
 商标分类
商标分类  商标转让
商标转让 
一种基于人工智能的多模态语义识别服务接入方法与流程
 2021-01-28 12:01:16|
2021-01-28 12:01:16| 311|
311| 起点商标网
起点商标网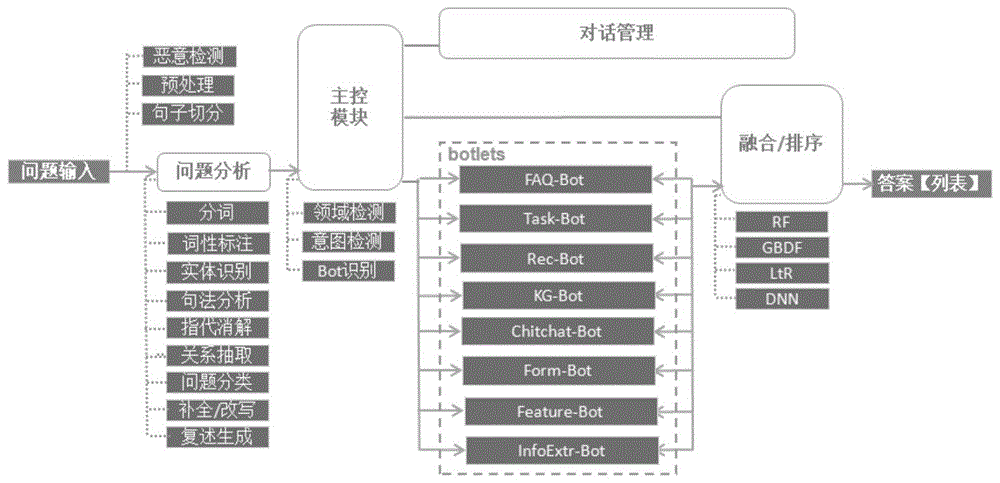
本发明涉及语义识别领域,特别涉及一种基于人工智能的多模态语义识别服务接入方法。
背景技术:
语音情感识别是一个非常具有挑战性的问题,因为人们总是以微妙和复杂的方式传达情感。对于语音情感识别,当前的方法主要包括:1)直接通过语音信号特征;2)通过语音识别的文本特征;3)融合音频和文本的多模态特征,在进行语义识别时,无法做到更加准确的识别,导致语义识别差,无法更好的理解语义。
技术实现要素:
本发明的目的在于提供一种基于人工智能的多模态语义识别服务接入方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种基于人工智能的多模态语义识别服务接入方法,包括基于多模态对齐的语音情感识别的模型,首先通过语音进行识别,识别时,通过视频设备、录音设备进行语音的收集,收集好的语音信息先进行分类,分类后的语音进行特征标记,然后将收集好的语音进行分析,利用双向长短期记忆模型对音频基于帧进行高维特征表示,且对语音识别出的文字进行特征化,对特征化的语音与相对应的文字进行匹配,匹配后的语音按照情绪特征进行分类,最后对识别出来的文字和信息进行整理,将整理的信息再次特征化。
优选的,基于多模态融合的训练,进行人工智能的语音训练,人机互动包含语音、图片、视频和文字,从帧序列中提取出语音和图像视频特征,按语音对应的视频片段,在各个中间阶段的不同模态之间的特征可以融合,在最后把不同模态的特征合并连接在一起又会形成混合的特征向量,最后融合的特征集,可以用支持向量机自动进行二分类。
优选的,语音识别相关的视频在于嘴部的图像和运动信息,将嘴部作为感兴趣区域,嘴部感兴趣区域都缩放到归一化的像素尺寸,进一步降维,用1-4帧连续视频作为输入,对应3-10帧连续语音的帧,对每个模态,在时间上进行特征平均值归一化,时间序列的导数用归一化线性斜率表示,体现了信号的变化特征,在训练和实际使用中,对缺失一种模态,即缺失语音、文字和视频的情况,依靠其它一种或二种模态进行工作,语音来自独立麦克风或从视频中提取,文字来自字幕、用户打字输入,图像视频中识别出的字符。
优选的,多模态语义识别服务还包括自然语言理解引擎,自然语言理解引擎采用多模态推理技术,对于多个领域的客服知识库,引擎采用文本聚类技术自动将知识点分为不同的子类,在每个子类知识库的推理过程中采用不同的参数,表现为多个相互独立的引擎模态,细化推理颗粒度,同时在软件技术上采用多线程方式。
优选的,融合文字与图像视频深度学习神经网络,利用文字和视觉之间的交叉相关提供用户问题的答案,多模态神经网络模型包含图像神经网络用于描述图像信息,另一个文字语义匹配神经网络进行文本信息中的单词的语义构建,两种模态之间的融合体现在由模型学习图像与文本之间的关联匹配关系。
优选的,基于手机拍照时的彩色图像和手机自带的激光测距得到的深度图,二者通过双模态信息的融合,实现机器人对目标的理解和分类。
优选的,基于文字的深度学习网络和基于图像的网络,在各层的中间特征层面进行多模态融合,并且在最后的输出进行融合,从而对图文并茂的内容进行综合理解,可以理解用户表达的喜怒哀乐情绪。
优选的,自然语言处理是在技术层面上的深度学习和知识层面上语言学应用的结合,语言学领域研究包括:词干提取、词形还原、分词、词性标注、命名实体识别、词义消歧、组块识别、句法分析、语义角色标注、共指消解、篇章分析。
本发明的技术效果和优点:
(1)利用多模态模型比单一模态训练出的模型更精准,所以即使在实际使用中只使用一个模态输入,由多模态训练得到的模型也会优于单模态训练得到的模型,对不同模态的关联融合进行中间层特征融合和最后层的融合时,每种模态的特征识别产生各自的置信度,从而在互相融合时将置信度作为贡献的权重。置信度高的模态得到的融合权重更大;
(2)神经网络模型挖掘以及学习图像与文本在单词级别,短语级别,以及句子级别的匹配关系,进而完全的描述了图像与文本的复杂的匹配关系,这种匹配关系可用于图像与文本的双向搜索,比如基于图像回答文字表达的问题或基于文字为用户返回相关的商品图像进行答疑、咨询和商品销售,基于图像和视频运动信息的双模态深度学习网络。最后通过得分的融合,对用户行为进行分类理解;
(3)基于文字的深度学习网络和基于图像的网络,在各层的中间特征层面进行多模态融合并且在最后的输出进行融合,从而对图文并茂的内容进行综合理解,比如理解用户表达的喜怒哀乐等情绪。情绪分析对企业营销和用户体验的评估具有重要的价值,且分析更加准确。
附图说明
图1为本发明的多核心自然语言理解引擎流程示意图;
图2为本发明多模态交互学习流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了如图1-2所示的一种基于人工智能的多模态语义识别服务接入方法,包括基于多模态对齐的语音情感识别的模型,首先通过语音进行识别,识别时,通过视频设备、录音设备进行语音的收集,收集好的语音信息先进行分类,分类后的语音进行特征标记,然后将收集好的语音进行分析,利用双向长短期记忆模型对音频基于帧进行高维特征表示,且对语音识别出的文字进行特征化,对特征化的语音与相对应的文字进行匹配,匹配后的语音按照情绪特征进行分类,最后对识别出来的文字和信息进行整理,将整理的信息再次特征化;
基于多模态融合的训练,进行人工智能的语音训练,人机互动包含语音、图片、视频和文字,从帧序列中提取出语音和图像视频特征,按语音对应的视频片段,在各个中间阶段的不同模态之间的特征可以融合,在最后把不同模态的特征合并连接在一起又会形成混合的特征向量,最后融合的特征集,可以用支持向量机自动进行二分类。
语音识别相关的视频在于嘴部的图像和运动信息,将嘴部作为感兴趣区域,嘴部感兴趣区域都缩放到归一化的像素尺寸,进一步降维,用1-4帧连续视频作为输入,对应3-10帧连续语音的帧,对每个模态,在时间上进行特征平均值归一化,时间序列的导数用归一化线性斜率表示,体现了信号的变化特征,在训练和实际使用中,对缺失一种模态,即缺失语音、文字和视频的情况,依靠其它一种或二种模态进行工作,语音来自独立麦克风或从视频中提取,文字来自字幕、用户打字输入,图像视频中识别出的字符,多模态语义识别服务还包括自然语言理解引擎,自然语言理解引擎采用多模态推理技术,对于多个领域的客服知识库,引擎采用文本聚类技术自动将知识点分为不同的子类,在每个子类知识库的推理过程中采用不同的参数,表现为多个相互独立的引擎模态,细化推理颗粒度,同时在软件技术上采用多线程方式。
