
 商标分类
商标分类  商标转让
商标转让 
一种语音穿戴装置及其音频数据处理方法与流程
 2021-01-28 13:01:31|
2021-01-28 13:01:31| 286|
286| 起点商标网
起点商标网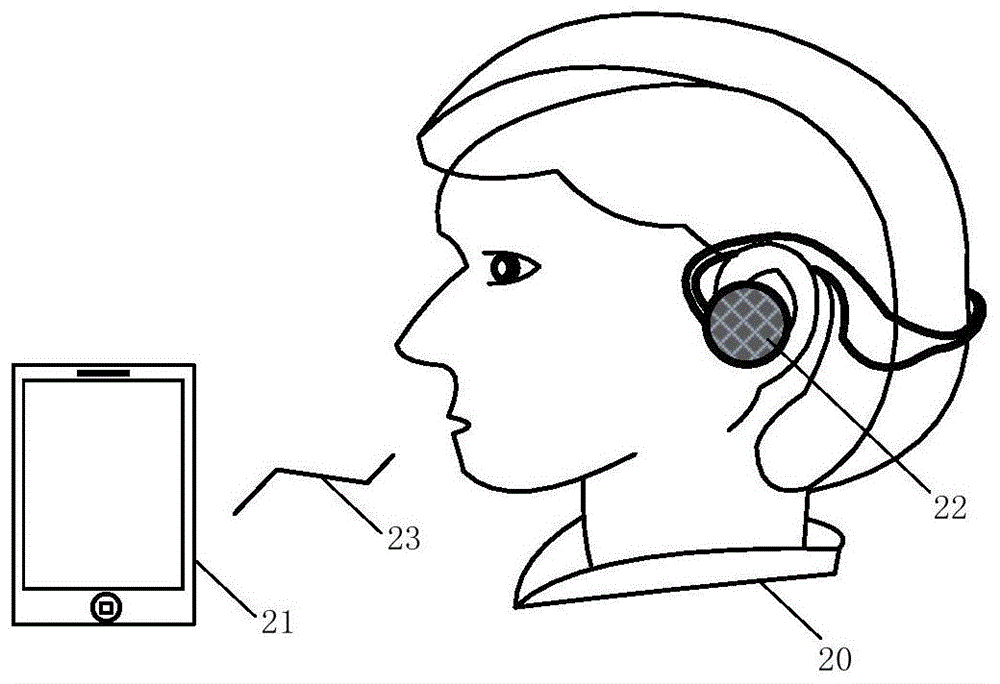
本发明属于智能穿戴的技术领域,尤其涉及一种语音穿戴装置及其音频数据处理方法。
技术背景
随着智能设备和穿戴设备的发展与完善,带音频输出功能的穿戴设备越来越多,譬如头戴类型、后挂类型、耳挂类型、耳塞类型、骨导类型的无线耳机、有线耳机、助听辅听耳机、vr头盔设备、智能眼镜和具有音频功能的穿戴式设备等,其音频输出具有固有性等特点。这些设备因为结构固定,可调节范围受限,很难由一种或多种设备型号就覆盖掉大部分使用者的头型和/或耳型。部分情况下设备与头型/耳型耦合不紧密,佩戴者感觉耦合比较松弛,使得设备的音频输出通道与听觉系统之间处于开放或半开放状态,从而使听觉系统感受到的音频频响发生变化,或听觉系统能感受到周围的环境噪声。部分情况下设备与头型/耳型耦合过于紧密,佩戴者感觉耦合比较紧,使得头型和/或耳型处于过压迫状态,从而使听觉系统感受到设备输出的音频频响发生变化,或听觉系统感受到设备输出的音频音量明显提高。这种设备佩戴耦合不紧密或过于紧密的状态,导致使用者无法真实听到美妙的原始音频,降低了用户体验预期。因此,有必要提供一种技术,来解决设备在各种人群、各种用户中的适配问题,提升用户体验,让更多人听到美妙的原始音频。
根据上述分析,现有技术方案存在如下问题:
第一:存在耦合不够合理的情况,导致语音穿戴设备输出的音频频响和音量发生改变,降低了用户体验。
第二:语音穿戴设备的佩戴无法自适应多种人群、多种用户头型和/或耳型。
第三:环境降噪处理,没有结合每个佩戴者的实际佩戴耦合情况进行个性化的特别自适应处理,音频体验效果不好。
技术实现要素:
本发明的目的在于提供一种根据环境声音强度和/或佩戴耦合状态以提升音频的清晰度和佩戴的舒适度的语音穿戴装置及其音频数据处理方法。
本发明提供一种语音穿戴装置,穿戴在佩戴者的头部上,其包括音频处理系统以及监测所述语音穿戴装置与佩戴者的头型和/或耳型的耦合状态的传感器模块,其中所述音频处理系统包括根据所述传感器模块监测的耦合状态的数据获取所述语音穿戴装置的佩戴状态信息的佩戴状态获取模块、获取一音频提供装置中的第一音频数据的第一音频获取模块、根据所述佩戴状态信息并调整所述第一音频数据和音量以获得第二音频数据的第一处理模块以及输出所述第二音频数据的第一输出模块;所述音频提供装置为所述语音穿戴装置的内置单元或独立于所述语音穿戴装置的外部终端设备。
进一步地,所述音频处理系统还包括获取所述语音穿戴装置的周围环境的第三音频数据的第二音频获取模块、根据所述传感器模块所述检测的佩戴状态信息以调整所述第三音频数据并得到第四音频数据的第二处理模块、用于将所述第二音频数据和所述第四音频数据进行合成并得到第五音频数据的第三处理模块和以及将所述第五音频数据输出的第二输出模块。
进一步地,所述音频处理系统还包括监测所述音频数据的音量输出的能量监测模块以及用于压缩和/或扩大所述音频数据的保护模块。
进一步地,所述第一处理模块包括模/数转换模块、音频分帧模块、时域到频域转换模块、频域信号处理模块、频域到时域转换模块、音频重组模块、数/模转换模块、降噪网络模块、特征信号检测模块和加权参数提取模块。
进一步地,所述传感器模块包括姿态检测传感器和佩戴状态传感器,所述佩戴状态传感器包括耦合度检测传感器,所述耦合度检测传感器位于语音穿戴装置的内侧且布置于与头型和/或耳型耦合相接面积最多的位置。
进一步地,所述语音穿戴装置还包括语音模块、存储模块、运算模块和通信模块。
本发明还提供一种语音穿戴装置的音频数据处理方法,包括如下步骤:
步骤101:获取一个音频提供装置中的第一音频数据;
步骤102:与步骤101同步,获取语音穿戴装置的佩戴状态信息;
步骤103:根据所述佩戴状态信息,调整所述第一音频数据和音量,以得到第二音频数据;
步骤104:输出所述第二音频数据。
本发明还提供一种语音穿戴装置的音频数据处理方法,包括如下步骤:
步骤201:获取一个音频提供装置中的第一音频数据;
步骤202:与步骤201同步,获取语音穿戴装置的佩戴状态信息;
步骤203:根据所述佩戴状态信息,调整所述第一音频数据和音量,以得到第二音频数据;
步骤204:输出所述第二音频数据;
步骤205:与步骤201同步,获取语音穿戴装置的周围环境的第三音频数据;
步骤206:与步骤203同步,根据所述佩戴状态信息,调整所述第三音频数据和音量,以得到第四音频数据;
步骤207:将所述第二音频数据与所述第四音频数据进行合成处理,以得到第五音频数据;
步骤208:输出所述第五音频数据。
本发明还提供一种语音穿戴装置的音频数据处理方法,包括如下步骤:
步骤301:获取一个音频提供装置中的第一音频数据;
步骤302:与步骤301同步,获取语音穿戴装置的佩戴状态信息;
步骤303:根据所述佩戴状态信息,调整所述音频数据和音量,以得到第二音频数据;
步骤304:监测所述第二音频数据的音量输出能量,判断是否超出预设的听力阈值范围;
步骤305:压缩/扩大所述第二音频数据;
步骤306:输出所述第二音频数据或压缩/扩大后的第二音频数据。
本发明还提供一种语音穿戴装置的音频数据处理方法,包括如下步骤:
步骤401:获取一个音频提供装置中的第一音频数据;
步骤402:与步骤401同步,获取语音穿戴装置的佩戴状态信息;
步骤403:根据所述佩戴状态信息,调整所述音频数据和音量,以得到第二音频数据;
步骤404:输出所述第二音频数据;
步骤405:与步骤401同步,获取语音穿戴装置的周围环境的第三音频数据;
步骤406:与步骤403同步,根据所述佩戴状态信息,调整所述第三音频数据和音量,以得到第四音频数据;
步骤407:将所述第二音频数据与所述第四音频数据进行合成处理,以得到第五音频数据;
步骤408:监测所述第五音频数据的音量输出能量,判断是否超出预设的听力阈值范围;
步骤409:压缩/扩大所述第五音频数据;
步骤410:输出所述第五音频数据或压缩/扩大后的第五音频数据。
本发明语音穿戴装置及其音频数据处理方法,语音穿戴装置以佩戴者当下的佩戴状态信息为参考,来处理音频数据,并输出与当下的佩戴状态信息相匹配的音频信号;在佩戴耦合紧密状态中,智能语音穿戴装置会调低该音频的低频分量,并适度调低输出音量;在佩戴耦合松弛状态中,则会相应地提高该音频的低频分量,并适度提高输出音量,达到根据佩戴耦合状态,自动调节音频频响和输出音量的目的;本发明可以根据环境声音强度和佩戴耦合状态,适度的开启主动降噪操作,提升音频的清晰度和佩戴的舒适度。
附图说明
下面将以明确易懂的方式,结合附图说明优选实施方式,对本发明予以进一步说明。
图1为本发明语音穿戴系统实施例的使用示意图;
图2为图1所示语音穿戴系统的语音穿戴装置的功能模块示意图;
图3为图2所示语音穿戴装置的第一处理模块在实施例中的子功能模块示意图;
图4为图3所示语音穿戴装置的第一处理模块的频域信号处理模块的子功能模块示意图;
图5为图1所示语音穿戴系统的语音穿戴装置的一实施例的音频数据处理方法的流程示意图;
图6为图1所示语音穿戴装置另一实施例的音频数据处理方法的流程示意图;
图7为图1所示语音穿戴装置另一实施例的音频数据处理方法的流程示意图;
图8为图1所示语音穿戴装置另一实施例的音频数据处理方法的流程示意图;
图9(a)为语音穿戴装置的佩戴状态检测传感器的一个惠斯通电桥型实施例的俯视图;
图9(b)为语音穿戴装置的佩戴状态检测传感器的一个惠斯通电桥型实施例的侧视图;
图9(c)为语音穿戴装置的佩戴状态检测传感器的一个惠斯通电桥型实施例的受力情况的侧视图;
图10为图9(a)至图9(c)所示惠斯通电桥型压阻耦合度检测传感器实施例在受力状态下的等效电路图;
图11(a)为基于惠斯通电桥型压阻耦合度检测传感器的语音穿戴装置的主体电路图;
图11(b)为语音穿戴装置实施例的压阻型耦合度检测传感器电路图。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
为使图面简洁,各图中只示意性地表示出了与本发明相关的部分,它们并不代表其作为产品的实际结构。另外,以使图面简洁便于理解,在有些图中具有相同结构或功能的部件,仅示意性地绘示了其中的一个,或仅标出了其中的一个。在本文中,“一个”不仅表示“仅此一个”,也可以表示“多于一个”的情形。
下面以具体实施例详细介绍本发明的技术方案。
本发明一种语音穿戴系统,作为物联网终端的穿戴设备,属于智能信息设备领域。
如图1所示,语音穿戴系统包括穿戴在佩戴者20头部上的语音穿戴装置22、终端设备21和连接语音穿戴装置22和终端设备21的通信链接23。其中通信链接23包括但不限于有线链接和无线链接。语音穿戴装置22佩戴于佩戴者20的头部和耳朵两侧周围,语音穿戴装置22的形态包括但不限于头戴类型、后挂类型、耳挂类型、耳塞类型、骨导类型的无线耳机、有线耳机、助听辅听耳机、vr头盔设备、智能眼镜和具有音频功能的穿戴式设备等,图1示意了语音穿戴装置22为后挂类型的无线耳机,图1所示的语音穿戴装置22的形态不作为发明专利的限制条件。终端设备21包括但不限于手机、手表、电脑、播放器、收音机、电视机、助听/辅听器或其他具备语音输出功能的设备。语音穿戴装置22可与终端设备21配合使用,也可独立使用,譬如语音穿戴装置22为带音乐播放功能的耳机/智能眼镜/头盔、带收音机功能的耳机、助听器等。
图2所示为语音穿戴装置22的功能模块示意图,语音穿戴装置22包括传感器模块111、语音模块112、存储模块113、运算模块114、通信模块115和音频处理系统120。
传感器模块111用于监测语音穿戴装置22与头型和/或耳型的耦合状态,传感器模块111包括姿态检测传感器和佩戴状态传感器,佩戴状态传感器包括耦合度检测传感器,耦合度检测传感器位于语音穿戴装置22的内侧且布置于与头型和/或耳型耦合相接面积最多的位置。
语音模块112用于声波信号与电信号的相互转换,语音模块112包括送话器、受话器、音频输入和/或输出接口以及对应的信号滤波处理电路单元等。
存储模块113用于存储语音穿戴装置22的程序代码、状态信息、数据结果、音频数据等资料。
运算模块114用于运行音频处理系统120的相关算法与逻辑,计算和处理各种音频数据、传感器数据和外部响应。
通信模块115用于与终端设备21建立通信链接,并与佩戴者20进行人机交互链接,通信模块115包括有线链接和无线链接的两种方式。通过通信模块115,语音穿戴装置22可获取终端设备21的数据信息流或传递语音穿戴装置22的数据信息流给终端设备21。
在一个优选实施例中,音频处理系统120由多个模块组成,每个模块是实现某一功能的特定程序代码段,具体包括佩戴状态获取模块121、第一音频获取模块122、第一处理模块123和第一输出模块124。
佩戴状态获取模块121,根据传感器模块111监测的耦合状态数据,通过滤波分析与处理,得到语音穿戴装置22的佩戴状态信息。
第一音频获取模块122,用于获取一个音频提供装置中的第一音频数据,其获取的方式包括但不限于有线和/或无线的链接方式。其中所述音频提供装置可以是语音穿戴装置22的内置单元,如内置音频播放单元、内置收音单元、内置助听单元等;所述音频提供装置也可以是独立于语音穿戴装置22的外部终端设备21,譬如手机、手表、电脑、播放器、收音机、电视机、助听/辅听器或其他具备语音输出功能的设备。所述第一音频数据可以是音乐、通话、助听语音、广播语音、合成音频等音频内容。
第一处理模块123,用于根据语音穿戴装置22的传感器模块111所检测到的佩戴状态信息,调整第一音频获取模块122所获取的第一音频数据的频响曲线和对应的音量,以得到第二音频数据。
其中所述调整的方式可以有多种:
方式一,调整所述第一音频数据本身的频响曲线,对相应特定频段的信号幅度进行放大和/或缩小,且可能对整体频响范围内的幅度进行等比的放大或缩小。
方式二,调整音频提供装置的输出数据,通过与音频提供装置进行通信,调节音频提供装置的输出数据的频响曲线,对相应特定频段的信号幅度进行放大和/或缩小,且可能对整体频响范围内的幅度进行等比的放大或缩小。
第一输出模块124,用于输出第二音频数据或压缩/扩大后的第二音频数据,至语音模块112,进行电信号到声波信号与的转换。
在另一个优选实施例中,音频处理系统120还包括第二音频获取模块125、第二处理模块126、第三处理模块127和第二输出模块128。
第二音频获取模块125,用于获取语音穿戴装置22的周围环境的第三音频数据,获取的方式包括但不限于有线和/或无线的链接方式。其中第三音频数据属于送话器信号,可以是模拟的信号,也可是数字信号。第二音频获取模块125可通过一个或多个送话器采集语音穿戴装置22周围环境的第三音频数据,还可以通过带滤波放大处理的送话器阵列来采集语音穿戴装置22周围环境的第三音频数据。
第二处理模块126,用于根据所述语音穿戴装置22的传感器模块111所检测到的佩戴状态信息,来调整所述第二音频获取模块125所获取的语音穿戴装置22周围环境的第三音频数据和音量,以得到第四音频数据,第四音频数据包含优化处理后的周围环境声音。
调整的方式可以有多种情况:
情况一,若佩戴状态耦合比较紧密,且第三音频数据的全频段能量较低,则对第三音频数据的整体频响范围内的幅度进行等比的缩小,直至降为零,以得到第四音频数据。
情况二,若佩戴状态耦合比较紧密,且第三音频数据的低频频段能量较高,则降低第三音频高频段的幅度至零,且对低频频段能量较高的部分进行等比的缩小,以得到第四音频数据。
情况三,若佩戴状态耦合比较松弛,则结合松弛的区域及面积对第三音频进行相应特定频段的信号幅度进行放大和/或缩小,且可能对整体频响范围内的幅度进行等比的放大或缩小,譬如松弛面积大,接触区域形成放大音腔,则对第三音频数据的整体频响范围内的幅度进行等比的放大,以得到第四音频数据。
第三处理模块127,用于将所述第二音频数据与所述第四音频数据进行合成处理,以得到第五音频数据,第五音频数据中含有与周围环境声音的成分,但相位与原始的周围环境声音相反,通过音频的传播路径后,最终在听觉系统处听到没有或几乎没有周围环境声音的干净音频。
第二输出模块128,用于输出所述第五音频数据或压缩/扩大后的第五音频数据至语音模块112,进行电信号到声波信号与的转换。
在另一个优选实施例中,音频处理系统120还包括能量监测模块129和保护模块130。
能量监测模块129,用于监测所述第二音频数据、第五音频数据的音量输出能量,并判断输出能量是否超出预设的听力阈值曲线范围,当所述音频音量的输出能量大于一个预设的曲线范围,且持续一个预定时间,则需开启保护模块130。
保护模块130,用于压缩和/或扩大所述第二音频数据、第五音频数据,譬如,对整体频响范围内的幅度进行等比的缩小。
需要说明的是,佩戴者20可以通过语音穿戴装置22的通信模块115进行选择,以选择音频处理系统120处于何种实施例模式,甚至完全关闭语音穿戴装置22的算法计算过程,把第一音频获取模块122直接链接到第一输出模块124。
在另一个优选实施例中,如图3所示,第一处理模块123在一个实施例中包含多个子功能模块。第一处理模块123包括模/数转换模块123a、音频分帧模块123b、时域到频域转换模块123c、频域信号处理模块123d、频域到时域转换模块123e、音频重组模块123f、数/模转换模块123g、降噪网络模块123h、特征信号检测模块123i和加权参数提取模块123j。
所述模/数转换模块123a,用于将所述第一音频数据进行数字化处理,以得到数字信号的第一音频数据。具体地,模/数转换模块123a可以配置采样率、通道延时等参数。需要说明的是,如果音频输入信号已经为数字信号,则输入信号可跳过模/数转换模块123a,直接进入音频分帧模块123b。
音频分帧模块123b,用于把数字化处理后的第一音频数据,按时间轴进行分段处理,以得到分段的数字化第一音频数据。需要说明的是,此处的分段的时长是可以配置的。
时域到频域转换模块123c,用于对所述分段后的数字化第一音频数据进行时域到频域转换,以得到与所述数字化第一音频数据对应的第一频域音频信号。需要说明的是,本实施例中,时域到频域转换模块123c可以通过快速傅里叶变换(fastfouriertransform,fft)将数字信号第一音频数据转换成对应的第一频域音频信号ffts1。
频域信号处理模块123d,用于对所述第一频域音频信号ffts1分频段进行限波/滤波处理,并进行对应的加权增益补偿控制,以得到第二频域音频信号ffts2。需要说明的是,本实施例中,可以通过梅尔滤波器把第一频域音频信号ffts1分拆到多个子频带中,如图4所示,基于加权参数提取模块123j提供的加权参数,子频带(具体为子频带增益补偿1、子频带增益补偿2、子频带增益补偿3、…、子频带增益补偿n)动态的调节第一频域音频信号ffts1的音量,然后合并各子频带的信号,从而形成新的频响曲线,以得到第二频域音频信号ffts2。
频域到时域转换模块123e,用于对所述第二频域音频信号ffts2进行频域到时域转换,以得到相应分段的数字化第二时域音频信号iffts2。需要说明的是,本实施例中,频域到时域转换模块123e采用快速傅里叶逆变换(inversefastfouriertransform,ifft)。
音频重组模块123f,用于将分段的数字化第二时域音频信号iffts2重组成在时间轴上连续的数字化第二音频信号。
数/模转换模块123g,用于将数字化第二音频信号,恢复成模拟音频信号,以输出第二音频信。
降噪网络模块123h,用于对佩戴状态检测的传感器数据进行滤波处理,移除和/或降低不相干的噪声信号,并对有用信息进行对应的增强。需要说明的是,本实施例中,前置使用了卡尔曼滤波的方法,以降低人体噪声带来的影响。
特征信号检测模块123i,用于对降噪后的传感器数据进行数据处理,提取出相关的特征信号匹配参数。需要说明的是,本实施例中,提取的相关特征信号包括,耦合的压力值、面积、腔体空间等。
加权参数提取模块123j,根据提取的佩戴状态特征参数,计算出对应的加权参数曲线和对应的加权因子。需要说明的是,本实施例中,加权因子是一系列与频响曲线相对应的参数组。
第一处理模块123的具体工作流程为:佩戴状态信息(具体为佩戴状态检测的传感器数据)依序降噪网络模块123h、特征信号检测模块123i、加权参数提取模块123j和频域信号处理模块123d,同时音频信号(具体为第一音频数据)依序输入模/数转换模块123a、音频分帧模块123b、时域到频域转换模块123c和频域信号处理模块123d,佩戴状态信息和音频信号输入均经频域信号处理模块123d处理后依序输入频域到时域转换模块123e、音频重组模块123f和数/模转换模块123g后输出音频信号。
图5~图8是语音穿戴装置22的多个优选实施例的音频数据处理方法的流程示意图。音频数据处理方法的执行主体是由图2所示的音频处理系统120中的各程序模块代码段执行,需要说明的是,实施例中的流程图不用于对执行步骤的顺序进行限定。
本发明还揭示一种语音穿戴装置22的音频数据处理方法,本方法基于传感器技术和信号处理技术,采用感知与数字信号处理相结合的方法。
图5是语音穿戴装置22的一个优选实施例的音频数据处理方法的流程示意图。
一种语音穿戴装置22的音频数据处理方法,其包括如下执行步:
步骤101:获取一个音频提供装置中的第一音频数据;
步骤102:与步骤101同步,获取语音穿戴装置的佩戴状态信息;
步骤103:根据所述佩戴状态信息,调整所述第一音频数据和音量,以得到第二音频数据;
步骤104:输出所述第二音频数据。
对于步骤101中,在实施例中,第一音频获取模块通过有线和/或无线的链接方式获取音频提供装置中的第一音频数据,第一音频数据可以是音乐、通话、助听语音、广播语音、合成音频等音频内容。
对于步骤102中,在实施例中,佩戴状态获取模块121通过耦合度检测传感器检测佩戴状态,通过分析对应的传感器数据,可反推佩戴状态。
对于步骤103中,在实施例中,语音穿戴装置22会先计算佩戴状态,获取加权参数组,然后第一处理模块123依据加权参数组对第一音频数据的频响曲线和幅度进行调整。
对于步骤104中,实施例中,第一输出模块124输出第二音频数据,第二音频数据会传递到语音穿戴装置22的语音模块112,进行电信号到声波信号与的转换。
因为使用者的头型、耳朵存在差异,因此导致语音穿戴装置22的佩戴状态也存在很大的差异,然而佩戴状态对听觉的频率响应造成一定的影响,譬如耦合越紧密,低频响应越好;同样音量输出的情况下,感觉音量越大。
图6是语音穿戴装置22的另一个优选实施例的音频数据处理方法的流程示意图。在实际情形一中,如果佩戴耦合效果差,听觉系统容易感知到额外的周围环境声音;在实际情形二中,如果佩戴相对紧密,但周围环境声音过大,特别是低频声音能量过大,听觉系统也会感知到额外的周围环境声音。为了获取更清晰的、更舒服的音频体验,有必要适度的自主开启自适应环境噪声处理功能。
一种语音穿戴装置22的音频数据处理方法,其执行步骤如下:
步骤201:获取一个音频提供装置中的第一音频数据;
步骤202:与步骤201同步,获取语音穿戴装置的佩戴状态信息;
步骤203:根据所述佩戴状态信息,调整所述第一音频数据和音量,以得到第二音频数据;
步骤204:输出所述第二音频数据;
步骤205:与步骤201同步,获取语音穿戴装置的周围环境的第三音频数据;
步骤206:与步骤203同步,根据所述佩戴状态信息,调整所述第三音频数据和音量,以得到第四音频数据;
步骤207:将所述第二音频数据与所述第四音频数据进行合成处理,以得到第五音频数据;
步骤208:输出所述第五音频数据。
本实施例中,步骤201至204分别与上述步骤101至104相同,就不重复叙述了。
对于步骤205,在实施例中,第二音频获取模块125获取语音穿戴装置的周围环境的第三音频数据,具体可通过送话器或送话器阵列从周围环境收集第三音频数据。第三音频数据可包括周围环境中任何声音源的音频信息,譬如交谈声、引擎声、汽笛声、撞击声等。
对于步骤206,在实施例中,第二处理模块126依据佩戴状态耦合的松紧程度,第三音频数据的频率成分与能量,来调整第三音频数据的频响曲线以及幅度,以得到第四音频数据,第四音频数据包含优化处理后的周围环境声音。
对于步骤207,在实施例中,第三处理模块127将所述第二音频数据与所述第四音频数据进行合成处理,以得到第五音频数据。第五音频数据中含有与周围环境声音的成分,但相位与原始的周围环境声音相反,通过音频的传播路径后,最终降低周围环境声音对听觉系统的感知干扰。
对于步骤208,在实施例中,第二输出模块128输出第五音频数据。第五音频数据会传递到语音穿戴装置22的语音模块112,进行电信号到声波信号与的转换。
图7语音穿戴装置22的另一个优选实施例的音频数据处理方法的流程示意图。实施例中,图7是在图5的基础上增加了保护听觉系统的功能,避免频段内的声音幅度过大,对听觉系统造成听力损伤。
一种语音穿戴装置22的音频数据处理方法,具体步骤如下:
步骤301:获取一个音频提供装置中的第一音频数据;
步骤302:与步骤301同步,获取语音穿戴装置的佩戴状态信息;
步骤303:根据所述佩戴状态信息,调整所述音频数据和音量,以得到第二音频数据;
步骤304:监测所述第二音频数据的音量输出能量,判断是否超出预设的听力阈值范围;
步骤305:压缩/扩大所述第二音频数据;实施例中,保护模块会对整体频响范围内的幅度进行等比的缩小。
步骤306:输出所述第二音频数据或压缩/扩大后的第二音频数据。
本实施例中,步骤301至303分别与上述步骤101至103相同,就不重复叙述了。
对于步骤304,在实施例中,能量监测模块129监测所述第二音频数据的音量输出能量,判断是否超出预设的听力阈值范围;需要说明的是,只有当第二音频的音量输出能量大于一个预设的曲线范围,且持续一个预定时间,则需开启保护模块130。
对于步骤305,在实施例中,保护模块130压缩/扩大所述第二音频数据,保护模块130会对整体频响范围内的幅度进行等比的缩小。
对于步骤306,在实施例中,第一输出模块124输出所述第二音频数据或压缩/扩大后的第二音频数据。第二音频数据或压缩/扩大后的第二音频数据会传递到语音穿戴装置22的语音模块112,进行电信号到声波信号与的转换。
图8语音穿戴装置22的另一个优选实施例的音频数据处理方法的流程示意图。实施例中,图8是在图6的基础上增加了保护听觉系统的功能,避免频段内的声音幅度过大,对听觉系统造成听力损伤。
一种语音穿戴装置22的音频数据处理方法,具体步骤如下:
步骤401:获取一个音频提供装置中的第一音频数据;
步骤402:与步骤401同步,获取语音穿戴装置的佩戴状态信息;
步骤403:根据所述佩戴状态信息,调整所述音频数据和音量,以得到第二音频数据;
步骤404:输出所述第二音频数据;
步骤405:与步骤401同步,获取语音穿戴装置的周围环境的第三音频数据;
步骤406:与步骤403同步,根据所述佩戴状态信息,调整所述第三音频数据和音量,以得到第四音频数据;
步骤407:将所述第二音频数据与所述第四音频数据进行合成处理,以得到第五音频数据;
步骤408:监测所述第五音频数据的音量输出能量,判断是否超出预设的听力阈值范围;
步骤409:压缩/扩大所述第五音频数据;
步骤410:输出所述第五音频数据或压缩/扩大后的第五音频数据。
本实施例中,步骤401至步骤407分别与步骤201至步骤207相同,就不重复叙述了。
对于步骤408,本实施例中,能量监测模块129监测所述第五音频数据的音量输出能量,判断是否超出预设的听力阈值范围。需要说明的是,只有当第五音频的音量输出能量大于一个预设的曲线范围,且持续一个预定时间,则需开启保护模块。
对于步骤409,本实施例中,保护模块130压缩/扩大所述第五音频数据,保护模块130会对整体频响范围内的幅度进行等比的缩小;
对应步骤410,本实施中,第二输出模块128输出所述第五音频数据或压缩/扩大后的第五音频数据。第五音频数据或压缩/扩大后的第五音频数据会传递到语音穿戴装置22的语音模块112,进行电信号到声波信号与的转换。
图9(a)至图9(c)是佩戴状态检测传感器的一个惠斯通电桥型实施例结构示意图,实施例中,优选压阻型惠斯通电桥传感器。图9(a)为压阻型惠斯通电桥传感器的结构单元俯视图,其中101为传感器的衬底材料,102为衬底材料101的两个镂空区,103为压阻材料单元,其布置于两个镂空区102之间的衬底材料101上,且惠斯通电桥的四个压阻材料单元103分别置于衬底材料101上下两侧,四个压阻材料单元分别为第一压阻材料单元1031、第二压阻材料单元1032、第三压阻材料单元1033和第四压阻材料单元1034,其电阻分别为r1、r2、r3和r4。
如图9(b)所示,第一压阻材料单元r1(1031)和第三压阻材料单元r3(1033)置于衬底材料101的下方,第二压阻材料单元r2(1032)和第四压阻材料单元r4(1034)置于衬底材料101的上方,第一压阻材料单元r1(1031)和第二压阻材料单元r2(1032)对称设置,第三压阻材料单元r3(1033)和第四压阻材料单元r4(1034)对称设置。
如图9(c)所示,当有一外部压力f作用于衬底材料101上,第一压阻材料单元r1和第三压阻材料单元r3被拉升,电阻增大;第二压阻材料单元r2和第四压阻材料单元r4被挤压,电阻减小。压力f越大,对应压阻材料单元的电阻增大、减少的越多。压阻材料单元r1、r2、r3、r4按照惠斯通电桥的方式链接起来,当有一外部压力f作用于该压阻型惠斯通电桥,则对应的电桥输出电压发生相应的变化,如图10所示。
图10是惠斯通电桥型压阻耦合度检测传感器实施例在受力状态下的等效电路图。如图10(a)所示,当压阻型惠斯通电桥没有受到外力的时候,电阻r1、r2、r3、r4的阻值保持相近且稳定不变,因此电桥的输出点2获得的电阻分压v1保持稳定不变,同时电桥的输出点4获得的电阻分压v2保持稳定不变,从而使得电桥的输出压差v=v1-v2保持稳定不变。如图10(b)所示,当有一外部压力f作用于该压阻型惠斯通电桥,则电阻r1和r3增大,电阻r2和r4减少,因此v1下降,同时v2上升,从而使得电桥的输出压差v=v1-v2成倍的扩大。采用图9所示的双面悬臂布局,可显著的提升压阻型惠斯通电桥的检测灵敏度。
图11(a)和图11(b)是基于惠斯通电桥型压阻耦合度检测传感器的语音穿戴装置的实施例电路图。图11(a)为语音穿戴装置22实施例的主体电路图。处理器芯片u1为b300,存储芯片u3为m95512,两者通过spi接口通信;晶体x1负责为处理器u1提供38.4mhz的时钟;小功率受话器u2可直接电连接到处理器芯片u1的rcvr接口,需要注意的是,如果驱动大功率受话器,则需要在大功率受话器与处理器芯片u1之间增加功放器;处理器芯片u1内置的模拟/数字转换接口ai0电连接到第一音频模块的一个声道;处理器芯片u1内置的模拟/数字转换接口ai1电连接到一个用于采集周围环境声音的送话器;处理器芯片u1内置的模拟/数字转换接口ai4电连接到传感器电路单元的输出;处理器芯片u1的sda_i2c/scl_i2c接口电连接到传感器单元,用于控制和动态配置传感器单元的参数;处理器芯片u1的gpio3/gpio4接口用于控制传感器单元的供电;处理器芯片u1的tx/rx接口用于与其他外设通信。
图11(b)为语音穿戴装置实施例的压阻型耦合度检测传感器电路图。其中,u7~u12为6个压阻型惠斯通电桥传感器,其全部电连接放大芯片u4;放大芯片u4为xr10910,芯片的out接口电连接处理器芯片u1的ai4接口,处理器芯片u1通过u4的out接口,获得传感器的原始模拟数据;芯片u4的sda/scl接口电连接处理器芯片u1的sda_i2c/scl_i2c接口,处理器芯片u1通过i2c可以方便的选择任意一个压阻型惠斯通电桥传感器的数据;pmos管q5/q6用于控制芯片u4的供电,通过合理的控制供电时序,可以降低系统整体能耗。
需要特别说明的是,图11(a)和图11(b)所示的基于惠斯通电桥型压阻耦合度检测传感器的语音穿戴装置的实施例电路图,只用于处理一个声道的数据信息,如果需要处理两个或两个以上声道的数据信息,则需要两个或两个以上同样的电路配置单元。
为了方便理解,以下结合图1~11(b)举例进行说明。
如图1所示,当佩戴者20佩戴语音穿戴装置22时,语音穿戴装置22基于传感器技术和信号处理技术,采用感知与数字信号处理相结合的方法,通过自动监测佩戴者的设备22佩戴状态信息,以及设备周围的环境声音为前提参考,来处理音频数据,并输出与当下状态相匹配的音频信号。具有根据环境声音强度和佩戴耦合状态,自适应调节输出的音频频响、音频音量,以及自适应开启主动降噪的特点,最终提升音频输出的清晰度和佩戴的舒适度。譬如,当佩戴者20在图书馆或办公室听音乐时,若佩戴耦合相对紧密,则语音穿戴装置22会调低该设备输出音频中的低频分量,并适度对整体频响范围内的幅度进行等比的缩小;若佩戴耦合相对松弛,则语音穿戴装置22会相应地提高该设备输出音频中的低频分量,并适度对整体频响范围内的幅度进行等比的放大。譬如,当佩戴者20在飞机或高铁上听音乐时,因为周围环境声音较大,周围环境声音相对容易对佩戴者20的听觉系统造成干扰,特别是语音穿戴装置22与佩戴者20的头型和/或耳型耦合不紧密,甚至在语音穿戴装置22与佩戴者20之间形成了开孔的腔体,此时周围环境声音对佩戴者20的听觉系统造成干扰会更加明显,且这种干扰因佩戴者20的头型和/或耳型而异;本发明通过检测环境声音强度和佩戴耦合状态,适度的开启主动降噪操作,可明显的提升音频的清晰度和佩戴的舒适度。
需要特别说明的是,在一实施例中,语音穿戴装置22与佩戴者20之间的佩戴耦合状态信息,可通过终端设备21传递到云服务器,通过对云服务器中海量语音穿戴装置22的佩戴状态信息进行数据挖掘和分析,可以针对具有不同头型和/或耳型特征的人群,评估并设计出多种更符合人体工学特征的普通耳机,为兼顾成本与佩戴舒适性提供更好的评判依据。
本发明一种语音穿戴装置及其音频数据处理方法,语音穿戴装置以佩戴者当下的佩戴状态信息为参考,来处理音频数据,并输出与当下的佩戴状态信息相匹配的音频信号;在佩戴耦合紧密状态中,智能语音穿戴装置会调低该音频的低频分量,并适度调低输出音量;在佩戴耦合松弛状态中,则会相应地提高该音频的低频分量,并适度提高输出音量,达到根据佩戴耦合状态,自动调节音频频响和输出音量的目的。进一步的,可以根据环境声音强度和佩戴耦合状态,适度的开启主动降噪操作,提升音频的清晰度和佩戴的舒适度。
应当说明的是,上述实施例均可根据需要自由组合。以上所述仅是本发明的优选实施方式,但是本发明并不限于上述实施方式中的具体细节,应当指出,对于本技术领域的普通技术人员来说,在本发明的技术构思范围内,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,对本发明的技术方案进行多种等同变换,这些改进、润饰和等同变换也应视为本发明的保护范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



