
 商标分类
商标分类  商标转让
商标转让 
声纹识别方法、装置和系统、计算机可读存储介质与流程
 2021-01-28 13:01:55|
2021-01-28 13:01:55| 277|
277| 起点商标网
起点商标网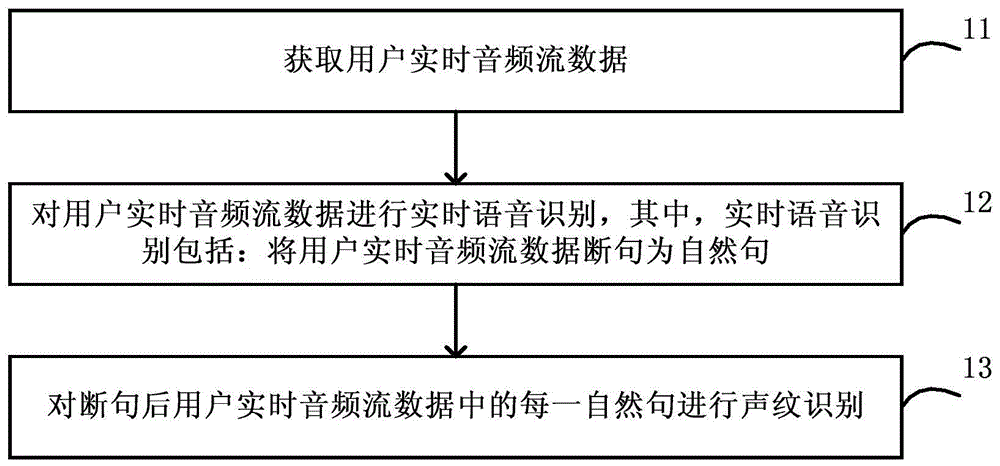
本公开涉及人工智能领域,特别涉及一种声纹识别方法、装置和系统、计算机可读存储介质。
背景技术:
声纹识别,也称为说话人识别,有两类,即说话人辨认和说话人确认。前者用以判断某段语音是若干人中的哪一个所说的,是“多选一”问题;而后者用以确认某段语音是否是指定的某个人所说的,是“一对一判别”问题。
技术实现要素:
发明人通过研究发现:在实时语音识别和声纹识别融合应用的实际场景中,会遇到如下技术挑战:
1、在直播会议、审讯、电话通话等场景下由多个说话人在交替说话,在实时识别人身份时,在超短语句的快速切换下,声纹识别常会对短语句(3秒以下)进行误判。
2、由于短语句常会含静音、叠音,在3秒中人声有用信息并不充分。且切换频繁,所以识别率远低于常语句的识别,无法达到商业要求。
3、短语句误判后,还会使得本属于一句话被角色拆分成多句,话不成人话。
鉴于以上技术问题中的至少一项,本公开提供了一种声纹识别方法、装置和系统、计算机可读存储介质,可以基于语音识别实时矫正声纹识别结果。
根据本公开的一个方面,提供一种声纹识别方法,包括:
获取用户实时音频流数据;
对用户实时音频流数据进行实时语音识别,其中,所述对用户实时音频流数据进行实时语音识别包括:将用户实时音频流数据断句为自然句;
对断句后用户实时音频流数据中的每一自然句进行声纹识别。
在本公开的一些实施例中,所述对用户实时音频流数据进行实时语音识别还包括:
确定断句的每一自然句的起始和终止时间戳。
在本公开的一些实施例中,所述对断句后用户实时音频流数据中的每一自然句进行声纹识别包括:
对断句后的用户实时音频流数据中的每一自然句,根据起始和终止时间戳进行对齐后,进行声纹识别。
在本公开的一些实施例中,所述声纹识别方法还包括:
组合声纹识别结果和语音识别结果;
利用自然语言处理方式,对组合后的声纹识别结果和语音识别结果进行优化。
在本公开的一些实施例中,所述声纹识别方法还包括:
显示优化后的声纹识别结果和语音识别结果。
在本公开的一些实施例中,所述声纹识别方法还包括:
存储优化后的声纹识别结果和语音识别结果。
在本公开的一些实施例中,所述声纹识别方法还包括:预先注册声纹识别中验证人的声音数据;在声音数据注册后、进行声纹识别的情况下,待识别的实时音频流数据与声音数据注册时验证人所说的自然语言、语义没有关联。
在本公开的一些实施例中,所述对断句后用户实时音频流数据中的每一自然句进行声纹识别包括:
判断每个自然句音频中是否包括静音时段;
在自然句音频中包括静音时段的情况下,消除静音时段,将消除静音时段后的多段音频进行首尾拼接后,对拼接后的自然句音频进行声纹识别。
在本公开的一些实施例中,所述对拼接后的自然句音频进行声纹识别包括:
判断自然句音频的音频时长是否小于预定时长阈值;
在自然句音频的音频时长小于预定时长阈值的情况下,将小于预定时长阈值的自然句音频复制拼接为有效语音片段,其中,所述有效语音片段的音频时长不小于预定时长阈值;
对有效语音片段进行声纹识别。
在本公开的一些实施例中,所述对拼接后的自然句音频进行声纹识别包括:
判断自然句音频的音频时长是否大于预定时长阈值;
在自然句音频的音频时长大于预定时长阈值的情况下,将大于预定时长上限的自然句音频切分为多段有效语音片段;
对所述多段有效语音片段分别进行声纹识别;
结合多个有效语音片段的声纹识别结果进行综合判断。
根据本公开的另一方面,提供一种声纹识别装置,包括:
服务模块,用于获取用户实时音频流数据;
语音识别模块,用于对用户实时音频流数据进行实时语音识别,其中,所述对用户实时音频流数据进行实时语音识别包括:将用户实时音频流数据断句为自然句;
声纹识别模块,用于对断句后用户实时音频流数据中的每一自然句进行声纹识别。
在本公开的一些实施例中,所述声纹识别装置还包括自然语言处理模块,其中:
服务模块,还用于组合声纹识别结果和语音识别结果;
自然语言处理模块,用于利用自然语言处理方式,对组合后的声纹识别结果和语音识别结果进行优化。
在本公开的一些实施例中,所述声纹识别装置用于执行实现如上述任一实施例所述的声纹识别方法的操作。
根据本公开的另一方面,提供一种声纹识别装置,包括:
存储器,用于存储指令;
处理器,用于执行所述指令,使得所述装置执行实现如上述任一实施例所述的声纹识别方法的操作。
根据本公开的另一方面,提供一种声纹识别系统,包括:
收音装置,用于对用户音频进行实时采集,并将采集的用户实时音频流数据发送给声纹识别装置;
声纹识别装置,为如上述任一实施例所述的声纹识别装置。
根据本公开的另一方面,提供一种计算机可读存储介质,其中,所述计算机可读存储介质存储有计算机指令,所述指令被处理器执行时实现如上述任一实施例所述的声纹识别方法。
本公开可以基于语音识别将用户实时音频流数据变成语音长度的自然整句后进行声纹识别,从而提高了声纹识别的准确性。
附图说明
为了更清楚地说明本公开实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本公开声纹识别方法一些实施例的示意图。
图2为本公开声纹识别方法另一些实施例的示意图。
图3为相关技术声纹识别方法一些实施例的示意图。
图4为本公开声纹识别方法又一些实施例的示意图。
图5为本公开声纹识别装置一些实施例的示意图。
图6为本公开声纹识别装置另一些实施例的示意图。
图7为本公开声纹识别系统一些实施例的示意图。
图8为本公开声纹识别系统另一些实施例的示意图。
具体实施方式
下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本公开一部分实施例,而不是全部的实施例。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本公开及其应用或使用的任何限制。基于本公开中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本公开的范围。
同时,应当明白,为了便于描述,附图中所示出的各个部分的尺寸并不是按照实际的比例关系绘制的。
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为授权说明书的一部分。
在这里示出和讨论的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它示例可以具有不同的值。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
图1为本公开声纹识别方法一些实施例的示意图。优选的,本实施例可由本公开声纹识别装置或声纹识别系统执行。该方法包括以下步骤:
步骤11,获取用户实时音频流数据。
在本公开的一些实施例中,步骤11可以包括:接收收音装置实时收音、采集并发送的音频数据。
步骤12,对用户实时音频流数据进行实时语音识别。
在本公开的一些实施例中,步骤12可以包括:
步骤121,将用户实时音频流数据断句为自然句。
在本公开的一些实施例中,步骤121可以包括:根据用户实时音频流数据中的语句和静音时间等进行自动断句,将用户实时音频流数据断句为语义相对完整的自然句。
步骤122,确定断句后的每一自然句的起始和终止时间戳。
步骤13,对断句(语音识别分段)后的用户实时音频流数据中的每一自然句,根据时间戳进行对齐后,进行声纹识别和矫正。
在本公开的一些实施例中,本公开声纹识别方法还可以包括:预先注册声纹识别中验证人的声音数据,其中,在声音数据注册后、进行声纹识别的情况下,待识别的实时音频流数据与注册时验证人所说的自然语言、语义没有关联。
本公开声纹识别方法属于文本无关,不要求固定文本、数字、长度等,在声纹识别验证时用户可以随机说任何文字,均可以进行声纹识别。
在本公开的一些实施例中,步骤13可以包括:
步骤131,判断每个自然句音频中是否包括静音时段。
步骤132,在自然句音频中包括静音时段的情况下,消除静音时段,将消除静音时段后的多段音频进行首尾拼接后,对拼接后的自然句音频进行声纹识别。
在本公开的一些实施例中,步骤132中,所述对拼接后的自然句音频进行声纹识别的步骤可以包括:
步骤1,判断自然句音频的音频时长是否小于预定时长阈值。
步骤2,在自然句音频的音频时长小于预定时长阈值的情况下,将小于预定时长阈值的自然句音频复制拼接为有效语音片段,其中,所述有效语音片段的音频时长不小于预定时长阈值。
步骤3,对有效语音片段进行声纹识别。
在本公开的一些实施例中,预定时长阈值可以为6s。
例如:在本公开的一些具体实施例中,预定时长阈值为6s;若一个自然句音频,在去除静音时段、并将消除静音时段后的多段音频进行首尾拼接后的音频时长为3s,则将该音频复制拼接为6s的有效语音片段后进行声纹识别。
在本公开的另一些实施例中,步骤132中,所述对拼接后的自然句音频进行声纹识别的步骤可以包括:
步骤(1),判断自然句音频的音频时长是否大于预定时长阈值。
步骤(2),在自然句音频的音频时长大于预定时长阈值的情况下,将大于预定时长上限的自然句音频切分为多段有效语音片段。
步骤(3),对所述多段有效语音片段分别进行声纹识别。
步骤(4),结合多个有效语音片段的声纹识别结果进行综合判断,从而提高了长音频声纹识别结果的置信度。
例如:例如:在本公开的一些具体实施例中,预定时长阈值为6s;若一个自然句音频,在去除静音时段、并将消除静音时段后的多段音频进行首尾拼接后的音频时长为12s,则将该12s的音频切分为两段有效语音片段分别进行声纹识别,结合两个有效语音片段的声纹识别结果进行综合判断说话人。
基于本公开上述实施例提供的声纹识别方法,解决了说话人完整自然句被分割成多个片段,出现多个识别人的计算问题,从而提高了声纹识别的识别率和识别效果。
本公开上述实施例可以将短句进行拼接,从而解决了短句、超短句被判错角色人的技术问题。
本公开上述实施例先消除静音时段,再将消除静音时段后的自然句音频切分为多段语音片段,从而解决了含有大量静音的声音片段声纹识别准确度低的技术问题。
图2为本公开声纹识别方法另一些实施例的示意图。优选的,本实施例可由本公开声纹识别装置或声纹识别系统执行。图2实施例的步骤21-23分别与图1实施例的步骤11-13相同或类似。该方法包括以下步骤:
步骤21,获取用户实时音频流数据。
步骤22,对用户实时音频流数据进行实时语音识别。
在本公开的一些实施例中,步骤22可以包括:根据用户实时音频流数据中的语句和静音时间等进行自动断句,将用户实时音频流数据断句为语义相对完整的自然句;确定断句后的每一自然句的起始和终止时间戳。
步骤23,对语音识别分段后的用户实时音频流数据进行声纹识别,根据时间戳进行对齐后,进行声纹识别和矫正。
步骤24,组合声纹识别结果和语音识别结果。
步骤25,利用nlp(naturallanguageprocessing,自然语言处理)方式,对组合后的声纹识别结果和语音识别结果进行优化。
在本公开的一些实施例中,步骤25可以包括:通过对每个文本片段内部、以及相邻文本片段之间的语义分析,对识别结果中语义不完整、不合理的地方进行纠正,从而可以进一步提高语音识别和角色分离结果的准确度。
在本公开的一些实施例中,步骤25可以包括:利用自然语言处理技术和算法,对组合对齐后的实时声纹识别结果和实时语音识别结果进行语义优化,对于识别不准确的语句、语义和词汇,包括但不限于地址名、常用词、专有名词的矫正和优化等。
在本公开的一些实施例中,步骤25还可以包括:利用自然语言处理技术和算法,对声纹识别结果和语音识别结果进行语义摘要处理。
在本公开的一些实施例中,在步骤25之后,本公开声纹识别方法还可以包括:输出优化后的声纹识别结果和语音识别结果,即输出用户实时音频流数据对应的文字信息以及说话者身份信息。
在本公开的一些实施例中,在步骤25之后,本公开声纹识别方法还可以包括:显示优化后的声纹识别结果和语音识别结果。
在本公开的一些实施例中,在步骤25之后,本公开声纹识别方法还可以包括:存储优化后的声纹识别结果和语音识别结果。
在本公开的一些实施例中,在步骤25之后,本公开声纹识别方法还可以包括:将实时声纹识别结果和实时语音识别结果,实时展现在系统界面,或者存储在文件系统里。
下面通过具体实施例对本公开声纹识别方法与相关技术的声纹识别方法进行比较。
发明人经过研究发现:图3为相关技术声纹识别方法一些实施例的示意图。图3的相关技术先进行声纹识别,会将原始语音进行固定分割等预处理,然后送入声纹模型中进行判别。由于实时性的要求,切割后的语音片段无法保证说话人身份的唯一性,尤其是在会议场景、电话场景等多个说话人讲话时,在说话人切换或者停顿的时刻,切割后的语音片段可能含有多个说话人声音或者大段的空白,从而导致声纹识别结果的准确度下降。
例如:图3具体实施例中,用户音频数据中,用户语音的实际文字为“我很久就想请年假跟一家人去斯里兰卡度假了”。相关技术针对该段语音进行固定分割(每3s一个片段),针对分割后的三个片段,分别进行声纹识别和语音识别。
“我很久就想”------speakerid:a
“请年假跟一家人去斯里兰卡”------speakerid:b
“度假”-------speakerid:未识别出来null
其中,第二片段的声纹识别结果错误,第三片段的声纹识别没有识别出。
图4为本公开声纹识别方法又一些实施例的示意图。此如图4所示,本公开声纹识别方法包括:在声纹识别之前,先调用语音识别服务进行识别;基于语音识别对于自然句的识别的时间戳去对齐获取此句的起始和结束,将完整句子送入声纹识别模型,声纹识别不再分割成固定时长的片段,而是以可变成语音长度的自然整句进行识别。识别后直接判断为唯一说话人。最后,本方案将语音识别和声纹识别组合的结果采用自然语言理解技术进行矫正,根据每个片段内部以及相邻片段之间的前后文关系,及时调整识别结果中语义不完整、不合理的地方,从而降低语音识别可能出现的断句错误对最终结果的影响,进一步提高系统识别的准确度。
例如:图4具体实施例中,将用户语音的实际文字“我很久就想请年假跟一家人去斯里兰卡度假了”,判定为一个完整的自然整句。之后,对所述自然整句进行声纹识别,判定对应说话人。
例如:“我很久就想请年假跟一家人去斯里兰卡度假了”------speakerid:a
“去多久”------speakerid:b
由此,本申请的声纹识别结果和语音识别结果都是准确的。
本公开上述实施例在声纹识别中,对于短句进行有效语音拼接,对于长句进行有效语音分段识别、综合判断等音频预处理,由此本公开上述实施例大大提升了声纹识别的准确程度。
本公开上述实施例采用实时语音识别矫正和优化声纹识别结果,并用自然语言理解技术来矫正和优化语音识别和声纹识别组合呈现后的结果。由此本公开上述实施例可以进一步提高语音识别和角色分离结果的准确度。
图5为本公开声纹识别装置一些实施例的示意图。如图5所示,本公开声纹识别装置可以包括服务模块51、语音识别模块52和声纹识别模块53,其中:
服务模块51,用于获取用户实时音频流数据。
语音识别模块52,用于对用户实时音频流数据进行实时语音识别,其中,所述对用户实时音频流数据进行实时语音识别包括:将用户实时音频流数据断句为自然句。
在本公开的一些实施例中,语音识别模块52可以用于据用户实时音频流数据中的语句和静音时间等进行自动断句,将用户实时音频流数据断句为语义相对完整的自然句;确定断句后的每一自然句的起始和终止时间戳。
声纹识别模块53,用于对断句后用户实时音频流数据中的每一自然句,根据时间戳进行对齐后,进行声纹识别和矫正。
在本公开的一些实施例中,声纹识别模块53可以用于预先注册声纹识别中验证人的声音数据,其中,在声音数据注册后、进行声纹识别的情况下,待识别的实时音频流数据与注册时验证人所说的自然语言、语义没有关联。
在本公开的一些实施例中,声纹识别模块53可以用于判断每个自然句音频中是否包括静音时段;在自然句音频中包括静音时段的情况下,消除静音时段,将消除静音时段后的多段音频进行首尾拼接后,对拼接后的自然句音频进行声纹识别。
在本公开的一些实施例中,声纹识别模块53在对拼接后的自然句音频进行声纹识别的情况下,可以用于判断自然句音频的音频时长是否小于预定时长阈值;在自然句音频的音频时长小于预定时长阈值的情况下,将小于预定时长阈值的自然句音频复制拼接为有效语音片段,其中,所述有效语音片段的音频时长不小于预定时长阈值;对有效语音片段进行声纹识别。
在本公开的一些实施例中,声纹识别模块53在对拼接后的自然句音频进行声纹识别的情况下,可以用于判断自然句音频的音频时长是否大于预定时长阈值;在自然句音频的音频时长大于预定时长阈值的情况下,将大于预定时长上限的自然句音频切分为多段有效语音片段;对所述多段有效语音片段分别进行声纹识别;结合多个有效语音片段的声纹识别结果进行综合判断。
在本公开的一些实施例中,所述声纹识别装置用于执行实现如上述任一实施例(例如图1-图4任一实施例)所述的声纹识别方法的操作。
在本公开的一些实施例中,如图5所示,所述声纹识别装置还可以包括自然语言处理模块54,其中:
服务模块51,还用于组合声纹识别结果和语音识别结果。
自然语言处理模块54,用于利用自然语言处理方式,对组合后的声纹识别结果和语音识别结果进行优化。
在本公开的一些实施例中,自然语言处理模块54还可以用于通过对每个文本片段内部、以及相邻文本片段之间的语义分析,对识别结果中语义不完整、不合理的地方进行纠正,从而可以进一步提高语音识别和角色分离结果的准确度。
基于本公开上述实施例提供的声纹识别装置,解决了说话人完整自然句被分割成多个片段,出现多个识别人的技术问题,从而提高了声纹识别的识别率和识别效果。
本公开上述实施例可以将短句进行拼接,从而解决了短句、超短句被判错角色人的技术问题。
本公开上述实施例先消除静音时段,再将消除静音时段后的自然句音频切分为多段语音片段,从而解决了含有大量静音的声音片段声纹识别准确度低的技术问题。
本公开上述实施例可以将语音识别和声纹识别组合后的呈现结果进一步优化,通过对每个文本片段内部、以及相邻文本片段之间的语义分析,对识别结果中语义不完整、不合理的地方进行纠正,从而可以进一步提高语音识别和角色分离结果的准确度。
图6为本公开声纹识别装置另一些实施例的示意图。如图6所示,本公开声纹识别装置可以包括存储器61和处理器62,其中:
存储器61,用于存储指令。
处理器62,用于执行所述指令,使得所述装置执行实现如上述任一实施例(例如图1-图4任一实施例)所述的声纹识别方法的操作。
与相关技术相比,本公开上述实施例对接收的语音信号先进行实时语音识别,语音识别根据用户所说话的语句、静音时间等进行自动断句为语义相对完整的自然句,根据识别结果中每一个语句的起止时间戳截取对应的语音片段进行声纹识别。由此解决了说话人完整自然句被分割成多个片段,出现多个识别人的技术问题,从而提高了声纹识别的识别率和识别效果。
本公开上述实施例采用了自然语言理解技术,对最终生成文本的语义进行完整性和合理性分析,从而进一步提高了语音识别和声纹角色分离的准确度。
图7为本公开声纹识别系统一些实施例的示意图。如图7所示,本公开声纹识别系统可以包括收音装置71和声纹识别装置72,其中:
收音装置71,用于对用户音频进行实时采集,并将采集的用户实时音频流数据发送给声纹识别装置。
声纹识别装置72,为如上述任一实施例(例如图5或图6实施例)所述的声纹识别装置。
基于本公开上述实施例提供的声纹识别系统,先进行流式的语音识别,语音识别根据用户所说话的语句、静音时间等进行自动断句为语义相对完整的自然句,用此自然句的起始终止时间戳的时间片段去进行声纹识别。由此解决了说话人完整自然句被分割成多个片段,出现多个识别人的技术问题,从而提高了声纹识别的识别率和识别效果。
图8为本公开声纹识别系统另一些实施例的示意图。如图8所示,本公开声纹识别系统可以包括收音装置71和声纹识别装置,其中:声纹识别装置可以包括如图5实施例所述的服务模块51、语音识别模块52、声纹识别模块53和自然语言处理模块54,其中:
图8实施例还给出了本公开声纹识别系统完成语音识别的方法步骤。如图8所示,本公开声纹识别方法可以包括:
步骤81,收音装置71对采集的音频进行实时收音,将音频数据流实时发送到声纹识别装置的服务模块51。
步骤82,服务模块51先向语音识别模块52进行请求。
步骤83,语音识别模块52根据用户所说话的语句、静音时间等进行自动断句为语义相对完整的自然句,并带自然句的起始结束的时间戳和识别结果发给服务模块51。
步骤84,服务模块51调用声纹识别模块53识别将此分段的语音进行声纹识别,声纹识别模块53根据时间戳进行对齐后进行识别和矫正。
在本公开的一些实施例中,根据截取音频的长短,步骤84可以包括两种解决方案:
步骤841,对于短自然句音频,声纹识别模块53采用音频拼接的方法,使其达到声纹识别能接受的音频时长的阈值,从而克服了有效语音不足导致声纹识别准确度低的问题。
步骤842,对于长自然句音频,声纹识别模块53采用音频静音消除后再拼接的方法,将其切分为多段有效的语音片段,分别进行声纹识别,并利用多个声纹识别结果进行综合判断,从而提高了长音频声纹识别结果的置信度。
步骤85,声纹识别模块53将此段句子的声纹识别结果发送给服务模块51。
步骤86,服务模块51组合声纹识别和语音识别结果;并将组合后的声纹识别和语音识别结果发送给自然语言处理模块54。
步骤87,自然语言处理模块54利用自然语言理解技术来优化声纹识别和语音识别结果;并将优化后的语言处理模块54利用自然语言理解技术来优化返回服务模块51,进行存储和对外显示。
在本公开的一些实施例中,步骤7可以包括服务模块51通过对每个文本片段内部、以及相邻文本片段之间的语义分析,对识别结果中语义不完整、不合理的地方进行纠正,从而进一步提高了语音识别和角色分离结果的准确度。
针对相关技术在要求实时的语音识别+实时声纹识别,且说话人快速切换语句等场景下,声纹识别的准确率无法达到商用要求的技术问题,本公开上述实施例提出了一种基于语音识别和语义理解技术实时矫正声纹识别结果的方法、装置和系统。
本公开上述实施例提供的声纹识别装置,可以将短句进行拼接,从而解决了短句、超短句被判错角色人的技术问题,从而提高了声纹识别的识别率和识别效果。
本公开上述实施例先消除静音时段,再将消除静音时段后的自然句音频切分为多段语音片段,从而解决了含有大量静音的声音片段声纹识别准确度低的技术问题,进一步提高了声纹识别的识别率和识别效果。
本公开上述实施例可以将语音识别和声纹识别组合后的呈现结果进一步优化,通过对每个文本片段内部、以及相邻文本片段之间的语义分析,对识别结果中语义不完整、不合理的地方进行纠正,从而可以进一步提高语音识别和角色分离结果的准确度。
根据本公开的另一方面,提供一种计算机可读存储介质,其中,所述计算机可读存储介质存储有计算机指令,所述指令被处理器执行时实现如上述任一实施例(例如图1-图4任一实施例)所述的声纹识别方法。
基于本公开上述实施例提供的计算机可读存储介质,先进行流式的语音识别,语音识别根据用户所说话的语句、静音时间等进行自动断句为语义相对完整的自然句,用此自然句的起始终止时间戳的时间片段去进行声纹识别。由此解决了说话人完整自然句被分割成多个片段,出现多个识别人的技术问题,从而提高了声纹识别的识别率和识别效果。
在上面所描述的声纹识别装置可以实现为用于执行本申请所描述功能的通用处理器、可编程逻辑控制器(plc)、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件或者其任意适当组合。
至此,已经详细描述了本公开。为了避免遮蔽本公开的构思,没有描述本领域所公知的一些细节。本领域技术人员根据上面的描述,完全可以明白如何实施这里公开的技术方案。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指示相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
本公开的描述是为了示例和描述起见而给出的,而并不是无遗漏的或者将本公开限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显然的。选择和描述实施例是为了更好说明本公开的原理和实际应用,并且使本领域的普通技术人员能够理解本公开从而设计适于特定用途的带有各种修改的各种实施例。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



