
 商标分类
商标分类  商标转让
商标转让 
基于TC-ResNet网络的麦克风阵列语音分离方法与流程
 2021-01-28 12:01:27|
2021-01-28 12:01:27| 371|
371| 起点商标网
起点商标网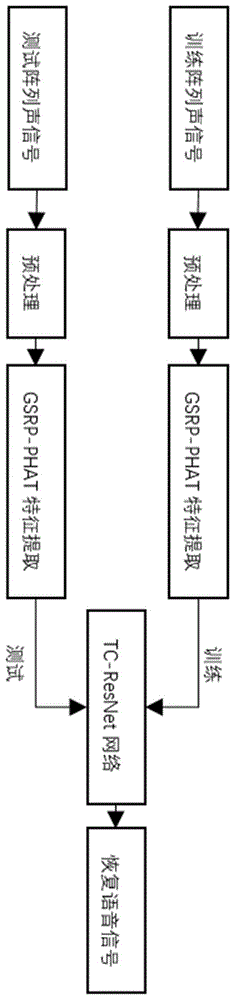
本发明属于语音分离技术领域,涉及一种基于tc-resnet网络的麦克风阵列语音分离方法。
背景技术:
实际生活环境中,因为噪声混响以及干扰的存在,机器难以分辨目标语音。语音分离作为语音信号系统的前端,分离后的语音信号质量对后续的语音信号处理模块会有很大的影响。
语音分离技术所涉领域很广,包括但不限于声学、数字信号处理、信息通讯、听觉心理与生理学等。多通道的语音分离技术利用阵列麦克风收集语音信号,然后从收集到的带有噪声、混响和其他说话人干扰的多通道语音信号中提取出说话人的语音。
多通道的传统语音分离主要使用独立成分分析以及波束成形。独立成分分析利用源信号的独立性,在信号瞬间混合的情况下有不错的分离性能。而波束成形则通过配置麦克风的空间结构,利用不同声源信号到不同麦克风的时延,提升选定方向的信号,削弱其他方向的信号。波束成形可分为固定波束成形与自适应波束成形,该类型算法有多种优化准则来调整滤波器的参数,常见的有最大信噪比(msnr),最小方差无失真(mvdr),最小均方误差(mmse)等。独立成分分析和波束成形两种方法在有混响时,分离性能会大幅度下降。此外,波束成形在目标声源与干扰声源非常近时也会变得难以分离。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种基于tc-resnet网络的麦克风阵列语音分离方法,针对带有噪声与混响的多说话人语音信号,使用改进的相位变换加权的可控响应功率(gsrp-phat)作为时频单元的特征,多帧拼接为特征参数对tc-resnet进行训练;测试过程中计算出测试语音的gsrp-phat,利用训练好的网络估计出时频单元的掩码,从而分离出单说话人语音信号。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于tc-resnet网络的麦克风阵列语音分离方法,针对带有噪声与混响的多说话人测试语音信号,提取每个时频单元的改进相位变换加权的可控响应功率(gsrp-phat)参数,同时为了引入上下文信息,将前、后时频单元的gsrp-phat参数进行拼接,作为当前时频单元的特征参数,输入tc-resnet网络进行训练;测试过程中,提取包含多个说话人的测试语音当前时频单元的特征参数,利用训练好的tc-resnet网络估计出当前时频单元的掩码,从而分离出各个说话人的语音信号,具体包括以下步骤:
步骤1,获取包含不同方位角、多个声源的混合麦克风阵列信号,阵列信号中同时包含混响和噪声;
步骤2,对步骤1获得的阵列信号进行子带滤波、分帧和加窗,得到各个子带分帧后的阵列语音信号;
步骤3,针对步骤2得到的子带分帧后的阵列语音信号,提取每个时频单元的改进gsrp-phat特征,同时引入前、后各3个时频单元共7个时频单元的gsrp-phat特征,融合为一个二维特征参数,作为tc-resnet网络的输入特征参数。
步骤4,利用训练阵列语音信号的特征参数训练tc-resnet网络,tc-resnet网络包括输入层、若干个卷积层和池化层、全连接层、输出层,输入层的输入特征参数为步骤3中特征参数,卷积层后面为池化层,若干个卷积层和池化层依次排列,将最后一个池化层的多维输出展开成一维输出,网络的输出为输入特征对应的时频单元的掩码;tc-resnet网络的训练过程具体包括:
步骤4-1,基于kaiming初始化随机设置所有卷积层和全连接层的权值;
步骤4-2,随机取一些特征参数构成一批数据输入训练样本,训练样本为(z(k,f),y),其中,z(k,f)是根据步骤3获得的特征参数,k为帧序号,f为子带序号;y=(y0,y1,y2,…,ymout),ym表示网络第m个输出神经元的预期输出值,下标0对应噪声,1,2,…,mout为方位角编号,mout为方位角个数,每个神经元的预期输出值由irm给定,其公式如下:
其中,m表示共有m个说话人,si(k,f)2表示第i个说话人语音信号在(k,f)时频单元内的能量,noise(k,f)2表示(k,f)时频单元内的噪声能量;i=0表示噪声;设第i个说话人所在方位角编号为m,则对应方位角神经元的期望输出值为ym=irmi,y0设为irm0;
步骤4-3,根据前向传播算法,依次计算每层网络的实际输出值,直到计算出每个softmax单元的实际输出y′=y′0,y′1,y′2,...,y′mout;
步骤4-4,计算当前训练特征参数的代价函数,使用均方误差函数作为代价函数,则代价函数j的计算公式如下:
步骤4-5,使用反向传播算法,计算代价函数j对网络权重的偏导,并修正权重;
步骤4-6,若当前迭代次数小于预设总迭代次数,则返回至步骤4-2,继续输入训练样本进行计算,直至得到达到预设迭代次数时迭代结束,训练网络结束;
步骤5,训练好的tc-resnet网络,对测试阵列语音信号对应的gsrp-phat特征参数进行计算,得到测试阵列语音信号的各时频单元的掩码,根据掩码和测试混合阵列信号,分离得到各个说话人的语音。
优选的:步骤3中gsrp-phat特征的计算公式为:
式中,gsrp-phatk,f(θ)表示第k帧、第f个子带的时频单元在声源方向角为θ时的特征值;n为阵列麦克风的总数;θ表示声源相对于阵列中心的方位角;ωfl、ωfh代表第f个子带的频率下限和上限;xu(k,ω)、xv(k,ω)表示第u个、第v个麦克风信号第k帧的频谱;w(ω)是矩形窗的频谱,()*表示共轭运算,j表示虚数单位,ω表示频点,τ(θ,u,v)表示声源相对于阵列中心的方位角为θ时,声信号到第u个和第v个麦克风的时延差。
优选的:声源相对于阵列中心的方位角为θ时,声信号到第u个和第v个麦克风的时延差τ(θ,u,v):
式中,r表示阵列半径,c表示声速,
θ方位角每隔10°计算一次gsrp-phatk,f(θ)参数,这样对每个时频单元,gsrp-phatk,f(θ)为1*36维的矢量,然后将该时频单元前、后各3帧同子带的时频单元gsrp-phat进行拼接,就得到了7*36的二维特征参数,作为tc-resnet网络的输入特征参数。
优选的:所述步骤5的使用网络输出作为irm掩码来恢复语音信号,先使用均值平滑处理掩码再用于进行语音分离,掩码滑动平均处理的计算公式如下:
其中,k0为当前帧的帧序号,d为正整数,将网络输出y’进行平滑处理之后,利用滑动均值p对混合测试语音进行分离,得到单个声源对应的声信号。
优选的:正整数d取1或2或3。
本发明相比现有技术,具有以下有益效果:
本发明提出的基于tc-resnet网络的麦克风阵列语音分离方法,语音可懂度更好,在高噪声和强混响情况下性能更为优越,优于现有技术中的经典算法。
附图说明
图1为本发明整体流程示意图;
图2为本发明特征参数的计算过程;
图3为本发明提供的实施例中tc-resnet网络结构示意图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
一种基于时序卷积残差网络(tc-resnet)的麦克风阵列语音分离方法,如图1所示,包括以下步骤:
步骤一、单个麦克风阵列语音信号的计算公式为:
式中,xn(t)表示第n个麦克风接收到的声信号,t表示时间,麦克风总数为n;si(t)表示第i个说话人的源信号,说话人总数为m;τin表示第n个麦克风接收到的第i个说话人直达声的延迟,ain表示直达声的衰减系数,δ(t)表示单脉冲信号,hin(t)表示第i个说话人到第n个麦克风的混响,noisen(t)是第n个麦克风接收的白噪声信号,每个麦克风之间的噪声不相关,而且噪声与信号之间也不相关,*为卷积运算。
本例中,单声道源信号采用从timit库中随机抽取的语音信号。房间冲激响应采用image法生成。方位角的范围为[0°,350°],间隔10°取值,总计36个方位角。采取三种混响时间,0s(无混响),0.2s,0.6s。采取3种信噪比,0db,10db,20db。
步骤一生成的是噪声、混响环境下的混合阵列声信号,是为了能让tc-resnet能够学习到噪声、混响环境下的空间特征参数的分布规律。
步骤二、对步骤一得到的训练阵列语音信号进行去直流分量、幅度归一化、分帧加窗,得到分帧的训练阵列语音信号,具体步骤如下:
(1)去直流分量:消除直流分量对后续处理的干扰,计算公式如下:
xn=xn-mean(x)
其中,xn表示第n个麦克风的信号向量,x表示所有麦克风信号向量构成的矩阵(x1,x2,…,xn),mean(x)表示均值;
(2)幅度归一化:降低多通道语音幅度范围的差异,计算公式如下:
(3)分帧加窗:对每一个通道的信号进行分帧加窗,窗函数使用矩形窗w(l),计算公式如下:
xn(k,l)=w(l)xn(kl+l),0≤l<t
其中xn(k,l)表示第n个麦克风在第k帧的信号,l是一帧内的采样点序号,t表示一帧长度时间序号,l是帧移。
步骤三、从每帧信号中提取每个子带的gsrp-phat,计算公式为:
式中,gsrp-phatk,f(θ)表示第k帧、第f个子带的时频单元在声源方向角为θ时的特征值;n为阵列麦克风的总数;θ表示声源相对于阵列中心的方位角;ωfl、ωfh代表第f个子带的频率下限和上限;xu(k,ω)、xv(k,ω)表示第u个、第v个麦克风信号第k帧的频谱;w(ω)是矩形窗的频谱,()*表示共轭运算,j表示虚数单位,ω表示频点,τ(θ,u,v)表示声源相对于阵列中心的方位角为θ时,声信号到第u个和第v个麦克风的时延差:
式中,r表示阵列半径,c表示声速,
xu(k,l)、xv(k,l)表示第u个、第v个麦克风接收到的第k帧时域信号。
针对每个时频单元,假定声源来自0°到360°,取θ值每10°一个间隔计算一个gsrp-phatk,f(θ),形成一个36维的向量;然后将该时频单元前后各3帧同子带的时频单元拼接,就得到了7*36的二维特征参数,作为网络输入,如图2所示;
步骤四、tc-resnet网络基于卷积神经网络(cnn),且使用了步骤三中所述的输入以增加对于时间上下文的使用,可认为进行了时序卷积,另外还引入了残差块。其中cnn包括输入层、若干卷积层和池化层、全连接层、输出层,输入层的输入特征参数为步骤(3)中特征参数矩阵,卷积层后面为池化层,若干个卷积层和池化层依次排列,将最后一个池化层的多维输出展开成一维输出。resnet的残差块是附加在cnn上的,如图3所示是本文所用的残差结构,将某一层的输入直接进行线性映射调整维度后,直接传给下面某一层,而不经过cnn的卷积池化,这种方法可以避免梯度消失,并且能将不同分辨率的特征相融合。另外网络引入批次归一化以降低过拟合的风险,使用参数l2正则化抑制过大参数。网络的输出为输入特征对应的时频单元的掩码,包含角度标签值和噪声标签值;
步骤五、训练好的tc-resnet网络,对测试阵列语音信号对应的gsrp-phat特征参数进行计算,得到测试阵列语音信号的各时频单元的掩码,根据掩码和测试混合阵列信号,分离得到各个说话人的语音。网络输出作为irm掩码来恢复语音信号,先使用均值平滑处理掩码再用于进行语音分离,掩码滑动平均处理的计算公式如下:
其中,k0为当前帧的帧序号,d为正整数,可取1或2或3,将网络输出y’进行平滑处理之后,利用滑动均值p对混合测试语音进行分离,得到单个声源对应的声信号。
对以上方法进行仿真验证,采用信源失真比sdr、信源干扰比sir评估分离算法性能。为了比较本算法与其他算法的优劣,此处也引入了主流的基于ibm与irm的dnn方法,比较它们在测试数据下的分离性能。sdr与sir如下表1、表2所示。
表1多环境下不同算法sdr值比较
表2多环境下不同算法sir值比较
通过表1、表2中可以看出,本专利基于tc-resnet模型的分离性能sir和sdr要优于dnn-ibm算法。与dnn-irm模型相比,高混响环境下,本专利算法的sdr、sir高于dnn-irm模型,低混响条件下,本专利算法的sdr、sir略低于dnn-irm模型。
除了sir、sdr评估算法分离性能外,还采用stoi客观可懂度指标评估分离语音的质量,其结果如表3所示。可以看出,本专利基于tc-resnet模型的分离算法在无混响、低噪声情况下stoi略低于dnn-irm模型,在高混响环境中stoi高于其余算法。噪声对算法stoi指标影响不大。混响对算法的stoi指标影响比较大,混响时间越长,性能下降越严重。
表3多环境下不同算法stoi值比较
同时为了研究本专利基于tc-resnet模型的分离算法对噪声和混响的泛化性,即测试数据与训练数据不相同时,分析不同算法的分离性能,表4给出了tc-resnet模型、dnn-irm模型在混响时间rt60为800ms,不同信噪比环境下语音分离性能指标。在此测试数据下,本专利基于tc-resnet模型的sdr、sir指标在不同信噪比下都比dnn-irm模型高,stoi指标两个模型比较接近。这说明,tc-resnet在高混响环境下有着更好的泛化性。
表4800ms混响不同信噪比下tc-resnet算法和dnn-irm算法分离性能比较
实验结果表明,在不同声学环境下,本发明提出的基于tc-resnet网络的麦克风阵列语音分离方法,语音可懂度更好,在高噪声和强混响情况下性能更为优越,优于现有技术中的经典算法。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



