
 商标分类
商标分类  商标转让
商标转让 
一种基于词覆盖率的语音训练集最小化方法与流程
 2021-01-28 12:01:09|
2021-01-28 12:01:09| 314|
314| 起点商标网
起点商标网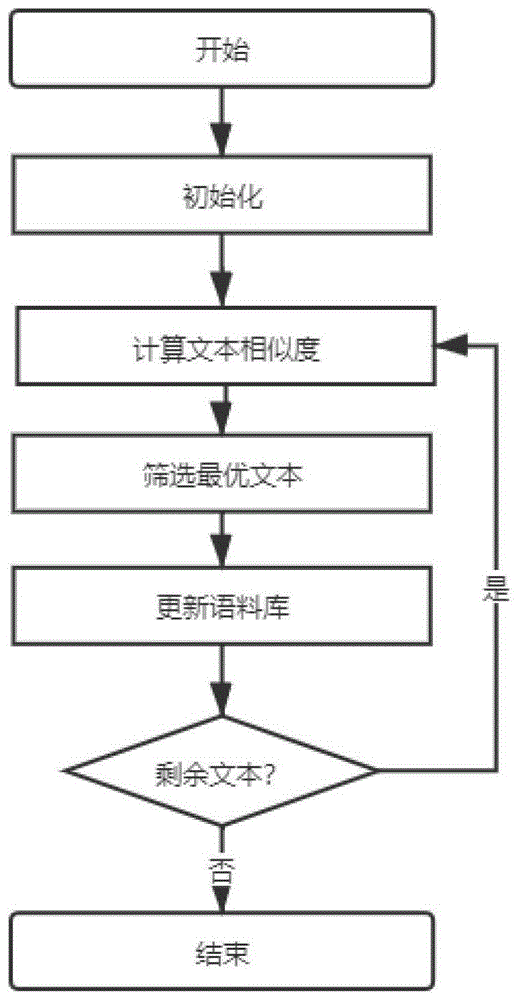
本发明涉及语音识别
技术领域:
,尤其涉及一种基于词覆盖率的语音训练集最小化方法。
背景技术:
:深度神经网络(deepneuralnetworks,dnn)在语音识别
技术领域:
的应用和改进和海量的训练数据以及强大的计算能力作为保障,通用自动语音识别技术(automaticspeechrecognition,asr)取得了巨大的突破。但是,在为专门领域开发基于asr的系统时,比如基于asr的医疗报告自动生成系统,通用asr模型的性能有显著下降。比如,科大讯飞的云端语音识别引擎,在通用语音上的语音识别的字错误率低于5%;但是前期实验评估表明,在医疗领域语音数据上,其字错误率接近20%。其原因在于通用asr模型是基于通用语音和文本数据训练的,其面临的特征和分布不能与专门领域的数据特征和分布完全一致。业界主要基于两种思路来改善专门领域的语音识别性能。第一种思路是,补充专门领域的数据集,然后利用模型迁移等技术,将通用asr模型适配到专门领域。第二种思路是,基于专门领域重新训练asr模型。这两种思路都需要搜集一定规模的专门领域的数据。然而,通常专门领域的数据集极为缺乏,尤其是语音数据。比如,在医疗报告自动生成场景下,已有海量医疗报告的文本数据,但是基本上没有语音记录。语音数据的采集成本异常高昂,不仅需要额外投入设备和人力资源,而且会干扰现有的医疗业务流程。技术实现要素:本发明通过提供一种基于词覆盖率的语音训练集最小化方法,解决了现有技术中通用asr模型在专门领域性能显著下降、语音数据采集成本高昂的问题。本发明提供一种基于词覆盖率的语音训练集最小化方法,包括以下步骤:步骤1、初始化词典集合为空,遍历所有训练集文本,将每条文本中的词汇集合与所述词典集合取并集得到词袋,所述词袋包含第一数量的词汇;得到所述词袋后,为每条文本生成对应的向量;将语料库的全局向量globalvector初始化为维度为所述第一数量的零向量;步骤2、计算当前未加入语料库的剩余文本对应的向量filevector与当前的语料库的向量globalvector之间的相似度,得到区别程度信息,所述区别程度信息记为dis(globalvector,filevector);对每一条剩余文本,以文件名作为key,以该文本对应的区别程度信息dis为value,存入文件名-dis词典;步骤3、遍历所述文件名-dis词典,维护最大dis值的{filename,dis}二元组;步骤4、将所述最大dis值的{filename,dis}二元组对应的文本加入语料库,更新语料库的词汇集合,并计算加入该文本后的词覆盖率;所述词覆盖率定义为当前语料库所含词汇数量与所述第一数量之比;步骤5、判断当前的词覆盖率是否达到预期条件且是否还有剩余文本;若所述当前的词覆盖率达到所述预期条件,或者,已无剩余文本可加入语料库,则结束训练集筛选算法,得到最小化的语音训练集;若所述当前的词覆盖率未达到所述预期条件,且还有剩余文本,则转至步骤2。优选的,所述步骤1中,所述为每条文本生成对应的向量的具体实现方式为:将词汇作为特征项,将文本定义为该文本包含的所有特征项及特征项对应的权重所组成的集合,表示为d=d(t1,w1;t2,w2;...,tn,wn);其中,tk表示特征项1≤k≤n,wk表示特征项tk对应的权重,1≤k≤n。优选的,所述步骤1中,为每条文本生成对应的向量后,以文本名路径作为key,将文本对应的向量作为value存入所述词袋中。优选的,所述步骤2中,计算相似度采用余弦相似度方法,所述区别程度信息dis(globalvector,filevector)=1-similarity(globalvector,filevector)=1-cosθ。优选的,所述步骤2中,计算相似度采用维度数评估方法,所述区别程度信息优选的,所述步骤3中,所述维护最大dis值的二元组的具体实现方式为:以所述文件名-dis词典中的第一条记录初始化{filename,dis}二元组,遍历比较后续记录的dis值,若当前记录dis值大于当前{filename,dis}二元组所维护的最大dis值,则用该记录的filename和dis更新{filename,dis}二元组。优选的,所述步骤4中,计算加入该文本后的词覆盖率后,记录当前的文件名和当前的词覆盖率。优选的,所述步骤5中的所述最小化的语音训练集对应的输出文件包括训练集中的所有文件名、文件数和对应的词覆盖率;所述最小化的语音训练集用于训练语音识别模型。本发明中提供的一个或多个技术方案,至少具有如下技术效果或优点:在发明中,遍历所有训练集文本获得词袋,并为每条文本生成对应的向量,计算当前未加入语料库的剩余文本对应的向量与当前的语料库的向量之间的相似度,得到区别程度信息,根据区别程度信息挑选出对语料库贡献最大的文本,最终得到最小化的语音训练集。本发明用最少的数据得到最大的模型性能提升,通过筛选现有文本数据采集录音,可以有效降低语音采集成本。附图说明图1为本发明实施例提供的一种基于词覆盖率的语音训练集最小化方法中筛选训练集的流程图;图2是本发明实施例提供的一种基于词覆盖率的语音训练集最小化方法中词覆盖率-训练样本量图;图3是本发明实施例提供的一种基于词覆盖率的语音训练集最小化方法中词覆盖率-模型性能图;图4是本发明实施例提供的一种基于词覆盖率的语音训练集最小化方法中训练样本量-模型性能图;图5是本发明实施例提供的一种基于词覆盖率的语音训练集最小化方法中训练样本量-模型性能平滑图;图6是本发明实施例提供的一种基于词覆盖率的语音训练集最小化方法中训练样本量-模型性能散点图。具体实施方式本发明的技术方案为一种基于词覆盖率的语音训练集最小化方法,包含以下步骤:步骤1,初始化词典dictionary集合为空,遍历所有训练集文本,将每条文本中的词汇集合与词典dictionary集合取并集,得到词袋(即所有词汇的集合dictionary),所述词袋包含第一数量的词汇。此时语料库未加入文本,语料库对应的向量globalvector为零向量,wordcoverage为0。得到所述词袋(即获取到总词汇)后对所有的文本生成对应的向量,对每个文本进行遍历词典,判断词典中的词是否出现在本文本中,若出现则向量新增一维置1,否则置0。将语料库的向量globalvector初始化为维度为所述第一数量的零向量。步骤2,计算当前未加入语料库的剩余文本对应的向量filevector与当前的语料库的向量globalvector之间的相似度,得到区别程度信息。相似度是指任意两个文本d1和d2之间的相似性系数similarity(d1,d2),代表两个文本内容的相关程度(degreeofrelevance)。可以借助于n维向量之间的某种距离来表示文本之间的相似度。每条文本对应的向量已由步骤1生成,globalvector随着文本加入语料库而不断变化,剩余文本与其相似度也随之改变,根据相似度求出区别程度dis(globalvector,filevector)。具体的,采用两种方法计算dis(globalvector,filevector)。一种方法令:dis(globalvector,filevector)=1-similarity(globalvector,filevector)=1-cosθ。另一种方法令:步骤3,遍历步骤2中得到的文件名-dis词典,维护最大dis值的{filename,dis}二元组。步骤4,根据步骤3中得到的最大dis值的{filename,dis}二元组,以该文本作为对当前语料库贡献最大的文本加入语料库中,更新语料库中的词汇集合,计算加入该文本后语料库的词覆盖率,记录当前文件名和词覆盖率。步骤5,判断当前的词覆盖率是否达到预期标准且是否还有剩余文本,若达到预期标准或已无文本可加入语料库,则结束训练集筛选算法,得到最小化的语音训练集,若未达到预期标准且还有剩余文本,则转步骤2。所述最小化的语音训练集对应的输出文件包括训练集中的所有文件名、文件数和对应的词覆盖率;所述最小化的语音训练集用于训练语音识别模型。此外,还可以包括步骤6。步骤6,根据所述最小化的语音训练集(即预期词覆盖率划分的训练集)去训练语音识别模型,得到训练好的语音识别模型,然后用测试集验证所述训练好的语音识别模型的性能。为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。本发明的应用场景满足如下假设:假设1:在目标应用领域,已有海量文本数据,但是缺乏对应的语音数据。假设2:在目标应用领域,语音数据的采集成本十分高昂。在本发明的目标应用场景下,从文本库中挑选文本(y),提供给录音人员来采集录音(x),从而构造训练样本(x,y)。本发明主要基于向量空间模型,提出的一种基于词覆盖率的语音训练集最小化方法。本方法通过计算文本相似度来考虑不同文本对当前语料库的模型训练性能提升贡献。通过本发明获得筛选后的训练集大小有可观的减少,其训练得到的语音识别模型性能与总语料库(即未删选前的全体训练集文本)训练得到的模型性能十分接近。本发明提供的方法能够用计算机软件技术实现流程。参见图1,实施例以thchs-30数据集和asrt语音识别模型为例对本发明的流程进行一个具体的阐述,如下:thchs-30数据集,共1000条选自大容量新闻的文本(语音13388条,总词数8873),实验过程中将全部数据拆分成训练集和测试集:训练集800(11392音频,词数7537);测试集200(1996音频,词数2513)。本发明基于向量空间模型(vsm),将词汇看作vsm中最小的不可分的语言单元作为特征项(featureterm)。一个文本的内容被看成是它含有的特征项所组成的集合,表示为:document=d(t1,t2,...,tn),其中tk是特征项,1≤k≤n。项的权重(termweight):对于含有n个特征项的文本d(t1,t2,...,tn),每一个特征项tk都依据一定的原则被赋予一个权重wk,用于表示特征项在文本中的重要程度。一个文本d可用它含有的特征项及其所对应的权重所表示:d=d(t1,w1;t2,w2;....,tn,wn),简记为d=d(w1,w2,...,wn),其中wk就是特征项tk的权重,1≤k≤n。一个文本在上述约定下可以看成是n维空间中的一个向量,各个特征项互异且无先后顺序关系。定义dictionary为存储训练集全部词汇的词袋,globalvector为当前语料库的向量,filename为文本名,filevector为文本对应的向量,wordcoverage为当前语料库所含词汇数与词袋中词汇数之比,即词覆盖率。步骤1,初始化词典dictionary集合为空,遍历所有训练集文本,将每条文本中的词汇集合与词典dictionary集合取并集,得到词袋(即所有词汇的集合dictionary)。此时语料库未加入文本,语料库对应的向量globalvector为零向量,wordcoverage为0。获取到总词汇后对所有的文本生成对应的向量,对每个文本进行遍历词典,判断词典中的词是否出现在本文本中,若出现则向量新增一维置1,否则置0。实施例具体的实施过程说明如下:根据1000条文本所存放的路径得到所有文本的完整路径名,用列表存储。初始化dictionary时遍历整个列表,与1000条文本的词集合作逐条的合并,遍历完毕后dictionary集合共计8873个词,globalvector初始化为维度为8873的零向量。遍历所有文本,为每条文本生成对应的向量,以文本路径名作为key,对应向量作为value存入词典中,避免后续重复计算。步骤2,计算当前未加入语料库的剩余文本对应的向量filevector与当前的语料库的向量globalvector之间的相似度,得到区别程度信息。相似度是指任意两个文本d1和d2之间的相似性系数similarity(d1,d2),代表两个文本内容的相关程度(degreeofrelevance)。可以借助于n维向量之间的某种距离来表示文本之间的相似度。每条文本对应的向量已由步骤1生成,globalvector随着文本加入语料库而不断变化,剩余文本与其相似度也随之改变,根据相似度求出区别程度dis(globalvector,filevector)。实施例具体实施方案为:本发明运用了两种不同的相似度计算方法,方法一采用余弦相似度(cosinesimilarity)通过计算两个向量的夹角余弦值来评估他们的相似度。将向量根据坐标值,绘制到向量空间中,求得他们的夹角,并得出夹角对应的余弦值,此余弦值就可以用来表征这两个向量的相似性。夹角越小,余弦值越接近于1,它们的方向越吻合,则越相似。假定a和b是两个n维向量,a(a1,a2,...,an),b(b1,b2,...,bn),则a与b的相似性系数等于:本发明记dis(a,b)=1-sim(a,b)=1-cosθ,向量a为globalvector,向量b为filevector,两向量的夹角θ越接近90°,两文本的相似度(cosθ)越小,dis越大,代表当前文本对语料库的贡献越大。该方法对应的结果为图2-图6中的cosine。方法二通过计算向量a(globalvector)为0,向量b(filevector)为1的维度数来评估当前文本对于语料库的贡献,dis越大,该文本为语料库添入的新词越多,代表当前文本对语料库的贡献越大。该方法对应的结果为图2-图6中的increment。对每一条文本以文件名为key,dis为value存入文件名-dis词典中。步骤3,遍历步骤2中得到的所述文件名-dis词典,维护最大dis值的{filename,dis}二元组。实施例具体实施方案为:以文件名-dis词典中的第一条记录初始化{filename,dis}二元组,遍历比较后续记录的dis值,若当前记录dis值大于二元组所维护的最大值,则用该记录的filename和dis更新二元组。步骤4,根据步骤3中得到的所述最大dis值的{filename,dis}二元组,以该文本作为对当前语料库贡献最大的文本加入语料库中,更新语料库中的词汇集合,计算加入该文本后语料库的词覆盖率,记录当前文件名和词覆盖率。实施例具体实施方案为:根据当前filename读取相应文本,获取到文本中的词汇并加入集合中,该集合与记录当前语料库的词集合相合并,即表明语料库中已加入该文本所含词汇。计算语料库集合的大小与词袋dictionary的大小得到词覆盖率,将filename和wordcoverage加入列表中。步骤5,判断当前的词覆盖率是否达到预期标准且是否还有剩余文本,若达到预期标准或已无文本可加入语料库,则算法结束转步骤6,若未达到预期标准且还有剩余文本,则转步骤2。步骤6,根据训练集筛选算法得到的输出文件可得出训练集的所有文件名、文件数和对应的词覆盖率。根据预期词覆盖率划分的训练集去训练语音识别模型,然后用测试集验证模型性能。实施例具体实施方案为:为找到合适词覆盖率去训练语音识别模型,根据词覆盖率分别为20%、40%、60%、80%、100%对相似度计算方法一(cosine)和方法二(increment)和随机采样方法(baseline)共得到15组训练集,随机采样方法用作对照。为达到词覆盖率标准所需训练样本量的具体数据如表1所示:表1三种采样方法对应的词覆盖率标准与所需训练样本量的关系方法20%覆盖率40%覆盖率60%覆盖率80%覆盖率100%覆盖率baseline133305504735800cosine122276462712800increment96235420686800根据图2可知,方法一和方法二相较于随机采样表现都更为优秀,能够以更小的训练集得到既定词覆盖率。且方法二能以最少的文本数得到相同覆盖率。对用15组训练集分别训练得到的语音识别模型进行测试集验证,每组的词错误率如表2所示:表2三种采样方法对应的词覆盖率标准与词错误率的关系方法20%覆盖率40%覆盖率60%覆盖率80%覆盖率100%覆盖率baseline0.5920.3490.2920.2490.247cosine0.6120.3480.2710.2430.247increment0.6630.3430.2780.2480.247根据图3可知,词覆盖率和模型性能是紧密相关的,词覆盖率越高,模型性能越高(词错误率越低)。将图3中横坐标由词覆盖率换成文本数可更直观体现出训练集筛选的效果,如图4、图5、图6所示,可知在相同的文本数下,方法一和方法二的模型性能有略微提升,而对于相同模型性能下所需要的文本数而言,方法一和方法二较随机采样方法有较大的减少,以0.3的词错误率为例,方法二较随机采样少用了130条左右的文本。综上,本发明提供的一种基于词覆盖率的语音训练集最小化方法,采取计算文本区别程度,根据结果挑选出对语料库贡献最大的文本,能够用最少的数据得到最大的模型性能提升。最后所应说明的是,以上具体实施方式仅用以说明本发明的技术方案而非限制,尽管参照实例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips