
 商标分类
商标分类  商标转让
商标转让 
一种基于BNEP协议实现蓝牙音频设备语音识别训练的系统及其方法与流程
 2021-01-28 12:01:28|
2021-01-28 12:01:28| 313|
313| 起点商标网
起点商标网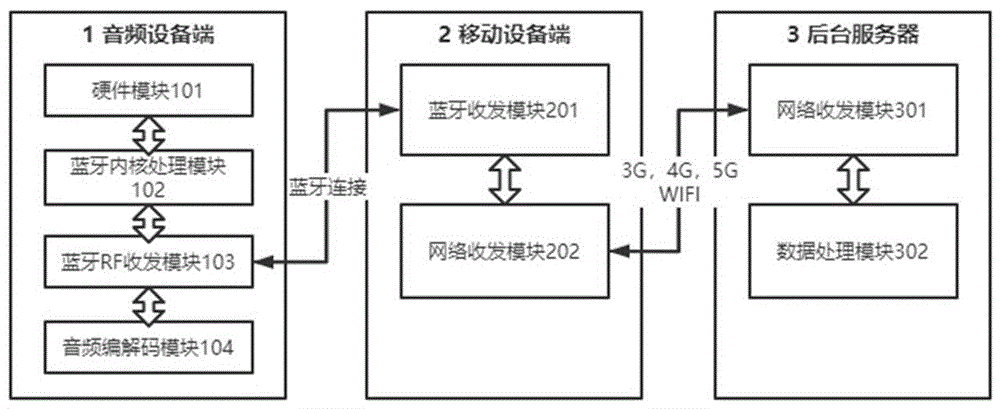
本发明属于通信技术领域,具体为一种基于bnep协议实现蓝牙音频设备语音识别训练的系统及其方法。
背景技术:
现有技术,一般通过蓝牙音频设备配置的语音识别模块及安装运行在移动终端的语音训练软件,蓝牙音频设备采集语音训练指令,移动终端的软件对语音进行识别并响应训练指令,将识别结果反馈后获得软件的结果分析,根据结果分析来确认语音识别的训练结果对错。其存在以下缺陷:软件端的训练数据库需要不断迭代数据以保证识别比对功能正常;由软件端比对训练数据,速度较慢、识别质量较低;下载软件占用用户移动终端的内存资源,数据库内容越多占用的内存资源越多;不同的移动终端存在的软件兼容性问题。
技术实现要素:
针对现有技术中存在的上述问题,本发明的目的在于设计提供一种基于bnep协议实现蓝牙音频设备语音识别训练的系统及其方法的技术方案,通过bnep的方法,用户终端设备无需下载app,仅需要连接网络就可以实现使用后台服务器数据库比对语音训练结果,实现蓝牙耳机语音识别训练;极大的提升用户的操作便利性、节约用户的内存资源、提高训练速度与训练质量。
所述的一种基于bnep协议实现蓝牙音频设备语音识别训练的系统,其特征在于包括音频设备端、移动设备端、后台服务器,音频设备端中设置硬件模块、蓝牙内核处理模块、蓝牙rf收发模块、音频编解码模块,移动设备端中设置蓝牙收发模块、网络收发模块,后台服务器中设置网络收发模块、数据处理模块;
所述音频设备端的硬件模块包括按键、led灯、喇叭、麦克风;蓝牙内核处理模块用于音频设备端的软硬件;蓝牙rf收发模块用于建立与移动设备端或音频设备端的连接及数据传输;音频编解码模块用于编解输入输出的音频信号。
所述移动设备端的蓝牙收发模块用于建立与音频设备端的连接及数据传输;网络收发模块用于连接3g、4g、5g、wifi或有线网络。
所述后台服务器的网络收发模块用于连接wifi或有线网络以实现与移动设备端的网络数据传输;数据处理模块用于接收解析回传从移动设备端处接收到的数据信息。
所述的一种基于bnep协议实现蓝牙音频设备语音识别训练的系统,其特征在于所述移动设备端与后台服务器的连接网络为3g、4g、5g或wifi,所述音频设备端为蓝牙耳机,所述移动设备端为手机。
所述的一种基于bnep协议实现蓝牙音频设备语音识别训练的系统的方法,其特征在于包括以下步骤:
1)音频设备端与后台服务器连接过程:音频设备端与移动设备端进行连接,通过bnep协议,移动设备端通过连接网络连接到后台服务器,以实现音频设备端与后台服务器的连接;
2)音频设备端与后台服务器语音数据解析的实现:音频设备端通过蓝牙bnep协议,通过移动设备端连接网络与后台服务器实现连接后就可进行数据流的交互;
3)音频设备端接收输入的语音信号后可主动发起训练请求,开启语音训练模式;
4)通过音频设备端传输给移动设备端后连接后台服务器数据库进行训练结果比对;
5)解析完成后,后台服务器通过网络下发对比数据返还至移动设备端;
6)移动设备端收到对比数据后可在终端显示训练结果。
所述的一种基于bnep协议实现蓝牙音频设备语音识别训练的系统的方法,特征在于语音识别训练方法包括:音频设备端将adc原始音频数据通过bnep直接发送到后台服务器,采用ctc算法进行语音识别训练,算法的实现如下:
训练集合为
对于其中一个样本(x,z),
特征x在经过rnn的计算之后,在经过一个softmax层,得到音素的后验概率y,
这个语音识别训练的过程可以看做是对输入的特征数据x做了变换nw:
所述的一种基于bnep协议实现蓝牙音频设备语音识别训练的系统的方法,其特征在于:
音频设备端、移动设备端蓝牙配对选择numericcomparison的方式,即双方都显示一个6位的数字,由用户来核对数字是否一致,并输入yes/no,两端yes表示一致即可配对,可以防止中间人攻击;加密过程算法采用e0算法,在e0算法中,加密密钥kc被修改为实际加密密钥kc′,kc′可在1-16字节间变化,但其最大有效长度由厂商预置;增加kc′的长度有利于增强安全性,当前64位加密密钥已足以满足大多数用户的安全要求;
蓝牙加密e0算法的主要作用是生成二进制密码流kcipher,蓝牙密码流生成系统使用了4个线性移位寄存器,每个lfsr的输出为一个16状态的简单有限状态机的组合,该状态机的输出为字节流序列,或是初始化阶段的随机初始值,四个寄存器的长度分别为:l1=25,l2=31,l3=33,l4=39,总长度为128位。
所述的一种基于bnep协议实现蓝牙音频设备语音识别训练的系统的方法,其特征在于步骤1)中:
音频设备端为从机,移动设备端蓝牙为主机;
从机端开机并开始广播,主机端打开蓝牙后会扫描蓝牙设备,从机被扫描到会回复主机;
主机端点击连接,从机端收到主机端的连接要求后回发出安全请求要求主机端进行配对,主机端收到从机要求配对的广播包后,就会发起配对请求;
从机收到主机的配对请求后,会回复主机同意配对;主机和从机就会进行信息传输并生成配对秘钥;
秘钥生成后主机和从机保存配对信息,配对完成。
上述一种基于bnep协议实现蓝牙音频设备语音识别训练的系统及其方法,简化语音训练的流程,用移动设备端无需下载app,不占用用户设备的内存资源;直接连接服务器数据库,无需用升级设备端数据库;数据传输效率高;语音训练速度与训练质量提高。
附图说明
图1为本发明的系统结构方框图;
图2为本发明的系统示意图;
图3为本发明的实现流程图;
图4为本发明蓝牙耳机与手机蓝牙配对流程图;
图中:1-音频设备端、101-硬件模块、102-蓝牙内核处理模块、103-蓝牙rf收发模块、104-音频编解码模块;2-移动设备端、201-蓝牙收发模块、202-网络收发模块;3-后台服务器、301-服务器网络收发模块、302-数据处理模块。
具体实施方式
以下结合附图及具体实施例,对本发明作进一步的详细说明。
bnep全称为bluetoothnetworkencapsulationprotocol(网络封装协议,以下简称bnep)。bnep是针对pan应用设计的,它提供了构建蓝牙无线局域网的一种应用模型,bnep能完成从ip层到l2cap层的映射网络协议层次。蓝牙个人局域网就是利用bnep为蓝牙设备提供组网能力,使两个或者多个蓝牙设备组成一个临时自组织网(groupad-hocnetwork,gn),或通过网络接入点(networkaccesspoint,nap)访问远程网络。bnep提供蓝牙协议栈和tcp/ip协议栈的转换,和ieee802.3以太网封装支持同样的上层网络协议。bnep净荷区的mtu定位1691个字节,可以保证网络层向下发送的以太层封包一次性传送。在数据传递方面,bnep直接接收ip层向下发送的以太网封包,并将以太网净荷区直接复制到bnep净荷区,加上bnep头部之后发送到l2cap层。
本发明所述的一种基于bnep协议实现蓝牙音频设备语音识别训练的系统,包括音频设备端1、移动设备端2、后台服务器3,音频设备端1中设置硬件模块101、蓝牙内核处理模块102、蓝牙rf收发模块103、音频编解码模块104,移动设备端2中设置蓝牙收发模块201、网络收发模块202,后台服务器3中设置服务器网络收发模块301、数据处理模块302;
