
 商标分类
商标分类  商标转让
商标转让 
一种基于心理声学模型的LSTM语音增强方法与流程
 2021-01-28 12:01:19|
2021-01-28 12:01:19| 251|
251| 起点商标网
起点商标网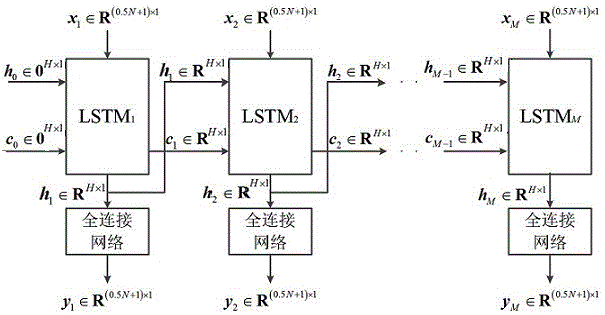
本发明属于语音增强技术领域,涉及语音识别系统中语音信号的增强技术,具体涉及一种基于心理声学模型的lstm语音增强方法。
背景技术:
随着人工智能技术的不断发展,asr技术的应用也日益广泛,语音识别率的提升是智能语音技术领域的核心。语音增强技术,作为语音识别中的关键一环,一直备受关注。将深度学习(deeplearning,dl)应用在语音增强领域是近年来的研究热点。譬如,基于全连接网络的语音增强方法,能够有效提升带噪语音信号的信噪比且结构简单。但是单个的全连接网络并未充分利用语音信号帧与帧之间的强相关性,因此采用lstm可有效利用信号的上下文信息,进一步提升语音信号的增强性能。
同时,由于人耳的感知特性,语音信号很多冗余信息并不能被感知。因此,利用基于人耳感知特性构建的心理声学模型对语音信号进行处理,可有效降低信号中的冗余成分。为后续的基于lstm的语音增强网络降低数据处理量,为语音识别降低干扰成分,从而提升语音增强的性能,提高语音的识别率。
技术实现要素:
为更好的利用人工智能技术进行语音信号识别,本发明公开了一种基于心理声学模型的lstm语音增强方法。
本发明所述基于心理声学模型的lstm语音增强方法,包括以下步骤:
s1.对输入的pcm信号进行vad处理,判断其是否为语音信号;
s2.如是语音信号,对语音信号进行特征处理,得到特征信号;
s3.将特征信号经过心理声学模型处理,得到声学特征信号;
s4.将声学特征信号经过lstm网络处理,得到增强语音信号;
s5.对增强语音信号做asr处理,实现语音识别。
优选的,所述步骤s2具体包括以下步骤:
s201.对输入的pcm语音信号
s202.对帧长为
s203.计算长度为
其中,
s204.计算频域信号
其中,功率谱
具体的,所述窗函数
优选的,所述步骤s3包括以下子步骤:
s301.根据特征信号
频率为
声压级
其中
s302.将语音信号的声压级
s303.将声压级低于全局掩蔽阈值的频点所对应的功率谱
采用本发明所述基于心理声学模型的lstm语音增强方法,利用心理声学模型对语音信号进行处理,将人耳不能感知的信号过滤,从而降低网络的输入数据量,提高网络的处理效率;同时,为充分利用语音信号中的上下文信息,本发明采用lstm网络做语音的增强处理,提高语音信号信噪比,进一步提升语音识别的准确率。
附图说明
图1为本发明所述基于心理声学模型的lstm语音增强方法一个具体实施方式示意图;
图2为本发明所述lstm网络的一个具体实施方式结构示意图。
具体实施方式
下面对本发明的具体实施方式作进一步的详细说明。
本发明所述基于心理声学模型的lstm语音增强方法,包括以下步骤:
s1.对输入的pcm信号进行vad处理,判断其是否为语音信号;
s2.如是语音信号,对语音信号进行特征处理,得到特征信号;
s3.将特征信号经过心理声学模型处理,得到声学特征信号;
s4.将声学特征信号经过lstm网络处理,得到增强语音信号;
s5.对增强语音信号做asr处理,实现语音识别。
步骤s1.对输入的pcm(pulsecodemodulation,脉冲编码调制)信号进行语音活动检测(voiceactivitydetection,vad)处理,判断其是否为语音信号;
其中pcm信号为实时采集的信号,经过vad处理后,若判断为音频信号则进行后续处理,若不为音频信号则终止。
s2.对判断为音频信号的pcm语音信号进行特征处理,得到特征信号;具体地,在本申请的实施例中所述步骤s2包括以下子步骤:
s201.对输入的pcm语音信号
所述的窗函数
s202.对帧长为
快速傅里叶变换是离散傅里叶变换(discretefouriertransform,dft)的快速算法,对帧长为
所述的fft就是不断把长序列的dft分解为几个短序列的dft,并利用①式中
;做
s203.计算长度为
其中,
s204.计算频域信号
其中,功率谱
s3.将特征信号经过心理声学模型处理,得到声学特征信号;
心理声学模型是一种模拟人耳滤波器的声学模型,将人耳不能感知的信号过滤掉,从而降低处理的数据量;与其他声学模型如基于隐马尔科夫模型等用于语音识别的模型不同,心理声学模型包括绝对掩蔽阈值曲线、临界频带和掩蔽效应等的计算,着重模拟人耳听音过程,而隐马尔科夫模型是着重模拟声带发声过程的声学模型。
具体地,在所述步骤s3可以包括以下子步骤:
s301.根据特征信号
频率为
声压级
其中
s302.将语音信号的声压级
s303.将声压级低于全局掩蔽阈值的频点所对应的功率谱
例如,在频点
通过心理声学模型计算得到全局掩蔽阈值曲线在上述频点的对应全局掩蔽阈值:
在频点
s4.将声学特征信号经过长短期记忆网络(longshort-termmemory,lstm)处理,得到增强语音信号;lstm网络可进一步提升语音的增强性能。
具体地,在本申请的实施例中所述的lstm网络为离线训练成熟的网络,lstm网络在训练过程中,网络的输入信号为经心理声学模型处理后的带噪语音特征信号,目标信号为经心理声学模型处理后的纯净语音特征信号。
纯净语音特征信号是通过纯净语音信号处理得到的,纯净语音信号通常是在安静环境即人耳感知不到环境噪声的环境下采集得到的;所述的带噪语音特征信号是通过带噪语音信号处理得到的,带噪语音信号是在噪声环境即人耳能明显感知到环境噪声的环境下采集得到的。
具体地,如图2所示给出一个现有技术下典型的lstm网络,在本申请的实施的步骤s4中所述的lstm网络输入信号的长度为,输出状态和cell状态的长度均为,初始化为0;输出状态经过一个全连接网络处理得到lstm网络的输出信号作为增强语音信号,其长度为;图2中、、、的下标为lstm单元的序号,表示实数集,其上标为表征的向量的维度,表示零集,为lstm单元的总数,如
表示第1个lstm单元的输入信号
其中,全连接网络包括一个输入层、
s5.对增强语音信号做asr(automaticspeechrecognition,自动化识别)处理处理,实现语音识别。
与传统的语音增强网络相比,本发明方案利用心理声学模型对带噪信号进行处理,消除冗余成分,降低网络的数据处理量;同时,相较于全连接的语音增强网络,本发明方案采用的lstm网络可联系上下文信息,进一步提升语音的增强性能,从而提升语音识别率。
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



