
 商标分类
商标分类  商标转让
商标转让 
一种语音消息的智能处理方法与流程
 2021-01-28 13:01:08|
2021-01-28 13:01:08| 252|
252| 起点商标网
起点商标网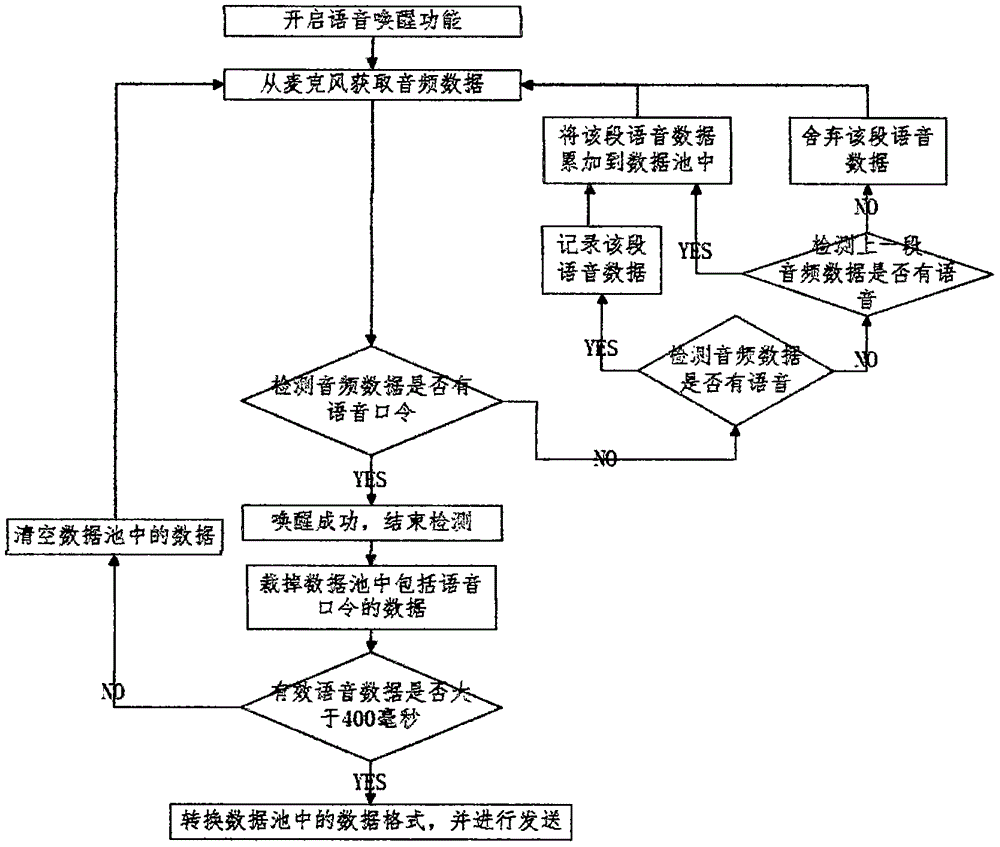
本发明属于通信技术领域,涉及一种消息处理方法,具体涉及一种语音消息的智能处理方法。
背景技术:
目前,用户通过社交软件发送语音消息时,录制过程中需要用手指一直接着录制按钮,并且会把停顿时的语音数据录制进去。
用现有的方式录制和发送语音消息时,由于需要一直用手指按着按钮,极易误操作,例如,还没有录制结束,由于不小心松手,把消息发送出去。取消发送的步骤也很繁琐,需要用手指在屏幕上滑动。同时,发送的语音消息中,包括一些停顿的空白数据,这就导致听消息的人多听到一些无效的消息,浪费听消息的人的时间。
鉴于现有技术的上述技术缺陷,迫切需要研发一种新型的语音消息处理方法。
技术实现要素:
本发明的目的在于克服现有技术中存在的缺点,利用人工智能技术,主要是语音识别及唤醒技术,提供一种新型的语音消息处理方法,其不仅解放双手,减少了误操作的可能性,还减少了听语音消息的时间。
为了实现上述目的,本发明提供如下技术方案:
一种语音消息的智能处理方法,其特征在于,包括以下步骤:
(1)、开启语音唤醒功能;
(2)、从麦克风获取音频数据;
(3)、检测从麦克风获取的音频数据是否有语音口令,如果没有语音口令,则进入步骤(4),如果有语音口令,则唤醒成功,结束检测,进入步骤(5);
(4)、检测从麦克风获取的音频数据是否有声音,如果有声音则记录该段音频数据并将该段音频数据累加到数据池中;如果没有声音则检测上一段音频数据是否有声音,如果上一段音频数据有声音则把该段音频数据也累加到数据池中,如果上一段音频数据没有声音则舍弃该段音频数据;将该段音频数据累加到数据池中或舍弃该段音频数据后返回步骤(2)继续从麦克风获取音频数据;
(5)、裁掉数据池中包括语音口令的数据;
(6)、判断裁掉语音口令的数据之后的有效语音数据是否大于一定时间,如果大于等于一定时间,则进入步骤(7),如果小于一定时间,则清空数据池中的音频数据并返回步骤(2)继续从麦克风获取音频数据;
(7)、转换数据池中的音频数据的数据格式,并进行发送。
优选地,其中,所述步骤(1)中,利用百度语音唤醒软件工具开启语音唤醒功能。
优选地,其中,所述步骤(2)中,每次从麦克风中获取的是20毫秒的音频数据。
优选地,其中,所述步骤(4)中,利用webrtc里的vad算法检测从麦克风获取的音频数据是否有声音。
优选地,其中,所述步骤(6)中的一定时间为400毫秒。
优选地,其中,所述步骤(7)中,将数据池中的音频数据转成amr格式。
优选地,其中,所述步骤(7)中,通过环信即时通讯软件开发工具进行自动发送。
优选地,其中,在步骤(1)之前,检查是否有读写本地文件的权限和调用麦克风的权限,如果没有,则引导用户进行授权。
与现有技术相比,本发明的语音消息处理方法具有如下有益技术效果:本发明的语音消息处理方法无需手动控制便可录制语音消息,且通过判断录制的语音数据是否有声音来选择是否记录该段数据,录制完成后可通过口令来发送语音消息。在这个过程中无需用手操作,对用户来说不仅解放双手,而且减少了误操作的可能性。同时,其还剔除了空白数据,使得语音消息里全是有效信息,减少了听语音消息的时间,节省了听者的时间。
附图说明
图1是本发明的语音消息智能处理方法的流程图。
具体实施方式
下面结合附图和实施例对本发明进一步说明,实施例的内容不作为对本发明的保护范围的限制。
本发明涉及一种在社交软件中新的录制、发送语音消息的方式,其中包括无需手动控制便可录制语音消息,且通过判断录制的语音数据是否有声音来选择是否记录该段数据,录制完成后可通过语音口令(如:“ok发送”)来发送语音消息。在这个过程中无需用手操作,对用户来说不仅解放双手,减少了误操作的可能性,还使得语音消息里全是有效信息,减少了听语音消息的时间。
图1示出了本发明的语音消息处理方法的流程图。如图1所示,本发明的语音消息智能处理方法包括以下步骤:
首先,开启语音唤醒功能。
也就是,在进行语音消息发送之前,用户需要先开启语音唤醒功能,以便于进行语音数据的获取和处理。
在本发明中,可以利用百度语音唤醒软件工具开启语音唤醒功能。
其中,百度语音唤醒软件开发工具是一个能够识别出预先设置好的语音口令的开发工具。通过百度语音唤醒软件开发工具可以设置唤醒语音口令,例如,“ok发送”等。
在本发明中,在开启语音唤醒功能之前,需要检查是否有读写本地文件的权限和调用麦克风的权限,如果没有,则引导用户进行授权。在用户进行授权之后,才能开启语音唤醒功能
在开启语音唤醒功能之后,即可从麦克风获取音频数据。也就是,打开麦克风,用麦克风进行录音,从而通过麦克风获取音频数据。
接着,检测从麦克风获取的音频数据是否有语音口令。所述语音口令为是否发送语音数据的口令,例如,“ok发送”等。通过是否有语音口令,来判断是否需要发送从麦克风获取的音频数据。
如果没有语音口令,则说明不需要进行语音数据的发送。此时,需要检测从麦克风获取的音频数据是否有声音。如果从麦克风获取的音频数据有声音则记录该段音频数据并将该段音频数据累加到数据池中。如果从麦克风获取的音频数据没有声音则检测上一段音频数据是否有声音。如果上一段音频数据有声音则把该段音频数据也累加到数据池中。如果上一段音频数据没有声音则舍弃该段音频数据。
将该段音频数据累加到数据池中或舍弃该段音频数据后要继续处理从麦克风获取的音频数据。
在本发明中,可以利用vad静音检测算法检测从麦克风获取的音频数据是否有声音。vad静音检测算法是webrtc里的vad算法,其可以检测20毫秒的音频数据有没有声音。
这样,在本发明中,当开启唤醒功能后,在有麦克风的权限的前提下,自动打开麦克风,触发录音功能,在录音过程中,每次返回20毫秒的数据,然后利用vad算法检测这20毫秒的音频数据有没有声音。如果有声音就把该段音频数据累加到要发送的数据池中。如果没有声音,则判断上一次检测有没有声音,如果上一次检测有声音(顺序是:有声音——没声音),说明这是一句话结束后的停顿,为防止每句话之间的间隔过于紧凑,则把这一段音频数据也累加到要发送的数据池中;如果上一次检测没有声音(顺序是:没声音——没声音),说明正处于一段长时间的停顿,此时直接舍弃该段音频数据。
如果有语音口令,则唤醒成功,结束检测。此时,需要将从数据池中的语音数据进行发送。但是,在发送前需要裁掉数据池中包括语音口令的数据。由于裁掉了数据池中包括语音口令的数据,因此,不需要将语音口令发送给对方,一方面比较节省时间,另一方面有助于保证语音数据都是有效语音数据。
在裁掉数据池中包括语音口令的数据之后,需要判断裁掉语音口令的数据之后的有效语音数据是否大于一定时间,例如400毫秒。
如果小于一定时间,或者只包含语音口令,则提示录制时间过短,清空数据池中的数据,重新录制,继续从麦克风获取音频数据。
如果大于等于一定时间,则说明是一段有效的语音消息,需要对其进行发送。因此,此时,要转换数据池中的音频数据的数据格式,并进行发送。
在本发明中,由于数据池中的数据为pcm格式,而发送的时候为amr格式,因此,需要转成amr格式进行发送。
同时,在本发明中,通过环信即时通讯软件开发工具进行自动发送。
其中,环信即时通讯软件开发工具是一个能够提供即时发送和接收互联网消息的开发工具,在此基础上开发者可以更方便快捷得实现聊天功能。本发明就是利用该工具使用户能够即时通讯。
本发明的语音消息处理方法无需手动控制便可录制语音消息,且通过判断录制的语音数据是否有声音来选择是否记录该段数据,录制完成后可通过口令来发送语音消息。在这个过程中无需用手操作,对用户来说不仅解放双手,而且减少了误操作的可能性。同时,其还剔除了空白数据,使得语音消息里全是有效信息,减少了听语音消息的时间,节省了听者的时间。
本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无法对所有的实施方式予以穷举。凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



