
 商标分类
商标分类  商标转让
商标转让 
一种保护隐私的语音交互系统及方法与流程
 2021-01-28 13:01:09|
2021-01-28 13:01:09| 237|
237| 起点商标网
起点商标网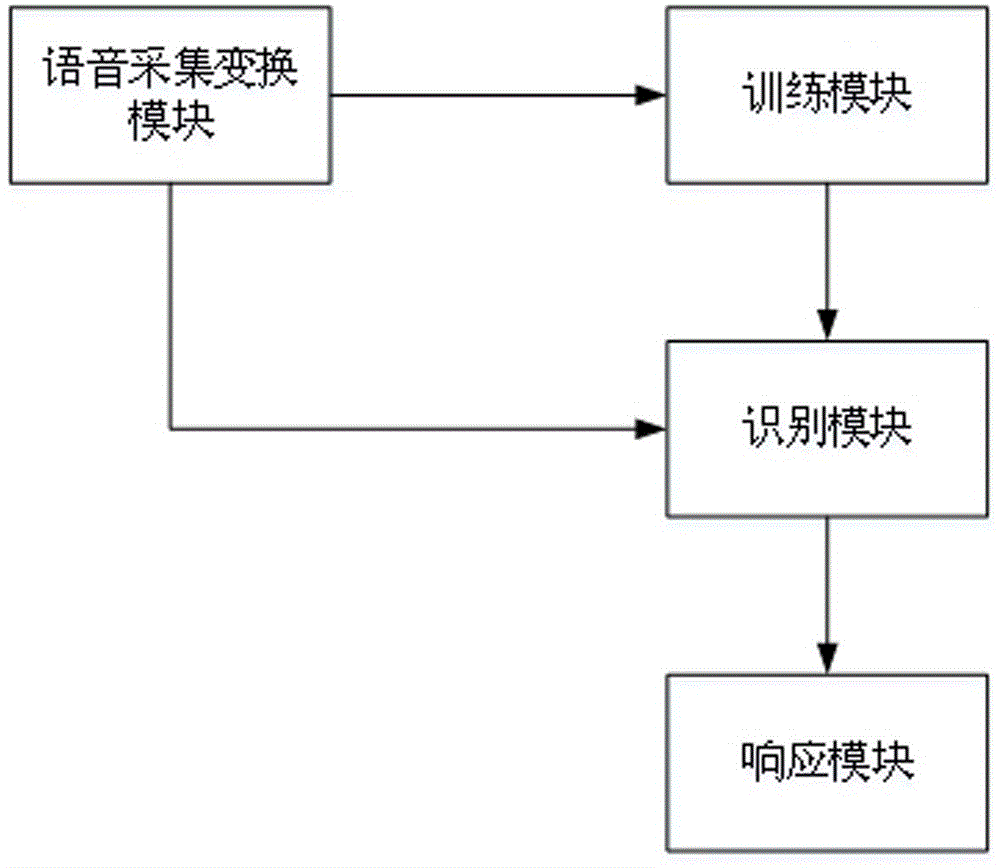
本发明属于语音交互和安全技术领域,具体涉及一种针对语音交互系统保护用户语音数据隐私需求而对用户语音数据提供安全保护的保护隐私的语音交互系统及方法。
背景技术:
语音作为场景交互的入口,往往存在令人难以防范的隐私安全隐患。随着ai语音技术的发展,语音交互系统的使用越来越广泛,而用户语音隐私泄露的问题也愈加严重。例如智能手机、智能音箱,车载智能语音终端等等,都有可能经用户允许,或者在未经允许的情况下,将用户录音上传到服务器。当我们在享受智能带给我们便捷生活的同时,我们的语音信息也很容易被泄露和非法使用。利用一个人的真实语音数据,很容易分析得到这个人的年龄、性别等信息,在有些情况下还可以通过声纹信息得到说话人的真实身份,个人隐私严重泄露;此外,还可以利用人工智能,根据一个人的真实语音数据,通过算法伪造出具有这个人个性特征的语音,令人真假难辨;如果伪造语音用于诈骗、散布谣言等,可能会造成严重的社会影响。
现有技术中,为保护用户隐私,常常采用将语音数据加密后再上传或者存储,使用时再解密的方式,虽然能保证语音数据在上传或者存储过程中的安全性,但却无法防止拥有和使用语音数据的一方滥用语音数据和暴露用户隐私。现实中,对语音数据泄露隐私的疑虑有很多来自能拥有和使用用户语音数据的公司的行为,如不经允许上传语音数据等。因而,需要对语音数据提供从源头开始的保护,使用户隐私不会悄无声息地通过语音数据轻易泄露。
技术实现要素:
本发明的目的是针对语音交互系统保护用户语音数据隐私的需求而提供一种保护隐私的语音交互系统和方法,可以从语音采集的步骤起,对用户语音数据提供隐私保护,避免用户语音数据被滥用,保护用户隐私。
为了实现上述目的,本发明技术方案是这样实现的:
本发明提供了一种保护隐私的语音交互系统,包括语音采集变换模块、训练模块、识别模块、响应模块;所述语音采集变换模块与训练模块相连接,训练模块又与识别模块相连接,识别模块与响应模块相连接;同时所述语音采集变换模块还与识别模块相连接;其中,
所述语音采集变换模块用于采集语音信号并对采集到的语音信号进行个性特征变换;
所述训练模块使用由语音采集变换模块采集并进行个性特征变换后的语音信号作为训练语音数据,通过机器学习方法训练识别模型;
所述识别模块使用训练模块训练得到的识别模型,通过语音识别算法对用户语音数据进行语音识别,并将识别结果发送给响应模块;其中用户语音数据是来自于由语音采集变换模块采集并进行个性特征变换后的语音信号;
所述响应模块用于根据识别模块发送的识别结果,按照预设程序进行相应的响应。
进一步的,所述个性特征变换是指对语音的音色和/或韵律特征的变换,包括对语音的频谱特征、基频特征、共振峰特征、音素时长特征、基频轨迹特征、能量轮廓特征中一项或多项的变换。
进一步的,所述个性特征变换的算法及算法参数由用户在算法选择范围及算法参数的允许取值范围内选取。
进一步的,所述识别模型用于进行语音内容识别和/或验证、语种识别和/或验证、方言识别和/或验证中的一项或多项。
进一步的,所述响应模块按照预设程序进行的相应的响应,包括语音应答、同声传译、执行语音指令、根据语音识别结果执行相应的策略、上传语音数据、上传语音识别结果中的一项或多项。
进一步的,所述语音采集变换模块包括用于使用数字信号处理方法对数字语音进行个性特征变换的数字信号处理单元;所述语音采集变换模块先将采集的模拟语音信号进行模数转换,然后再通过所述数字信号处理单元对模数转换后的数字语音信号进行个性特征变换。
进一步的,所述语音采集变换模块包括用于对模拟语音进行个性特征变换的模拟信号处理电路,所述语音采集变换模块先通过模拟信号处理电路对采集的模拟语音信号进行个性特征变换,然后再对个性特征变换后的语音信号进行模数转换。
进一步的,所述语音采集变换模块包括第一语音采集变换单元和第二语音采集变换单元,其中所述第一语音采集变换单元与所述训练模块连接,所述第二语音采集变换单元与所述识别模块连接;所述第一语音采集变换单元和所述第二语音采集变换单元采用相同的个性特征变换算法。
进一步的,所述语音交互系统通过深度学习方法进行识别模型的训练和语音识别,所述训练模块具有预训练模型,训练模块在预训练模型的基础上,使用由语音采集变换模块采集并进行个性特征变换后的语音信号作为训练语音数据,训练得到所述识别模型。
本发明另一方还提供了一种保护隐私的语音交互方法,包括以下步骤:
步骤1)、设定个性特征变换处理算法,并将语音信号采集功能与所述个性特征变换算法集成,使采集输出数据为经过所述个性特征变换算法进行个性特征变换后的语音数据;
步骤2)、使用经过所述个性特征变换算法进行个性特征变换后的语音数据作为训练语音数据,通过机器学习方法训练识别模型;
步骤3)、进行语音交互时,使用训练得到的所述识别模型,通过语音识别算法对用户数据进行识别,并根据识别结果按照预设程序进行相应的响应;其中用户数据是对用户语音进行采集并使用所述个性特征变换算法进行个性特征变换后的语音数据。
本发明相对现有技术具有突出的实质性特点和显著的进步,具体地说:
1.本发明技术方案中语音交互系统采集得到和使用的语音数据均不是原始语音数据,而是经过个性特征变换后的语音数据,既难以用来识别用户的个人相关信息,无法被用来伪造用户的语音,大大减少了语音数据被滥用的可能性。经个性特征变换后的语音数据即使需要被上传,或者存储在云端,也能在很大程度上保护用户隐私。
2.本发明技术方案从技术角度对用户的语音数据提供了从源头开始的隐私保护,即使是拥有和使用用户语音数据的一方,也无法获得用户的原始语音数据,有利于用户的隐私保护和语音交互系统的推广应用。
本发明针对语音交互系统保护用户语音数据隐私需求而对用户语音数据提供安全保护,本发明将语音采集和语音个性特征变换功能集成,使采集输出数据为经过个性特征变换的语音数据,对语音的音色和/或韵律特征进行了变换;语音交互系统训练识别模型和进行识别时,使用的数据均为经过个性特征变换后的语音数据,由于语音交互系统采集得到和使用的语音数据均不是原始语音数据,而是经过个性特征变换后的语音数据,既难以用来识别用户的个人身份、年龄、性别相关信息,又无法被用来伪造用户的语音,大大减少了语音数据被滥用的可能性,从技术角度、从源头开始对用户的语音数据提供了隐私保护。
附图说明
图1是根据本发明一个实施例的一种保护隐私的语音交互系统的示意图。
图2是根据本发明另一个实施例的一种保护隐私的语音交互系统的示意图。
图3是根据本发明另一个实施例的一种保护隐私的语音交互方法的示意图。
具体实施方式
实施例1:本实施例提供了一种保护隐私的语音交互系统,如图1所示,包括语音采集变换模块、训练模块、识别模块、响应模块;所述语音采集变换模块与训练模块相连接,训练模块又与识别模块相连接,识别模块与响应模块相连接;同时所述语音采集变换模块还与识别模块相连接;其中,
所述语音采集变换模块用于采集语音信号并对采集到的语音信号进行个性特征变换;并设定个性特征变换算法及算法参数;
所述训练模块使用由所述语音采集变换模块采集并进行个性特征变换后的语音信号作为训练语音数据,通过机器学习方法训练识别模型;
所述识别模块使用所述训练模块训练得到的所述识别模型,通过语音识别算法对用户语音数据进行语音识别,并将识别结果发送给所述响应模块;其中用户语音数据是来自于由所述语音采集变换模块采集并进行个性特征变换后的语音信号;
所述响应模块用于根据所述识别模块发送的识别结果,按照预设程序进行相应的响应。
本实施例中,所述个性特征变换是对语音的音色和/或韵律特征的变换,包括对语音的频谱特征、基频特征、共振峰特征、音素时长特征、基频轨迹特征、能量轮廓特征中一项或多项的变换处理。
个性特征变换的算法有多种选择,例如可以采用源-滤波器的语音模型,使用分析-合成的方法把语音分解成声源激励和声道滤波部分,控制和改变语音模型参数,合成出个性特征变换后的语音;可以基于统计模型、人工神经网络等对韵律特征建模,然后控制语音音色和韵律相关特征参数,实现个性特征变换;可以通过重采样、时域压扩、波形相似叠加、频域加权滤波等方法实现个性特征变换。
一般来说,通过个性特征变换的语音在内容上没有改变,但在听觉上和原始语音不同,难以用来识别用户的个人身份、年龄、性别等,也无法被用来伪造用户的语音,减少了语音数据被滥用的可能性,保护了用户的隐私。
由于个性特征变换是对语音的音色和/或韵律特征的变换,语音信号中对语音识别起关键作用的语音信息得到了保留,而且识别模块所用的识别模型也是使用个性特征变换后的语音数据训练得到的,所以识别模块识别率受变换的影响相对比较小。
本实施例中,所述语音采集变换模块的个性特征变换算法和/或算法参数由用户在算法选择范围和/或算法参数的允许取值范围内选取。
用户选取个性特征变换算法和/或算法参数的方式可实现用户的个性化定制,也使不同的语音交互系统具有差异性,更有利于语音数据隐私保护。
本实施例中,所述识别模型用于进行语音内容识别和/或验证、语种识别和/或验证、方言识别和/或验证中的一项或多项。
识别模型包括多种类型,如高斯混合模型(gmm)、隐马尔科夫模型(hmm)、混合高斯-隐马尔科夫模型(gmm-hmm)、深度神经网络-隐马尔科夫模型(dnn-hmm)、深度循环神经网络-隐马尔科夫模型(rnn-hmm)、深度卷积神经网络-隐马尔科夫模型(cnn-hmm),连接时序分类-长短时记忆模型(ctc-lstm)、注意力模型(attention)、高斯混合模型-通用背景模型(gmm-ubm)、联合因子分析(jfa)、线性鉴别分析(lda)、概率线性判别分析(plda)、i-vector、支持向量机(svm)等等。
本实施例中,所述响应模块按照预设程序进行的相应的响应,包括语音应答、同声传译、执行语音指令、根据语音识别结果执行相应的策略、上传语音数据、上传语音识别结果中的一项或多项。
本实施例中,所述语音采集变换模块包括用于使用数字信号处理方法对数字语音进行个性特征变换的数字信号处理单元;所述语音采集变换模块先将采集的模拟语音信号进行模数转换处理,然后再通过所述数字信号处理单元对模数转换处理后的数字语音信号进行个性特征变换。
数字信号处理单元可采用数字信号处理器(dsp)进行个性特征变换。
本实施例中,所述语音交互系统通过深度学习方法进行所述识别模型的训练和语音识别,所述训练模块具有预训练模型,所述训练模块在所述预训练模型的基础上,使用由所述语音采集变换模块采集并进行个性特征变换后的语音信号作为训练语音数据,训练得到所述识别模型。
预训练模型是预先用数据集训练好了的识别模型,在预训练模型的基础上进行训练,可以使用较少的时间、数据和算力资源,得到效果较好的识别模型。
实施例2:
本实施例与实施例1的第一个区别在于,所述语音采集变换模块包括用于对模拟语音进行个性特征变换的模拟信号处理电路,所述语音采集变换模块先通过所述模拟信号处理电路对采集的模拟语音信号进行个性特征变换,然后再对个性特征变换后的语音信号进行模数转换处理。
本实施例与实施例1的第二个区别在于,本实施例中,如图2所示,所述语音采集变换模块包括第一语音采集变换单元和第二语音采集变换单元,其中所述第一语音采集变换单元与所述训练模块连接,所述第二语音采集变换单元与所述识别模块连接;所述第一语音采集变换单元和所述第二语音采集变换单元采用相同的变换算法。
训练模块和识别模块在物理位置上可以分离,第一语音采集变换单元和第二语音采集变换单元在物理位置上也可以分离,方便语音交互系统的灵活应用。
基于与上述两个实施例,本发明还提供了同样方法的发明构思,即上述两个实施例还提供了相同的一种保护隐私的语音交互方法,如图3所示,所述方法包括以下步骤:
步骤1)、设定语音个性特征变换算法,并将语音信号采集功能与所述语音个性特征变换算法集成,使采集输出数据为经过所述语音个性特征变换算法进行个性特征变换后的语音数据;
步骤2)、使用经过所述语音个性特征变换算法进行个性特征变换后的语音数据作为训练语音数据,通过机器学习方法训练识别模型;
步骤3)、进行语音交互时,使用训练得到的所述识别模型,通过语音识别算法对用户数据进行识别,并根据识别结果按照预设程序进行相应的响应;其中用户数据是对用户语音进行采集并使用所述语音个性特征变换算法进行个性特征变换后的语音数据。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



