
 商标分类
商标分类  商标转让
商标转让 
一种基于对数谱平滑滤波的特征提取方法与流程
 2021-01-28 12:01:48|
2021-01-28 12:01:48| 307|
307| 起点商标网
起点商标网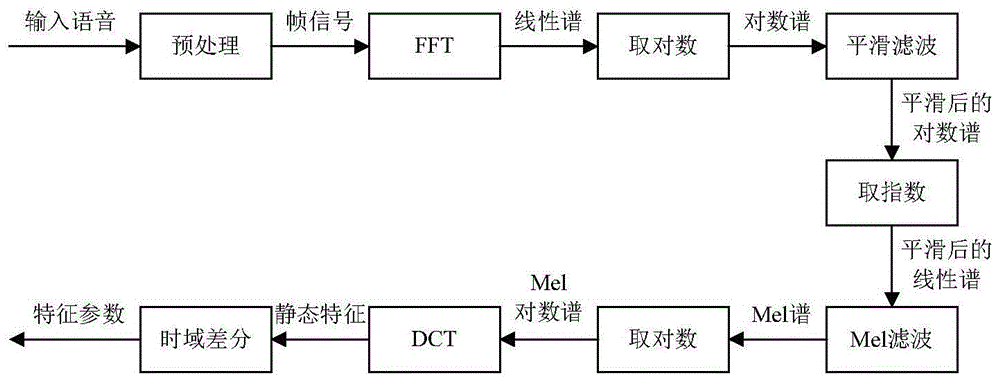
本发明属于语音识别技术领域,具体涉及到一种基于对数谱平滑滤波的特征提取方法。
背景技术:
语音可以看作是由声门激励信号e(n)与声道滤波器单位脉冲响应h(n)卷积生成的:
s(n)=e(n)*h(n)(1)
其中,s(n)表示卷积产生的语音信号。在频域,它们的关系可以表示为:
s(ω)=e(ω)*h(ω)(2)
其中,s(ω)、e(ω)和h(ω)分别表示s(n)、e(n)和h(n)的短时谱。e(ω)具有明显的周期性,不同说话人的e(ω)是不一样的,它代表说话人的个性特征;h(ω)的结构比较稳定,不同说话人的h(ω)具有一定的相似性,它代表语音的特征。显然,在语音识别的特征提取中,应该尽可能减小e(ω)的影响,突出h(ω)的作用,即尽量减小语音个性的影响,突出语音的共性特征。
目前的语音识别系统多数以美尔频率倒谱系数(mfcc:melfrequencycepstralcoefficients)为语音的特征参数。由于在特征提取中采用了倒谱滤波技术,因而mfcc对语音中的激励信号成分有一定的抑制作用。但是,研究标明,对部分基音频率较高的人群,激励信号对mfcc的影响仍然较大,这会影响语音识别系统的性能。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提供一种基于对数谱平滑滤波的特征提取方法,解决了语音特征鲁棒性差的问题。
技术方案:本发明提供基于对数谱平滑滤波的特征提取方法,包括以下步骤:
(1)对输入语音进行声学预处理;
(2)对每一帧语音进行fft运算,并取频谱幅度,得到每帧信号的线性谱;
(3)对每帧信号的线性谱取对数,得到每帧信号的对数谱;
(4)对每帧信号的对数谱进行低通平滑滤波,得到每帧信号平滑后的对数谱;
(5)对每帧信号平滑后的对数谱取指数,得到每帧信号平滑后的线性谱;
(6)对每帧信号平滑后的线性谱进行mel滤波,并取对数,得到每帧信号的mel对数谱;
(7)对每帧信号的mel对数谱进行离散余弦变换,并作一阶差分和二阶差分,得到输入语音的特征参数。
进一步的,包括:
所述步骤(1)包括对输入语音加窗,分帧,将其分解为帧信号,窗函数采用海明窗,帧移长度为帧长的一半。
进一步的,包括:
所述步骤(2)包括对预处理后的每一帧信号x(n),用快速傅里叶变换进行短时谱估计:
其中,n表示帧长,x(k)是x(n)的短时谱;
然后对短时谱x(k)取模,得到每帧信号的线性谱|x(k)|:
|x(k)|=x(k)。
进一步的,包括:
所述步骤(6)中,包括:
对每帧信号平滑后的线性谱
其中,wm(k)为mel滤波器组第m个三角滤波器在频率k处的加权因子;m为滤波器的个数;s(m)为第m个滤波器的输出,即mel谱向量的第m个元素。
然后对s(m)取对数,得到mel对数谱slog(m):
slog(m)=lns(m)。
进一步的,包括:
所述步骤(7)包括:
因为对数谱特征slog(m)的维数m较高,且各维系数的相关性较强,不利于声学解码,所以对每帧信号的mel对数谱进行离散余弦变换,去除各维系数之间的相关性:
其中,l是静态特征向量c的维数,c(l)是c的第l个元素。
进一步的,包括:
只保留静态特征的低13维系数,即l=13。
进一步的,包括:
所述步骤(7)还包括:
对第t帧13维静态特征向量ct作一阶差分和二阶差分,得到一阶动态特征参数δct和二阶动态特征参数δδct:
得到动态倒谱参数后,静态参数ct和动态参数δct、δδct共同组成第t帧语音的39维倒谱特征向量
其中,上标t表示向量的转置,即将列向量转置为行向量,或者将行向量转置为列向量。
有益效果:本发明与现有技术相比,其显著优点是:本发明将语音信号的短时谱s(ω)看作是时域信号,那么h(ω)可以看作是s(ω)的低频成分(信号的包络),e(ω)可以看作是s(ω)的高频成分(信号的细节)。因此,对s(ω)进行平滑滤波,就可以减小e(ω)的影响,本发明可以减小说话人的改变对语音识别系统的影响,提高语音识别系统对说话人的鲁棒性。
附图说明
图1为本发明所述的方法流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
一种基于对数谱平滑滤波的特征提取方法,其框架如附图1所示。首先,对输入语音进行声学预处理和快速傅里叶变换(fft:fastfouriertransform),得到每一帧语音的线性谱;再对线性谱取对数,平滑滤波和取指数,得到平滑后的线性谱;最后,对平滑后的线性谱进行mel滤波,取对数,离散余弦变换(dct:discretecosinetransform)和时域差分,得到输入语音的特征参数。
本发明的具体步骤如下:
(1)对输入语音进行声学预处理,包括预加重、加窗和分帧,将输入语音分解为若干帧信号;
(2)对每一帧语音进行fft运算,并取频谱幅度,得到每帧信号的线性谱;
(3)对每帧信号的线性谱取对数,得到每帧信号的对数谱;
(4)对每帧信号的对数谱进行低通平滑滤波,得到每帧信号平滑后的对数谱;
(5)对每帧信号平滑后的对数谱取指数,得到每帧信号平滑后的线性谱;
(6)对每帧信号平滑后的线性谱进行mel滤波,并取对数,得到每帧信号的mel对数谱;
(7)对每帧信号的mel对数谱进行离散余弦变换(dct),并作一阶差分和二阶差分,得到输入语音的特征参数。
具体的,本发明的基于对数谱平滑滤波的特征提取方法主要包括预处理、fft、取对数、平滑滤波、取指数、mel滤波、dct和时域差分模块。下面逐一详细说明附图中各模块的具体实施方案。
1、预处理:
在声学预处理阶段,对输入语音加窗,分帧,将其分解为帧信号。窗函数采用海明窗,帧移长度为帧长的一半。
2、fft:
对预处理后的每一帧信号x(n),用快速傅里叶变换进行短时谱估计:
其中,n表示帧长,x(k)是x(n)的短时谱。
然后对短时谱x(k)取模,得到每帧信号的线性谱|x(k)|:
|x(k)|=x(k)(2)
3、取对数
在附图中,有两个取对数模块,分别对线性谱和mel对数谱进行取对数操作。这两个模块的功能相同,都是对输入信号取自然对数。对线性谱|x(k)|取对数,得到对数谱xlog(k):
xlog(k)=ln|x(k)|(3)
4、平滑滤波
将对数谱xlog(k)看作是时域信号,将其通过一个低通滤波器,保留低频成分,滤除高频成分,得到平滑后的对数谱
5、取指数
对平滑后的对数谱
6、mel滤波
首先,对每帧信号平滑后的线性谱
其中,wm(k)为mel滤波器组第m个三角滤波器在频率k处的加权因子;m为滤波器的个数;s(m)为第m个滤波器的输出,即mel谱向量的第m个元素。
然后,对s(m)取对数,得到mel对数谱slog(m):
slog(m)=lns(m)
(6)
7、dct
因为对数谱特征slog(m)的维数m较高,且各维系数的相关性较强,不利于声学解码,所以需要对每帧信号的mel对数谱进行离散余弦变换,去除各维系数之间的相关性:
其中,l是静态特征向量c的维数,c(l)是c的第l个元素。为了减小矩阵运算的计算量,通常只保留静态特征的低13维系数,所以l一般取13。
8、时域差分
对第t帧13维静态特征向量ct作一阶差分和二阶差分,得到一阶动态特征参数δct和二阶动态特征参数δδct:
得到动态倒谱参数后,静态参数ct和动态参数δct、δδct共同组成第t帧语音的39维倒谱特征向量
其中,上标t表示向量的转置,即将列向量转置为行向量,或者将行向量转置为列向量。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