所述音频设备端1的硬件模块101包括按键、led灯、喇叭、麦克风;蓝牙内核处理模块102用于音频设备端1的软硬件;蓝牙rf收发模块103用于建立与移动设备端2或音频设备端1的连接及数据传输;音频编解码模块104用于编解输入输出的音频信号。
所述移动设备端2的蓝牙收发模块201用于建立与音频设备端1的连接及数据传输;网络收发模块202用于连接3g、4g、5g、wifi或有线网络。
所述后台服务器3的服务器网络收发模块301用于连接wifi或有线网络以实现与移动设备端2的网络数据传输;数据处理模块302用于接收解析回传从移动设备端2处接收到的数据信息。
所述的一种基于bnep协议实现蓝牙音频设备语音识别训练的系统,其特征在于所述移动设备端2与后台服务器3的连接网络为3g、4g、5g或wifi,所述音频设备端1为蓝牙耳机,所述移动设备端2为手机。
所述的一种基于bnep协议实现蓝牙音频设备语音识别训练的系统的方法,包括以下步骤:
1)音频设备端1与后台服务器3连接过程:音频设备端1与移动设备端2进行连接,通过bnep协议,移动设备端2通过连接网络连接到后台服务器3,以实现音频设备端1与后台服务器3的连接;在步骤1)中:音频设备端1为从机,移动设备端2蓝牙为主机;从机端开机并开始广播,主机端打开蓝牙后会扫描蓝牙设备,从机被扫描到会回复主机;主机端点击连接,从机端收到主机端的连接要求后回发出安全请求要求主机端进行配对,主机端收到从机要求配对的广播包后,就会发起配对请求;从机收到主机的配对请求后,会回复主机同意配对;主机和从机就会进行信息传输并生成配对秘钥;秘钥生成后主机和从机保存配对信息,配对完成;
2)音频设备端1与后台服务器3语音数据解析的实现:音频设备端1通过蓝牙bnep协议,通过移动设备端2连接网络与后台服务器3实现连接后就可进行数据流的交互;
3)音频设备端1接收输入的语音信号后可主动发起训练请求,开启语音训练模式;
4)通过音频设备端1传输给移动设备端2后连接后台服务器3数据库进行训练结果比对;
5)解析完成后,后台服务器3通过网络下发对比数据返还至移动设备端2;
6)移动设备端2收到对比数据后可在终端显示训练结果。
本发明所述的语音识别训练方法包括:音频设备端1将adc原始音频数据通过bnep直接发送到后台服务器3;另外,本发明采用ctc(connectionisttemporalclassification)算法进行语音识别训练,算法的实现如下:
训练集合为s={(x1,z1),(x2,z2),...(xn,zn)},表示有n个训练样本,x是输入样本,z是对应的真实输出的label,一个样本的输入是一个序列,输出的label也是一个序列,输入的序列长度大于输出的序列长度;
对于其中一个样本(x,z),x=(x1,x2,x3,…xt)表示一个长度为t帧的数据,每一帧的数据是一个维度为m的向量,即每个xi∈rm,xi可以理解为对于一段语音,每25ms作为一帧,其中第i帧的数据经过mfcc计算后得到的结果;
z=(z1,z2,z3,…zu)表示这段样本语音对应的正确的音素,一段语音,经过mfcc计算后,得到特征x,对应的音素信息是z;
特征x在经过rnn的计算之后,在经过一个softmax层,得到音素的后验概率y。
所述的音频设备端1、移动设备端2蓝牙配对选择numericcomparison的方式,即双方都显示一个6位的数字,由用户来核对数字是否一致,并输入yes/no,两端yes表示一致即可配对,可以防止中间人攻击;加密过程算法采用e0算法,在e0算法中,加密密钥kc被修改为实际加密密钥kc′,kc′可在1-16字节间变化,但其最大有效长度由厂商预置;增加kc′的长度有利于增强安全性,当前64位加密密钥已足以满足大多数用户的安全要求;蓝牙加密e0算法的主要作用是生成二进制密码流kcipher,蓝牙密码流生成系统使用了4个线性移位寄存器,每个lfsr的输出为一个16状态的简单有限状态机的组合,该状态机的输出为字节流序列,或是初始化阶段的随机初始值,四个寄存器的长度分别为:l1=25,l2=31,l3=33,l4=39,总长度为128位。
实际系统中,如果要求手机实时运行一个应用在绝大多数场景下该应用都会被系统强制停止,而离线语音识别在音频设备这类有限资源设备上实现会占用设备大量资源,不仅提升了设备的计算成本也提升了设备功耗。通过bnep可以确保设备和服务器一直保持连接,不用担心手机兼容性导致的app被系统强制停止。考虑到实际使用过程中,如果音频设备端1持续不断上传音频数据到后台服务器3将极大增加系统功耗,可以通过bnep预先完成语音识别训练,实现针对于个人的关键字识别离线处理功能。当用户触发了预设的关键字,本地识别到特定条件后,就启动后台服务器3的实时语音识别功能,而后借助于后台服务器3强大的数据运算能力,完成高效语音识别服务,包括不限于询问天气,订购机票,聊天,语音控制等行为。
目前主流的手机系统集成有bnepprofile,按照蓝牙规范,在音频设备端1实现bnepprofile,而后音频设备端1和移动设备端2建立链接,通过bnep音频设备就可以通过移动设备端2的无线网络直接与后台服务器3进行通信,至此音频设备端1和后台服务器3就可以实现双向通信。音频设备端1可以借助后台服务器3强大计算资源实现本地关键字识别的训练,同时也可以实现语音实时识别,进一步实现智能语音服务。考虑到音频设备端1计算资源有限,而一直开启后台服务器3的音频实时识别算法又大大浪费系统算例。在音频设备端1仅仅是实现关键字识别算法所需的算力并不是太高,考虑到不同用户对关键字的定制化需求,可以通过bnep实现关键字识别模型的训练功能,由后台服务器3针对个人需要实现识别模型,而后部署在音频设备端1,可以避免音频设备端1关键字有限,且特定关键字识别率不高的问题。音频设备端1部署好训练好的音频识别模型后,当触发关键字后,可通过bnep开启语音实时识别行为,之后就借助于后台服务器3的算力就可以完成丰富的智能语音服务。bnep是蓝牙标准协议,基于bnep能够完成音频设备端1与后台服务器3的直接通信。一般而言通话系统对音频传输的速率要求只需要8kmono16bit,也就是128kbps,同时也可以承载高清语音通话需要。bnep的数据吞吐量足够满足音频识别音频传输需要。所设计的语音识别训练系统是基于bnep协议的,主要完成语音识别服务和语音训练服务。
下面对本发明所描述的语音识别训练系统的主要业务行为进行说明:
语音训练服务,该服务主要完成用户关键字的离线识别训练需要,所训练的关键字模型可部署在音频设备端1,之后音频设备端1可以利用自身有限的算力完成特定关键字的识别;通过语音训练功能,可以有效避免固定关键字模型识别率不高的问题。语音识别服务,当音频设备端1触发了关键字行为后,音频设备端1会和后台服务器3开启语音识别服务需要,这时用户可以直接利用服务器的算力体验到高质量的智能语音服务。从上述方案可知,相比于传统关键字识别系统,本发明可以通过在线训练来完成针对特定用于的关键字识别训练,训练结果针对性强,识别效率高。相比于手机安装的语音识别软件,可以无需用户额外安装应用,只需要有音频设备端1就可以实现网络通话功能,避免用户安装一堆无用的app。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这些仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式作出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



