
 商标分类
商标分类  商标转让
商标转让 
一种中英文混合的语音合成方法及装置与流程
 2021-01-28 13:01:34|
2021-01-28 13:01:34| 270|
270| 起点商标网
起点商标网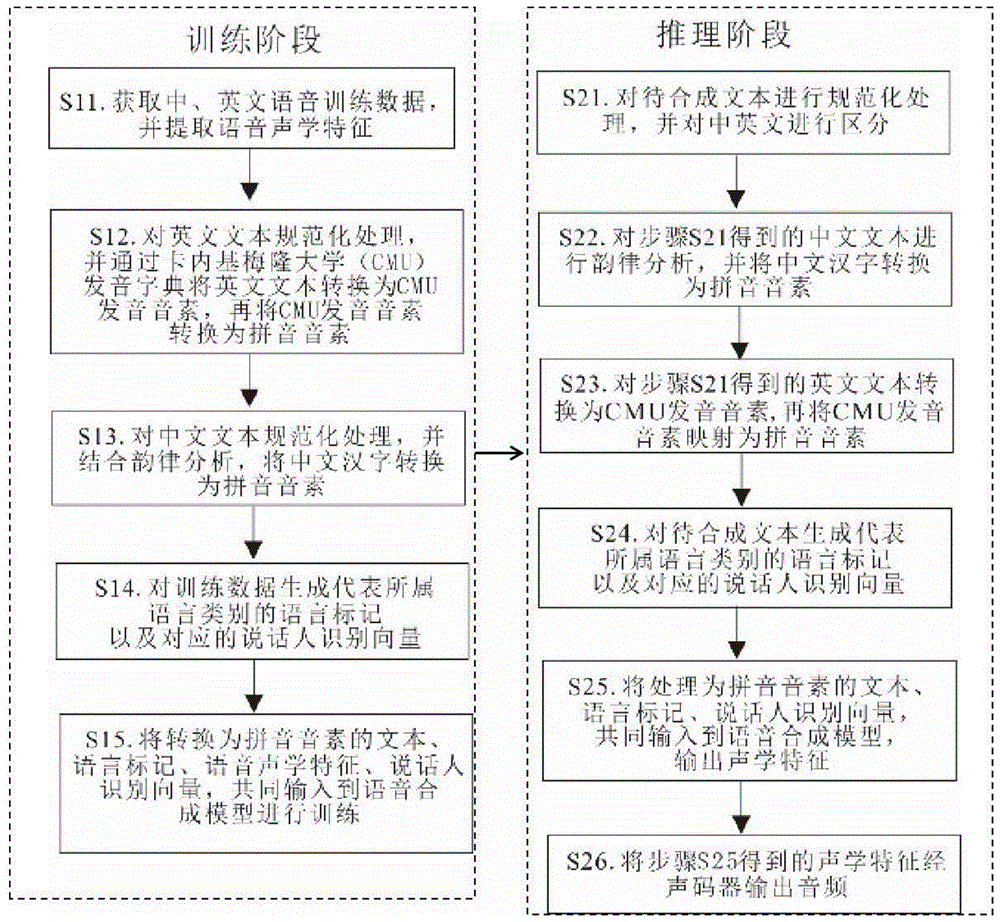
本发明涉及语音处理技术领域,具体的说是一种中英文混合的语音合成方法及装置。
背景技术:
语音合成是一种将文本信息转换为语音信息的技术,即将文字信息转换为任意的可听的语音。涉及到声学、语言学、计算机科学等多门学科。然而,不同语言的语音合成在各方面都存在差异,如前端处理的差异、发音特点的差异、表征方式的差异等等,现有的混合语言文本的合成方式是由一个主播同时说多种语言进行采集后合成,这使得混合语言文本的语音合成存在较大难度,以及过度依赖能同时说多种语言的主播。
技术实现要素:
本发明提供了一种中英文混合的语音合成方法及装置,用于解决现有技术中中英文混合文本语言合成难度大的问题。
本发明采用的技术方案是:提供一种中英文混合的语音合成方法,包括训练阶段和推理阶段,训练阶段包括以下步骤:
s11.获取多人中、英文语音训练数据,并提取语音声学特征,得到训练数据集;
s12.对英文文本规范化处理,并通过cmu发音字典将英文文本转换为cmu发音音素,再将cmu发音音素转换为拼音音素;
s13.对中文文本规范化处理,并结合韵律分析,将中文汉字转换为拼音音素;
s14.对训练数据集生成代表所属语言类别的语言标记以及对应说话人识别向量;
s15.将转换为拼音音素的文本、语言标记、语音声学特征、说话人识别向量,共同输入到语音合成模型进行训练,得到训练好的语音合成模型;
所述推理阶段包括以下步骤:
s21.对待合成文本进行规范化处理,并对中英文进行区分,得到中文文本和英文文本;
s22.对步骤s21得到的中文文本采用韵律分析,并将中文汉字转换为拼音音素;
s23.将步骤s21得到的英文文本转换为cmu发音音素,再将cmu发音音素映射为拼音音素;
s24.对待合成文本生成代表所属语言类别的语言标记以及对应说话人识别向量;
s25.将处理为拼音音素的文本、语言标记、说话人识别向量,共同输入到训练好的语音合成模型,输出声学特征;
s26.将步骤s25得到的声学特征经声码器输出音频。
优选地,在步骤s11中:
中、英文的语音训练数据包括:中文语音数据以及对应的中文文本,英文语音数据以及对应的英文文本,中英文混合的语音数据以及对应的中英文混合文本;提取的语音声学特征包括梅尔频谱特征。
优选地,在步骤s12中:
对非法字符进行剔除;将英文文本统一为ascii编码;将英文字符统一为小写字母;对英文缩写进行单词拓展;利用cmu发音字典将每个英文单词转换为cmu的发音音素,若单词不在cmu的字典,则将该句文本以及对应的语音从训练数据剔除;创建cmu发音音素与拼音音素的映射字典;通过映射字典将cmu发音音素转换为拼音音素。
优选地,在步骤s13中:
对中文文本进行规范化处理,筛选出非法字符,对合法输入进行分词、词性标注,并将提取的综合语言学特征输入到韵律预测模型,获得停顿级别标注;将中文汉字转换为拼音标记,再将拼音标记转换为对应的拼音音素。
优选地,在步骤s14中:
语言标记的长度与转换为音素后的文本步长一致;属同一类语言的语音数据其标记的值相等;特殊字符采取其他标记;说话人识别向量由经过预训练的多说话人识别模型生成,用于编码说话人信息。
优选地,在步骤s15中:
文本对应的语音声学特征包括梅尔频谱特征;经处理的拼音音素文本经过词嵌入网络层生成了文本向量,将文本向量与语言标记一起输入到编码层网络;再将编码层网络的输出与说话人识别向量一起输入到解码层网络,最后输出声学特征;模型网络结构包括但不限于目前主流的端到端tacotron模型。
优选地,在步骤s21-s25中:
推理阶段的语音合成模型参数由训练阶段得到,并且网络结构一致;推理阶段的中、英文语音文本的处理方式与训练阶段一致,不同点在于,若文本中的英文单词不存在于cmu发音字典,则将该单词看作分开的英文字母,并将英文字母转换为cmu发音字典,进而转换为拼音音素。
优选地,在步骤s26中:
采用的声码器包括wavenet、wavrnn、melgan。
本发明还提供一种中英文混合的语音合成装置,包括:
文本处理模块,用于将中英文文本规范化处理,并且转换为统一的拼音音素表达方式;
信息编码模块,用于对中、英文生成代表不同所属语言类别的语言标记以及对应说话人的说话人识别向量;
声学特征输出模块,用于输入经处理为拼音音素的文本、语言标记、说话人识别向量,输出语音的声学特征;
声码器模块,用于输入语音的声学特征,输出音频。
本发明的有益效果是:通过将英文单词转换为cmu发音音素,再将cmu发音音素转换为拼音音素,将中、英文统一为了拼音音素的表征方式,此外,为了区分中、英文的发音特点,引入了代表不同语言的语言标记,为了区分不同说话人的声学特征,引入了说话人识别向量,使得中英文混合的语音合成成为可能,并且具有很高的语音合成质量。
附图说明
图1为本发明公开的一种中英文混合的语音合成方法流程示意图;
图2为本发明公开的语音合成模型训练的流程示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步详细描述,但本发明的实施方式不限于此。
实施例1:
参见图1,一种中英文混合的语音合成方法,包括训练阶段和推理阶段,在训练阶段包括以下步骤:
s11.获取多人中、英文语音训练数据,并提取语音声学特征,得到训练数据集;
可选的,英文语音合成数据集可以使用ljspeech、vctk等公开数据集,中文语音合成数据集使用标贝公司的女生语音数据库以及自行录制的涵盖20多个人声音的语音数据库。
可理解的,中、英文的语音训练数据包括:中文语音数据以及对应的中文文本,英文语音数据以及对应的英文文本,中英文混合的语音数据以及对应的中英文混合文本;提取的语音声学特征包括但不限于梅尔频谱特征。
s12.对英文文本规范化处理,并通过卡内基梅隆大学(cmu)发音字典将英文文本转换为cmu发音音素,再将cmu发音音素转换为拼音音素;
可选的,对英文文本规范化处理,剔除非法字符;将英文文本统一为ascii编码;将英文字符统一为小写字母;对英文缩写进行单词拓展;利用cmu发音字典将每个英文单词转换为cmu的发音音素,若单词不在cmu的字典键值,则将该句文本以及对应的语音从训练数据剔除;创建cmu发音音素与拼音音素的映射字典;通过映射字典将cmu发音音素转换为拼音音素。
举例说明,英文文本为“dr.forde,%anamefamiliartothereader,whomethimatthedoor.”,首先剔除非法字符‘%’,然后将英文文本统一为ascii编码,再将英文统一为小写字母,对英文缩写‘dr.’拓展为‘docter’,经处理的英文文本为“doctorforde,anamefamiliartothereaderwhomethimatthedoor.”;再根据cmu发音字典,将英文单词转换为cmu发音音素,得到“{daa1kter0}{fao1rd}{ey1}{ney1m}{fah0mih1lyer0}{tuw1}{dhah0}{riy1der0}{sey1}{beh1st}{ah1v}{yuw1}{hhuw1}{meh1t}{hhih1m}{ae1t}{dhah0}{dao1r}”;通过cmu发音音素与拼音音素的映射字典,将cmu发音音素转换为拼音音素,得到“da1kte0fuo1rd,ai1nai1mfa0mi1lye0tu1sia0ri1de0sai1bai1sta1wyu1hu1mai1thi1ma1tsia0duo1r.”。
s13.对中文文本规范化处理,并结合韵律分析,将中文汉字转换为拼音音素;
可选的,对中文文本进行规范化处理,筛选出非法字符,对合法输入进行分词、词性标注等,并将提取的综合语言学特征输入到韵律预测模型,获得停顿级别标注;将中文汉字转换为拼音标记,再将拼音标记转换为对应的拼音音素。
s14.对训练数据集生成代表所属语言类别的语言标记以及对应说话人识别向量;
可理解的是,语言标记的长度与转换为音素后的文本步长一致;属同一类语言的语音数据其标记的值相等,反之亦然;特殊字符采取其他标记;说话人识别向量由经过预训练的多说话人识别模型生成,用于编码说话人信息。
具体的,生成语言标记以及说话人识别向量的过程如图2所示,在本例中,混合文本为“我是中国人,我爱china”,经处理及转换后,为“uo3shiii4#1zhong1guo2ren2#3uo3ai4chai1na0#4”,此处中文标记为0,英文标记为1,其它标记为2,完整的的语言标记为“000200000021111112”;说话人识别向量则由经过预训练的多说话人识别模型生成,维度为256。
s15.将转换为拼音音素的文本、语言标记、语音声学特征、说话人识别向量,共同输入到语音合成模型进行训练,得到训练好的语音合成模型。
可选的,文本对应的语音声学特征包括但不限于梅尔频谱特征;经处理的拼音音素文本经过词嵌入网络层生成了文本向量,将文本向量与语言标记一起输入到编码层网络;再将编码层网络的输出与说话人识别向量一起输入到解码层网络,最后输出声学特征;模型网络结构包括但不限于目前主流的端到端tacotron模型。
具体的,如图2所示,整体架构采用tacotron网络模型,将文本向量与语言标记进行拼接,一起输入到编码层网络,再将编码层网络的输出与说话人识别向量进行拼接,一起输入到解码层网络,最后输出声学特征。
推理阶段包括以下步骤:
s21.对待合成文本进行规范化处理,并对中英文进行区分,得到中文文本和英文文本;
s22.对步骤s21得到的中文文本采用韵律分析,并将中文汉字转换为拼音音素;
s23.将步骤s21得到的英文文本转换为cmu发音音素,再将cmu发音音素映射为拼音音素;
s24.对待合成文本生成代表所属语言类别的语言标记以及对应说话人识别向量;
s25.将处理为拼音音素的文本、语言标记、说话人识别向量,共同输入到训练好的语音合成模型,输出声学特征;
s26.将步骤s25得到的声学特征经声码器输出音频。
可理解的是,推理阶段的语音合成模型参数由训练阶段得到,并且网络结构一致;推理阶段的中、英文语音文本的处理方式与训练阶段一致,不同点在于,若文本中的英文单词不存在于cmu发音字典,则将该单词看作分开的英文字母,并将英文字母转换为cmu发音字典,进而转换为拼音音素。
举例说明,若待合成文本为“我爱china”,由于“china”存在于发音字典,则将“china”转换为cmu发音“chay1nah0”,再转换为拼音音素“chai1na0”,最后得到“uo3ai4chai1na0”;若待合成文本为“我会念abcd”,由于“abcd”不在cmu发音字典,则对“abcd”添加分隔符,变成“abcd”,此时的cmu发音为“{ey1}{biy1}{siy1}{diy1}”,转换为拼音音素得到“ai1bi1si1di1”,最后得到“uo3huei4nian4ai1bi1si1di1”。
可选的,采用的声码器包括但不限于wavnet、wavrnn、melgan。
通过本实施例1提供的一种中英文混合的语音合成方法,通过将英文单词转换为cmu发音音素,再将cmu发音音素转换为拼音音素,将中、英文统一为了拼音音素的表征方式,此外,为了区分中、英文的发音特点,引入了代表不同语言的语言标记,为了区分不同说话人的声学特征,引入了说话人识别向量,使得中英文混合文本的语音合成成为可能,并且具有较高的语音合成质量。
实施例2
一种中英文混合的语音合成装置,包括:
文本处理模块,用于将中英文文本规范化处理,并且转换为统一的拼音音素表达方式;
可选的,文本处理模块对混合文本中英文进行不同处理,对英文文本进行规范化,剔除非法字符;将英文文本统一为ascii编码;将英文字符统一为小写字母;对英文缩写进行单词拓展;利用cmu发音字典将每个英文单词转换为cmu的发音音素,若单词不在cmu的字典键值,则将该句文本以及对应的语音从训练数据剔除;创建cmu发音音素与拼音音素的映射字典;通过映射字典将cmu发音音素转换为拼音音素;对中文文本进行规范化处理,筛选出非法字符,对合法输入进行分词、词性标注等,并将提取的综合语言学特征输入到韵律预测模型,获得停顿级别标注;将中文汉字转换为拼音标记,再将拼音标记转换为对应的拼音音素。
信息编码模块,用于对中、英文生成代表不同所属语言类别的语言标记以及对应的说话人识别向量;
可理解的是,语言标记的长度与转换为音素后的文本步长一致;属同一类语言的语音数据其标记的值相等,反之亦然;特殊字符采取其他标记;说话人识别向量由经过预训练的多说话人的识别模型生成,用于编码说话人信息。
声学特征输出模块,用于输入经处理为拼音音素的文本、语言标记、说话人识别向量,输出语音的声学特征;
可选的,文本对应的语音声学特征包括但不限于梅尔频谱特征;经处理的拼音音素文本经过词嵌入网络层生成了文本向量,将文本向量与语言标记一起输入到编码层网络;再将编码层网络的输出与说话人识别向量一起输入到解码层网络,最后输出声学特征。
声码器模块,用于输入语音的声学特征,输出音频。
可选的,采用的声码器包括但不限于wavenet、wavrnn、melgan。
通过本实施例2提供的一种中英文混合的语音合成装置,利用cmu发音字典以及cmu发音与拼音音素的映射字典,将文本统一为拼音音素表达方式;同时为了区别中、英文发音特征,加入了区别语言的语言标记;为了区别说话人特征,加入了代表说话人信息的说话人识别向量。通过以上方法,将语音合成的应用场景扩展到了中英文混合文本。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