融合文字与图像视频深度学习神经网络,利用文字和视觉之间的交叉相关提供用户问题的答案,多模态神经网络模型包含图像神经网络用于描述图像信息,另一个文字语义匹配神经网络进行文本信息中的单词的语义构建,两种模态之间的融合体现在由模型学习图像与文本之间的关联匹配关系,基于手机拍照时的彩色图像和手机自带的激光测距得到的深度图,二者通过双模态信息的融合,实现机器人对目标的理解和分类,基于文字的深度学习网络和基于图像的网络,在各层的中间特征层面进行多模态融合,并且在最后的输出进行融合,从而对图文并茂的内容进行综合理解,可以理解用户表达的喜怒哀乐情绪,自然语言处理是在技术层面上的深度学习和知识层面上语言学应用的结合,语言学领域研究包括:词干提取、词形还原、分词、词性标注、命名实体识别、词义消歧、组块识别、句法分析、语义角色标注、共指消解、篇章分析。
自然语言处理相当于认知层,对话管理(dm)包括对话状态跟踪和对话方案选择,相当于决策层。问答系统侧重于一问一答,即直接根据用户的问题给出精准的答案,是一个信息检索的过程。任务驱动的对话系统通常由多轮问答,倾向于一个决策的过程。另外与人机交互相关联的语音识别(asr)和语音合成(tts)则类似于感知层的功能。自然语言处理是在技术层面上的深度学习和知识层面上语言学应用的结合。语言学领域研究包括:词干提取、词形还原、分词、词性标注、命名实体识别、词义消歧、组块识别、句法分析、语义角色标注、共指消解、篇章分析等。因此自然语言处理的技术难点主要体现为:
(1)语言学层面上语言的模糊性。比如多义词,当你说“苹果”的时候,可能是一种水果,也可能是一个高科技品牌。解决这个问题需要帮助机器进行上下文理解,采用大规模的后端资源集成方式,通过判定用户的意图辅助分析。
(2)语言学层面上语言的多样性。每个用户的用语习惯不一样,有人简练,有人哆嗦。再加上方言千变万化,迫使机器在大数据学习之外,进行小样本的学习和预测。
目前主流解决方法是利用日志数据,即跟踪用户用语习惯,并在其语言上抽取语义标注数据,然后用这些数据构建相关领域的语言模型。
(3)技术层面上模型优化,机器思考方式和人的思考方式不一样,人可以基于小样本,并辅以推理能力进行学习,而机器则依赖大规模标注的数据,由于没有常识性知识储备,机器难以有效利用先验知识,而用深度学习模型得出的结果有时也与先验知识和专家知识相冲突。
这一问题的解决方法是在应用层面上,将深度学习和知识图谱(kg)相结合。这有两种方式,第一种是kg=模型input。即把知识图谱作为先验知识,将其中的语义信息量化为深度学习模型的输入。第二种是kg=模型约束条件,即在传统机器学习的基础上,把知识图谱作为机器学习的一个约束条件,来优化结果。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



