
 商标分类
商标分类  商标转让
商标转让 
声音可视化方法及装置、存储介质、MR混合现实设备与流程
 2021-01-28 12:01:15|
2021-01-28 12:01:15| 226|
226| 起点商标网
起点商标网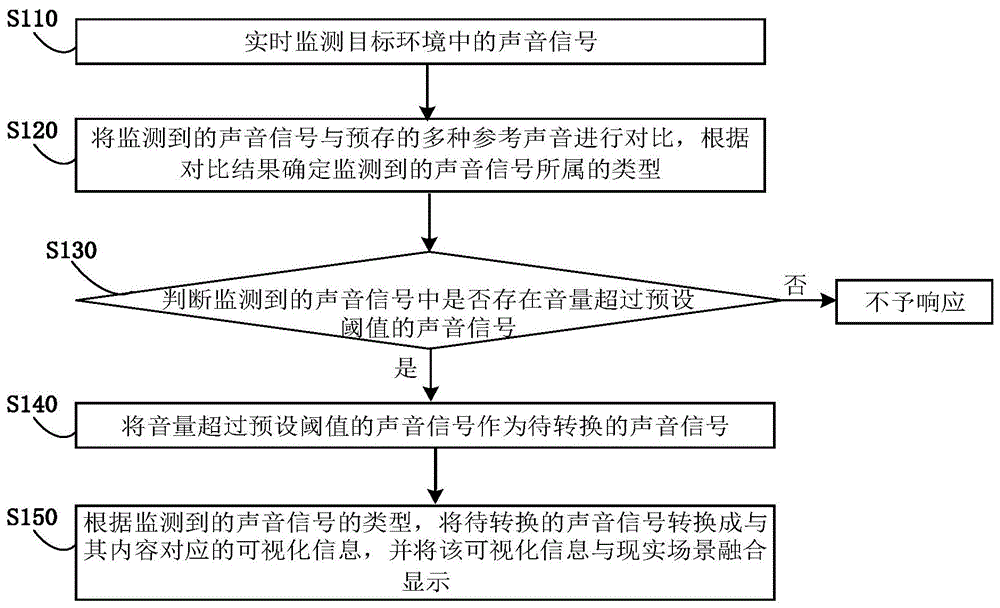
本发明属于声音识别与转换应用技术领域,具体涉及一种声音可视化方法及装置、存储介质、mr混合现实设备。
背景技术:
mr混合现实技术是一种将物理现实与数字世界相互混合的技术,此技术实现了对人所处真实世界中的位置数据的捕获,并包括对其边界和表面通过空间映射和理解实现的位置、照明、声音、定位以及对象识别等。之后,通过将计算机处理、人类输入和环境输入这三方面结合起来,就能创建出混合的世界,并让外人在其中感受到沉浸式的混合现实体验了。
经检索,公开号为cn109308282a的专利属于该领域的发明。该发明阐述了一种运用在mr混合现实设备上的并行架构方法及装置,采用中央处理器、图形图像处理器、可重构处理器组合的异构并行形式,利用可重构处理器的高并发、低功耗、可重构的特点实现对数据流的高速处理,使得mr混合现实设备显示的画面能够更实时,提升用户体验。
目前,市面上已有mr混合现实设备,例如mr穿戴设备,穿戴者可以感受到虚拟的影像在现实生活中的投射。
目前,听障人士无法听到声音,无法知晓身边人讨论的内容,更无法感受到身边环境的氛围,因而无法融入身边环境。甚至,在特殊情况下可能因无法及时做出反应而发生危险。
现在亟须一种声音可视化方法及装置、存储介质、mr混合现实设备。
技术实现要素:
本发明所要解决的技术问题是由于听障人士无法听到声音导致无法融入身边环境的问题。
针对上述问题,本发明提供了一种声音可视化方法及装置、存储介质、mr混合现实设备。
第一方面,本发明提供了一种声音可视化方法,应用于mr混合现实设备,包括以下步骤:
实时监测目标环境中的声音信号,其中,所述目标环境为mr混合现实设备所在环境;
将监测到的声音信号与预存的多种参考声音进行对比,根据对比结果确定监测到的声音信号所属的类型;
从监测到的声音信号中筛选出待转换的声音信号;
根据监测到的声音信号的类型,将待转换的声音信号转换成与其内容对应的可视化信息,并将该可视化信息与现实场景融合显示。
根据本发明的实施例,优选地,从监测到的声音信号中筛选出待转换的声音信号,包括以下步骤:
从监测到的声音信号中筛选出音量超过预设阈值的声音信号,作为待转换的声音信号。
根据本发明的实施例,优选地,从监测到的声音信号中筛选出待转换的声音信号,包括以下步骤:
根据监测到的声音信号的类型,判断监测到的声音信号中是否存在用于提示危险情况的声音;
当监测到的声音信号中存在用于提示危险情况的声音时,将用于提示危险情况的声音作为待转换的声音信号;
当监测到的声音信号中不存在用于提示危险情况的声音时,从监测到的声音信号中筛选出音量超过预设阈值的声音信号,作为待转换的声音信号。
根据本发明的实施例,优选地,当监测到的声音信号的类型为音乐时,可视化信息为带有歌词和/或带有音乐波形节奏跳动的视频。
根据本发明的实施例,优选地,当监测到的声音信号的类型为语言时,可视化信息为文字和/或手势。
根据本发明的实施例,优选地,当监测到的声音信号的类型为车辆鸣笛声时,可视化信息为表示不同危险等级的警告图像。
根据本发明的实施例,优选地,所述危险等级通过以下步骤确定:
通过相邻两时刻下车辆的位置变化计算车辆的速度;
根据车辆的速度以及车辆与mr混合现实设备之间的距离确定车辆的危险等级。
第二方面,本发明提供了一种声音可视化装置,应用于mr混合现实设备,包括:
监测模块,用于实时监测目标环境中的声音信号,其中,所述目标环境为mr混合现实设备所在环境;
确定模块,用于将监测到的声音信号与预存的多种参考声音进行对比,根据对比结果确定监测到的声音信号所属的类型;
筛选模块,用于从监测到的声音信号中筛选出待转换的声音信号;
转换模块,用于根据监测到的声音信号的类型将待转换的声音信号转换成与其内容对应的可视化信息,并将该可视化信息与现实场景融合显示。
第三方面,本发明提供了一种存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述方法的步骤。
第四方面,本发明提供了一种mr混合现实设备,其包括存储器和处理器,该存储器上存储有计算机程序,该计算机程序被处理器执行时实现上述方法的步骤。
与现有技术相比,上述方案中的一个或多个实施例可以具有如下优点或有益效果:
应用本发明的声音可视化方法,实时监测目标环境中的声音信号,其中,所述目标环境为mr混合现实设备所在环境;将监测到的声音信号与预存的多种参考声音进行对比,根据对比结果确定监测到的声音信号所属的类型;从监测到的声音信号中筛选出待转换的声音信号;根据监测到的声音信号的类型,将待转换的声音信号转换成与其内容对应的可视化信息,并将该可视化信息与现实场景融合显示,将声音可视化与mr混合现实技术结合起来,能够在现实场景中呈现可视化信息,在不影响听障人士的现实生活的前提下,还能够帮助听障人士感受周围环境的声音。
本发明的其它特征和优点将在随后的说明书中阐述,并且部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例共同用于解释本发明,并不构成对本发明的限制。在附图中:
图1示出了本发明实施例一声音可视化方法的流程图;
图2示出了本发明实施例二声音可视化方法的流程图;
图3示出了本发明实施例三声音可视化方法的流程图。
具体实施方式
以下将结合附图及实施例来详细说明本发明的实施方式,借此对本发明如何应用技术手段来解决技术问题,并达成技术效果的实现过程能充分理解并据以实施。需要说明的是,只要不构成冲突,本发明中的各个实施例以及各实施例中的各个特征可以相互结合,所形成的技术方案均在本发明的保护范围之内。
实施例一
为解决现有技术中存在的上述技术问题,本发明实施例提供了一种声音可视化方法,在本实施例中,按照音量大小从监测到的声音信号中筛选待转换的声音信号。
参照图1,本实施例的声音可视化方法,应用于mr混合现实设备,包括以下步骤:
s110,实时监测目标环境中的声音信号,其中,所述目标环境为mr混合现实设备所在环境;
s120,将监测到的声音信号与预存的多种参考声音进行对比,根据对比结果确定监测到的声音信号所属的类型;
s130,判断监测到的声音信号中是否存在音量超过预设阈值的声音信号:
若是,则执行步骤s140;
若否,则不予响应;
s140,将音量超过预设阈值的声音信号作为待转换的声音信号;
s150,根据监测到的声音信号的类型,将待转换的声音信号转换成与其内容对应的可视化信息,并将该可视化信息与现实场景融合显示。
在步骤s120中,预存的多种参考声音是根据每种声音的频率、振幅不一样,预先建立的声音库,例如,输入一段汽车鸣笛声,那么当获取到相似频率的声音时,就可以判定为是鸣笛声。
在步骤s150中,对于不同的监测到的声音信号的类型,声音信号的转换形式不同。具体如下:
当监测到的声音信号的类型为音乐时,将待转换的声音信号转换成带有歌词和/或带有音乐波形节奏跳动的视频。
当监测到的声音信号的类型为语言时,将待转换的声音信号转换成文字和/或手势。
当监测到的声音信号的类型为车辆鸣笛声时,将待转换的声音信号转换成表示不同危险等级的警告图像。
其中,所述危险等级通过以下步骤确定:
通过相邻两时刻下车辆的位置变化计算车辆的速度;
根据车辆的速度以及车辆与mr混合现实设备之间的距离确定车辆的危险等级。
具体地,计算车辆的速度时,类似行车测速仪,mr混合现实设备通过在某两个时刻利用动态图像追踪识别技术捕获同一行车的位置,根据距离与时间公式就可以计算出速度。测距原理可以参考iphone设备的测距仪。
本实施例的声音可视化方法按照音量大小从监测到的声音信号中筛选待转换的声音信号,将音量超过预设阈值的声音信号进行声音可视化,能够让用户用视觉感受到周围环境中跟自己相关的声音。
本实施例的声音可视化方法将音乐转换成带有歌词和/或带有音乐波形节奏跳动的视频,从而让用户用视觉感受音乐。
本实施例的声音可视化方法将语言转换成文字和/或手势,从而让用户用视觉感受语言。
本实施例的声音可视化方法将车辆鸣笛声转换成表示不同危险等级的警告图像,从而让用户用视觉感受车辆危险性。
本实施例的声音可视化方法根据车辆的速度以及车辆与用户之间的距离判断该车辆对用户的危险性,从而让用户根据车辆的危险性做出及时的反应。
本实施例的声音可视化方法利用mr混合现实技术将可视化信息与现实场景融合显示,能够利用mr混合现实技术帮助听障人士理解“声音”,为听障人士带来生活便利,帮助听障人士融入身边环境;弱化听障人士主观上的受歧视感,为他们的日常生活增添勇气。
实施例二
为解决现有技术中存在的上述技术问题,本发明实施例提供了一种声音可视化方法,在本实施例中,结合提示危险情况和音量大小从监测到的声音信号中筛选待转换的声音信号。
参照图2,本实施例的声音可视化方法,应用于mr混合现实设备,包括以下步骤:
s210,实时监测目标环境中的声音信号,其中,所述目标环境为mr混合现实设备所在环境;
s220,将监测到的声音信号与预存的多种参考声音进行对比,根据对比结果确定监测到的声音信号所属的类型;
s230,根据监测到的声音信号的类型,判断监测到的声音信号中是否存在用于提示危险情况的声音:
若是,则执行s240;
若否,则执行s250;
s240,将用于提示危险情况的声音作为待转换的声音信号;
s250,判断监测到的声音信号中是否存在音量超过预设阈值的声音信号:
若是,则执行步骤s260;
若否,则不予响应;
s260,将音量超过预设阈值的声音信号作为待转换的声音信号;
s270,根据监测到的声音信号的类型,将待转换的声音信号转换成与其内容对应的可视化信息,并将该可视化信息与现实场景融合显示。
在步骤s270中,对于不同的监测到的声音信号的类型,声音信号的转换形式不同。具体如下:
当监测到的声音信号的类型为音乐时,将待转换的声音信号转换成带有歌词和/或带有音乐波形节奏跳动的视频。
当监测到的声音信号的类型为语言时,将待转换的声音信号转换成文字和/或手势。
当监测到的声音信号的类型为车辆鸣笛声时,将待转换的声音信号转换成表示不同危险等级的警告图像。
其中,所述危险等级通过以下步骤确定:
通过相邻两时刻下车辆的位置变化计算车辆的速度;
根据车辆的速度以及车辆与mr混合现实设备之间的距离确定车辆的危险等级。
本实施例的声音可视化方法结合提示危险情况和音量大小从监测到的声音信号中筛选待转换的声音信号,先通过判断监测到的声音信号中是否是用于提示危险情况的声音,再根据监测到的声音信号的音量大小筛选出待转换的声音信号,从而实现优先呈现用于提示危险情况的声音,以保障用户的安全。
本实施例的声音可视化方法利用mr混合现实技术,将mr与语音输入、语音分析结合,将声音在听障人士的视野内可视化,帮助听障人士融入周边环境,对他人或者危急情况及时反应
实施例三
为解决现有技术中存在的上述技术问题,本发明实施例还提供了将实施例一的声音可视化方法应用于听障人士穿戴的mr混合现实设备的实例。
参照图3,本实施例的声音可视化方法,包括以下步骤:
s310,听障人士穿戴mr混合现实设备;
s320,mr混合现实设备接收到周围环境声音;
s330,智能判定声音类型,例如鸣笛声、语言和音乐等;
s340,结合多种技术(图像识别、语义分析等)将声音文字化或图形化,辅以动效,并呈现在mr混合现实设备穿戴者的视野范围内,与现实场景融合。
下面以具体应用场景描述本实施例的声音可视化方法。
场景一:听障人士a佩戴上mr穿戴设备,走在马路上,远方有一辆车高速驶来,并持续鸣笛。此时,mr穿戴设备捕捉到该鸣笛声,根据声音的持续情况,结合真实世界中行车位置及其位置变化情计算出其速度,以及其与a的实时距离,判断危险等级,并发出对应等级的危险警告:如此时行车速度较慢,鸣笛声短,且与a仍有一段距离,则危险等级判定为低等级,在a的视野中投射出颜色较淡、不阻挡主要实现的文字提示信息(亦可结合图形);反之,如果系统判定当前危险等级较高,则在a的视野中投射出颜色较重(如红色,或者运用对比色)的警示并闪烁,起到强提示的作用。
场景二:听障人士b佩戴mr穿戴设备走进一家餐厅,餐厅播放着轻松的音乐。mr穿戴设备捕捉到当前音乐的节奏、旋律,结合歌词内容(实时听译或者联网听歌识曲后搜索到歌词)在b的视野内生成与音乐节奏相呼应的动效,如跳动的音符、律动的光线等。当b坐下点餐时,服务员走来向他介绍菜品并点单,此时mr穿戴设备识别服务员所说内容并实时翻译出来,以文字+虚拟人物比划手语的形式展示在b的视野范围内。
本实施例的声音可视化方法在场景一中将汽车鸣笛声音可视化,将提示信息与现实场景结合,在眼前直接呈现,比起其他警报设备更能让听障人士第一时间获知并及时做出反应,为听障人士带来安全保障。
本实施例的声音可视化方法在场景二中将餐厅音乐可视化,让听障人士通过另一种感官感受到当前环境的氛围,同时,本实施例的声音可视化方法还能够帮助听障人士与他人更方便地沟通,为他的日常社会生活带来极大便利,有效地减弱了听障人士在主观上的受歧视感。
本实施例的声音可视化方法基于mr混合现实技术帮助听障人员实现声音可视化,仅需在目前的mr穿戴设备上置入语音模块,用于捕捉、分析环境声音、理解语义即可帮助听障人士感受周围环境的声音。
实施例四
为解决现有技术中存在的上述技术问题,本发明实施例还提供了一种声音可视化装置。
本实施例的声音可视化装置,应用于mr混合现实设备,包括:
监测模块,用于实时监测目标环境中的声音信号,其中,所述目标环境为mr混合现实设备所在环境;
确定模块,用于将监测到的声音信号与预存的多种参考声音进行对比,根据对比结果确定监测到的声音信号所属的类型;
筛选模块,用于从监测到的声音信号中筛选出待转换的声音信号;
转换模块,用于根据监测到的声音信号的类型将待转换的声音信号转换成与其内容对应的可视化信息,并将该可视化信息与现实场景融合显示。
其中,筛选模块,还用于从监测到的声音信号中筛选出音量超过预设阈值的声音信号,作为待转换的声音信号。
筛选模块,还用于根据监测到的声音信号的类型,判断监测到的声音信号中是否存在用于提示危险情况的声音;
当监测到的声音信号中存在用于提示危险情况的声音时,将用于提示危险情况的声音作为待转换的声音信号;
当监测到的声音信号中不存在用于提示危险情况的声音时,从监测到的声音信号中筛选出音量超过预设阈值的声音信号,作为待转换的声音信号。
在转换模块中,当监测到的声音信号的类型为音乐时,可视化信息为带有歌词和/或带有音乐波形节奏跳动的视频。
在转换模块中,当监测到的声音信号的类型为语言时,可视化信息为文字和/或手势。
在转换模块中,当监测到的声音信号的类型为车辆鸣笛声时,可视化信息为表示不同危险等级的警告图像。
在转换模块中,所述危险等级通过以下步骤确定:
通过相邻两时刻下车辆的位置变化计算车辆的速度;
根据车辆的速度以及车辆与mr混合现实设备之间的距离确定车辆的危险等级。
本实施例的声音可视化装置将声音可视化与mr混合现实技术结合起来,通过mr混合现实技术将可视化信息与现实场景融合呈现出来,当供听障人士观看时,能够在不影响听障人士的现实生活的前提下,帮助听障人士感受周围环境的声音,方便听障人士更好地适应周围环境。
实施例五
为解决现有技术中存在的上述技术问题,本发明实施例还提供了一种存储介质。
本实施例的存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述实施例中方法的步骤。
实施例六
为解决现有技术中存在的上述技术问题,本发明实施例还提供了一种mr混合现实设备。
本实施例的mr混合现实设备,其包括存储介质和处理器,该存储器上存储有计算机程序,该计算机程序被处理器执行时实现上述方法的步骤。
虽然本发明所公开的实施方式如上,但所述的内容只是为了便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属技术领域内的技术人员,在不脱离本发明所公开的精神和范围的前提下,可以在实施的形式上及细节上作任何的修改与变化,但本发明的保护范围,仍须以所附的权利要求书所界定的范围为准。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



