
 商标分类
商标分类  商标转让
商标转让 
基于对数幅度谱和耳间相位差的深度聚类语音分离方法与流程
 2021-01-28 12:01:01|
2021-01-28 12:01:01| 310|
310| 起点商标网
起点商标网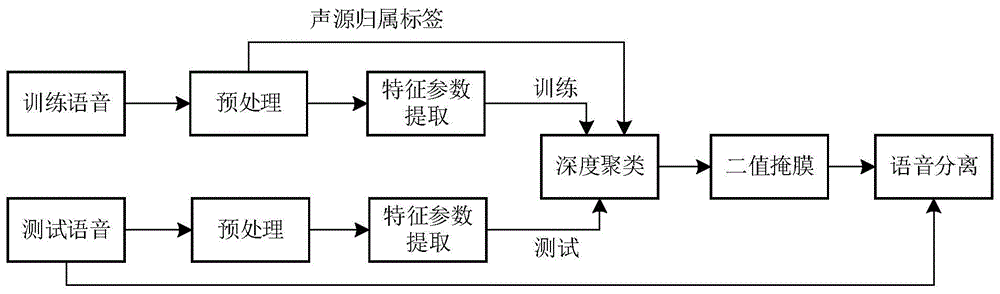
本发明属于语音分离
技术领域:
,涉及一种基于对数幅度谱和耳间相位差的深度聚类双耳语音分离方法。
背景技术:
:语音分离,指的是从复杂的声学环境中,提取中目标说话人的语音信号,同时尽可能减少对原始语音的改变。语音分离技术可以提高语音信号处理系统的整体性能。语音分离作为语音学术界的重要领域,一直以来都受到广大学者的重点关注。在嘈杂的环境中,人类能够轻易地辨别出自己感兴趣的语音,这就是著名的“鸡尾酒会”问题。“鸡尾酒会”问题自1953年由cherry提出以来,很多的学者都为此付出大量的努力,希望能够研究出一种适用范围很广的语音分离技术。而按照研究算法的不同,可以主要分为盲源分离和计算听觉场景分析两个方向。近年来,深度学习技术因其出色的学习学习能力也被引入到了语音分离任务中来。过往的研究中往往仅利用了当前帧的特征信息进行语音分离,没有考虑到语音信号在时序上的相关性和声源空间位置的短时稳定性。技术实现要素:发明目的:为了克服现有技术中存在的不足,本发明提供一种基于对数幅度谱和耳间相位差的深度聚类语音分离方法,利用深度聚类网络对混合双耳语音进行分离。考虑语音信号在时序上具有相关性,因此本发明选取了长短时记忆网络lstm(longshort-termmemory)作为聚类前的编码层主要部分,编码层将测试混合双耳语音信号的特征图映射到高维空间,对高维特征图的矢量进行聚类,从而实现语音分离。利用多种信噪比和混响条件下的数据进行训练,从而保证了深度聚类网络的鲁棒性。技术方案:为实现上述目的,本发明采用的技术方案为:一种基于对数幅度谱和耳间相位差的深度聚类语音分离方法,包括以下步骤:步骤1,获取包含不同方位角声源的混合双耳语音信号,且混合双耳语音信号中加入不同混响时间的混响和不同信噪比的噪声。步骤2,对步骤1得到的混合双耳语音信号进行预处理,并根据预处理后的混合双耳语音信号计算混合双耳语音信号的短时傅里叶变换得到短时频谱:其中,xl(τ,n)表示分帧后第τ帧的左耳语音信号,xr(τ,n)表示分帧后第τ帧的右耳语音信号,n表示样本点序号,n为帧长,xl(τ,ω)表示傅里叶变换后的左耳语音信号的频谱,xr(τ,ω)表示傅里叶变换后的右耳语音信号的频谱,ω表示频点,j表示虚数单位。步骤3,对于步骤2得到的短时频谱提取对数幅度谱和耳间相位差函数,并进行组合:对傅里叶变换后的左耳语音信号的频谱xl(τ,ω)做对数运算,得到对数幅度谱。耳间相位差定义为左、右耳语音信号频谱的相位差值为:其中,表示左耳语音信号频谱的相位,表示右耳语音信号频谱的相位,其计算分别为:得到耳间相位差后,对耳间相位差进行余弦、正弦变换,得到耳间相位差函数:其中,cosipd(τ,ω)表示耳间相位差余弦函数,sinipd(τ,ω)表示耳间相位差正弦函数。将对数幅度谱和耳间相位差函数组成一个新的矢量,作为第τ帧的特征参数c(τ):c(τ)=[log10|xl(τ,ω)|,cosipd(τ,ω),sinipd(τ,ω)]。每t帧特征参数进行组合,得到特征图c。c=[c(1),c(2),...,c(t)]步骤4,建立深度聚类网络模型,深度聚类网络模型包括编码层和聚类层,编码层将输入的特征图映射为高维特征图。聚类层则利用k均值聚类方法对映射后的高维特征图中各矢量进行分类。将步骤3得到的特征图序列,作为深度聚类网络模型的输入参数进行训练,得到训练好的深度聚类网络模型的编码层。得到训练好的深度聚类网络模型的编码层的方法:步骤41,将特征图c送入编码层,得到映射后的高维特征图v:v=f(c)其中,f表示编码层的映射函数。步骤42,根据高维特征图v和频点归属矩阵y之间的范数最小原则对编码层进行训练,网络的损失函数定义为:j=|vvh-yyh|2其中,表示每帧、每个频点归属的矩阵,当第τ帧、第ω个频点对应的第m个说话人的幅值大于其他说话人时,否则h表示转置运算。步骤43,使用反向传播方法,计算损失函数j对网络权重的偏导,并修正权重。步骤44,若当前迭代次数小于预设总迭代次数,则返回至步骤41,继续输入特征图c进行计算,直至达到预设迭代次数时迭代结束,则深度聚类网络模型的编码层训练结束。步骤5,获取测试混合双耳语音信号,测试混合双耳语音信号根据步骤2、步骤3提取特征参数,得到测试特征图。