
 商标分类
商标分类  商标转让
商标转让 
基于多头注意力机制的语音情感识别方法与流程
 2021-01-28 12:01:24|
2021-01-28 12:01:24| 303|
303| 起点商标网
起点商标网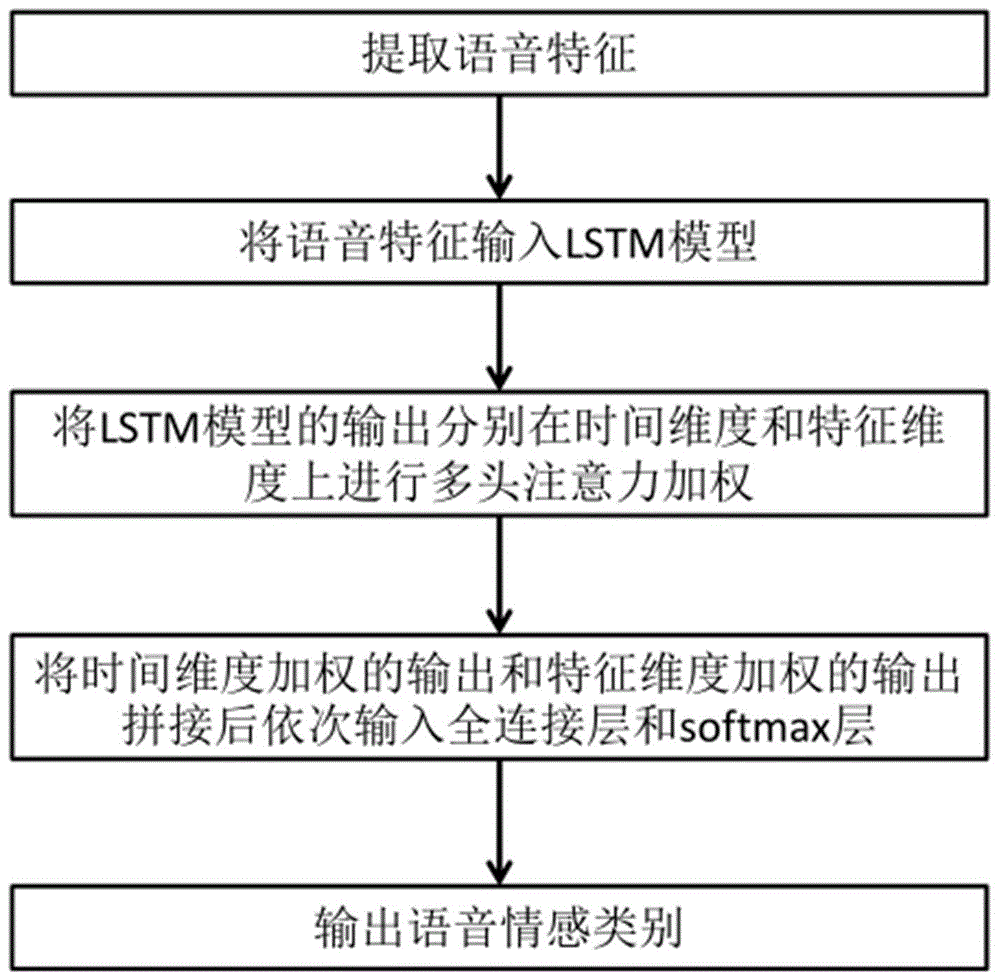
本发明涉及语音情感识别
技术领域:
,特别涉及一种基于多头注意力机制的语音情感识别方法。
背景技术:
:近年来,语音情感识别(ser)受到越来越多的关注,因为它在人机交互中具有很大的实用价值。随着深度学习的发展,不同结构的神经网络已经被研究用于ser。例如,长短期记忆(lstm)是递归神经网络(rnn)的一种变体,它可以建模和存储较长的时间信息,这使得它在ser上取得了良好的分类性能。在lstm的大多数应用中,选择其最后一个时间步长的输出作为最终分类器的输入。在这个框架下,lstm作为特征提取器,由于长程的时间跨度不是无限的,所以最后一个时间步提取的特征信息可能不够充分。因此,计算机视觉领域的一些研究者装备了具有注意力机制的卷积神经网络,能够自动学习到图像中哪一部分对最终性能更重要。同时,bahdanau在基于lstm的端对端中引入了注意力机制,在机器翻译领域取得了显著的改进。在情绪识别任务方面,tao运用注意力机制更新lstm的细胞状态,关注细胞之间的信息,考虑了更多的历史的细胞状态。mirsamadi提出了局部注意来计算带有注意参数向量的帧的权值。传统的缩放点注意力算法执行单一的注意函数,具有一定的片面性;而多头注意力机制相比于传统的单头注意力机制,将注意向量以不同的线性投影映射到多个新的子空间,使模型能够在不同位置联合关注来自不同特征子空间的信息,可以有效减少片面性。技术实现要素:发明目的:针对现有技术中存在的问题,本发明公开了一种基于多头注意力机制的语音情感识别方法,用多头注意力机制替代传统的缩放点注意力机制,对lstm的历史输出和最后时刻的输出在时间维度进行注意力加权,区分不同时间片段内情感的饱和度,并将多头注意力机制拓展至特征维度,区分不同特征对情感的识别能力,提高语音情感识别的性能。技术方案:本发明采用如下技术方案:一种基于多头注意力机制的语音情感识别方法,其特征在于,包括以下步骤:s1、从原始语音数据样本中提取具有时序信息的帧级语音特征;s2、建立具有处理时序数据能力的lstm模型,将步骤s1中具有时序信息的语音特征输入lstm模型;s3、利用多头注意力机制对lstm模型的输出在时间维度上进行注意力加权,结合lstm模型所有时刻输出的矩阵和最后时刻的输出,得到时间维度加权后的输出;s4、利用多头注意力机制对lstm模型的输出在特征维度上进行注意力加权,结合lstm模型所有时刻输出的矩阵,得到特征维度加权后的输出;s5、将时间维度加权后的输出和特征维度加权后的输出拼接后输入全连接层,再经过softmax层得到语音情感类别;s6、用已知的原始语音数据样本及其语音情感类别对如步骤s1至s5中所述的情感识别模型进行训练,并对训练好的情感识别模型进行测试验证,评测识别性能;s7、将未知的原始语音数据样本输入训练好的情感识别模型,输出对应的语音情感类别。优选地,步骤s3中利用多头注意力机制对lstm模型的输出在时间维度上进行注意力加权,包括如下步骤:s31、计算lstm模型所有时刻输出的矩阵和最后时刻的输出分别在每个线性子空间中的投影:t_ki=oall_time*t_wi,k+t_bi,kt_qi=omax_time*t_wi,q+t_bi,q其中,*表示矩阵乘法;oall_time表示lstm模型所有时刻输出的矩阵,omax_time表示lstm模型最后时刻的输出;和分别表示oall_time和omax_time在第i个线性子空间线性变换中的权重,i表示线性子空间的索引,共计有h个线性子空间,n表示lstm模型的隐层单元数量;t_bi,k和t_bi,q分别表示oall_time和omax_time在第i个线性子空间线性变换中的偏置;t_ki和t_qi分别表示oall_time和omax_time在第i个线性子空间中的投影;s32、计算每个线性子空间中时间维度的加权系数:t_scorei=softmax(t_qi*t_kih)其中,t_scorei表示第i个线性子空间中时间维度的加权系数,softmax()表示归一化指数函数;s33、计算每个线性子空间中待加权的值:t_vi=oall_time*t_wi,v+t_bi,v其中,t_vi表示第i个线性子空间中待加权的值;t_wi,v表示第i个线性子空间求待加权的值时的权重;t_bi,v表示第i个线性子空间求待加权的值时的偏置;s34、计算每个线性子空间的输出,并将所有线性子空间的输出拼接在一起,得到时间维度加权后的输出:t_outputi=t_scorei*t_vit_output=concat(t_output1,...,t_outputh)其中,concat()用于连接两个或多个数组;t_outputi表示第i个线性子空间的输出;t_output表示时间维度加权后的输出。优选地,步骤s4中利用多头注意力机制对lstm模型的输出在特征维度上进行注意力加权,包括如下步骤:s41、计算lstm模型所有时刻输出的矩阵和最后时刻的输出分别在每个线性子空间中的投影:f_ki=oall_time*f_wi,k+f_bi,k其中,*表示矩阵乘法;oall_time表示lstm模型所有时刻输出的矩阵;f_wi,k表示oall_time在第i个线性子空间线性变换中的权重;f_bi,k表示在第i个线性子空间线性变换中的偏置;f_ki表示oall_time在第i个线性子空间中的投影;s42、计算每个线性子空间中特征维度的加权系数:f_scorei=softmax(tanh(f_ki)*f_wscore+f_bscore)其中,f_scorei表示第i个线性子空间中特征维度的加权系数,采用了自注意力算法获取,f_wscore与f_bscore分别表示自注意力算法的权重与偏置;softmax()表示归一化指数函数;s43、计算每个线性子空间中待加权的值:f_vi=oall_time*f_wi,v+f_bi,v其中,f_vi表示第i个线性子空间中待加权的值;f_wi,v表示第i个线性子空间求待加权的值时的权重;f_bi,v表示第i个线性子空间求待加权的值时的偏置;s44、计算每个线性子空间的输出,并将所有线性子空间的输出拼接在一起,在时间维度上求和,得到特征维度加权后的输出:其中,表示hadamard乘积;concat()用于连接两个或多个数组;f_outputi表示第i个线性子空间的输出;f_output表示特征维度加权后的输出。优选地,步骤s2中,lstm模型的计算方法如下:ft=σ(wfh*ht-1+wfx*xt+wfc*ct-1+bf)it=σ(wih*ht-1+wix*xt+wic*ct-1+bi)ot=σ(woh*ht-1+wox*xt+woc*ct+bo)其中,*表示矩阵乘法,表示hadamard乘积;wfh、wfc、wfx分别为遗忘门ft的隐层输出、细胞状态与输入的权值,bf为遗忘门ft的偏置;wih、wic、wix分别为信息更新值it的隐层输出、细胞状态与输入的权值,bi为信息更新值it的偏置;wch、wcx分别为细胞状态更新值的隐层输出与输入的权值,bc为细胞状态更新值的偏置;woh、wox、woc分别为输出值ot的隐层输出、输入与细胞状态的权值,bo为输出值ot的偏置;ht、xt、ct分别表示t时刻的隐层输出、输入与细胞状态。优选地,步骤s5中,全连接层的输入为concat(t_output,f_output),其中t_output表示时间维度加权后的输出,f_output表示特征维度加权后的输出。优选地,步骤s6中,用召回率对情感识别模型进行测试验证:其中,recall为召回率;tp是预测为正,实际为正的数量;tn是预测为负,实际为正的数量。优选地:步骤s1中,提取的语音特征通过语音帧之间的序列关系保留了原始语音数据样本中的时序信息,且语音特征的维度随原始语音数据样本的实际长度而变化。有益效果:本发明具有如下有益效果:本发明的基于多头注意力机制的语音情感识别方法,通过多头注意力机制替代传统缩放点注意力机制,结合lstm模型的历史输出和最后一刻的输出,对lstm模型输出的时间维度进行注意力加权,区分不同时间片段内,情感的饱和度;并将多头注意力机制拓展至特征维度,区分不同特征对情感的识别能力,可以提高语音情感识别的性能,具有良好的应用前景。附图说明图1为本发明的基于多头注意力机制的语音情感识别方法的方法流程图;图2是本发明的基于多头注意力机制的语音情感识别方法的系统框图;图3是验证在时间维度上,enterface和gemep数据库上的性能随子空间数量的变化曲线;图4是验证在特征维度上,enterface和gemep数据库上的性能随子空间数量的变化曲线。具体实施方式下面结合附图对本发明作更进一步的说明。本发明公开了一种基于多头注意力机制的语音情感识别方法,如图1和图2所示,包括如下步骤:步骤a、从原始语音数据中提取具有时序信息的帧级语音特征,其中,该语音特征通过语音帧之间的序列关系保留了原始语音数据中的时序信息,且该语音特征的维度是随原始语音数据的实际长度而变化的。详细的语音特征集合如下表1所示:表1步骤b、建立具有处理时序数据能力的长短时记忆(lstm)模型,通过细胞单元记忆历史信息,通过遗忘门对历史冗余信息进行筛选,解决了长程依赖问题,适用于步骤a中所提出的动态的语音特征,即模型能够与特征数据相匹配。lstm模型计算方法如下,其中,*表示矩阵乘法:ft=σ(wfh*ht-1+wfx*xt+wfc*ct-1+bf)(1)其中,wfh、wfc、wfx分别为遗忘门ft的隐层输出、细胞状态与输入的权值,bf为遗忘门ft的偏置,wfh、wfc、wfx和bf均为待训练的参数;遗忘门ft受上一时刻的细胞状态ct-1、隐层输出ht-1和当前时刻的输入xt的影响,表达了对历史信息的保留程度。it=σ(wih*ht-1+wix*xt+wic*ct-1+bi)(2)其中,wih、wic、wix分别为信息更新值it的隐层输出、细胞状态与输入的权值,bi为信息更新值it的偏置,wih、wic、wix和bi均为待训练的参数;信息更新值it受上一时刻的细胞状态ct-1、隐层输出ht-1和当前时刻的输入xt的影响,决定了当前的有效信息量。ot=σ(woh*ht-1+wox*xt+woc*ct+bo)(5)其中,表示hadamard乘积,wch、wcx分别为细胞状态更新值的隐层输出与输入的权值,bc为细胞状态更新值的偏置,wch、wcx和bc均为待训练的参数,细胞状态更新值受上一时刻的隐层输出ht-1和当前时刻的输入xt的影响;当前时刻的细胞状态ct受上一时刻的细胞状态ct-1和细胞状态更新值的影响;woh、wox、woc分别为输出值ot的隐层输出、输入与细胞状态的权值,bo为输出值ot的偏置,woh、wox、woc和bo均为待训练的参数,输出值ot受上一时刻的隐层输出ht-1和当前时刻的细胞状态ct、输入xt的影响。其中,当前时刻的隐层输出ht受当前时刻的细胞状态ct和输出值ot的影响。公式(1)至公式(6)中,下标t为时间步,对应语音特征中的帧数;σ是sigmoid函数,表示式为:σ(x)=1/(1+e-x),取值在0到1之间,表达了一种分数加权的概念。步骤c、用多头注意力机制替代传统的缩放点注意力机制,对lstm模型输出的时间维度进行注意力加权,区分不同时间片段内,情感的饱和度。多头注意力机制避免了传统缩放点注意力机制的单次线性映射的片面性,“多头”是指多次线性变化,可获得更加强健的信息表示。其计算公式如下:t_ki=oall_time*t_wi,k+t_bi,k(7)t_qi=omax_time*t_wi,q+t_bi,q(8)其中,是线性变换中的权重,t_bi,k和t_bi,q则是线性变换中的偏置,t_wi,k、t_wi,q、t_bi,k和t_bi,q均为待训练的参数,i表示线性子空间的索引,共计有h个线性子空间,n对应lstm模型的隐层单元数量;oall_time是lstm模型在所有时刻输出的矩阵,omax_time则是lstm模型在最后一刻的输出。由于lstm模型对历史信息的累计特性,使其在最后一刻具有相对较多的有效信息,所以本发明将omax_time作为参考量来衡量其他时刻的信息有效性;而t_ki和t_qi分别是oall_time与omax_time在第i个线性子空间中的投影。t_scorei=softmax(t_qi*t_kih)(9)t_vi=oall_time*t_wi,v+t_bi,v(10)t_outputi=t_scorei*t_vi(11)其中,softmax()表示归一化指数函数;t_scorei是第i个线性子空间中时间维度的加权系数;待加权的值是oall_time在第i个线性子空间下的新的投影t_vi,该投影是以t_wi,v为权重,t_bi,v为偏置的新的线性变换,t_wi,v和t_bi,v均为待训练的参数;将t_scorei作用于t_vi,获得各个线性子空间对应的输出t_outputi;最后将所有线性子空间的输出t_outputi拼接在一起,形成全新的输出t_output:t_output=concat(t_output1,...,t_outputh)(12)其中,concat()用于连接两个或多个数组。步骤d、将多头注意力机制拓展至特征维度,对lstm模型的输出在特征维度上进行注意力加权,区分不同特征对情感的识别能力。不同特征对情感识别的能力是有差异的,通过多头注意力机制的加权系数自动筛选出与情感识别任务密切相关的深层特征,以提高情感识别性能。其计算方法如下:f_ki=oall_time*f_wi,k+f_bi,k(13)f_scorei=softmax(tanh(f_ki)*f_wscore+f_bscore)(14)f_vi=oall_time*f_wi,v+f_bi,v(15)其中,f_wi,k和f_bi,k分别是oall_time线性变化的权重与偏置,f_wi,k和f_bi,k均为待训练的参数,f_ki是oall_time在第i个线性子空间中的投影;f_scorei是第i个线性子空间中特征维度的加权系数,采用了自注意力算法获取,f_wscore与f_bscore是自注意力算法中待训练的权重与偏置;与时间维度的加权类似,特征维度上待加权的值是oall_time在第i个线性子空间下的新的投影f_vi,该投影是以f_wi,v为权重,f_bi,v为偏置的新的线性变换,f_wi,v和f_bi,v均为待训练的参数;将f_scorei作用于f_vi,获得各个线性子空间对应的输出f_outputi,与时间维度不同的是,加权系数f_scorei与f_vi之间是hadamard乘积;最终的输出f_output是将各个线性子空间的输出f_outputi拼接,并在时间维度上求和,此时的求和与传统静态统计有异曲同工之处,不过此处的权值系数是训练获得的,而非人工设计的:步骤e、在lstm模型后添加全连接层与softmax层,其中将上述时间维度的加权结果与特征维度的加权结果的拼接,即concat(t_output,f_output)作为全连接层的输入,再将全连接层的输出输入softmax层进行归一化后,输出属于每种语音情感类别的概率,概率最大的即为最终的语音情感类别。