
 商标分类
商标分类  商标转让
商标转让 
一种降噪座椅和降噪方法与流程
 2021-01-28 13:01:43|
2021-01-28 13:01:43| 251|
251| 起点商标网
起点商标网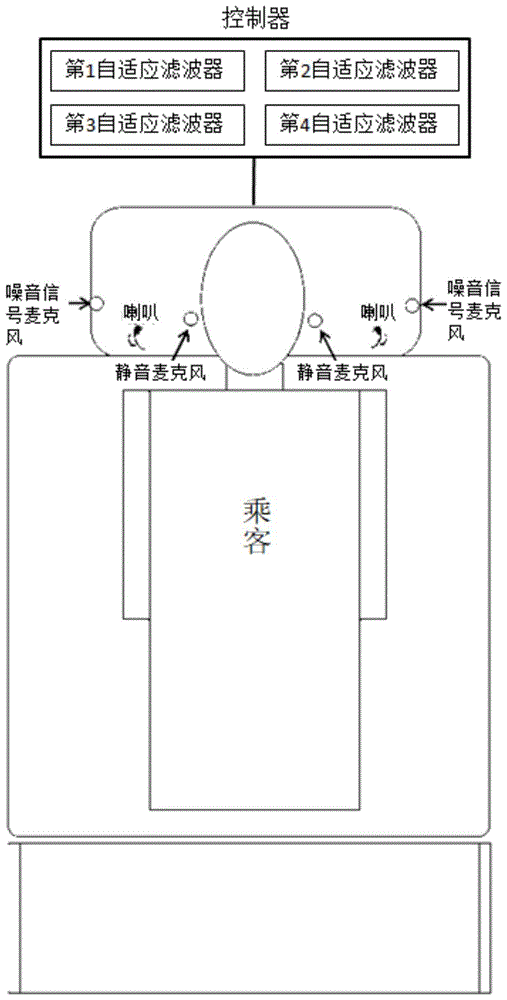
本发明涉及声学领域,尤其涉及交通工具的主动噪声控制方法。
背景技术:
随着轮轨、磁浮列车的速度的提升,车辆高速运行时产生的噪声问题也渐渐的凸显出来。相对于普通汽车车辆的噪声主要来自单一频率的发动机噪声,高速列车车辆的噪声来源更为复杂,包括车辆内噪杂的人声、车辆行进中轮轨摩擦产生的噪音和高速列车行驶风压变化产生的噪声,声音成分在低频段分布范围更广,较难消除。
目前,对于列车噪音主要通过增强列车密闭性,功率性原件结构设计避免噪音等方法来降噪,然而列车由于声音可以通过不同介质传播,列车密闭性对高频段噪声有较好效果,对低频段噪音效果不明显。而功能结构性设计,受限制于元器件本身改动较大。目前飞机和列车上的普遍做法是为每位乘客配发耳塞,随着车辆乘坐班次的增多,产生很大浪费和污染环境。并且随着列车时速的增加,噪音问题将变的更加突出,因此为乘客提供更加舒适的乘车环境具有很大的现实意义和经济意义。
主动噪音控制技术利用声波叠加原理,参见图1,针对信号源(主波),产生一个于其幅值相同,相位相反的噪声信号(次波),两声波相互叠加,达到消声的目的。目前市面上有类似的主动降噪耳机,但主动降噪耳机无法在列车等大型公共交通工具上集中化供应,并且长久佩戴或不习惯佩戴耳机的乘客会产生不适感。因此需要将主动噪声控制系统安装在车座椅上,在靠近乘客耳朵附近,安装扬声器和接受麦克风,使座椅具有主动噪声消除功能。
目前,已有部分工业领域采用了类似的主动噪声控制技术,所采用的算法包括最小均方算法和滤波最小均方算法(fx-lms算法)。
采用最小均方算法的主动噪声控制系统基于最小均方算法构建自适应滤波器来控制减小噪声,最小均方算法能够跟踪改变的输入信号,并根据输入的参数自动调整自适应滤波器的设置参数,并可以持续建模来模拟声音通道,采用最小均方算法的主动噪声控制系统结构参见图2,噪声信号源x(n)穿过未知的通道p(z)形成主源噪声d(n),数字自适应滤波器w(z)的输出y(n)根据输入信号x(n)和误差传感器扑捉到的误差信号e(n)来调整,输入信号x(n)和误差信号e(n)作为反馈信号来调整数字自适应滤波器参数w(z)。主动噪声控制系统通过不断调整数字自适应滤波器参数w(z)使误差信号e(n)达到最小均方值。
输入信号x(n)由一组向量x(n)=[x(n),x(n-1),…,x(n-n+1)]t表示,输出信号y(n)由公式
fx-lms算法是一种在最小均方算法基础上加入补偿的算法,参见图3,误差信号e(n)由公式e(n)=d(n)-s(n)*[wt(n)x(n)]计算得到,自适应滤波器系数w(n)由w(n+1)=w(n)+μe(n)x′(n)得到,其中x′(n)=x(n)*s(n),此处的s(n)为声音通道传递函数,在加入计算前需提前测量好。目前的单通道主动噪声控制技术可以消除频带较宽的噪声,但消除噪声的安静区域非常小,并不能为用户提供足够的舒适性。
技术实现要素:
本发明所要解决的技术问题是,针对现有技术的不足,提供了一种主动噪声控制技术,可用于磁悬浮等交通工具,采用多通道主动噪声控制技术,对麦克风和喇叭布置位置进行了优化,改进了噪音控制算法,解决了降噪区域过小的问题。
为了解决以上问题,根据本发明的第一个方面,提供了一种降噪座椅,包括头枕、靠背、座部和噪声控制系统,所述噪声控制系统包括:
2个噪音信号麦克风,包括第1噪音信号麦克风和第2噪音信号麦克风,分别设置于头枕左右两侧边缘位置,用于采集环境噪音信号;
2m个静音麦克风,其中m≥1,包括第1静音麦克风、第2静音麦克风、……、第2m静音麦克风,对称设置于头枕的乘客左右耳旁区域位置,用于采集耳旁噪音信号;
2个喇叭,包括第1喇叭和第2喇叭,分别设置于所述噪音信号麦克风和所述静音麦克风之间,用于播放反噪音信号;
所述噪声控制系统还具有控制器,所述第1噪音信号麦克风,所述第2噪音信号麦克风、所述第1静音麦克风、所述第2静音麦克风、……、第2m静音麦克风、所述第1喇叭和所述第2喇叭与所述控制器连接,所述控制器包括第1自适应滤波器、第2自适应滤波器、……、第4m自适应滤波器共4m个自适应滤波器,用于对噪音信号麦克风至静音麦克风间的声音传播路径进行滤波消音。
优选的,所述噪声控制系统采用fx-lms算法进行主动降噪控制,包括如下步骤:
步骤1:所述第1噪音信号麦克风采集噪音信号并经过合成处理后生成噪音源信号x1(n)作为所述第1至第2m自适应滤波器的输入信号,所述第2噪音信号麦克风采集噪音信号并经过合成处理后生成噪音源信号x2(n)作为所述第2m+1至第4m自适应滤波器的输入信号;
步骤2:所述4m个自适应滤波器根据所述输入信号分别输出反噪音信号y1(n)、y2(n)、……、y4m(n);
步骤3:所述第1喇叭和所述第2喇叭同时播放所述反噪音信号y1(n)、y2(n)、……、y4m(n);
步骤4:所述第1静音麦克风采集耳旁噪音信号e1(n),所述第2静音麦克风采集耳旁噪音信号e2(n),……,所述第2m静音麦克风采集耳旁噪音信号e2m(n),所述耳旁噪音信号e1(n)为所述反噪音信号y1(n)和y2m+1(n)与噪音源信号x1(n)和x2(n)的误差,所述耳旁噪音信号e2(n)为所述反噪音信号y2(n)和y2m+2(n)与噪音源信号x1(n)和x2(n)的误差,……,所述耳旁噪音信号e2m(n)为所述反噪音信号y2m(n)和y4m(n)与噪音源信号x1(n)和x2(n)的误差;
步骤5:所述第1至第2m自适应滤波器根据所述耳旁噪音信号e1(n)、e2(n)、……、e2m(n)以及噪音源信号x1(n)分别调整输出的反噪音信号y1(n)、y2(n)、……、y2m(n),所述第2m+1至第4m自适应滤波器根据所述耳旁噪音信号e1(n)、e2(n)、……、e2m(n)和噪音源信号x2(n)分别调整输出的反噪音信号y2m+l(n)、y2m+2(n)、……、y4m(n);
步骤6:重复步骤3至步骤5。
优选的,所述步骤4进一步包括:
步骤41:所述噪音源信号x1(n)经过空气路径p1(z)、p2(z)、……、p2m(z)分别产生主源噪音d11(n)、d12(n)、……、d1(2m)(n),所述噪音源信号x2(n)经过空气路径p2m+1(z)、p2m+2(z)、……、p4m(z)分别产生主源噪音d21(n)、d22(n)、……、d2(2m)(n);
步骤42:所述反噪音信号y1(n)经过声音通道传递函数s11(z)和s21(z)分别产生修正反噪音信号y11(n)和y12(n),所述反噪音信号y2(n)经过声音通道传递函数s12(z)和s22(z)分别产生修正反噪音信号y21(n)和y22(n),……,所述反噪音信号y2m(n)经过声音通道传递函数s12m(z)和s22m(z)分别产生修正反噪音信号y(2m)1(n)和y(2m)2(n),所述反噪音信号y2m+1(n)经过声音通道传递函数s11(z)和s21(z)分别产生修正反噪音信号y(2m+1)1(n)和y(2m+1)2(n),……,所述反噪音信号y4m(n)经过声音通道传递函数s12m(z)和s22m(z)分别产生修正反噪音信号y(4m)1(n)和y(4m)2(n);
步骤43:所述第1静音麦克风采集所述修正反噪音信号y11(n)、y12(n)、y(2m+1)1(n)和y(2m+1)2(n)与所述主源噪音d11(n)、d21(n)之差,即耳旁噪音信号e1(n),所述第2静音麦克风采集所述修正反噪音信号y21(n)、y22(n)、y(2m+2)1(n)和y(2m+2)2(n)与所述主源噪音d12(n)、d22(n)之差,即耳旁噪音信号e2(n),……,所述第2m静音麦克风采集所述修正反噪音信号y(2m)1(n)、y(2m)2(n)、y(4m)1(n)和y(4m)2(n)与所述主源噪音d1(2m)(n)、d2(2m)(n)之差,即耳旁噪音信号e2m(n)。
根据本发明的第二个方面,提供了一种降噪方法,用于上述的降噪座椅,所述方法采用fx-lms算法,包括如下步骤:
步骤1:所述第1噪音信号麦克风采集噪音信号并经过合成处理后生成的噪音源信号x1(n)输入所述第1至第2m自适应滤波器第1自适应滤波器第2自适应滤波器,所述第2噪音信号麦克风采集噪音信号并经过合成处理后生成的噪音源信号x2(n)输入所述第2m+1至第4m自适应滤波器,其中m≥1;
步骤2:所述第1至第4m自适应滤波器根据所述输入信号分别输出反噪音信号y1(n)、y2(n)、……、y4m(n);
步骤3:所述第1喇叭和所述第2喇叭同时播放所述反噪音信号y1(n)、y2(n)、……、y4m(n);
步骤4:所述第1静音麦克风采集耳旁噪音信号e1(n),所述第2静音麦克风采集耳旁噪音信号e2(n),……,所述第2m静音麦克风采集耳旁噪音信号e2m(n),所述耳旁噪音信号e1(n)为所述反噪音信号y1(n)和y2m+1(n)与噪音源信号x1(n)和x2(n)的误差,所述耳旁噪音信号e2(n)为所述反噪音信号y2(n)和y2m+2(n)与噪音源信号x1(n)和x2(n)的误差,……,所述耳旁噪音信号e2m(n)为所述反噪音信号y2m(n)和y4m(n)与噪音源信号x1(n)和x2(n)的误差;
步骤5:所述第1至第2m自适应滤波器根据所述耳旁噪音信号e1(n)、e2(n)、……、e2m(n)以及噪音源信号x1(n)分别调整输出的反噪音信号y1(n)、y2(n)、……、y2m(n),所述第2m+1至第4m自适应滤波器根据所述耳旁噪音信号e1(n)、e2(n)、……、e2m(n)和噪音源信号x2(n)分别调整输出的反噪音信号y2m+l(n)、y2m+2(n)、……、y4m(n);
步骤6:重复步骤3至步骤5。
优选的,所述步骤4进一步包括:
步骤41:所述噪音源信号x1(n)经过空气路径p1(z)、p2(z)、……、p2m(z)分别产生主源噪音d11(n)、d12(n)、……、d1(2m)(n),所述噪音源信号x2(n)经过空气路径p2m+1(z)、p2m+2(z)、……、p4m(z)分别产生主源噪音d21(n)、d22(n)、……、d2(2m)(n);
步骤42:所述反噪音信号y1(n)经过声音通道传递函数s11(z)和s21(z)分别产生修正反噪音信号y11(n)和y12(n),所述反噪音信号y2(n)经过声音通道传递函数s12(z)和s22(z)分别产生修正反噪音信号y21(n)和y22(n),……,所述反噪音信号y2m(n)经过声音通道传递函数s12m(z)和s22m(z)分别产生修正反噪音信号y(2m)1(n)和y(2m)2(n),所述反噪音信号y2m+1(n)经过声音通道传递函数s11(z)和s21(z)分别产生修正反噪音信号y(2m+1)1(n)和y(2m+1)2(n),……,所述反噪音信号y4m(n)经过声音通道传递函数s12m(z)和s22m(z)分别产生修正反噪音信号y(4m)1(n)和y(4m)2(n);
步骤43:所述第1静音麦克风采集所述修正反噪音信号y11(n)、y12(n)、y(2m+1)1(n)和y(2m+1)2(n)与所述主源噪音d11(n)、d21(n)之差,即耳旁噪音信号e1(n),所述第2静音麦克风采集所述修正反噪音信号y21(n)、y22(n)、y(2m+2)1(n)和y(2m+2)2(n)与所述主源噪音d12(n)、d22(n)之差,即耳旁噪音信号e2(n),……,所述第2m静音麦克风采集所述修正反噪音信号y(2m)1(n)、y(2m)2(n)、y(4m)1(n)和y(4m)2(n)与所述主源噪音d1(2m)(n)、d2(2m)(n)之差,即耳旁噪音信号e2m(n)。
与现有技术相比,本发明采用的算法参数更精确,使计算出的反噪音信号更精确,提高了降噪的效果,也为系统优化带来更多的可能,并且具有造价低、占地小和去除低频噪声的优点,为高速列车或飞机提供了车辆噪声解决方案,提高了旅客乘坐列车的舒适性。本发明采用了多通道主动噪声控制技术,优化了麦克风和喇叭布置位置,加入了前馈噪音消除系统并预处理输入的噪音信号,对声音传递路径的参数信息进行了精确测量,调整自适应滤波器找到了适当的算法迭代步长值,提升了反噪音信号精确度,提高了降噪的效果。
附图说明
本发明的以上发明内容以及下面的具体实施方式在结合附图阅读时会得到更好的理解。需要说明的是,附图仅作为所请求保护的发明的示例。在附图中,相同的附图标记代表相同或类似的元素。
图1是主动噪声控制原理示意图;
图2是采用最小均方算法的噪声控制系统结构示意图;
图3是采用fxlms算法的噪声控制系统结构示意图;
图4是根据本发明一实施例的一种降噪座椅示意图;
图5是根据本发明一实施例的一种噪声控制系统结构示意图。
图6是根据本发明一实施例的主动降噪控制流程;以及
图7是根据本发明一实施例的耳旁噪音信号采集流程。
具体实施方式
以下在具体实施方式中详细叙述本发明的详细特征以及优点,其内容足以使任何本领域技术人员了解本发明的技术内容并据以实施,且根据本说明书所揭露的说明书、权利要求及附图,本领域技术人员可轻易地理解本发明相关的目的及优点。
作为本发明的第一个方面,提供了一种降噪座椅,可用于中高速交通工具中。如图4所示,根据本发明的降噪座椅包括头枕、靠背、座部和噪声控制系统,噪声控制系统包括多个单独通道的主动噪声控制系统。噪声控制系统包括:
第1噪音信号麦克风和第2噪音信号麦克风,分别设置于头枕左右两侧边缘位置,用于采集环境噪音信号;
第1静音麦克风和第2静音麦克风,分别设置于头枕的乘客左右耳旁区域位置,用于采集耳旁噪音信号;
第1喇叭和第2喇叭,分别设置于噪音信号麦克风和静音麦克风之间,用于播放反噪音信号;
噪声控制系统还具有控制器,第1噪音信号麦克风,第2噪音信号麦克风、第1静音麦克风、第2静音麦克风、第1喇叭和第2喇叭与控制器连接,控制器包括第1自适应滤波器w1(z)、第2自适应滤波器w2(z)、第3自适应滤波器w3(z)、第4自适应滤波器w4(z),其中,该第1自适应滤波器至第4自适应滤波器能够分别对两个噪声源(第1和第2噪音信号麦克风)至两个静音麦克风间的四条声音传播路径进行滤波消音。
需要注意的是,本发明并不局限于设置两个静音麦克风,为了扩大降噪区域、提高降噪效果,还可设置四个静音麦克风,相应地,噪声控制系统中的自适应滤波器数量增至八个,需要进行滤波消音的声音传播路径也增至八条,若需进一步的增强降噪效果,可将静音麦克风扩充至2m个,对应的自适应滤波器数量和需要进行滤波消音的声音传播路径扩充至4m个。
进一步的,根据本发明另一方面,噪声控制系统执行一种降噪方法,采用fx-lms算法进行主动降噪控制,参见图5和图6,在本发明的噪音控制系统仅包括两个静音麦克风的情况下,包括如下步骤:
步骤1:第1噪音信号麦克风采集噪音信号并经过合成处理后生成噪音源信号x1(n)作为第1自适应滤波器和第2自适应滤波器的输入信号,第2噪音信号麦克风采集噪音信号并经过合成处理后生成噪音源信号x2(n)作为第3自适应滤波器和第4自适应滤波器的输入信号;
步骤2:第1自适应滤波器和第3自适应滤波器分别根据输入信号分别输出反噪音信号y1(n)和y3(n),第2自适应滤波器和第4自适应滤波器分别根据输入信号分别输出反噪音信号y2(n)和y4(n);
步骤3:第1喇叭和第2喇叭同时播放反噪音信号y1(n)、y2(n)、y3(n)和y4(n);
步骤4:第1静音麦克风采集耳旁噪音信号e1(n),第2静音麦克风采集耳旁噪音信号e2(n),耳旁噪音信号e1(n)为反噪音信号y1(n)和y3(n)与噪音源信号x1(n)和x2(n)的误差,耳旁噪音信号e2(n)为反噪音信号y2(n)和y4(n)与噪音源信号x1(n)和x2(n)的误差;
步骤5:第1自适应滤波器和第2自适应滤波器根据耳旁噪音信号e1(n)和e2(n)以及噪音源信号x1(n)分别调整输出的反噪音信号y1(n)和y2(n),第3自适应滤波器和第4自适应滤波器根据耳旁噪音信号e1(n)和e2(n)以及噪音源信号x2(n)分别调整输出的反噪音信号y3(n)和y4(n);
步骤6:重复步骤3至步骤5。
进一步的,参照图7,上述步骤4进一步包括:
步骤41:噪音源信号x1(n)经过空气路径p1(z)、p2(z)分别产生主源噪音d11(n)、d12(n),噪音源信号x2(n)经过空气路径p3(z)、p4(z)分别产生主源噪音d21(n)、d22(n),p1(z)、p2(z)、p3(z)、p4(z)是从第1和第2噪音收集麦克风到耳旁的第1和第2静音麦克风的4个空气路径通道;
步骤42:反噪音信号y1(n)经过声音通道传递函数s11(z)和s21(z)分别产生修正反噪音信号y11(n)和y12(n),反噪音信号y2(n)经过声音通道传递函数s12(z)和s22(z)分别产生修正反噪音信号y21(n)和y22(n),反噪音信号y3(n)经过声音通道传递函数s11(z)和s21(z)分别产生修正反噪音信号y31(n)和y32(n),反噪音信号y4(n)经过声音通道传递函数s12(z)和s22(z)分别产生修正反噪音信号y41(n)和y42(n),其中声音通道传递函数是空气路径的模拟路径;
步骤43:第1静音麦克风采集所述修正反噪音信号y11(n)、y12(n)、y31(n)和y32(n)与所述主源噪音d11(n)、d21(n)之差,即耳旁噪音信号e1(n),第2静音麦克风采集所述修正反噪音信号y21(n)、y22(n)、y41(n)和y42(n)与所述主源噪音d12(n)、d22(n)之差,即耳旁噪音信号e2(n)。
同样的,若噪声控制系统中的静音麦克风数量扩充至2m个,其中m≥1,则降噪方法包括如下步骤:
步骤1:第1噪音信号麦克风采集噪音信号并经过合成处理后生成噪音源信号x1(n)作为第1至第2m自适应滤波器的输入信号,第2噪音信号麦克风采集噪音信号并经过合成处理后生成噪音源信号x2(n)作为第2m+1至第4m自适应滤波器的输入信号;
步骤2:4m个自适应滤波器根据输入信号分别输出反噪音信号y1(n)、y2(n)、……、y4m(n);
步骤3:第1喇叭和第2喇叭同时播放反噪音信号y1(n)、y2(n)、……、y4m(n);
步骤4:第1静音麦克风采集耳旁噪音信号e1(n),第2静音麦克风采集耳旁噪音信号e2(n),……,第2m静音麦克风采集耳旁噪音信号e2m(n),耳旁噪音信号e1(n)为反噪音信号y1(n)和y2m+1(n)与噪音源信号x1(n)和x2(n)的误差,耳旁噪音信号e2(n)为反噪音信号y2(n)和y2m+2(n)与噪音源信号x1(n)和x2(n)的误差,……,耳旁噪音信号e2m(n)为反噪音信号y2m(n)和y4m(n)与噪音源信号x1(n)和x2(n)的误差;
步骤5:第1至第2m自适应滤波器根据耳旁噪音信号e1(n)、e2(n)、……、e2m(n)以及噪音源信号x1(n)分别调整输出的反噪音信号y1(n)、y2(n)、……、y2m(n),第2m+1至第4m自适应滤波器根据耳旁噪音信号e1(n)、e2(n)、……、e2m(n)和噪音源信号x2(n)分别调整输出的反噪音信号y2m+l(n)、y2m+2(n)、……、y4m(n);
步骤6:重复步骤3至步骤5。
上述步骤4进一步包括:
步骤41:噪音源信号x1(n)经过空气路径p1(z)、p2(z)、……、p2m(z)分别产生主源噪音d11(n)、d12(n)、……、d1(2m)(n),噪音源信号x2(n)经过空气路径p2m+1(z)、p2m+2(z)、……、p4m(z)分别产生主源噪音d21(n)、d22(n)、……、d2(2m)(n),p1(z)、p2(z)、……、p4m(z)是从第1和第2噪音收集麦克风到耳旁的2m个静音麦克风的4m个空气路径通道;
步骤42:反噪音信号y1(n)经过声音通道传递函数s11(z)和s21(z)分别产生修正反噪音信号y11(n)和y12(n),反噪音信号y2(n)经过声音通道传递函数s12(z)和s22(z)分别产生修正反噪音信号y21(n)和y22(n),……,反噪音信号y2m(n)经过声音通道传递函数s12m(z)和s22m(z)分别产生修正反噪音信号y(2m)1(n)和y(2m)2(n),反噪音信号y2m+1(n)经过声音通道传递函数s11(z)和s21(z)分别产生修正反噪音信号y(2m+1)1(n)和y(2m+1)2(n),……,反噪音信号y4m(n)经过声音通道传递函数s12m(z)和s22m(z)分别产生修正反噪音信号y(4m)1(n)和y(4m)2(n);
步骤43:第1静音麦克风采集修正反噪音信号y11(n)、y12(n)、y(2m+1)1(n)和y(2m+1)2(n)与主源噪音d11(n)、d21(n)之差,即耳旁噪音信号e1(n),第2静音麦克风采集修正反噪音信号y21(n)、y22(n)、y(2m+2)1(n)和y(2m+2)2(n)与主源噪音d12(n)、d22(n)之差,即耳旁噪音信号e2(n),……,第2m静音麦克风采集修正反噪音信号y(2m)1(n)、y(2m)2(n)、y(4m)1(n)和y(4m)2(n)与主源噪音d1(2m)(n)、d2(2m)(n)之差,即耳旁噪音信号e2m(n)。
这里采用的术语和表述方式只是用于描述,本发明并不应局限于这些术语和表述。使用这些术语和表述并不意味着排除任何示意和描述(或其中部分)的等效特征,应认识到可能存在的各种修改也应包含在权利要求范围内。其他修改、变化和替换,例如不同规格的元器件的替换,也可能存在。相应的,权利要求应视为覆盖所有这些等效物。
同样,需要指出的是,虽然本发明已参照当前的具体实施例来描述,但是本技术领域中的普通技术人员应当认识到,以上的实施例仅是用来说明本发明,在没有脱离本发明精神的情况下还可做出各种等效的变化或替换,因此,只要在本发明的实质精神范围内对上述实施例的变化、变型都将落在本申请的权利要求书的范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



