
 商标分类
商标分类  商标转让
商标转让 
单通道语音增强方法及装置、存储介质、终端与流程
 2021-01-28 13:01:16|
2021-01-28 13:01:16| 286|
286| 起点商标网
起点商标网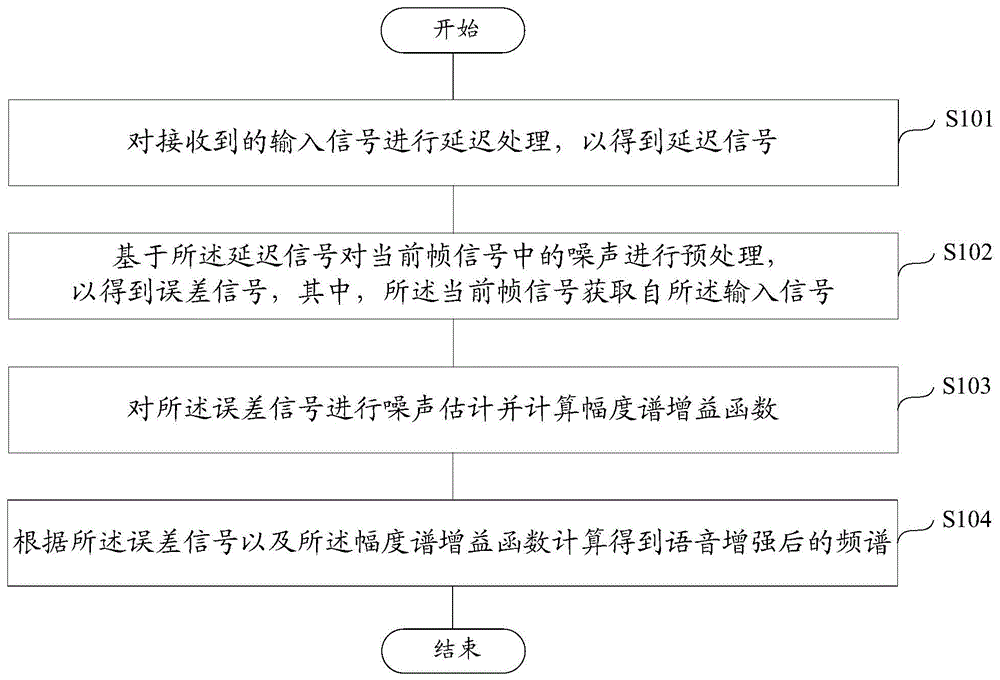
本发明涉及语音处理技术领域,具体地涉及一种单通道语音增强方法及装置、存储介质、终端。
背景技术:
现实生活中经常会遇到各种各样的噪声场景,其中鸣笛类噪声比较常见。通常而言,鸣笛类噪声包括马路上汽车拥堵时发出的鸣笛声、火车站火车进站时发出的汽笛声以及工厂中机器发出的轰鸣声等。这类噪声响度大且持续时间长,会严重影响语音通话的质量。
如今的智能手机通常会配备两个或多个麦克风,这种配置可以通过麦克风之间的能量差等方法有效地消除鸣笛类噪声的干扰。
但是,对于一些只配置有一个麦克风的低端手机或者通话手表来说,现有的降噪方案不能很好的在较短的时间内对鸣笛类噪声做出抑制。或者,现有的降噪方案应用于单通道语音设备时,在消除鸣笛类噪声的同时对原有的语音成分也进行了抑制,导致语音失真。
综上,现有技术亟需一种能够适用于单通道语音设备的语音增强方案,能够在较短时间内消除鸣笛类噪声同时保护原有语音质量。
技术实现要素:
本发明解决的技术问题是在单通道语音通话场景中如何在较短时间内有效抑制鸣笛类噪声并维持较优的语音质量。
为解决上述技术问题,本发明实施例提供一种单通道语音增强方法,包括:对接收到的输入信号进行延迟处理,以得到延迟信号;基于所述延迟信号对当前帧信号中的噪声进行预处理,以得到误差信号,其中,所述当前帧信号获取自所述输入信号;对所述误差信号进行噪声估计并计算幅度谱增益函数;根据所述误差信号以及所述幅度谱增益函数计算得到语音增强后的频谱。
可选的,所述误差信号是对所述当前帧信号中的第一类噪声进行预测并抑制后得到的含噪语音信号,所述第一类噪声在前后两帧信号中的特性基本保持不变。
可选的,所述对接收到的输入信号进行延迟处理,以得到延迟信号包括:对所述当前帧信号进行预设数量的采样点的延迟,以得到所述延迟信号。
可选的,所述当前帧信号包括多个采样点,所述对所述当前帧信号进行预设数量的采样点的延迟,以得到所述延迟信号包括:将所述当前帧信号中的采样点依次右移预设数量得到的序列确定为所述延迟信号。
可选的,所述基于所述延迟信号对当前帧信号中的噪声进行预处理,以得到误差信号包括:将所述延迟信号输入自适应滤波器,以预估得到所述延迟信号中的预估噪声信号;根据所述当前帧信号和所述预估噪声信号计算得到所述误差信号。
可选的,所述将所述延迟信号输入自适应滤波器,以预估得到所述延迟信号中的预估噪声信号包括:将所述延迟信号与所述自适应滤波器的滤波器系数进行卷积运算,并将卷积运算结果确定为所述预估噪声信号。
可选的,所述单通道语音增强方法还包括:根据所述误差信号更新所述自适应滤波器的滤波器系数。
可选的,所述对所述误差信号进行噪声估计并计算幅度谱增益函数包括:获取所述误差信号的频域幅度谱;对所述误差信号的频域幅度谱进行噪声估计,以得到所述误差信号的噪声功率谱;根据所述噪声功率谱计算得到所述误差信号的幅度谱增益函数。
可选的,所述对所述误差信号的频域幅度谱进行噪声估计,以得到所述误差信号的噪声功率谱包括:根据上一帧信号的误差信号功率谱以及所述当前帧信号的频率幅度谱,计算得到所述当前帧信号的误差信号功率谱;根据所述上一帧信号的误差信号功率谱的最小值、所述当前帧信号的误差信号功率谱以及预设噪声估计参数,计算得到所述当前帧信号的误差信号功率谱的最小值;根据所述当前帧信号的误差信号功率谱以及所述上一帧信号的噪声功率谱,估算所述当前帧信号的初始后验信噪比;根据所述上一帧信号的幅度谱增益函数、所述上一帧信号的优选后验信噪比以及当前帧信号的初始后验信噪比,估算所述当前帧信号的初始先验信噪比;根据所述初始后验信噪比、初始先验信噪比以及所述当前帧信号的语音不存在概率,计算得到所述当前帧信号的语音存在概率;根据所述当前帧信号的语音存在概率、所述上一帧信号的噪声功率谱以及所述当前帧信号的误差信号功率谱,计算得到所述当前帧信号的噪声功率谱。
可选的,所述当前帧信号的语音不存在概率基于如下步骤确定:根据所述当前帧信号的频域幅度谱以及所述当前帧信号的误差信号功率谱的最小值计算得到第一判别后验信噪比;根据所述当前帧信号的误差信号功率谱以及所述当前帧信号的误差信号功率谱的最小值计算得到第二判别后验信噪比;根据所述第一判别后验信噪比以及所述第二判别后验信噪比确定所述当前帧信号的语音不存在概率。
可选的,所述根据所述第一判别后验信噪比以及所述第二判别后验信噪比确定所述当前帧信号的语音不存在概率包括:所述第一判别后验信噪比以及所述第二判别后验信噪比越小,所述语音不存在概率越大。
可选的,所述单通道语音增强方法还包括:对所述语音增强后的频谱进行频时变换操作以及重叠相加操作,以得到增强后的语音信号并输出。
为解决上述技术问题,本发明实施例还提供一种单通道语音增强装置,包括:延迟处理模块,用于对接收到的输入信号进行延迟处理,以得到延迟信号;预处理模块,用于基于所述延迟信号对当前帧信号中的噪声进行预处理,以得到误差信号,其中,所述当前帧信号获取自所述输入信号;语音增强模块,用于对所述误差信号进行噪声估计并计算幅度谱增益函数;计算模块,用于根据所述误差信号以及所述幅度谱增益函数计算得到语音增强后的频谱。
为解决上述技术问题,本发明实施例还提供一种存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时执行上述方法的步骤。
为解决上述技术问题,本发明实施例还提供一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行上述方法的步骤。
与现有技术相比,本发明实施例的技术方案具有以下有益效果:
本发明实施例提供一种单通道语音增强方法,包括:对接收到的输入信号进行延迟处理,以得到延迟信号;基于所述延迟信号对当前帧信号中的噪声进行预处理,以得到误差信号,其中,所述当前帧信号获取自所述输入信号;对所述误差信号进行噪声估计并计算幅度谱增益函数;根据所述误差信号以及所述幅度谱增益函数计算得到语音增强后的频谱。
较之现有应用于单通道语音设备的降噪方案,本实施方案能够在单通道语音通话场景中在较短时间内有效抑制噪声(尤其鸣笛类噪声)并维持较优的语音质量,利于提升单通道的语音通话设备、语音录制设备等音频设备的语音质量。具体而言,利用延迟的含噪语音数据对噪声进行预处理,以使当前帧信号中噪声的能量被初步衰减。然后对预处理后的含噪语音数据(即误差信号)进行语音增强处理。由此,通过在传统的语音增强处理之前先对当前帧信号中的噪声进行预处理,能够在有效消除鸣笛类噪声的同时保护原有语音质量,且噪声衰减时间短,整体响应快。
进一步,所述误差信号是对所述当前帧信号中的第一类噪声进行预测并抑制后得到的含噪语音信号,所述第一类噪声在前后两帧信号中的特性基本保持不变。例如,所述第一类噪声包括所述鸣笛类噪声。由于第一类噪声的特性随时间的变化不明显,因而这类噪声是可预测的。因此,本实施方案利用诸如鸣笛类噪声等的第一类噪声可预测的特点,对含噪语音信号中的噪声做预处理,使含噪语音信号经过预处理后其噪声能量得到快速衰减。进一步,对噪声成分初步衰减后的含噪语音信号(即误差信号)进行语音增强,以在降噪的同时保证良好的语音质量。
附图说明
图1是本发明实施例一种单通道语音增强方法的流程图;
图2是采用图1所示方法处理输入信号的算法流程图;
图3是图2中自适应滤波模块的原理示意图;
图4是图2中语音增强模块的原理示意图;
图5是本发明实施例一种单通道语音增强装置的结构示意图;
图6是采用本实施方案与现有其他方案对含有鸣笛噪声的语音信号进行噪声抑制后的处理结果在时域上的对比图。
具体实施方式
如背景技术所言,现有技术亟需一种能够适用于单通道语音设备的语音增强方案,能够在较短时间内消除鸣笛类噪声同时保护原有语音质量。
具体而言,人们在使用手机等移动设备进行日常通话时会遇到各种各样的噪声,其中有一些噪声例如交通工具的鸣笛声、工厂机器的轰鸣声等,因其响度大、持续时间长的特点给手机通话引入了非常糟糕的主观体验,影响通话质量。
传统的语音增强方法对这类噪声的抑制强度非常弱,且噪声衰减时间长。
为解决上述技术问题,本发明实施例提供一种单通道语音增强方法,包括:对接收到的输入信号进行延迟处理,以得到延迟信号;基于所述延迟信号对当前帧信号中的噪声进行预处理,以得到误差信号,其中,所述当前帧信号获取自所述输入信号;对所述误差信号进行噪声估计并计算幅度谱增益函数;根据所述误差信号以及所述幅度谱增益函数计算得到语音增强后的频谱。
本实施方案能够在单通道语音通话场景中在较短时间内有效抑制噪声(尤其鸣笛类噪声)并维持较优的语音质量,利于提升单通道的语音通话设备、语音录制设备等音频设备的语音质量。具体而言,利用延迟的含噪语音数据对噪声进行预处理,以使当前帧信号中噪声的能量被初步衰减。然后对预处理后的含噪语音数据(即误差信号)进行语音增强处理。由此,能够在有效消除鸣笛类噪声的同时保护原有语音质量,且噪声衰减时间短,整体响应快。
具体而言,利用鸣笛类噪声可预测的特点,能够在短时间内消除鸣笛类噪声,同时保证通话时的语音质量,达到提升语音通话主观感受的目的。
为使本发明的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
图1是本发明实施例一种单通道语音增强方法的流程图。
本实施例方案可以由具有语音通话功能的智能设备执行,如由手机、电话手表等移动设备执行。进一步,执行本实施方案的智能设备可以为单通道语音设备,即仅配置有一个麦克风的智能设备。
具体地,参考图1,本实施例所述单通道语音增强方法可以包括如下步骤:
步骤s101,对接收到的输入信号进行延迟处理,以得到延迟信号;
步骤s102,基于所述延迟信号对当前帧信号中的噪声进行预处理,以得到误差信号,其中,所述当前帧信号获取自所述输入信号;
步骤s103,对所述误差信号进行噪声估计并计算幅度谱增益函数;
步骤s104,根据所述误差信号以及所述幅度谱增益函数计算得到语音增强后的频谱。
在一个具体实施中,所述输入信号可以是采用单个麦克风采集得到的含噪语音信号。例如,所述麦克风可以为集成于智能设备的语音采集模块。
具体而言,所述输入信号可以是含有第一类噪声的语音信号,具体可以表示为x(n)=s(n)+n(n),其中,x(n)为所述输入信号,s(n)为纯净语音信号,n(n)为噪声信号,括号中的n为样点数(也可称为离散点数)。
在一个具体实施中,在所述步骤s101之前,可以先对所述输入信号x(n)进行时域上的分帧操作,分帧得到的每一帧信号可以表示为xk(n),其中k为帧数。
进一步,每一帧信号可以包括n个采样点,n≥1。
例如,参考图1和图2,信号分析模块202可以对输入信号201进行时域上的分帧操作。进一步,分帧操作时每一帧可以有部分重叠,如前后两帧存在50%、25%的重叠。
进一步,所述信号分析模块202还可以对分帧后的每一帧信号执行加窗操作,以有效防止频谱泄露。将信号分析模块202输出的每一帧信号记作当前帧信号203。
在一个具体实施中,信号分析模块202输出的当前帧信号203可以是经过快速傅里叶变换(fastfouriertransform,简称fft)的结果,以在频域上实现对当前帧信号203中噪声的预处理。
在一个具体实施中,继续参考图1和图2,所述步骤s101和步骤s102可以由自适应滤波模块204执行。
具体而言,信号分析模块202输出的当前帧信号203可以作为自适应滤波模块204中自适应滤波器2044的参考信号dk(n),即dk(n)=xk(n)。进一步,经过频域上的自适应滤波处理后得到误差信号205。
在一个具体实施中,所述自适应滤波模块204可以包括延迟处理模块2041,用于对所述当前帧信号203进行预设数量的采样点的延迟,以得到延迟信号2042。具体可以表示为uk(n)=xk(n-d),其中,d为延迟的采样点数(即所述预设数量),uk(n)为延迟信号。也即,将所述当前帧信号203中的采样点依次右移预设数量得到的序列确定为所述延迟信号。所述预设数量d的大小应保证自适应滤波器2044能够收敛并对第一类噪声信号进行准确的估计。优选地,预设数量d与采样率fs的关系应满足0.001fs≤d≤0.01fs。
在一个具体实施中,所述自适应滤波模块204可以包括预处理模块2043,用于执行步骤s102以得到误差信号205。
具体而言,所述误差信号205是对所述当前帧信号203中的第一类噪声进行预测并抑制后得到的含噪语音信号,所述第一类噪声在前后两帧信号中的特性基本保持不变。
进一步,所述第一类噪声可以包括鸣笛类噪声,还可以包括其他满足如下特性的噪声:噪声的持续时间长,且在持续时间内噪声的频谱特征如谐波的数量、谐波的能量等保持相对稳定不变。
这些特性使得第一类噪声是可预测的。相应的,在本实施例中,利用第一类噪声可预测的特性,利用延迟信号构建时间差,使得预处理模块2043能够在当前帧对自己的第一类噪声做预测,然后和自己做减法得到误差信号205,从而在当前帧信号203实现对第一类噪声的初步抑制。
本申请发明人经过分析发现,智能设备在通话过程中,接收到的输入信号通常包含两类噪声:第一类噪声以及环境噪声,所述第一类噪声的响度明显大于环境噪声。而现有单通道语音设备的语音增强方案是直接对输入信号进行语音增强处理,其具体实现时虽然会对输入信号进行噪声估计,但仅对环境噪声比较有效,对第一类噪声的估计和抑制效果非常差且噪声衰减时间长。针对此问题,本实施方案在语音增强模块206之前,增设自适应滤波模块204,以对输入信号中的第一类噪声进行预处理,再结合后续语音增强模块206的处理,就能够同时实现对第一类噪声和环境噪声的有效消除,同时保持良好的语音质量。
在一个具体实施中,所述预处理模块2043可以包括自适应滤波器2044。
例如,所述自适应滤波器2044可以为使用归一化最小均方算法的自适应滤波器(normalizedleastmeansquare,简称nlms)
具体地,所述自适应滤波器2044的输入为所述延迟信号2042。
进一步,在所述步骤s102中,可以将所述延迟信号2042输入自适应滤波器2044,以预估得到所述延迟信号2042中的预估噪声信号2045。其中,所述预估噪声信号2045是基于延迟信号2042对当前帧信号203中第一类噪声的预测结果。
例如,可以将所述延迟信号2042与所述自适应滤波器2044的滤波器系数hk(n)进行卷积运算,并将卷积运算结果确定为所述预估噪声信号2045。
所述自适应滤波器2044的阶数m小于当前帧信号203包括的采样点的数量n,hk(n)的系数为m个。
进一步,所述预处理模块2043可以包括计算单元2046,用于根据所述当前帧信号203和所述预估噪声信号2045计算得到所述误差信号205。
例如,所述计算单元2046可以为加法器,作为参考信号dk(n)的当前帧信号203的符号为正(“+”),所述自适应滤波器2044输出的预估噪声信号2045符号为负(“-”),所述计算单元2046加和前述两个物理量即可获得所述误差信号205。具体可以表示为ek(n)=dk(n)-yk(n),其中,ek(n)为所述误差信号205,yk(n)为所述预估噪声信号2045。
在一个具体实施中,在得到所述误差信号205后,还可以根据所述误差信号205更新所述自适应滤波器2044的滤波器系数。
以使用nlms的频域算法为例,可以基于梯度下降法使用误差信号205对所述自适应滤波器2044的滤波器系数hk+1进行反馈更新。更新得到的用于处理第k+1帧信号的滤波器系数hk+1可以如公式(1)所示:
hk+1=hk+μδhk
其中,hk+1为自适应滤波器2044的滤波器系数hk+1(n)的频域表示;hk为自适应滤波器2044的滤波器系数hk(n)的频域表示;fft表示正向离散傅里叶变换;ifft表示逆向离散傅里叶变换;μ为系数更新的步长,且0<μ<2;rm为含有m个上对角元素为1,其余元素为0的约束矩阵;uk为延迟信号uk(n)的加窗离散傅里叶变换;ek为误差信号ek(n)的加窗离散傅里叶变换;上标*表示共轭操作,即:
uk=fft[w(1)uk(1),w(2)uk(2),...,w(n)uk(n)];
ek=fft[w(1)ek(1),w(2)ek(2),...,w(n)ek(n)];
其中,w(n)=[w(1),w(2),...,w(n)]为窗函数,可选择海明窗(hamming)、汉宁窗(hanning)、布莱克曼窗(blackman)、tukey窗等窗函数中的任意一种;e(|uk|2)表示延迟信号uk(n)的平均能量,“||”表示取复数的模,e(|uk|2)可由公式e(|uk+1|2)=ηe(|uk|2)+(1-η)|uk|2计算得到,η为平滑参数,且0<η<1。
进一步,所述系数更新的步长μ的具体数值可以在本实施方案运行期间根据残差信号ek与滤波器系数更新量δhk之间的关系进行自动调节,从而使自适应滤波器具有较快的收敛速度和较小的稳态误差。
在一个变化例中,所述自适应滤波器2044可以是在时域上实现对当前帧信号203中第一类噪声的估计的。相应的,可以在得到误差信号205后,再对误差信号进行fft操作,以在后续在频域上对误差信号205进行语音增强处理。
在本实施例中,通过执行步骤s101和步骤s102,利用自适应滤波器2044对当前帧信号203中的噪声(尤其第一类噪声)进行预处理,即对含有鸣笛类噪声的含噪语音信号做若干个采样点的延迟,以延迟信号作为自适应滤波器2044的输入信号进行自适应滤波处理得到自适应滤波器2044的输出信号。所述自适应滤波器2044的输出信号即为对当前帧信号203中第一类噪声的预测结果,即预估噪声信号2045。以原始含噪语音信号(即当前帧信号203)作为自适应滤波器2044的参考信号减去自适应滤波器2044的输出信号得到误差信号205,也即,从当前帧信号203中减去预估噪声信号2045,使得当前帧信号203中的噪声得到能量上的初步衰减。由此,能够消除当前帧信号203中绝大部分的第一类噪声。
也就是说,预处理模块2043输出的误差信号205即为对当前帧信号203中的第一类噪声进行预测并抑制后得到的含噪语音信号。
对误差信号205(即ek(n))的加窗离散傅里叶变换ek可以重新表示为ek=|ek|∠ek,其中,|ek|为幅度谱,∠ek为相位谱,∠为辅角(arg)。也即,fft变换得到的误差信号205的频谱包括幅度和相位两个维度,其中相位在增强前后基本不变,因此,步骤s103主要针对幅度谱|ek|进行处理。
在步骤s104中,误差信号205的相位∠ek可近似作为增强后语音信号211的相位直接与经过步骤s103增强得到的幅度谱相合成。
进一步,参考图1,将误差信号205的幅度谱输入到语音增强模块206做噪声估计以及幅度谱增益计算,以进一步对误差信号205中包含的噪声(如残留的第一类噪声以及环境噪声)进行噪声估计,从而实现对鸣笛类噪声及环境噪声的抑制,最终得到语音增强后的信号。
所述语音增强模块206所使用的语音增强方法可以为谱减法,最小值跟踪法等算法估计噪声功率谱,接下来结合图4以基于语音存在概率的噪声功率谱估计算法为例进行详细阐述。
在一个具体实施中,所述步骤s103可以由语音增强模块206执行,所述语音增强模块206可以包括噪声估计单元2061和幅度谱增益单元2063。
所述步骤s103可以包括:步骤a1,获取所述误差信号205的频域幅度谱|ek|;步骤a2,对所述误差信号205的频域幅度谱|ek|进行噪声估计,以得到所述误差信号205的噪声功率谱2062;步骤a3,根据所述噪声功率谱2062计算得到所述误差信号205的幅度谱增益函数207。
所述噪声估计单元2061可以用于执行所述步骤a2,所述幅度谱增益单元2063可以用于执行所述步骤a3。
在一个具体实施中,所述步骤a2可以包括步骤:根据上一帧信号的误差信号功率谱以及所述当前帧信号203的频率幅度谱,计算得到所述当前帧信号203的误差信号功率谱。
具体地,噪声估计单元2061可以对当前帧k的输入信号(即所述误差信号205的频域幅度谱|ek|)进行功率谱平滑处理,使得前后两帧信号平滑过滤,以考虑上一帧信号对当前帧信号203的影响。
例如,可以基于公式(2)进行功率谱平滑处理:
sk=αssk-1+(1-αs)|ek|2(2)
其中,sk为所述当前帧输入的误差信号功率谱;αs为取值于[0,1]之间的平滑参数;sk-1为所述上一帧信号的误差信号功率谱。
进一步,所述步骤a2还可以包括步骤:根据所述上一帧信号的误差信号功率谱的最小值、所述当前帧信号203的误差信号功率谱以及预设噪声估计参数,计算得到所述当前帧信号203的误差信号功率谱的最小值。
所述当前帧信号203的误差信号功率谱的最小值是指当前帧信号中最安静时刻的功率。
具体地,噪声估计单元2061可以利用对平滑后的功率谱历史值跟踪得到当前帧信号203的误差信号功率谱的最小值。
例如,可以基于公式(3)计算得到所述当前帧信号203的误差信号功率谱的最小值:
其中,smin,k为所述当前帧信号203的误差信号功率谱的最小值;smin,k-1为所述上一帧信号的误差信号功率谱的最小值;α1、α2和α3为取值于[0,1]之间的预设噪声估计参数。
进一步,预设噪声估计参数的具体数值可以根据实验确定,根据最终降噪效果调整。
进一步,当前帧输入的误差信号功率谱sk与当前帧信号的误差信号功率谱的最小值smin,k在第0帧的初始值为误差信号的频域幅度谱的平方,即|e0|2。
进一步,所述步骤a2还可以包括步骤:根据所述当前帧信号203的误差信号功率谱以及所述上一帧信号的噪声功率谱,估算所述当前帧信号203的初始后验信噪比;根据所述上一帧信号的幅度谱增益函数、所述上一帧信号的优选后验信噪比以及当前帧信号203的初始后验信噪比,估算所述当前帧信号203的初始先验信噪比。
具体地,噪声估计单元2061可以基于公式(4)估计所述当前帧信号203的初始后验信噪比:
其中,
进一步,先验信噪比可以根据后验信噪比计算得到。
例如,噪声估计单元2061可以基于公式(5)计算得到所述初始先验信噪比:
其中,
换言之,所述初始后验信噪比用于表征当前帧信号203的误差信号功率谱与上一帧信号的噪声信号功率谱之比。因为此阶段尚不知当前帧信号的噪声信号功率谱,因此先基于上一帧信号的噪声信号功率谱进行估计。
所述初始先验信噪比用于表征纯净信号功率谱与噪声信号功率谱的比值。
进一步,所述步骤a2还可以包括步骤:根据所述初始后验信噪比、初始先验信噪比以及所述当前帧信号203的语音不存在概率,计算得到所述当前帧信号203的语音存在概率。
具体地,所述当前帧信号203的语音不存在概率可以基于如下步骤确定:根据所述当前帧信号203的频域幅度谱|ek|以及所述当前帧信号203的误差信号功率谱的最小值计算得到第一判别后验信噪比;根据所述当前帧信号203的误差信号功率谱以及所述当前帧信号203的误差信号功率谱的最小值计算得到第二判别后验信噪比;根据所述第一判别后验信噪比以及所述第二判别后验信噪比确定所述当前帧信号203的语音不存在概率。
例如,噪声估计单元2061可以基于公式(6)计算得到所述第一判别后验信噪比:
其中,γmin,k为所述第一判别后验信噪比;b为用于噪声估计的预设偏置补偿参数。
换言之,所述第一判别后验信噪比可以是由当前帧信号203的误差信号功率谱的最小值计算得到的后验信噪比。
又例如,所述噪声估计单元2061可以基于公式(7)计算得到所述第二判别后验信噪比:
其中,ηk为所述第二判别后验信噪比。
换言之,所述第二判别后验信噪比是考虑上一帧信号得到的后验信噪比。
进一步,所述第一判别后验信噪比以及所述第二判别后验信噪比越小,所述语音不存在概率越大。
例如,当第一判别后验信噪比以及所述第二判别后验信噪比满足γmin,k≤1,且ηk<η0时,确定所述语音不存在概率qk=1。即当前帧信号203没有语音。
又例如,当第一判别后验信噪比以及所述第二判别后验信噪满足1<γmin,k≤γ1,且ηk<η0时,根据公式(8)计算得到所述语音不存在概率:
再例如,当第一判别后验信噪比以及所述第二判别后验信噪满足γmin,k≥γ1,且ηk≥η0时,确定所述语音不存在概率qk=0。即当前帧信号203没有噪声。
前述γ1和η0均为预设常数。
进一步,可以基于贝叶斯统计概率计算得到所述语音存在概率。
例如,噪声估计单元2061可以基于公式(9)计算得到所述语音存在概率:
其中,pk为所述当前帧信号203的语音存在概率;
进一步,所述步骤a2还可以包括步骤:根据所述当前帧信号203的语音存在概率、所述上一帧信号的噪声功率谱以及所述当前帧信号203的误差信号功率谱,计算得到所述当前帧信号203的噪声功率谱2062。
具体地,噪声估计单元2061可以基于公式(10)计算得到所述当前帧信号203的噪声功率谱2062:
其中,
本实施例方案采用软判决逻辑,通过计算当前帧信号203的语音不存在概率和语音存在概率,使得对当前帧信号203的语音活动检测结果更为准确且符合实际场景,能够保留更多的语音细节。例如,对于低信噪比的误差信号,本实施例采用的概率判断明显比传统vad非1即0的判断方式更为合适,利于确保语音数据的完整性,避免包含语音数据的信号帧因被误识别为纯噪声帧而造成语音数据丢失。
需要指出的是,步骤s103中的当前帧信号203指的是经过自适应滤波模块204预处理得到的误差信号205。
通过执行所述步骤a2,所述噪声估计单元2061输出所述当前帧信号203的噪声功率谱2062至所述幅度谱增益单元2063。
进一步,所述幅度谱增益单元2063可以根据所述当前帧信号203的误差信号功率谱以及所述当前帧信号203的噪声功率谱2062计算得到所述当前帧信号的优选后验信噪比。如公式(11)所示:
其中,γk为所述当前帧信号203的优选后验信噪比。
进一步,所述幅度谱增益单元2063根据所述优选后验信噪比计算得到所述当前帧信号203的优选先验信噪比,如公式(12)所示:
ξk=εgk-1γk-1+(1-ε)max(γk-1,0)(12)
其中,ξk为所述当前帧信号203的优选先验信噪比。
与前述初始后验信噪比和初始先验信噪比相比,优选后验信噪比和优选先验信噪比是基于当前帧信号203的噪声功率谱2062计算得到的,能够更准确的体现当前帧信号203的噪声分布。
进一步,所述幅度谱增益单元2063基于公式(13)计算得到所述当前帧信号203的幅度谱增益函数207:
其中,gk为所述当前帧信号203的幅度谱增益函数207。
在一个具体实施中,所述步骤s104可以由图2中的计算模块208执行。
具体地,所述计算单元208可以为乘法器,用于将所述当前帧信号203的幅度谱增益函数207与误差信号205在频域上相乘,以得到语音增强后的频谱209。
在一个具体实施中,在所述步骤s104之后,本实施例所述单通道语音增强方法还可以包括步骤:对所述语音增强后的频谱209进行频时变换操作以及重叠相加操作,以得到增强后的语音信号211并输出。
具体地,本步骤可以由图2中的信号合成模块210执行,所述信号合成模块210对语音增强后的频谱209进行ifft变换到时域,在时域内完成信号合成得到完整的增强后的语音信号211。
例如,所述信号合成可以包括将之前分帧的各个帧信号合并起来。
又例如,所述信号合成还可以包括将相位谱和幅度谱合并起来。
由上,采用本实施方案,能够在单通道语音通话场景中在较短时间内有效抑制噪声(尤其鸣笛类噪声)并维持较优的语音质量,利于提升单通道的语音通话设备、语音录制设备等音频设备的语音质量。具体而言,利用延迟的含噪语音数据对噪声进行预处理,以使当前帧信号中噪声的能量被初步衰减。然后对预处理后的含噪语音数据(即误差信号)进行语音增强处理。由此,通过在传统的语音增强处理之前先对当前帧信号中的噪声进行预处理,能够在有效消除鸣笛类噪声的同时保护原有语音质量,且噪声衰减时间短,整体响应快。
具体而言,利用鸣笛类噪声的特点首先对噪声进行预处理,即利用延迟的含噪数据经过自适应滤波器对噪声进行预测,得到噪声能量衰减的误差信号;再对自适应滤波器的误差信号进行语音增强达到对鸣笛类噪声进行消除的同时保护原有语音质量的目的。
进一步,该算法对低信噪比输入含噪信号同样有效,因此可同样应用于手持及免提通话。
图5是本发明实施例一种单通道语音增强装置的结构示意图。本领域技术人员理解,本实施例所述单通道语音增强装置5可以用于实施上述图1至图4所述实施例中所述的方法技术方案。
具体地,参考图5,本实施例所述单通道语音增强装置5可以包括:延迟处理模块51,用于对接收到的输入信号进行延迟处理,以得到延迟信号;预处理模块52,用于基于所述延迟信号对当前帧信号中的噪声进行预处理,以得到误差信号,其中,所述当前帧信号获取自所述输入信号;语音增强模块53,用于对所述误差信号进行噪声估计并计算幅度谱增益函数;计算模块54,用于根据所述误差信号以及所述幅度谱增益函数计算得到语音增强后的频谱。
关于所述单通道语音增强装置5的工作原理、工作方式的更多内容,可以参照上述图1至图4中的相关描述,这里不再赘述。
在一个典型的应用场景中,图6是采用本实施方案与现有其他方案对含有鸣笛噪声的语音信号进行噪声抑制后的处理结果在时域上的对比图。
图6中第一行为原始的含噪语音信号,第二行为现有其他方案的处理结果,第三行为本实施例方案的处理结果。
由对比框x1和x2可以看出,本方案较其他方案能够在更短的时间内对鸣笛噪声进行抑制,并且对其他背景噪声(即环境噪声)也有较好的抑制效果,同时语音信号得到了很好的保护。
进一步地,本发明实施例还公开一种存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时执行上述图1至图4所示实施例中所述的方法技术方案。优选地,所述存储介质可以包括诸如非挥发性(non-volatile)存储器或者非瞬态(non-transitory)存储器等计算机可读存储介质。所述存储介质可以包括rom、ram、磁盘或光盘等。
进一步地,本发明实施例还公开一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行上述图1至图4所示实施例中所述的方法技术方案。具体地,所述终端可以为手机等集成或外部耦接有语音采集模块的移动终端。
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



