
 商标分类
商标分类  商标转让
商标转让 
一种多模式语音识别送话装置及其控制方法与流程
 2021-01-28 13:01:45|
2021-01-28 13:01:45| 260|
260| 起点商标网
起点商标网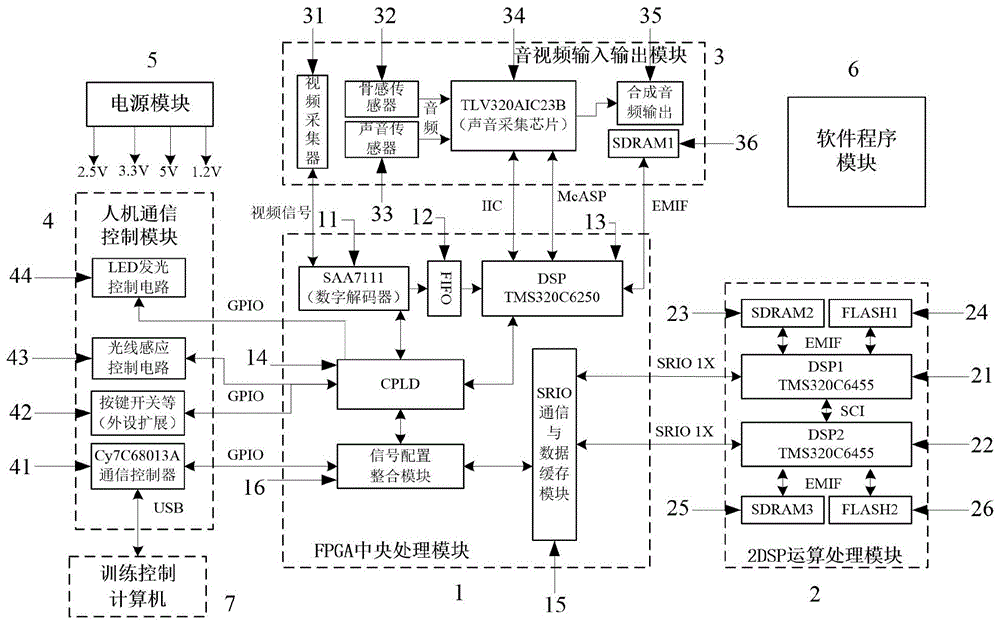
本发明涉及多模式语音识别及送话领域,具体是一种多模式语音识别送话装置及其控制方法。
背景技术:
在语音识别领域,以往情况下大部分都是采用直接语音处理或喉头送话或唇读技术来实现,因为常规耳机以及进行降噪增强处理后,和基于骨导技术的骨传导耳机,就可以满足一般噪声干扰下很多场合下的语音通讯交流需要。随着通用飞机和发动机的不断应用,当进行试飞及试车时,航空发动机将是现场噪音的主要来源,特别大型航空发动机,其噪声频率范围宽,且分贝高,严重影响了现场工作人员正常工作交流。目前,所使用的降噪耳机,降低噪声后大幅度降低了噪声对工作人员的干扰,但仍无法满足作业人员互相交流的需求,只能通过手势或其它方式进行沟通,不能及时表达和传递更多信息。
在飞机或航空发动机检查过程中,操作人员需要进行有效的信息交流,按传统语音通讯交流方法和装置,仅仅通过降噪耳机和手势或旗语等方式难以满足使用要求,因此,必须采用新技术新方法,提高语音识别与送话的有效性和科学性,促进飞机或航空发动机检查高效安全实施。
如中国发明专利申请号为201910032244.0中公开了一种智能头戴式耳机及耳机系统,该系统可以能够根据语音指令实现对应的功能操作,无需手动按键,操作便捷,能够提升用户的体验,系统包括麦克风、语音处理模块、中央处理模块、音频处理模块和喇叭。缺点是该系统只是用于语音指令控制,没有涉及大噪音下多模式语音识别与有效通讯。
如中国发明专利申请号为201910012835.1中公开了一种混合结构主动降噪耳机、降噪方法及存储介质,能够选择出最适合的降噪系统系数,更加快速准确地追踪噪声信号的变化,从而大幅度提升降噪效果。混合结构主动降噪耳机包括:有源噪声控制系统、参考传声器以及消声传声器。缺点是该系统只是进行循环迭代处理选择降噪系统系数,没有涉及大噪音下多模式语音识别与有效通讯。
如中国发明专利申请号为201810422275.2中公开了一种基于级联特征提取的唇部检测及读取方法,能够提升唇读的速度和准确性,该方法包括唇部区域检测、唇区提取、维度提取和唇区的读取等。缺点是该方法只是通过对唇区图像特征的多级提取和降维,没有涉及大噪音下多模式语音识别与有效通讯。
如中国发明专利号为201611086527.6中公开了一种喉头送话器音频增强处理模块,该设备包含包括去呼吸声信号处理板、供电电源和音频输出开关。缺点是该模块改善了喉头送话器的清晰度和识别度,没有涉及大噪音下多模式语音识别与有效通讯。
2019年2月出版的《信号处理》第2期第293-299页公开了提出了基于bilstm/ctc模型的陆空通话语音识别方法,主要是针对民航陆空通话语言特点,通过,训练bilstm网络得到bilstm/ctc模型,利用声学模型,语言模型与陆空通话词典实现民航陆空通话的语音识别。缺点是该系统只是实现了应用增强的声学模型使陆空通话语音识别在词识别错误方面降低到5.53%,没有涉及大噪音下多模式语音识别与有效通讯。
2019年3月出版的《高技术通讯》第3期第287-294页公开了一种基于人机交互(hci)设计了表情和语音交互的脑瘫康复训练系统,综合采用上位机和下位机相结合的方式,下位机采用51单片机进行主体驱动,语音采集模块应用ld3320语音芯片,并通过串口通讯的方式,将c语言编程的下位机与labview编写的上位机相连接,实现语音语义规则进行辨识匹配,对测试完成评判和统计。缺点是该系统只是设计了表情和语音交互人机交互,没有涉及大噪音下多模式语音识别与有效通讯。
因此,针对语音识别设计研究,主要是在头戴式耳机及耳机系统、唇部检测及读取方法、喉头送话器和相关提升语音识别质量方面的研究,为脑瘫康复训练系统、民航陆空通话、语音指令控制等功能,但是就大噪音下多模式语音识别与有效送话方法和装置研究较少。有必要开展大噪音下多模式语音识别送话装置及其控制方法的研究。
技术实现要素:
为了解决上述问题,本发明提出一种多模式语音识别送话装置及其控制方法。
一种多模式语音识别送话装置,包括通过供电实现装置工作电压转换类功能的电源模块,还包括:
fpga中央处理模块,与电源模块连接,用于实现中央处理;
2dsp运算处理模块,与fpga中央处理模块和电源模块连接,用于实现对视频数字信号的唇部分割、特征提取、唇话识别及融合识别类运算处理功能;
音视频输入输出模块,与fpga中央处理模块和电源模块相连接,将处理融合完成的音频信号通过合成音频输出电路输出;
人机通信控制模块,与fpga中央处理模块和电源模块连接,用于完成电源开关、模式选择、工作状态显示、光线感应和led发光控制;
软件程序模块,与fpga中央处理模块连接,完成音频和视频的融合识别与决策输出。
所述的fpga中央处理模块包括用于实现对视频信号的数字化处理的saa7111数字解码器、与saa7111数字解码器和音视频输入输出模块相连接,完成前级数据的输入缓存和后级数据输出缓存的fifo单元、通过虚拟的dsp对外主要与音视频输入输出模块相连接用于提供fpga中央处理模块的外部音频信号的输入输出功能的dsp单元、通过gpio及人机通信控制模块相连接实现内部功能模块之间的信号控制的cpld单元、作为fpga中央处理模块的通信与数据缓存部分,用于提供fpga中央处理模块的高速数据处理功能的srio通信与数据缓存模块、作为fpga中央处理模块的对外接口连接电路之一,用于实现信号的配置与整合的信号配置整合模块。
所述的2dsp运算处理模块包括分别通过srio1x接口与fpga中央处理模块相连接的dsp1单元和dsp2单元。
所述的2dsp运算处理模块采用满足装置的实时性和识别率要求且优化图像信息处理能力和系统的可扩展性,实现送话装置的语音识别、唇话识别和融合决策的两片tms320c6455处理器。
所述的音视频输入输出模块包括通过视频信号线与fpga中央处理模块中的saa7111数字解码器相连,用于提供用于唇话识别的原始视频信号源的视频采集器、与fpga中央处理模块中的dsp单元通过iic和mcasp接口相连接收音频信号,实现芯片控制和数据传输,同时将处理融合完成的音频信号通过合成音频输出电路输出的tlv320aic23b声音采集芯片、通过音频信号线向tlv320aic23b声音采集芯片提供常规音频和骨传导音频信号的骨感传感器和声音传感器、为dsp单元提供扩展外部数据存储空间的sdram1单元。
所述的人机通信控制模块包括通过gpio与fpga中央处理模块中的信号配置整合模块相连,提供usb通讯功能,与外部的训练控制计算机进行通讯,完成训练后的数据下载及接收状态回复的cy7c68013a通信控制器、通过gpio与fpga中央处理模块中的cpld单元相连接,分别完成电源开关、模式选择、工作状态显示、光线感应和led发光控制的按键开关类、光线感应控制电路及led发光控制电路。
所述的按键开关类包括电源开关、控制按键、光亮旋钮、液晶显示屏、鼠标、数字键盘。
所述的软件程序模块包括用于实现识别算法的训练与数据下载上传的上位机训练控制软件模块、与上位机训练控制软件模块交互用于完成初始化、自检测和故障状态存储与提示、数据更新和usb通讯的嵌入式系统主流程模块、用于完成音频和视频的融合识别与决策输出的嵌入式系统算法模块。
所述的嵌入式系统算法模块的音频识别由音频采集、预处理、矢量量化、语音合成和语音识别组成,视频识别由视频采集、预处理、唇部分割、唇部特征提取和视觉识别组成。
一种多模式语音识别送话装置的控制方法,其具体步骤如下:
步骤8.1:初始化及自检测:初始化多模式语音识别送话装置及控制程序,并且进行装置硬件自检测,获取装置各模块工作状态,完成后执行下一步步骤8.2;
步骤8.2:判断装置是否正常:根据装置的自检测模块,从各模块返回的数据,综合对比后给出是否正常,当“故障”时进行故障提示,并且跳转至是否退出步骤8.11,当“正常”时,执行下一步步骤8.3;
步骤8.3:判断装置是否更新:当装置通过usb连接训练控制计算机时,可以进行数据更新,更新内容主要为识别算法和系统优化,当需要“更新”时,执行更新程序,否则,执行下一步步骤8.4;
步骤8.4:判断是否为自动设置方式:系统通过“手动/自动”按键设置“自动”和“手动”两种设置方式,默认为“自动”,直接转入下一步步骤8.5;当为“手动”方式,将手动选择工作模式,跳转至设置工作模块,进行工作模式设置;
步骤8.5:环境步骤噪音及光亮:采集处理:根据装置采集到的噪音及光亮情况,自动设置工作模式,当噪音小于参考阀值1时,选择模式“1”;当噪音大于等于参考阀值1,而小于参考阀值2时,选择模式“2”或“3”,当噪音大于等参考阀值2时,选择模式“4”或“5”;光亮只有当工作在模式“3”、“4”、“5”时有效,当光亮小于参考光亮阀值时,将打开led发光器,否则,关闭led发光器,处理完成后,执行下一步步骤8.6;
步骤8.6:设置工作模式:自动工作模式设置由环境步骤噪音及光亮:采集处理来选择,手动工作模式设置主要通过人机通信控制模块的工作模式选择按键来选择,系统初始工作模式状态为“1”,工作后将以上次工作模式为初始状态;每按压一次按键,工作模式将依次循环改变,按压等待3秒后,自动完成工作模式设置后,执行下一步步骤8.7,另外,还可以通过led开关按键设置led发光器的工作状态;
步骤8.7:判断是否为模式“x”步骤x值取1至5:当为“1”时,将执行常规音频送话语音模式;当为“2”时,将执行常规组合喉头送话语音模式;当为“3”时,将执行常规组合唇读送话语音模式;当为“4”时,将执行喉头组合唇读送话语音模式;当为“5”时,将执行三者组合送话语音模式;根据模式选择,分别执行不同的送话语音模式步骤8.8;
步骤8.8:执行送话语音模式:根据当前工作模式,执行相应的送话语音模式,具体为:
一、常规音频送话语音模式,仅仅声音传感器有效工作,骨感传感器和视频采集不参加语音识别;
二、常规组合喉头送话语音模式,主要是声音传感器和骨感传感器有效工作,视频采集不参加语音识别;
三、常规组合唇读送话语音模式,主要是声音传感器和视频采集有效工作,骨感传感器不参加语音识别;
四、喉头组合唇读送话语音模式,主要是骨感传感器和视频采集有效工作,声音传感器不参加语音识别;
五、三者组合送话语音模式,主要是声音传感器、骨感传感器和视频采集三者同时有效工作,进行综合融合识别,然后,执行下一步步骤8.9;
步骤8.9:语音信息输出:输出融合后的语音信息后,执行下一步步骤8.10;
步骤8.10:判断是否中断:检查外部是否有中断,当没有中断时,将跳转至判断是否为模式“x”步骤8.7,否则,执行下一步步骤8.11;
步骤8.11:判断是否退出:检查有无退出信号,当没有退出信号时,将跳转至判断装置是否正常步骤8.3,否则,执行下一步步骤8.12;
步骤8.12:退出:退出程序,结束控制程序。
本发明的有益效果是:本发明实现多模式语音识别的送话,模式选择、常规音频及喉头送话、唇话识别及融合送话能力,用于飞机或航空发动机检查时大噪音条件下,操作人员能够通过多模式切换与组合进行语音送话,以达到较好地保障通讯信息容量和通话质量的有效性和科学性,尤其是音视频信号的语音识别和唇话识别及融合,通过嵌入式软件开发设计,提高了语音送话的实时性、准确性和实用性。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1为本发明的结构示意图;
图2为本发明的软件程序模块结构示意图;
图3为本发明的控制方法流程结构示意图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面对本发明进一步阐述。
如图1至图3所示,一种多模式语音识别送话装置,包括通过供电实现装置工作电压转换类功能的电源模块,还包括:
fpga中央处理模块,与电源模块连接,用于实现中央处理;
2dsp运算处理模块,与fpga中央处理模块和电源模块连接,用于实现对视频数字信号的唇部分割、特征提取、唇话识别及融合识别类运算处理功能;
音视频输入输出模块,与fpga中央处理模块和电源模块相连接,将处理融合完成的音频信号通过合成音频输出电路输出;
人机通信控制模块,与fpga中央处理模块和电源模块连接,用于完成电源开关、模式选择、工作状态显示、光线感应和led发光控制;
软件程序模块,与fpga中央处理模块连接,完成音频和视频的融合识别与决策输出。
本发明实现多模式语音识别的送话,模式选择、常规音频及喉头送话、唇话识别及融合送话能力,用于飞机或航空发动机检查时大噪音条件下,操作人员能够通过多模式切换与组合进行语音送话,以达到较好地保障通讯信息容量和通话质量的有效性和科学性,尤其是音视频信号的语音识别和唇话识别及融合,通过嵌入式软件开发设计,提高了语音送话的实时性、准确性和实用性。
所述的fpga中央处理模块包括用于实现对视频信号的数字化处理的saa7111数字解码器、与saa7111数字解码器和音视频输入输出模块相连接,完成前级数据的输入缓存和后级数据输出缓存的fifo单元、通过虚拟的dsp对外主要与音视频输入输出模块相连接用于提供fpga中央处理模块的外部音频信号的输入输出功能的dsp单元、通过gpio及人机通信控制模块相连接实现内部功能模块之间的信号控制的cpld单元、作为fpga中央处理模块的通信与数据缓存部分,用于提供fpga中央处理模块的高速数据处理功能的srio通信与数据缓存模块、作为fpga中央处理模块的对外接口连接电路之一,用于实现信号的配置与整合的信号配置整合模块。
采用fpga中央处理模块,把高性能的fpga及srio通信与数据缓存功能结合起来,可生成saa7111数字解码器、fifo单元、dsp单元、cpld单元、srio通信与数据缓存模块和信号配置整合模块,实现送话装置的综合控制、音视频数据处理、高速数据传输和信号配置整合能力,有效发挥准fpga的灵活优势,提高电路的工作效率和可靠性;也简化装置的复杂性,使得电路简化降低硬件成本。
fpga中央处理模块分别与2dsp运算处理模块、音视频输入输出模块、人机通信控制模块、电源模块相连接,通过2路srio1x接口与2dsp运算处理模块进行交互控制,分别通过视频信号、iic和mcasp接口与音视频输入输出模块相连接,与人机通信控制模块主要通过gpio接口进行控制,工作所需的各种电源电压由电源模块提供。
所述的fifo单元作为数据缓存使用,主要与saa7111数字解码器和dsp单元相连接。
所述的saa7111数字解码器作为视频采集处理单元,分别与视频采集器、cpld单元、fifo单元相连接。
所述的2dsp运算处理模块包括分别通过srio1x接口与fpga中央处理模块相连接的dsp1单元和dsp2单元。
所述的dsp单元是虚拟的dsp对外主要与音视频输入输出模块相连接,通过iic接口实现对tlv320aic23b声音采集芯片控制;用mcasp接口实现数据接收,通过emif接口连接sdram1单元,实现音频数据的采集和处理,对内主要与fifo单元和cpld单元相连接,提供fpga中央处理模块的外部音频信号的输入输出功能。
所述的cpld单元作为fpga中央处理模块的对外接口连接电路之一,通过gpio及人机通信控制模块相连接,提供fpga中央处理模块的人机交互控制和光线感应及led发光控制功能,对内与saa7111数字解码器、dsp单元和信号配置整合模块相连接。
所述的2dsp运算处理模块采用满足装置的实时性和识别率要求且优化图像信息处理能力和系统的可扩展性,实现送话装置的语音识别、唇话识别和融合决策的两片tms320c6455处理器。
采用2dsp运算处理模块,实现送话装置的语音识别、唇话识别和融合决策能力,选用两片tms320c6455处理器,通过srio1x与fpga中央处理进行高速数据交互,可以进行并行处理,快速完成很大的计算量运算,满足装置的实时性和识别率要求的同时,也优化了图像信息处理能力和系统的可扩展性。
所述的srio通信与数据缓存模块作为fpga中央处理模块的通信与数据缓存部分,通过2路srio1x接口与2dsp运算处理模块进行交互控制,并且对内与信号配置整合模块相连接。
所述的信号配置整合模块作为fpga中央处理模块的对外接口连接电路之一,通过gpio及人机通信控制模块相连接,提供fpga中央处理模块的usb通讯功能
所述的音视频输入输出模块包括通过视频信号线与fpga中央处理模块中的saa7111数字解码器相连,用于提供用于唇话识别的原始视频信号源的视频采集器、与fpga中央处理模块中的dsp单元通过iic和mcasp接口相连接收音频信号,实现芯片控制和数据传输,同时将处理融合完成的音频信号通过合成音频输出电路输出的tlv320aic23b声音采集芯片、通过音频信号线向tlv320aic23b声音采集芯片提供常规音频和骨传导音频信号的骨感传感器和声音传感器、为dsp单元提供扩展外部数据存储空间的sdram1单元。
采用音视频输入输出模块,实现送话装置的音视频采集、声音信息预处理和合成音频输出能力,采用tlv320aic23b声音采集芯片,可对多路音频信号进行输入输出,带有可编程增益调节,满足送话装置高音频性能输入输出的同时,也满足了很低的能耗,提高装置工作的能效比。
所述的人机通信控制模块包括通过gpio与fpga中央处理模块中的信号配置整合模块相连,提供usb通讯功能,与外部的训练控制计算机进行通讯,完成训练后的数据下载及接收状态回复的cy7c68013a通信控制器、通过gpio与fpga中央处理模块中的cpld单元相连接,分别完成电源开关、模式选择、工作状态显示、光线感应和led发光控制的按键开关类、光线感应控制电路及led发光控制电路。
采用人机通信控制模块,实现送话装置的人机控制与上位机usb通讯能力,采用cy7c68013a通信器,基于内嵌入微处理器的接口,支持usb2.0协议,通过简单配一些寄存器和存储器,就可以完成对usb数据口的数据传输,简化了程序的设计外,提高传输速率,增加可靠性。
所述的按键开关类包括电源开关、控制按键、光亮旋钮、液晶显示屏、鼠标、数字键盘。
所述的软件程序模块包括用于实现识别算法的训练与数据下载上传的上位机训练控制软件模块、与上位机训练控制软件模块交互用于完成初始化、自检测和故障状态存储与提示、数据更新和usb通讯的嵌入式系统主流程模块、用于完成音频和视频的融合识别与决策输出的嵌入式系统算法模块。
采用软件程序模块,实现送话装置的软件功能控制和运算能力,采用嵌入式系统和pc机系统,嵌入式系统语音识别、融合决策等,pc系统完成码本训练和语音模板的训练,两者之间分工明确,满足识别率和识别时间的要求外,又使系统简化,降低了硬件成本。
所述的嵌入式系统算法模块的音频识别由音频采集、预处理、矢量量化、语音合成和语音识别组成,视频识别由视频采集、预处理、唇部分割、唇部特征提取和视觉识别组成。
所述的嵌入式系统算法模块是软件程序模块中的核心。
一种多模式语音识别送话装置的控制方法,其具体步骤如下:
步骤8.1:初始化及自检测:初始化多模式语音识别送话装置及控制程序,并且进行装置硬件自检测,获取装置各模块工作状态,完成后执行下一步步骤8.2;
步骤8.2:判断装置是否正常:根据装置的自检测模块,从各模块返回的数据,综合对比后给出是否正常,当“故障”时进行故障提示,并且跳转至是否退出步骤8.11,当“正常”时,执行下一步步骤8.3;
步骤8.3:判断装置是否更新:当装置通过usb连接训练控制计算机时,可以进行数据更新,更新内容主要为识别算法和系统优化,当需要“更新”时,执行更新程序,否则,执行下一步步骤8.4;
步骤8.4:判断是否为自动设置方式:系统通过“手动/自动”按键设置“自动”和“手动”两种设置方式,默认为“自动”,直接转入下一步步骤8.5;当为“手动”方式,将手动选择工作模式,跳转至设置工作模块,进行工作模式设置;
步骤8.5:环境步骤噪音及光亮:采集处理:根据装置采集到的噪音及光亮情况,自动设置工作模式,当噪音小于参考阀值1时,选择模式“1”;当噪音大于等于参考阀值1,而小于参考阀值2时,选择模式“2”或“3”,当噪音大于等参考阀值2时,选择模式“4”或“5”;光亮只有当工作在模式“3”、“4”、“5”时有效,当光亮小于参考光亮阀值时,将打开led发光器,否则,关闭led发光器,处理完成后,执行下一步步骤8.6;
步骤8.6:设置工作模式:自动工作模式设置由环境步骤噪音及光亮:采集处理来选择,手动工作模式设置主要通过人机通信控制模块的工作模式选择按键来选择,系统初始工作模式状态为“1”,工作后将以上次工作模式为初始状态;每按压一次按键,工作模式将依次循环改变,按压等待3秒后,自动完成工作模式设置后,执行下一步步骤8.7,另外,还可以通过led开关按键设置led发光器的工作状态;
步骤8.7:判断是否为模式“x”步骤x值取1至5:当为“1”时,将执行常规音频送话语音模式;当为“2”时,将执行常规组合喉头送话语音模式;当为“3”时,将执行常规组合唇读送话语音模式;当为“4”时,将执行喉头组合唇读送话语音模式;当为“5”时,将执行三者组合送话语音模式;根据模式选择,分别执行不同的送话语音模式步骤8.8;
步骤8.8:执行送话语音模式:根据当前工作模式,执行相应的送话语音模式,具体为:
六、常规音频送话语音模式,仅仅声音传感器有效工作,骨感传感器和视频采集不参加语音识别;
七、常规组合喉头送话语音模式,主要是声音传感器和骨感传感器有效工作,视频采集不参加语音识别;
八、常规组合唇读送话语音模式,主要是声音传感器和视频采集有效工作,骨感传感器不参加语音识别;
九、喉头组合唇读送话语音模式,主要是骨感传感器和视频采集有效工作,声音传感器不参加语音识别;
十、三者组合送话语音模式,主要是声音传感器、骨感传感器和视频采集三者同时有效工作,进行综合融合识别,然后,执行下一步步骤8.9;
步骤8.9:语音信息输出:输出融合后的语音信息后,执行下一步步骤8.10;
步骤8.10:判断是否中断:检查外部是否有中断,当没有中断时,将跳转至判断是否为模式“x”步骤8.7,否则,执行下一步步骤8.11;
步骤8.11:判断是否退出:检查有无退出信号,当没有退出信号时,将跳转至判断装置是否正常步骤8.3,否则,执行下一步步骤8.12;
步骤8.12:退出:退出程序,结束控制程序。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



