
 商标分类
商标分类  商标转让
商标转让 
语音增强方法、系统、电子设备和存储介质与流程
 2021-01-28 13:01:30|
2021-01-28 13:01:30| 275|
275| 起点商标网
起点商标网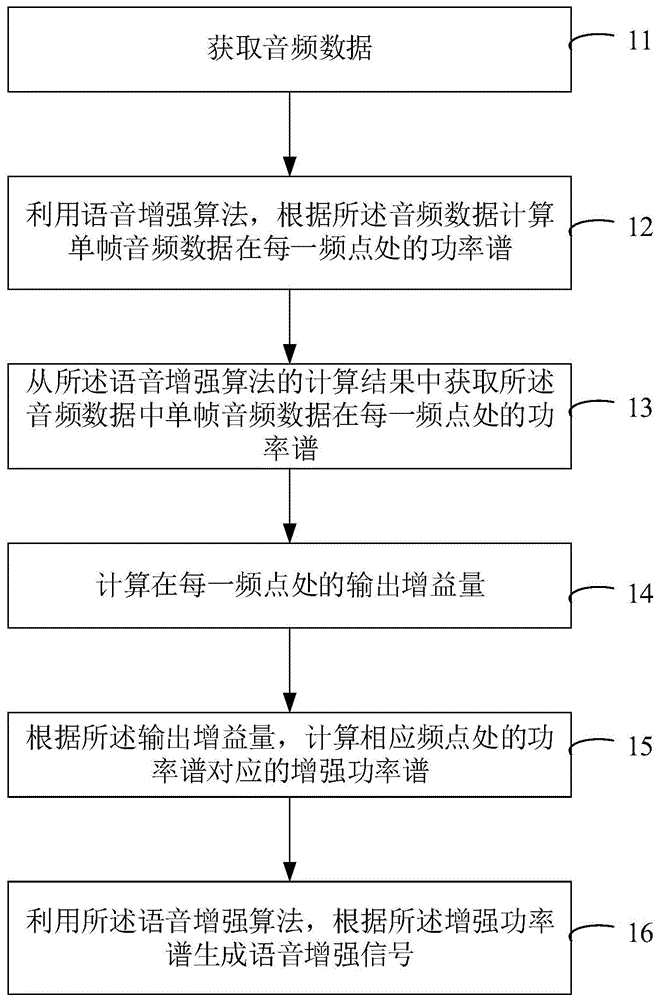
本发明属于计算机领域,尤其涉及一种语音增强方法、系统、电子设备和存储介质。
背景技术:
语音增强是语音信号处理系统的核心技术之一,其增强效果的好坏直接影响输出语音的质量,对后续的处理,包括关键词唤醒,语音识别等有着重要的影响。
在现有的语音增强算法中,分为单通道和多通道语音增强。其中多通道语音增强使用较多的是波束形成算法,其核心是设计一种空间滤波,实现对期望方向的语音进行增强,对其它方向的声音进行抑制。
对于单通道语音增强使用较多的算法包括谱减法、最小均方误差估计以及omlsa(optimallymodifiedlog-spectralamplitudeestimator)算法。其核心先对噪声进行估计,然后从含噪语音中估计出干净的语音。
在现有的技术方案中,单通道语音增强的处理过程中对输出音频的增益没有做处理,而是在语音增强处理结束后再利用单独的增益控制模块对输出的音频进行增益调整。这种方式一方面无法避免语音增强处理后的语音可能出现声音过大或过小的情况,另一方面在增加输出增益调整后使得系统变得复杂,消耗较多的计算资源。
技术实现要素:
本发明实施例要解决的技术问题是为了克服现有技术中单通道语音增强的处理过程中对输出音频的增益没有做处理的缺陷,提供一种语音增强方法、系统、电子设备和存储介质。
本发明实施例是通过以下技术方案解决上述技术问题的:
本发明实施例提供一种语音增强方法,包括:
获取音频数据;
利用语音增强算法,根据所述音频数据计算单帧音频数据在每一频点处的功率谱;
从所述语音增强算法的计算结果中获取所述功率谱;
计算在每一频点处的输出增益量;
根据所述输出增益量,计算相应频点处的功率谱对应的增强功率谱;
利用所述语音增强算法,根据所述增强功率谱生成语音增强信号。
较佳地,所述语音增强方法还包括在计算每一频点处的输出增益量之前:利用所述语音增强算法,根据所述音频数据计算在每一频点处的噪声抑制增益量;
计算在每一频点处的输出增益量的步骤包括:
从所述语音增强算法的计算结果中获取在每一频点处的噪声抑制增益量;
获取当前的增益量;
根据所述噪声抑制增益量、所述功率谱以及当前的增益量,计算所述单帧音频数据的当前语音响度,所述当前语音响度等于所述单帧音频数据在每一频点处的语音响度的累计;
比较所述当前语音响度与参考语音响度,计算使所述当前语音响度与所述参考语音响度缩小差距的增益调整量;
对当前的增益量调整所述增益调整量,得到新的增益量;
计算每一频点处的输出增益量,所述输出增益量等于新的增益量乘以相应频点处的噪声抑制增益量。
较佳地,计算在每一频点处的输出增益量的步骤还包括在获取所述噪声抑制增益量之后且在计算所述当前语音响度之前执行以下步骤:
计算在每一频点处的临时增益量,其中:
若所述噪声抑制增益量大于或等于增益阈值,则所述临时增益量等于1;
若所述噪声抑制增益量小于所述增益阈值,则所述临时增益量等于0;
在计算所述当前语音响度的步骤中,所述当前语音响度等于所述临时增益量等于1的频点处的语音响度的累计。
较佳地,比较所述当前语音响度与参考语音响度,计算使所述当前语音响度与所述参考语音响度缩小差距的增益调整量的步骤包括:
比较所述当前语音响度与所述参考语音响度;
若所述当前语音响度大于所述参考语音响度,则所述增益调整量取负值;
若所述当前语音响度小于所述参考语音响度,则所述增益调整量取正值;
若所述当前语音响度等于所述参考语音响度,则所述增益调整量取0。
较佳地,正的增益调整量和负的增益调整量的绝对值相等。
较佳地,所述当前的增益量等于前一帧音频数据的增益量,起始帧音频数据的增益量等于预设的增益初始值。
较佳地,所述语音增强算法为omlsa算法。
本发明实施例还提供一种语音增强系统,包括:
音频获取模块,用于获取音频数据;
第一算法模块,用于利用语音增强算法,根据所述音频数据计算单帧音频数据在每一频点处的功率谱;
第一获取模块,用于从所述第一算法模块获取所述功率谱;
第一计算模块,用于计算在每一频点处的输出增益量;
第二计算模块,用于根据所述输出增益量,计算相应频点处的功率谱对应的增强功率谱;
第二算法模块,用于利用所述语音增强算法,根据所述增强功率谱生成语音增强信号。
较佳地,所述第一算法模块还用于利用所述语音增强算法,根据所述音频数据计算在每一频点处的噪声抑制增益量的步骤;
所述第一计算模块具体包括:
增益获取单元,用于从所述第一算法模块获取在每一频点处的噪声抑制增益量,获取当前的增益量;
响度计算单元,用于根据所述噪声抑制增益量、所述功率谱以及当前的增益量,计算所述单帧音频数据的当前语音响度,所述当前语音响度等于所述单帧音频数据在每一频点处的语音响度的累计;
增益调整单元,用于比较所述当前语音响度与参考语音响度,计算使所述当前语音响度与所述参考语音响度缩小差距的增益调整量,对当前的增益量调整所述增益调整量,得到新的增益量;
增益计算单元,用于计算每一频点处的输出增益量,所述输出增益量等于新的增益量乘以相应频点处的噪声抑制增益量。
较佳地,所述第一计算模块还具体包括:
临时增益单元,用于在获取所述噪声抑制增益量之后且在计算所述当前语音响度之前计算在每一频点处的临时增益量,其中:
若所述噪声抑制增益量大于或等于增益阈值,则所述临时增益量等于1;
若所述噪声抑制增益量小于所述增益阈值,则所述临时增益量等于0;
在所述响度计算单元中,所述当前语音响度等于所述临时增益量等于1的频点处的语音响度的累计。
较佳地,所述增益调整单元还用于:
比较所述当前语音响度与所述参考语音响度;
若所述当前语音响度大于所述参考语音响度,则所述增益调整量取负值;
若所述当前语音响度小于所述参考语音响度,则所述增益调整量取正值;
若所述当前语音响度等于所述参考语音响度,则所述增益调整量取0。
较佳地,正的增益调整量和负的增益调整量的绝对值相等。
较佳地,所述当前的增益量等于前一帧音频数据的增益量,起始帧音频数据的增益量等于预设的增益初始值。
较佳地,所述语音增强算法为omlsa算法。
本发明实施例还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上所述的语音增强方法。
本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现如上所述的语音增强方法的步骤。
在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
本发明实施例的积极进步效果在于:在语音增强的过程中增加了自动增益调整的过程,避免语音增强处理后的语音可能出现声音过大或过小的情况,在对语音增强算法不增加太多计算量的情况下,实现对输出音频的自动增益控制。
附图说明
图1为本发明较佳实施例1的一种语音增强方法的流程图;
图2为本发明较佳实施例2的一种语音增强方法中步骤14的流程图;
图3为本发明较佳实施例2的另一种语音增强方法中步骤14的流程图;
图4为本发明较佳实施例3的一种基于omlsa算法的语音增强方法的流程图;
图5为本发明较佳实施例4的一种语音增强系统的示意框图;
图6为本发明较佳实施例5的一种语音增强系统的示意框图;
图7为本发明较佳实施例6的一种电子设备的结构示意图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
实施例1
本实施例给出了一种语音增强方法,其可以在语音增强算法的基础上进行音频输出增益的自动控制。如图1所示,所述语音增强方法可以包括:
步骤11:获取音频数据。所述音频数据可以包括以某一采样频率采集的若干采样数据。
步骤12:利用语音增强算法,根据所述音频数据计算单帧音频数据在每一频点处的功率谱。当然,此步骤还可以包括实现所述语音增强算法原有的其他步骤。取决于所述语音增强算法,根据所述音频数据计算单帧音频数据在每一频点处的功率谱的步骤可能是一个步骤,也可能是多个步骤。从所述音频数据可以直接或间接得到所述功率谱。
步骤13:从所述语音增强算法的计算结果中获取所述音频数据中单帧音频数据在每一频点处的功率谱。
步骤14:计算在每一频点处的输出增益量。其中,所述输出增益量可以表示输出音频的增益,可以影响最终输出音频的音量。
步骤15:根据所述输出增益量,计算相应频点处的功率谱对应的增强功率谱。
步骤16:利用所述语音增强算法,根据所述增强功率谱生成语音增强信号。当然,此步骤还可以包括实现所述语音增强算法原有的其他步骤。取决于所述语音增强算法,根据所述增强功率谱生成语音增强信号的步骤可能是一个步骤,也可能是多个步骤。从所述增强功率谱可以直接或间接得到所述语音增强信号。
本实施例的语音增强方法在语音增强算法中插入了步骤13-15,利用所述功率谱和所述输出增益量计算的所述增强功率谱,替代所述功率谱作用于利用语音增强算法实现的步骤15中,将所述语音增强算法中原先使用所述功率谱的位置替换为使用所述增强功率谱,使得生成所述语音增强信号的同时自动完成音量调节。其相比于单独利用语音增强算法,可在生成语音增强信号之前,在不增加过多计算量的情况下实现了对输出增益量的自动增益控制。其相比于单独利用语音增强算法生成语音增强信号及在生成语音增强信号后再单独进行音量调节,还可减化方法流程,减少计算资源。
实施例2
本实施例是在实施例1上的进一步改进,其给出了可以计算每一频点处的输出增益量的一种具体过程,实现了自动增益控制。所述语音增强方法还包括在计算每一频点处的输出增益量之前:利用所述语音增强算法,根据所述音频数据计算在每一频点处的噪声抑制增益量。如图2所示,步骤14可以具体包括以下步骤:
步骤141:从所述语音增强算法的计算结果中获取在每一频点处的噪声抑制增益量。
步骤142:获取当前的增益量。其中,所述当前的增益量可以等于前一帧音频数据的增益量,起始帧音频数据的增益量可以等于预设的增益初始值。
步骤143:根据所述噪声抑制增益量、所述功率谱以及当前的增益量,计算所述单帧音频数据的当前语音响度,所述当前语音响度等于所述单帧音频数据在每一频点处的语音响度的累计。
步骤144:比较所述当前语音响度与参考语音响度,计算使所述当前语音响度与所述参考语音响度缩小差距的增益调整量。
在一些实施例中,可以通过所述当前语音响度与所述参考语音响度的比较结果计算所述增益调整量,具体可以包括:比较所述当前语音响度与所述参考语音响度;若所述当前语音响度大于所述参考语音响度,则所述增益调整量取负值;若所述当前语音响度小于所述参考语音响度,则所述增益调整量取正值;若所述当前语音响度等于所述参考语音响度,则所述增益调整量取0。优选地,正的增益调整量和负的增益调整量的绝对值相等,使得每次输出音量调整相同,实现音量的均匀调整。由此给出一种可以计算所述增益调整量的公式:
其中lt0为参考语音响度,可以设定为期望达到的语音响度,可以取60分贝或根据实际需求进行调整;δg0为所述增益调整量,可以取0.05或可根据实际需求进行调整。
步骤145:对当前的增益量调整所述增益调整量,得到新的增益量ga:
ga=ga+δga
步骤146:计算每一频点处的输出增益量,所述输出增益量等于新的增益量乘以相应频点处的噪声抑制增益量。其中,在频点k处的输出增益量go,k可以为:
go,k=ga*gk
在一些实施例中,还可以引入临时增益量作为粗略判断在一个频点处是否存在语音的参数,步骤14还可以如图3所示,还包括在步骤141之后且在步骤142之前执行以下步骤,或,在一些实施例中步骤14还可以包括在步骤142之后且在步骤143之前执行以下步骤:
步骤1411:计算在每一频点处的临时增益量,其中,若所述噪声抑制增益量大于或等于增益阈值,则所述临时增益量等于1;若所述噪声抑制增益量小于所述增益阈值,则所述临时增益量等于0。
利用公式表示在频点k处的临时增益量gs,k可以为:
其中gt0为设置的所述增益阈值。若所述噪声抑制增益量大于或等于所述增益阈值,则表示在频点k处存在语音,否则表示在频点k处不存在语音。所述增益阈值可以取0.5,也可以根据具体的环境和需求进行调节。
相应地,在步骤143中,所述当前语音响度等于所述临时增益量等于1的频点处的语音响度的累计。下面给出了计算当前语音响度的一种公式::
其中,l为当前语音响度,ga为当前的增益量,gk为在频点k处的噪声抑制增益量,sl,k为在频点k处的功率谱。
上述的步骤14可以利用所述语音增强算法中计算的一些参数,快速完成自动增益控制,不会给增加过多的计算量。在执行完步骤14后,步骤15中在频点k处的所述增强功率谱yl,k:
yl,k=sl,kgo,k
步骤16利用yl,k继续所述语音增强算法中生成语音增强信号的步骤,完成语音增量调节。
实施例3
omlsa算法是一种单通道语音增强算法。本实施例给出了基于omlsa算法的语音增强方法。如图4所示,所述方法包括获取音频数据,然后执行以下步骤:
步骤001:分帧:将采集到的音频数据进行分帧,这里采样率为16k,具体可根据实际情况进行调整,每帧的大小为n=512个采样点,帧移为256,即当前帧的n采样点包括256个新采集的数据和上一帧后256个数据。
xl=[xl,0xl,1…xl,n-1]t
其中xl为第l帧的音频数据。
步骤002:加窗:由于语音信号是非平稳的信号,傅里叶变换需要信号是平稳的,因此需要增加窗函数将非平稳信号变成短时平稳信号。这里的窗函数选择汉明窗,其表达式如下:
数据帧进行加窗的实现如下:
步骤003:fft:对加窗后的信号进行fft(快速傅里叶变换),将信号从时域转换成频域信号。
其中xl,k=[xl,0xl,k…xl,n-1]t。元素xl,k为第l帧频点k处的值。
步骤004:功率谱计算:根据功率谱的定义,频点k处的功率谱计算如下:
sl,k=|xl,k|2
步骤005:噪声估计:这个主要是对静态噪声估计,使用的估计方法为imcra算法。
步骤006:信噪比和语音概率计算:噪声抑制增益量计算,属于omlsa算法的标准流程,由于其不是本发明的重点,故在此不进行详细展开,只给出必要的符号说明,在频点k处的噪声抑制增益量表示为
gk∈[0,1]
所述噪声抑制增益量与该频点的语音概率有关系,即如果语音存在的可能性比较大,则增益值较大,如果语音存在的概率较少,则增益值较少。通过将增益作用在相应的频点上来实现语音的增强。
步骤007:自动增益计算:包括实施例1或2中的步骤13-15。该过程最后的输出是在频点k处的输出增益量go,k。
步骤008:语音增强:根据计算出的输出增益量,作用在相应频点的功率谱上进行增强,得到增强功率谱。对于频点k,实现如下:
yl,k=sl,kgo,k
步骤009:ifft:傅里叶逆变换,将增强后的频域数据转换到时域。
yl=ifft(yl)
其中
yl=[yl,0yl,1…yl,n-1]t
步骤010:加窗与合帧:将增强后的时域信号进行加窗,然后采用重叠-相加的方式合成最后的语音增强信号。
虽然本实施例给出了基于omlsa算法进行语音增强的方法,但是本发明并不局限于此,凡是能够提供步骤13-15所需要的必要参数的语音增强算法,均可与步骤13-15结合,从而形成本发明的其他实施例。
在实际的工程实现中,可以结合多通道语音增强算法和单通道语音增强算法两种方式对语音进行增强,即先用多通道语音增强算法对期望方向的语音信号进行增强,然后再使用单通道的增强算法对信号进行进一步的增强处理,此种情况,本发明同样适用。
实施例4
本实施例给出了一种语音增强方法,其可以在语音增强算法的基础上进行音频输出增益的自动控制。如图5所示,所述语音增强系统可以包括:
音频获取模块21,用于获取音频数据。所述音频数据可以包括以某一采样频率采集的若干采样数据。
第一算法模块22,用于利用语音增强算法,根据所述音频数据计算单帧音频数据在每一频点处的功率谱。当然,所述第一算法模块22还可以实现所述语音增强算法原有的其他步骤。取决于所述语音增强算法,根据所述音频数据计算单帧音频数据在每一频点处的功率谱的步骤可能是一个步骤,也可能是多个步骤。从所述音频数据可以直接或间接得到所述功率谱。
第一获取模块23,用于从所述第一算法模块22获取所述功率谱。
第一计算模块24,用于计算在每一频点处的输出增益量。其中,所述输出增益量可以表示输出音频的增益,可以影响最终输出音频的音量。
第二计算模块25,用于根据所述输出增益量,计算相应频点处的功率谱对应的增强功率谱。
第二算法模块26,用于利用所述语音增强算法,根据所述增强功率谱生成语音增强信号。当然,所述第二算法模块26还可以实现所述语音增强算法原有的其他步骤。取决于所述语音增强算法,根据所述增强功率谱生成语音增强信号的步骤可能是一个步骤,也可能是多个步骤。从所述增强功率谱可以直接或间接得到所述语音增强信号。
本实施例的语音增强系统在所述第一算法模块22和所述第二算法模块26之间插入了所述第一获取模块23、第一计算模块24和第二计算模块25,利用所述功率谱和所述输出增益量计算的所述增强功率谱,替代所述功率谱作用于所述第二算法模块26中,将所述语音增强算法中原先使用所述功率谱的位置替换为使用所述增强功率谱,使得生成所述语音增强信号的同时自动完成音量调节。其相比于单独利用语音增强算法,可在生成语音增强信号之前,在不增加过多计算量的情况下实现了对输出增益量的自动增益控制。其相比于单独利用语音增强算法生成语音增强信号及在生成语音增强信号后再单独进行音量调节,还可减化系统,减少计算资源。
实施例5
本实施例是在实施例4上的进一步改进,其给出了可以计算每一频点处的输出增益量的一种具体过程,实现了自动增益控制。所述第一算法模块22还用于利用所述语音增强算法,根据所述音频数据计算在每一频点处的噪声抑制增益量。如图6所示,所述第一计算模块24具体包括:
增益获取单元241,用于从所述第一算法模块22获取在每一频点处的噪声抑制增益量,获取当前的增益量。其中,所述当前的增益量可以等于前一帧音频数据的增益量,起始帧音频数据的增益量可以等于预设的增益初始值。
响度计算单元242,用于根据所述噪声抑制增益量、所述功率谱以及当前的增益量,计算所述单帧音频数据的当前语音响度,所述当前语音响度等于所述单帧音频数据在每一频点处的语音响度的累计。
增益调整单元243,用于比较所述当前语音响度与参考语音响度,计算使所述当前语音响度与所述参考语音响度缩小差距的增益调整量,对当前的增益量调整所述增益调整量,得到新的增益量。
增益计算单元244,用于计算每一频点处的输出增益量,所述输出增益量等于新的增益量乘以相应频点处的噪声抑制增益量。
在一些实施例中,可以通过所述当前语音响度与所述参考语音响度的比较结果计算所述增益调整量,所述增益调整单元243还用于:
比较所述当前语音响度与所述参考语音响度;
若所述当前语音响度大于所述参考语音响度,则所述增益调整量取负值;
若所述当前语音响度小于所述参考语音响度,则所述增益调整量取正值;
若所述当前语音响度等于所述参考语音响度,则所述增益调整量取0。
优选地,正的增益调整量和负的增益调整量的绝对值相等,使得每次输出音量调整相同,实现音量的均匀调整。
在一些实施例中,还可以引入临时增益量作为粗略判断在一个频点处是否存在语音的参数,所述第一计算模块24还具体包括:
临时增益单元245,用于在获取所述噪声抑制增益量之后且在计算所述当前语音响度之前计算在每一频点处的临时增益量,其中:
若所述噪声抑制增益量大于或等于增益阈值,则所述临时增益量等于1;
若所述噪声抑制增益量小于所述增益阈值,则所述临时增益量等于0;
在所述响度计算单元242中,所述当前语音响度等于所述临时增益量等于1的频点处的语音响度的累计。
上述的第一计算模块24可以利用所述语音增强算法中计算的一些参数,快速完成自动增益控制,不会给增加过多的计算量。
omlsa算法是一种单通道语音增强算法。本实施例还给出了基于omlsa算法进行语音增强的系统。所述系统包括所述音频获取模块21、所述第一算法模块22、所述第一获取模块23、所述第一计算模块24、所述第二计算模块25和所述第二算法模块26。其中,所述第一算法模块22可执行实施例3中的步骤001-007。所述第二算法模块26可执行实施例3中的步骤008-010。
实施例6
图7为本发明实施例6提供的一种电子设备的结构示意图。所述电子设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现实施例1-3的任意一种语音增强方法。图7显示的电子设备40仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
如图7所示,电子设备40可以以通用计算设备的形式表现,例如其可以为服务器设备。电子设备40的组件可以包括但不限于:上述至少一个处理器41、上述至少一个存储器42、连接不同系统组件(包括存储器42和处理器41)的总线43。
总线43包括数据总线、地址总线和控制总线。
存储器42可以包括易失性存储器,例如随机存取存储器(ram)421和/或高速缓存存储器422,还可以进一步包括只读存储器(rom)423。
存储器42还可以包括具有一组(至少一个)程序模块424的程序/实用工具425,这样的程序模块424包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
处理器41通过运行存储在存储器42中的计算机程序,从而执行各种功能应用以及数据处理,例如本发明实施例1-3所提供的语音增强方法。
电子设备40也可以与一个或多个外部设备44(例如键盘、指向设备等)通信。这种通信可以通过输入/输出(i/o)接口45进行。并且,模型生成的设备40还可以通过网络适配器46与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图7所示,网络适配器46通过总线43与模型生成的设备40的其它模块通信。应当明白,尽管图中未示出,可以结合模型生成的设备40使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理器、外部磁盘驱动阵列、raid(磁盘阵列)系统、磁带驱动器以及数据备份存储系统等。
应当注意,尽管在上文详细描述中提及了电子设备的若干单元/模块或子单元/模块,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本发明的实施方式,上文描述的两个或更多单元/模块的特征和功能可以在一个单元/模块中具体化。反之,上文描述的一个单元/模块的特征和功能可以进一步划分为由多个单元/模块来具体化。
实施例10
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现实施例1-3所提供的任意一种语音增强方法的步骤。
其中,可读存储介质可以采用的更具体可以包括但不限于:便携式盘、硬盘、随机存取存储器、只读存储器、可擦拭可编程只读存储器、光存储器件、磁存储器件或上述的任意合适的组合。
在可能的实施方式中,本发明还可以实现为一种程序产品的形式,其包括程序代码,当所述程序产品在终端设备上运行时,所述程序代码用于使所述终端设备执行实现实施例1-3所述的任意一种语音增强方法中的步骤。
其中,可以以一种或多种程序设计语言的任意组合来编写用于执行本发明的程序代码,所述程序代码可以完全地在用户设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户设备上部分在远程设备上执行或完全在远程设备上执行。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这些仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