步骤f、将已知的原始语音数据样本及其语音情感类别对如步骤a至e中所述的情感识别模型;训练情感识别模型,并对训练好的情感识别模型的识别性能进行评测;将未知的原始语音数据样本输入训练好的情感识别模型,输出对应的语音情感类别。为评价模型性能,本发明通过情感识别中常用的召回率(recall)对比了传统缩放点注意力机制算法,总体评价指标为无加权平均召回率(unweightedaveragerecall,uar)。其中,tp是预测为正,实际为正的数量;tn是预测为负,实际为正的数量。为验证本发明的有效性,在enterface和gemep两个情感数据库上进行了测试,测试结果如下表2和表3所示,其中,表2为lstm模型、lstm模型结合缩放点注意力机制以及lstm模型结合多头注意力机制在enterface数据库上的实验结果,表3为lstm模型、lstm模型结合缩放点注意力机制以及lstm模型结合多头注意力机制在gemep数据库上的实验结果。如表2所示,在enterface数据库上,本发明的lstm模型结合多头注意力机制的uar达到91.2%,超过其他模型。与缩放点注意力机制相比,本发明的大部分情绪的回忆都得到了提高,说明多线性子空间比单一注意函数能获得更稳健的情绪信息。如表3所示,在gemep数据库上,本发明的lstm模型结合多头注意力机制取得了最好的结果,uar达到了62%。对于召回率在60%以上的最容易被识别的情绪,与表中其他模型相比,多头注意力能取得明显的改善。表2模型生气厌恶害怕高兴伤心惊讶uarlstm88.4%64.3%76.6%83.8%68.9%73.9%75.8%lstm+缩放点注意力88.4%85.7%80.9%97.3%86.7%84.8%86.9%lstm+多头注意力90.7%90.5%87.2%94.6%93.3%91.3%91.2%表3为了分别研究注意力机制的头数在时间维数和特征维数上对性能的影响,实验首先将特征维度的头数设为固定参数1,研究时间维度与uar的关系,如图3所示:uar会随着gemep数据库和enterface数据库上时间维度头数的增加而逐渐增加,当头数为8时,uar在gemep数据库和enterface数据库上分别达到最大的58%和91.2%,这说明多个线性子空间可以形成互补关系,增强情感信息的健全性,防止单子空间的片面性。然而,这种正相关是有边界的,当头数超过8时,uar会下降,更多的头数意味着需要学习的线性子空间更多,这会增加网络的学习负担,特别是在训练数据有限的情况下。在此基础上,将时间维度的头数固定为8,研究特征维度的头数对uar的影响,如图4所示:在gemep数据库上,uar随特征维度头数的增大而增大,直到头数为16时,uar达到最大的62%,之后头数再增加时,uar会下降。相反,在enterface数据库上,uar随着特征维度头数的上升而下降。这可能是由于两个数据库中情绪识别任务的复杂性造成的。gemep数据库的情感分类是enterface数据库的两倍,所以前者更复杂。而情绪类别越多,特征空间中情绪信息交织越严重,识别的难度也越大。多线性子空间可以更好地缓解情感特征的重叠,提高性能。对于只有6种情绪的enterface数据库来说,情绪之间的重叠较少,因此,线性子空间的增加只会增加训练的难度,对性能产生原生的影响。因此,gemep数据库在时间维度头数为8、特征维度头数为16时能达到最佳的uar,而enterface数据库在时间维度头数为8、特征维度头数为1时能达到最佳的uar。以上所述仅是本发明的优选实施方式,应当指出:对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips