征量向量制作部217输出。
另外,本发明并不限定于上述的实施例,而包含各种各样的变形例。例如,上述的实施例是为了容易理解地说明本发明而详细地说明的,并不限定于必定具备所说明的全部的结构。此外,能够将某个实施例的结构的一部分替换为其他实施例的结构,此外,还能够对某个实施例的结构添加其他实施例的结构。此外,关于各实施例的结构的一部分,能够进行其他结构的追加、削除、替换。
此外,上述的各结构、功能、处理部、处理机构等也可以通过将它们的一部分或全部例如用集成电路设计等而由硬件实现。此外,上述的各结构、功能等也可以通过由处理器将实现各个功能的程序解释并执行而由软件来实现。实现各功能的程序、表、文件等的信息能够放置到存储器或硬盘、ssd(solidstatedrive)等的记录装置,或ic卡、sd卡、dvd等的记录介质中。
上述实施例的具备伪音生成功能的异常音检测系统是判定或许包含在设备的工作音中的异常音的例子。根据应用例,并不限于此,还能够应用于判定为在特定的场所或环境中采取的声音数据中包含由通常时学习的正常音模型不能以充分的概率生成的异常音那样的系统也能够应用。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