步骤6,将步骤5得到的测试特征图输入到训练好的深度聚类网络模型的编码层,将测试特征图映射为高维测试特征图。步骤7,将步骤6得到的高维测试特征图中各个特征矢量通过深度聚类网络模型的聚类层进行分类,得到二值掩膜矩阵,利用测试混合双耳语音信号和二值掩膜矩阵实现语音分离。优选的:步骤2中的预处理包括分帧、加窗操作。优选的:步骤3中对傅里叶变换后的左耳语音信号的频谱xl(τ,ω)做对数运算:log10|xl(τ,ω)|。优选的:所述步骤4中编码层包括依次连接的双向lstm网络、dropout层及全连接层。本发明相比现有技术,具有以下有益效果:本发明充分地利用了语音信号的谱信息和空间信息,分离性能良好,且算法的泛化性能好,具有较强的鲁棒性。本发明在各信噪比、混响环境下的sar、sir、sdr、pesq性能指标整体提升,本发明提出的方法对噪声和混响具有一定的鲁棒性和泛化性。附图说明图1为本发明整体算法流程图;图2为语音信号对数幅度谱;图3为混合语音信号的耳间相位差函数示意图;图4为深度聚类网络的结构示意图。具体实施方式下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。一种基于对数幅度谱和耳间相位差的深度聚类语音分离方法,如图1所示,包括以下步骤:步骤1,获取包含不同方位角声源的混合双耳语音信号,且混合双耳语音信号中加入不同混响时间的混响和不同信噪比的噪声。将两个在不同方位角的声源对应的双耳语音信号进行混合,得到训练混合双耳语音信号,计算公式为:xl(n)=s1(n)*h1,l+s2(n)*h2,l+vl(n)xr(n)=s1(n)*h1,r+s2(n)*h2,r+vr(n)其中,xl(n)、xr(n)分别表示加入混响和噪声后的左、右耳语音信号,s1(n)、s2(n)表示两个在不同方位角的单声源语音信号,h1,l、h1,r表示方位角一对应声源的双耳房间脉冲响应函数,h2,l、h2,r表示方位角二对应声源的双耳房间脉冲响应函数,h1,l、h1,r、h2,l、h2,r中包含了混响,vl(n)、vr(n)表示指定信噪比下的左、右耳噪声信号,n表示样本点序号,*为卷积运算。本例中的语音数据来自timit语音数据库,主要针对两说话人的场景进行训练,两个声信号的方位角设定在[-90°,90°]之间,且两声源的方位角不重合,计算可得一共有37*36/2=种组合。训练时将两个不同声源的不同语句进行混合。训练设置的信噪比有4种情况,分别为0db,10db,20db和无噪声。本例中同时考虑了混响对语音信号的影响,在训练集中设置混响为200ms和600ms,混响包含在双耳房间脉冲响应函数中。步骤2,对步骤1得到的混合双耳语音信号进行预处理,包括分帧、加窗操作,并根据预处理后的混合双耳语音信号计算混合双耳语音信号的短时傅里叶变换得到短时频谱。分帧和加窗操作为:xl(τ,n)=wh(n)xl(τ·n/2+n),0≤n<nxr(τ,n)=wh(n)xr(τ·n/2+n),0≤n<n其中,xl(τ,n)、xr(τ,n)表示分帧后第τ帧的左、右耳语音信号,n表示样本点序号,wh(n)为窗函数,n为帧长。每一帧信号的短时傅立叶变换为:其中,xl(τ,n)表示分帧后第τ帧的左耳语音信号,xr(τ,n)表示分帧后第τ帧的右耳语音信号,n表示样本点序号,n为帧长,xl(τ,ω)表示傅里叶变换后的左耳语音信号的频谱,xr(τ,ω)表示傅里叶变换后的右耳语音信号的频谱,ω表示频点,j表示虚数单位。步骤3,对于步骤2得到的短时频谱提取对数幅度谱和耳间相位差函数,并进行组合:对傅里叶变换后的左耳语音信号的频谱xl(τ,ω)做对数运算,即log10|xl(τ,ω)|,得到对数幅度谱,如图2所示。耳间相位差定义为左、右耳语音信号频谱的相位差值为:其中,表示左耳语音信号频谱的相位,表示右耳语音信号频谱的相位,其计算分别为:得到耳间相位差后,对耳间相位差进行余弦、正弦变换,如图3所示,得到耳间相位差函数:其中,cosipd(τ,ω)表示耳间相位差余弦函数,sinipd(τ,ω)表示耳间相位差正弦函数。将对数幅度谱和耳间相位差函数组成一个新的矢量,作为第τ帧的特征参数c(τ):c(τ)=[log10|xl(τ,ω)|,cosipd(τ,ω),sinipd(τ,ω)]。每t帧特征参数进行组合,得到特征图c:c=[c(1),c(2),...,c(t)]步骤4,建立深度聚类网络模型,深度聚类网络模型包括编码层和聚类层,编码层将输入的特征图映射为高维特征图。聚类层则利用k均值聚类方法对映射后的高维特征图中各矢量进行分类。将步骤3得到的特征图序列,作为深度聚类网络模型的输入参数进行训练,得到训练好的深度聚类网络模型的编码层。如图4所示,搭建的深度聚类主要由编码层和聚类层组成,其中训练时只用到编码层,测试时,测试混合语音信号的特征图经过编码层映射为高维特征图,通过聚类层完成对每一帧各频点的分类。编码层由双向lstm、dropout层及全连接层组成,隐藏层设置为600个神经元,全连接层则将每帧、每个频点的特征参数映射为20维的特征向量,训练过程如下:步骤41,将特征图c送入编码层,得到映射后的高维特征图v:v=f(c)其中,f表示编码层的映射函数。步骤42,根据高维特征图v和频点归属矩阵y之间的范数最小原则对编码层进行训练,网络的损失函数定义为:j=|vvh-yyh|2其中,表示每帧、每个频点归属的矩阵,当第τ帧、第ω个频点对应的第m个说话人的幅值大于其他说话人时,否则h表示转置运算。步骤43,使用反向传播方法,计算损失函数j对网络权重的偏导,并修正权重。步骤44,若当前迭代次数小于预设总迭代次数,则返回至步骤41,继续输入特征图c进行计算,直至达到预设迭代次数时迭代结束,则深度聚类网络模型的编码层训练结束。步骤5,获取测试混合双耳语音信号,测试混合双耳语音信号根据步骤2、步骤3提取特征参数,得到测试特征图。步骤6,将步骤5得到的测试特征图输入到训练好的深度聚类网络模型的编码层,将测试特征图映射为高维测试特征图。步骤7,将步骤6得到的高维测试特征图中各个特征矢量通过深度聚类网络模型的聚类层进行分类,得到各频点的二值掩膜矩阵,从而实现了对每一帧各频点的分类,结合输入的测试混合双耳语音信号即可分离目标语音。仿真本例采用sar、sir、sdr、pesq来评估分离语音信号的感知质量,将基于前后帧信息的cnn算法、ibm-dnn算法和本例基于深度聚类的算法进行了对比。表1、表2、表3和表4分别比较了三种方法的sar、sir、sdr值和pesq值,指标数值越高,表明语音分离的效果就越好。表1三种方法sar值比较snr(db)ibm-dnn前后帧-cnn深度聚类00.072.021.5752.714.544.02106.026.957.15157.818.018.54208.348.779.12noiseless8.859.039.44表2三种方法sir值比较snr(db)ibm-dnn前后帧-cnn深度聚类014.4215.1914.79515.1416.0116.181015.9816.4516.921516.4116.7017.012016.7116.8717.35noiseless17.1417.0217.58表3三种方法sdr值比较snr(db)ibm-dnn前后帧-cnn深度聚类0-0.771.540.7953.024.414.16105.316.027.41156.957.218.15207.527.859.02noiseless7.968.319.79表4三种算法pesq值比较snr(db)ibm-dnn前后帧-cnn深度聚类01.421.851.6751.72.071.94101.792.172.11151.952.242.25202.212.452.39noiseless2.412.572.52根据性能比较,在低信噪比条件下,本实例基于深度聚类的语音分离方法性能与前后帧-cnn较为接近,并显著优于ibm-dnn方法;在信噪比较高时,其性能则优于其余两种方法。同时我们对基于深度聚类算法的泛化性进行分析。训练集为200ms、600ms的混响数据,测试集为300ms的混响数据,本例基于深度聚类的分离效果与cnn的对比结果如表5、6、7所示。表5300ms混响环境下两种算法sar比较snr(db)前后帧-cnn深度聚类01.891.3254.073.95106.616.70157.457.79208.268.71表6300ms混响环境下两种算法sir比较snr(db)前后帧-cnn深度聚类014.7714.51515.8215.941015.9116.411516.5416.632016.6816.72表7300ms混响环境下两种算法sdr比较snr(db)前后帧-cnn深度聚类01.020.3453.573.46105.216.71156.577.35207.258.07本例基于深度聚类的语音分离算法在非匹配混响下的分离性能优于cnn方法,表明本例提出的基于深度聚类的分离方法具有一定的泛化性。以上所述仅是本发明的优选实施方式,应当指出:对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips