
 商标分类
商标分类  商标转让
商标转让 
声音处理装置以及翻译装置的制作方法
 2021-01-28 13:01:16|
2021-01-28 13:01:16| 278|
278| 起点商标网
起点商标网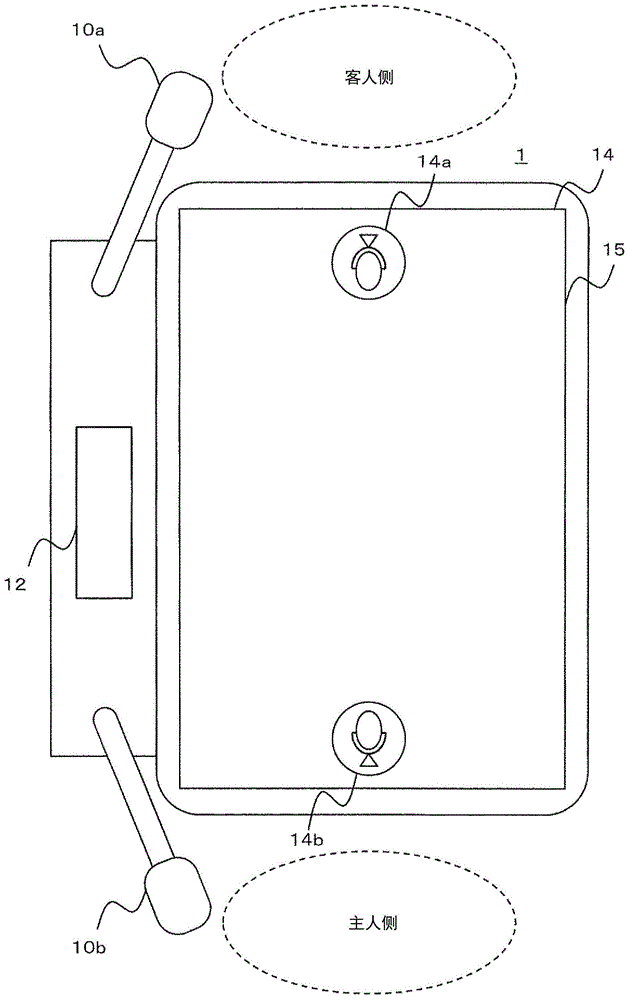
本公开提供一种能够使说话者注意到以过大的音量输入声音的声音处理装置。
背景技术:
专利文献1公开了一种能够将基于一个语言的输入声音翻译为基于多个语言的声音的电视系统。电视系统将输入声音信号分解为音量、音调以及音色。电视系统输出与分解的音量、音调以及音色融合的基于多个语言的翻译声音信号。
在先技术文献
专利文献
专利文献1:jp特开2014-21485号公报
技术实现要素:
-发明要解决的课题-
提供一种能够使说话者注意到以过大的音量输入声音的声音处理装置。
-解决课题的手段-
本公开的声音处理装置具备输入部、处理部、电平检测部、输出声音转换部和输出部。输入部输入声音,生成输入声音信号。处理部基于输入声音信号,生成第1输出声音信号。电平检测部检测输入声音信号中信号电平大于规定电平的第1期间。输出声音转换部在第1输出声音信号中,针对第1期间所对应的第2期间的信号电平,进行与其他期间的信号处理不同的信号处理,生成第2输出声音信号。输出部输出基于第2输出声音信号的声音。
-发明效果-
通过本公开,能够提供一种能够使说话者注意到以过大的音量输入了声音的声音处理装置。
附图说明
图1是表示翻译装置的外观的图。
图2是表示翻译系统的结构的框图。
图3a是表示输入到翻译装置的适当电平的输入声音数据所示的声音信号的波形的图。
图3b是表示输入到翻译装置的过大电平的输入声音数据所示的声音信号的波形的图。
图4是表示基于实施方式1所涉及的翻译装置的翻译处理的流程图。
图5a是表示输入到实施方式1所涉及的翻译装置的输入声音数据所示的声音信号的波形的图。
图5b是表示实施方式1所涉及的翻译装置中从输入声音数据生成的声音合成数据所示的声音信号的波形的图。
图5c是表示实施方式1所涉及的翻译装置中从声音合成数据生成的输出声音数据所示的声音信号的波形的图。
图6是表示实施方式1所涉及的翻译装置中的从声音合成数据生成输出声音数据的处理的流程图。
图7是表示对声音合成数据的输出电平进行放大的处理的图。
图8a是表示输入到实施方式2所涉及的翻译装置的声音合成数据所示的声音信号的波形的图。
图8b是表示实施方式2所涉及的翻译装置中从输入声音数据生成的声音合成数据所示的声音信号的波形的图。
图8c是表示实施方式2所涉及的翻译装置中从声音合成数据生成的输出声音数据所示的声音信号的波形的图。
图9是表示实施方式2所涉及的翻译装置中的从声音合成数据生成输出声音数据的处理的流程图。
图10是表示实施方式3所涉及的翻译系统的结构的框图。
图11是表示实施方式3所涉及的翻译装置中的动作的流程图。
图12是表示实施方式4所涉及的翻译装置中在显示器显示注意唤起消息的状态的图。
图13是表示实施方式4所涉及的翻译装置的动作的流程图。
具体实施方式
以下,适当地参照附图,详细说明实施方式。其中,可能省略非必要详细的说明。例如,可能省略已知事项的详细说明、针对实质相同的结构的重复说明。这是为了避免以下的说明不必要地变得冗长,使本领域技术人员容易理解。
另外,发明人为了本领域技术人员充分理解本公开而提供附图以及以下的说明,并不意图通过这些来限定权利要求书所述的主题。在以下的各实施方式中,作为声音处理装置的实施方式,说明翻译装置。
(实施方式1)
1.结构
1-1.翻译装置的概要
图1是表示作为实施方式1所涉及的声音处理装置的一实施方式的翻译装置的外观的图。图1所示的翻译装置1是对以第1语言说话的主人与以第2语言说话的客人之间的会话进行翻译的装置。经由翻译装置1,主人以及客人能够面对面并以各自的语言进行会话。翻译装置1进行从第1语言向第2语言的翻译、从第2语言向第1语言的翻译。翻译装置1通过声音来输出翻译结果。主人以及客人能够通过从翻译装置1输出的声音,相互掌握说出的内容。例如,第1语言是日语,第2语言是英语。
翻译装置1具备:客人侧话筒10a、主人侧话筒10b、扬声器12、显示器14、触摸面板15。客人侧话筒10a以及主人侧话筒10b是输入部的一个例子。扬声器12是输出部的一个例子。
客人侧话筒10a将客人说出的声音转换为作为数字声音信号的输入声音数据。主人侧话筒10b将主人说出的声音转换为作为数字声音信号的输入声音数据。即,客人侧话筒10a以及主人侧话筒10b作为对声音处理装置1输入声音数据的声音输入部而发挥功能。
显示器14基于客人或者主人的操作,显示文字串或图像。显示器14包含液晶显示器或者有机el显示器等。
触摸面板15与显示器14重叠配置。触摸面板15能够接受基于客人或者主人的触摸操作。
扬声器12是输出声音的装置,例如,输出表示翻译结果的内容的声音。
在图1中,翻译装置1在显示器14,显示客人侧的声音输入按钮14a和主人侧的声音输入按钮14b。翻译装置1经由触摸面板15来检测声音输入按钮14a、14b的按下。
翻译装置1若检测基于客人的声音输入按钮14a的按下,则从客人侧话筒10a开始输入声音数据的获取。翻译装置1若在输入声音数据的获取中再次检测声音输入按钮14a的按下,则结束输入声音数据的获取。翻译装置1例如进行从英语向日语的翻译处理,将日语的输出声音数据从扬声器12输出。
此外,翻译装置1若检测基于主人的声音输入按钮14b的按下,则从主人侧话筒10b开始输入声音数据的获取。翻译装置1若在输入声音数据的获取中再次检测声音输入按钮14b的按下,则结束输入声音数据的获取。翻译装置1例如进行从日语向英语的翻译处理,将英语的输出声音数据从扬声器12输出。另外,翻译装置1也可以通过检测来自客人侧话筒10a以及主人侧话筒10b的输入声音数据的音量电平为规定的阈值以下,来自动地结束输入声音数据的获取。
1-2.翻译系统的结构
图2是表示本实施方式所涉及的翻译系统的结构的框图。图2所示的翻译系统除了图1的翻译装置1,还具备声音识别服务器3、翻译服务器4、声音合成服务器5。
声音识别服务器3是从翻译装置1经由网络2而接收输入声音数据、对输入声音数据进行声音识别并生成文字串的声音识别数据的服务器。
翻译服务器4是从翻译装置1经由网络2而接收声音识别数据、对声音识别数据进行翻译并生成文字串的翻译数据的服务器。在本实施方式中,翻译服务器4将日语的文字串翻译为英语的文字串,或者将英语的文字串翻译为日语的文字串。
声音合成服务器5是从翻译装置1经由网络2而接收文字串的翻译数据、对翻译数据进行声音合成并生成声音合成数据的服务器。
1-3.翻译装置的内部结构
翻译装置1还具备存储部23、通信部18和控制部20。
存储部23包含闪存、ssd(solidstatedevice)以及/或者硬盘等。存储部23对为了实现翻译装置1的各种功能所必须的程序以及数据进行存储。
控制部20例如包含与软件配合来实现规定的功能的cpu或者mpu等,对翻译装置1的整体动作进行控制。控制部20通过对存储于存储部23的规定的程序以及数据等进行读取并执行运算处理,来实现各种功能。例如,控制部20作为功能性结构,包含电平检测部21、翻译部22和输出声音转换部24。控制部20也可以是被专用设计为实现规定的功能的电子电路。即,控制部20也可以包含cpu、mpu、gpu、dsp、fpga或者asic等各种处理器。翻译部22是处理部的一个例子。
电平检测部21对主人或者客人输入的输入声音数据的输入电平是否超过规定的阈值进行检测。
翻译部22与外部的声音识别服务器3、翻译服务器4以及声音合成服务器5协作并实施翻译处理。具体而言,翻译部22与声音识别服务器3、翻译服务器4以及声音合成服务器5协作,进行从经由话筒10a、10b而输入的声音数据来生成对表示翻译结果的内容的声音进行生成的数据即声音合成数据的处理。
输出声音转换部24基于电平检测部21所检测到的声音的输入电平,将从声音合成服务器5经由网络2而接收的声音合成数据转换为输出声音数据。
通信部18通过控制部20的控制,从翻译装置1经由网络2来向外部的服务器发送各种信息,或者从外部的服务器接收各种信息。通信部18包含3g、4g、wi-fi、bluetooth(注册商标)、lan等以规定的通信标准进行通信的通信模块、通信电路。
2.本公开要解决的课题
在如以上那样构成的翻译处理系统中,在客人或者主人以过大的音量向翻译装置1输入声音的情况下,声音处理系统有时不能适当地翻译被输入的声音。以下对此进行说明。
图3a、图3b是表示输入到翻译装置1的声音数据所示的声音信号的波形的图。图3a表示针对适当的输入电平、即规定的允许输入电平以下的电平的声音的声音数据所示的声音信号的波形。在图3a的声音数据中,波形未饱和,未变形。在该情况下,翻译处理系统能够正确地识别声音数据。
另一方面,图3b表示以过大的输入电平、即超过允许输入电平的电平的声音被输入时得到的声音数据所示的声音信号的波形。在图3b的声音数据中,由于波形饱和并变形,因此担心声音处理系统错误识别本来的声音信号的波形。
鉴于上述的课题,本公开提供一种能够使客人或者主人注意到以过大的音量输入了声音数据的声音处理装置。以下,对本实施方式所涉及的翻译装置1的动作进行说明。
3.动作
参照图4~7来说明翻译装置1的动作。图4是表示基于本实施方式所涉及的翻译装置1的翻译处理的流程图。以下,使用图4,对基于翻译装置1的翻译处理进行说明。
最初,翻译装置1的控制部20若检测声音输入按钮14a或者声音输入按钮14b的按下,则经由主人侧话筒10a或者客人10b来获取说话者即主人或者客人所发出的声音的输入声音数据(s101)。
然后,控制部20经由网络2来向声音识别服务器3发送输入声音数据。声音识别服务器3经由网络2来接收输入声音数据,基于输入声音数据来进行声音识别处理,转换为文字串的声音识别数据(s102)。声音识别数据是文本形式的数据。翻译装置1的控制部20经由网络2,从声音识别服务器3接收声音识别数据,将接收的声音识别数据发送给翻译服务器4。
翻译服务器4经由网络2来接收声音识别数据,对声音识别数据进行翻译并转换为文字串的翻译数据(s103)。翻译数据是文本形式的数据。翻译装置1的控制部20经由网络2来从翻译服务器4接收翻译数据,将接收的翻译数据发送给声音合成服务器5。
声音合成服务器5经由网络2来接收翻译数据,基于翻译数据来进行声音合成并转换为声音合成数据(s104)。声音合成数据是用于再现声音的数据。翻译装置1的控制部20经由网络2来从声音合成服务器5接收声音合成数据。
然后,翻译装置1的控制部20根据声音合成数据生成输出声音数据(s105)。特别地,控制部20在判断为被输入的声音的输入电平过大时,对声音合成数据进行调制并生成输出声音数据以使得该事实被传递至说话者。后面叙述这样的输出声音数据的生成处理的详细。
最后,翻译装置1的控制部20再现输出声音数据,使表示翻译结果的声音从扬声器12输出(s106)。
如以上那样,翻译装置1将以第1语言说出的声音的内容翻译为第2语言,通过声音来输出翻译的结果。
以下,对上述的翻译处理中的根据声音合成数据生成输出声音数据的处理(图4的步骤s105)的详细进行说明。
图5a、图5b、图5c是用于对基于翻译装置1的声音处理进行说明的图。图5a表示输入声音数据所示的声音信号的波形。图5b表示从图5a的输入声音数据转换的声音合成数据所示的声音信号的波形。图5c表示从图5b的声音合成数据转换的输出声音数据所示的声音信号的波形。图6是表示本实施方式所涉及的根据声音合成数据生成输出声音数据的处理的流程图。
在图6中,最初,控制部20的电平检测部21检测输入声音数据所示的声音的输入电平超过规定电平的期间即过大期间(第1期间)、和从输入声音的开始时刻到各过大期间的开始时刻为止的经过(s201)。在图5a的例子中,电平检测部21检测过大期间ta、tb、tc、到各过大期间为止经过时间ta、tb、tc。
接下来,控制部20的输出声音转换部24针对声音合成数据,对输入声音数据的过大期间所对应的放大期间(第2期间)的输出电平进行放大,生成输出声音数据(s202)。在图5b、图5c的例子中,输出声音转换部24在图5b的声音合成数据中,在从声音合成数据所示的声音的开始时刻起经过了经过时间ta的时刻至与过大期间ta相等的长度的放大期间tas的期间,输出声音电平被放大,图5c的输出声音数据被生成。同样地,在图5c的输出声音数据中,针对图5b的声音合成数据,在从声音合成数据所示的声音的开始时刻起经过了经过时间tb、tc的时刻至与过大期间tb、tc相等的长度的放大期间tbs、tcs的期间,其输出声音电平被放大。
另外,在声音合成数据的输出电平的放大处理中能够使用现有的技术。例如,能够使用公知的压缩处理技术来实现。图7是用于对公知的压缩处理进行说明的图。如图7所示,在声音信号80a中将信号电平超过规定电平的部分剪切,生成声音信号80b。在声音信号80b中,波形81、82的部分被剪切。然后,将振幅较大的部分被剪切的声音信号80b放大到规定的放大电平,生成放大的声音信号80c。这样,能够放大声音信号。
如以上那样,本实施方式的翻译装置1在输入声音具有超过规定电平的过大期间的情况下,在输出声音中,使超过规定电平的过大期间所对应的放大期间的电平增大。输入声音的说话者、即主人或者客人通过听到一部分的电平被增大的声音,能够意识到自身发出的声音过大。此时,能够期待输入声音的说话者、即主人或者客人远离话筒10b或10a、或者减小音量,以使得成为适当的输入电平,来调整输入电平。
4.总结
如以上说明那样,翻译装置1具备:客人侧话筒10a、主人侧话筒10b、翻译部22、电平检测部21、输出声音转换部24、以及扬声器12。客人侧话筒10a以及主人侧话筒10b输入表示以第1语言的说话内容的声音,生成输入声音信号。翻译部22生成表示将输入声音信号所示的说话内容翻译为第2语言的说话内容的结果的声音信号即第1输出声音信号。电平检测部21对输入声音信号中信号电平比规定电平大的过大期间进行检测。输出声音转换部24在第1输出声音信号中,通过比其他期间的放大电平大的放大电平,将过大期间(第1期间)所对应的放大期间(第2期间)的信号电平放大,生成第2输出声音信号。扬声器12输出基于第2输出声音信号的声音。
此时,输入声音信号中的过大期间的长度与第2输出声音信号中的放大期间的长度一致,并且输入声音信号中从输入声音信号的开始时刻到过大期间的开始时刻的长度、与第2输出声音信号中从第2输出声音信号的开始时刻到放大期间的长度一致。
由此,本实施方式的翻译装置1在输入声音具有超过规定电平的过大期间的情况下,在输出声音中,使超过规定电平的过大期间所对应的放大期间的电平增大。输入声音的说话者、即主人或者客人通过听到一部分的电平被增大的声音,能够注意到自身发出的声音过大。此时,能够期待输入声音的说话者、即主人或者客人远离话筒10b或10a、或者减小音量来调整输入电平,以使得成为适当的输入电平。
(实施方式2)
实施方式1的翻译装置1在输出声音数据中,在与输入声音数据的过大期间相同的开始定时以相同的长度的放大期间放大声音电平。输入声音数据与输出声音数据的整体的长度未必相同。因此,在实施方式1那样的放大方法中,难以根据输出声音来识别输入声音整体中的哪个部分的输入电平过大。因此,在本实施方式中,设定放大期间,以使得过大期间相对于输入声音的整体期间的相对位置关系以及长度的比例与放大期间相对于输出声音的整体期间的相对位置关系以及长度的比例相等。由此,能够容易根据输出声音来识别输入声音整体中的哪个部分的输入电平过大。以下,对本实施方式的处理具体进行说明。另外,本实施方式的翻译系统的硬件结构与实施方式1的相同。
图8a、图8b、图8c是表示实施方式2所涉及的翻译装置1所处理的输入声音数据、声音合成数据和输出声音数据所示的声音信号的波形的图。图9是表示实施方式2的翻译装置1中的输出声音数据的生成处理的流程图。
在图9中,最初,翻译装置1的控制部20的电平检测部21对输入声音数据的持续时间进行检测(s301)。在图8a的例子中,控制部20的电平检测部21对输入声音数据的持续时间t进行检测。
接下来,电平检测部21针对输入声音数据,对输入电平超过规定电平的过大期间、和到各过大期间的开始时刻的经过时间进行检测(s302)。在图8a的例子中,电平检测部21检测过大期间ta、tb、tc和到各过大期间的开始时刻为止的经过时间ta、tb、tc。
接下来,电平检测部21对声音合成数据的持续时间进行检测(s303)。在图8a的例子中,电平检测部21检测声音合成数据的持续时间t’。
接下来,控制部20的输出声音转换部24基于下式,针对声音合成数据,计算放大期间ta’、tb’、tc’以及到各放大期间的经过时间ta’、tb’、tc’(s304)。
ta’=ta×t’/t
tb’=tb×t’/t
tc’=tc×t’/t
ta’=ta×t’/t
tb’=tb×t’/t
tc’=tc×t’/t
控制部20的输出声音转换部24针对声音合成数据,将放大期间中的声音输出电平放大,生成输出声音数据(s305)。在图8c的例子中,针对图8b的声音合成数据,在从输出声音的开始时刻到时间ta’经过后的放大期间ta’的期间,放大输出声音电平。同样地,在图8c的输出声音数据中,针对图8b的声音合成数据,在从声音合成数据的开始时刻到时间tb’经过后的放大期间tb’的期间、从声音合成数据的开始时刻到时间tc’经过后的放大期间tc’的期间,放大输出声音电平。
通过如以上那样控制,在与输入声音中的过大期间对应的、输出声音的放大期间中,输出电平被放大。由此,说话者能够根据输出声音来识别输入声音整体中的哪个部分的输入电平过大。
(实施方式3)
以下,对本公开的另一实施方式进行说明。声音处理装置1以及声音处理系统的结构与实施方式1相同。
实施方式1的翻译装置1对翻译后的声音合成数据的一部分进行放大并从扬声器12输出,从而使说话者注意到以过大的音量输入了声音数据。与此相对地,本实施方式的翻译装置1在说话者输入声音数据时,从扬声器12输出以过大的音量输入了声音数据这一内容的消息。由此,针对说话者,使其注意到以过大的音量输入了声音数据。
图10是表示本实施方式所涉及的翻译系统的结构的框图。在图10的翻译装置1中,控制部20相比于图1的控制部20,还具备警告部25。警告部25在说话者输入声音数据时,经由扬声器12来输出以过大的声音输入了声音数据这一内容的消息。
图11是表示本实施方式所涉及的翻译装置1的动作的流程图。
若检测声音输入按钮14a、14b的按下,则翻译装置1的控制部20经由客人侧话筒10a或者主人侧话筒10b来输入由说话者输入的声音(s401)。
此时,在声音输入按钮14a被按下的情况下,从客人侧话筒10a输入的声音的信息被输入到翻译装置1。在声音输入按钮14b被按下的情况下,从主人侧话筒10b输入的声音被输入到翻译装置1。
控制部20对从话筒10a或者10b输入的声音的输入电平进行检测(s402),对检测的输入电平与规定的阈值进行比较(s403)。
在被输入的声音的输入电平超过规定的阈值的情况下(s403中为否),控制部20从扬声器12输出以过大的音量进行了声音数据输入这一内容的注意唤起消息(s404)。
另一方面,在被输入的声音的输入电平为规定的阈值以下的情况下(s403中为是),控制部20判断是否进行了指示声音输入的结束的操作(s405)。所谓指示声音输入的结束的操作,是指在从客人侧话筒10a获取声音时按下声音输入按钮14a的操作、或者在从主人侧话筒10b获取声音时按下声音输入按钮14b的操作。
控制部20在检测到进行了指示声音输入的结束的操作的情况下(s405中为是),结束本处理。在未检测到进行了指示声音输入的结束的操作的情况下(s405中为否),控制部20返回到s401,反复上述的处理。
如以上那样,本实施方式的翻译装置1通过声音消息,能够向说话者传递以过大的音量进行了声音数据输入这一内容,能够使其引起注意。
另外,也可以将本实施方式中的用于注意唤起的声音消息的输出所涉及的控制应用于实施方式1、2的翻译装置。
(实施方式4)
以下,对本公开的另一实施方式进行说明。声音处理装置1以及声音处理系统的结构与实施方式3相同。
实施方式3的翻译装置1通过从扬声器12输出注意唤起消息,使说话者注意到以过大的音量输入了声音数据。与此相对地,本实施方式的翻译装置1如图12所示,通过将注意唤起消息显示于显示器14,来使说话者注意到以过大的音量输入了声音数据。
图13是表示本实施方式所涉及的翻译装置1的动作的流程图。在图12中,本变形例所涉及的声音处理装置1取代图11的步骤s403以及s404的处理,进行步骤s403a、s403b、s404a以及s404b的处理。
翻译装置1的控制部20输入声音(s401),检测到输入的声音的电平(s402)后,对单位期间内的输入电平超过阈值的次数进行计数(s403a)。在判断为该次数是规定次数以下的情况下(s403a中为是),控制部20不在显示器14显示注意唤起消息(s404a)。
另一方面,在判断为单位期间内的输入电平超过阈值的次数大于规定次数的情况下(s403b中为否),控制部20将注意唤起消息显示于显示器14(s404b)。步骤s404a或者s404b之后,进行声音输入是否结束的处理(s405)。作为注意唤起消息,例如图13中记载那样,在显示器14显示“请远离话筒!”这一消息。
如以上那样,本实施方式的翻译装置1通过注意唤起消息的显示,能够向说话者传递以过大的音量进行了声音数据输入这一内容,能够使其引起注意。
另外,也可以将本实施方式中的注意唤起消息的显示所涉及的控制应用于上述的实施方式的翻译装置。
(其他实施方式)
如以上那样,作为本申请中公开的技术的示例,说明了实施方式。但是,本公开中的技术并不局限于此,也能够应用于适当地进行了变更、置换、附加、省略等的实施方式。此外,也能够将上述实施方式中说明的各结构要素组合,设为新的实施方式。
在上述的实施方式中,翻译装置1作为主人用和客人用而具备两个话筒,但也可以仅具备兼用于主人用和客人用的一个话筒。
实施方式1的翻译装置1在将声音合成数据的输出电平放大的处理中,将对声音合成数据的音质、音量的影响少的、超过规定的电平的部分剪切并放大到规定的放大电平,但并不限定于此。例如,也可以去除对声音合成数据的音质有影响的部分。
在上述的实施方式中,用于对声音合成数据所示的声音中的过大期间进行判定的规定电平固定,但也可以使该规定电平根据输入声音数据的输入电平而变化。例如,信号电平越大,则将规定电平设定得越大。由此,能够起到信号电平的急剧变化时也判定为过大期间这一效果。
在上述的实施方式中,翻译装置1与外部的声音识别服务器3、翻译服务器4以及声音合成服务器5协作并实施了翻译处理,但各服务器的功能不是必须设置于云上。翻译装置1也可以安装声音识别服务器3、翻译服务器4以及声音合成服务器5的功能之中的至少一个。
在实施方式1、2中,将声音合成数据所示的声音信号的放大期间的信号电平放大,但也可以不将放大期间中的声音信号放大而使其变形。
在上述的实施方式中,将第1语言设为日语,将第2语言设为英语,但第1语言与第2语言的组合并不限定于此。第1语言和第2语言的组合能够包含从包含日语、英语、中文、韩语、泰语、印度尼西亚语、越南语、西班牙语、法语、缅甸语等的多个语言群之中任意选择的两个语言。
在上述的实施方式中,作为声音处理装置的一个例子,表示了翻译装置,但本公开的声音处理装置并不限定于翻译装置。上述的实施方式中公开的技术思想能够应用于经由话筒那样的声音输入装置来输入声音信号并进行基于输入的声音信号的处理的任意的电子设备。例如,能够应用于假定店铺、酒店等处的利用的对话型的会话装置。
在上述的实施方式中,输出声音转换部(24)在第1输出声音信号中,将放大期间(第2期间)的信号电平以比其他期间的放大电平大的放大电平进行放大并生成了第2输出声音信号,但也可以将第2期间的信号转换为乐器的声音、动物的叫声以及声学机器的噪声音等不基于输入声音信号的声响信号。换句话说,输出声音转换部(24)在第1输出声音信号中,对第2期间的信号进行与其他期间的信号处理不同的信号处理并生成第2输出声音信号即可。由此,翻译装置1能够使说话者注意到以过大的音量输入了声音。
如以上那样,作为本公开中的技术的示例,说明了实施方式。为此,提供了附图以及详细的说明。
因此,附图以及详细的说明中所述的结构要素之中,不仅包含了为了课题解决所必须的结构要素,为了示例上述技术还包含了为了课题解决不是必须的结构要素。为此,这些非必须的结构要素被记载于附图、详细的说明,但不应直接将这些非必须的结构要素认定为必须。
此外,上述的实施方式用于示例本公开中的技术,因此在权利要求书或者其等同的范围内能够进行各种变更、置换、附加、省略等。
产业上的可利用性
本公开能够应用于经由话筒那样的声音输入装置来输入声音信号并进行基于输入的声音信号的处理的任意的电子设备。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



