
 商标分类
商标分类  商标转让
商标转让 
一种基于alexa云服务的语音交互方法及系统与流程
 2021-01-28 12:01:33|
2021-01-28 12:01:33| 250|
250| 起点商标网
起点商标网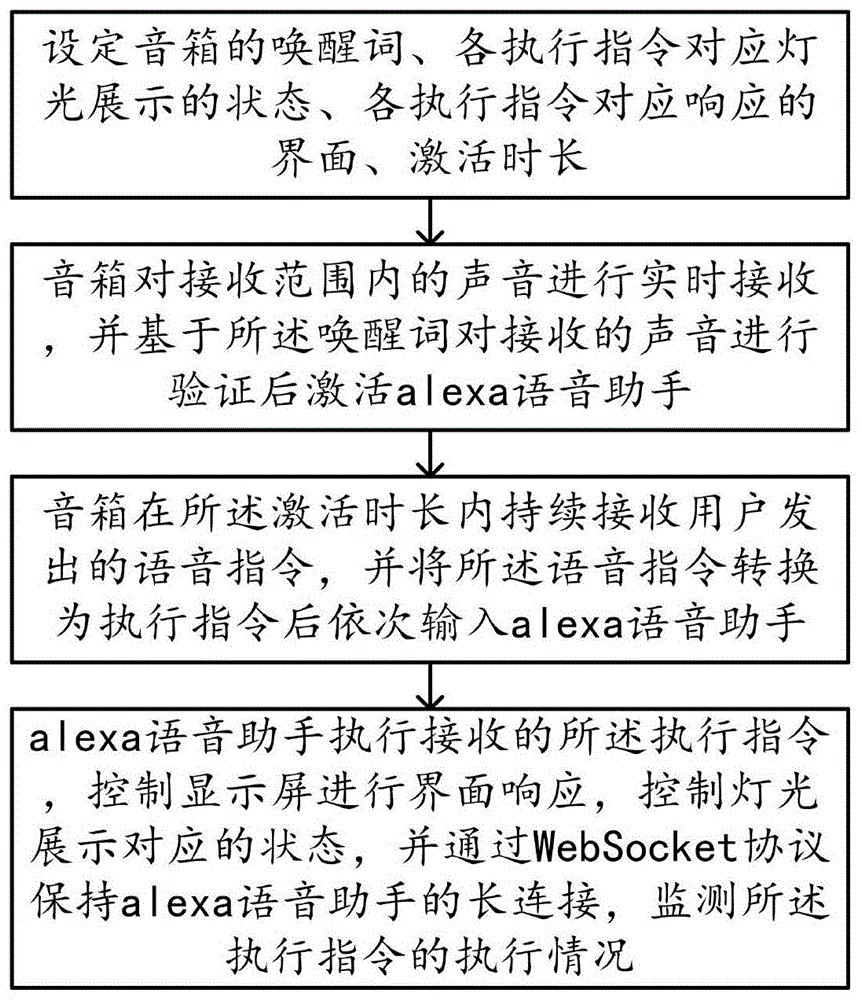
本发明涉及智能音箱技术领域,特别指一种基于alexa云服务的语音交互方法及系统。
背景技术:
随着科技的不断进步,智能音箱逐渐出现在了人们的视野中,智能音箱不仅可以播放音乐,还能与用户进行语音交互。然而,传统的智能音箱在执行任务的过程中,若因网络掉线等原因产生了中断,无法继续执行任务,且在语音交互的过程中无法响应对应的界面,导致用户体验低下。
因此,如何提供一种基于alexa云服务的语音交互方法及系统,实现智能音箱的长连接,并进行界面响应,进而提升用户体验,成为一个亟待解决的问题。
技术实现要素:
本发明要解决的技术问题,在于提供一种基于alexa云服务的语音交互方法及系统,实现智能音箱的长连接,并进行界面响应,进而提升用户体验。
一方面,本发明提供了一种基于alexa云服务的语音交互方法,包括如下步骤:
步骤s10、设定音箱的唤醒词、各执行指令对应灯光展示的状态、各执行指令对应响应的界面、激活时长;
步骤s20、音箱对接收范围内的声音进行实时接收,并基于所述唤醒词对接收的声音进行验证后激活alexa语音助手;
步骤s30、音箱在所述激活时长内持续接收用户发出的语音指令,并将所述语音指令转换为执行指令后依次输入alexa语音助手;
步骤s40、alexa语音助手执行接收的所述执行指令,控制显示屏进行界面响应,控制灯光展示对应的状态,并通过websocket协议保持alexa语音助手的长连接,监测所述执行指令的执行情况。
进一步地,所述步骤s20具体为:
音箱利用拾音器对接收范围内的声音进行实时接收,利用语音引擎将接收的声音实时转换为文字,比对转换的文字与所述唤醒词是否一致,若是,则激活alexa语音助手;若否,则继续对接收范围内的声音进行接收和识别。
进一步地,所述步骤s30具体为:
音箱在所述激活时长内,利用拾音器持续接收用户发出的语音指令,利用声纹识别技术对所述语音指令进行分类,利用神经网络识别分类的所述语音指令的潜在意图后,将所述语音指令转换为执行指令后依次输入alexa语音助手。
进一步地,所述步骤s30中,所述执行指令包括执行时长。
进一步地,所述步骤s40中,所述通过websocket协议保持alexa语音助手的长连接,监控执行指令的执行情况具体包括:
步骤s41、设定一心跳周期,监测所述执行指令在执行时长内是否产生中断,若是,则进入步骤s42;若否,则进入步骤s20;
步骤s42、利用websocket协议,以所述心跳周期为间隔监测中断是否恢复,若是,则继续执行所述执行指令;若否,则继续以所述心跳周期为间隔监测中断是否恢复。
另一方面,本发明提供了一种基于alexa云服务的语音交互系统,包括如下模块:
音箱初始化模块,用于设定音箱的唤醒词、各执行指令对应灯光展示的状态、各执行指令对应响应的界面、激活时长;
alexa语音助手激活模块,用于音箱对接收范围内的声音进行实时接收,并基于所述唤醒词对接收的声音进行验证后激活alexa语音助手;
指令接收模块,用于音箱在所述激活时长内持续接收用户发出的语音指令,并将所述语音指令转换为执行指令后依次输入alexa语音助手;
指令执行模块,用于alexa语音助手执行接收的所述执行指令,控制显示屏进行界面响应,控制灯光展示对应的状态,并通过websocket协议保持alexa语音助手的长连接,监测所述执行指令的执行情况。
进一步地,所述alexa语音助手激活模块具体为:
音箱利用拾音器对接收范围内的声音进行实时接收,利用语音引擎将接收的声音实时转换为文字,比对转换的文字与所述唤醒词是否一致,若是,则激活alexa语音助手;若否,则继续对接收范围内的声音进行接收和识别。
进一步地,所述指令接收模块具体为:
音箱在所述激活时长内,利用拾音器持续接收用户发出的语音指令,利用声纹识别技术对所述语音指令进行分类,利用神经网络识别分类的所述语音指令的潜在意图后,将所述语音指令转换为执行指令后依次输入alexa语音助手。
进一步地,所述指令接收模块中,所述执行指令包括执行时长。
进一步地,所述指令执行模块中,所述通过websocket协议保持alexa语音助手的长连接,监控执行指令的执行情况具体包括:
中断监测单元,用于设定一心跳周期,监测所述执行指令在执行时长内是否产生中断,若是,则进入心跳测试单元;若否,则进入alexa语音助手激活模块;
心跳测试单元,用于利用websocket协议,以所述心跳周期为间隔监测中断是否恢复,若是,则继续执行所述执行指令;若否,则继续以所述心跳周期为间隔监测中断是否恢复。
本发明的优点在于:
1、通过websocket协议保持alexa语音助手的长连接,监测所述执行指令的执行情况,当所述执行指令在执行时长内产生了中断,则以心态周期为间隔进行心跳测试,中断恢复后继续执行所述执行指令,实现智能音箱的长连接;通过设置各执行指令对应响应的界面,alexa语音助手基于接收的所述执行指令后,令显示屏跳转至对应的界面,实现智能音箱的界面响应,进而极大的提升了用户体验。
2、通过采用alexa语音助手,极大的提升了英文识别的准确度。
3、通过设置所述激活时长,使得用户在唤醒alexa语音助手后,在所述激活时长内可以连续的下发语音指令,不必每次下发所述语音指令均要唤醒alexa语音助手一次,即可与音箱进行连续交互,进而极大的提升了用户体验。
4、利用声纹识别技术对所述语音指令进行分类,使得音箱能够识别不同的用户,进而依据不同的用户进行偏好设置。例如同样是播放音乐,其中用户a偏好摇滚乐,用户b偏好影视金曲,当音箱接受到播放音乐的语音指令时,若利用声纹识别技术识别到发出该语音指令的人为用户a,则播放摇滚乐,使得音箱更加的智能,进而极大的提升了用户体验。
5、利用神经网络识别分类的所述语音指令的潜在意图,极大的提升了所述语音指令的识别准确度。
附图说明
下面参照附图结合实施例对本发明作进一步的说明。
图1是本发明一种基于alexa云服务的语音交互方法的流程图。
图2是本发明一种基于alexa云服务的语音交互系统的结构示意图。
具体实施方式
本申请实施例中的技术方案,总体思路如下:通过websocket协议保持alexa语音助手的长连接,当所述执行指令在执行时长内产生了中断,则以心态周期为间隔进行心跳测试,中断恢复后继续执行所述执行指令;通过设置各执行指令对应响应的界面,alexa语音助手基于接收的所述执行指令后,令显示屏跳转至对应的界面;进而实现智能音箱的长连接,并进行界面响应,进而提升用户体验。
本发明使用的智能音箱设有显示屏、指示灯、拾音器以及无线通信模块;其中显示屏用于显示执行指令对应的界面,指示灯用于显示不同的状态以告知用户音箱当前的运行情况,拾音器用于拾取用户发出的声音,无线通信模块用于与服务器或者其他智能设备进行连接交互。
请参照图1至图2所示,本发明一种基于alexa云服务的语音交互方法的较佳实施例,包括如下步骤:
步骤s10、设定音箱的唤醒词、各执行指令对应灯光展示的状态、各执行指令对应响应的界面、激活时长;通过设置各执行指令对应响应的界面,alexa语音助手基于接收的所述执行指令后,令显示屏跳转至对应的界面,实现智能音箱的界面响应,进而极大的提升了用户体验。
步骤s20、音箱对接收范围内的声音进行实时接收,并基于所述唤醒词对接收的声音进行验证后激活alexa语音助手;通过采用alexa语音助手,极大的提升了英文识别的准确度。
步骤s30、音箱在所述激活时长内持续接收用户发出的语音指令,并将所述语音指令转换为执行指令后依次输入alexa语音助手;通过设置所述激活时长,使得用户在唤醒alexa语音助手后,在所述激活时长内可以连续的下发语音指令,不必每次下发所述语音指令均要唤醒alexa语音助手一次,即可与音箱进行连续交互,进而极大的提升了用户体验。
步骤s40、alexa语音助手执行接收的所述执行指令,控制显示屏进行界面响应,控制灯光展示对应的状态,并通过websocket协议保持alexa语音助手的长连接,监测所述执行指令的执行情况。通过websocket协议保持alexa语音助手的长连接,监测所述执行指令的执行情况,当所述执行指令在执行时长内产生了中断,则以心态周期为间隔进行心跳测试,中断恢复后继续执行所述执行指令,实现智能音箱的长连接。
所述步骤s20具体为:
音箱利用拾音器对接收范围内的声音进行实时接收,利用语音引擎将接收的声音实时转换为文字,比对转换的文字与所述唤醒词是否一致,若是,则激活alexa语音助手;若否,则继续对接收范围内的声音进行接收和识别。
所述步骤s30具体为:
音箱在所述激活时长内,利用拾音器持续接收用户发出的语音指令,利用声纹识别技术对所述语音指令进行分类,利用神经网络识别分类的所述语音指令的潜在意图后,利用语音引擎将所述语音指令转换为执行指令后依次输入alexa语音助手;所述执行指令为精确的文本指令。利用声纹识别技术对所述语音指令进行分类,使得音箱能够识别不同的用户,进而依据不同的用户进行偏好设置。例如同样是播放音乐,其中用户a偏好摇滚乐,用户b偏好影视金曲,当音箱接受到播放音乐的语音指令时,若利用声纹识别技术识别到发出该语音指令的人为用户a,则播放摇滚乐,使得音箱更加的智能,进而极大的提升了用户体验。利用神经网络识别分类的所述语音指令的潜在意图,极大的提升了所述语音指令的识别准确度。
所述步骤s30中,所述执行指令包括执行时长,例如播放音乐半小时,则该执行指令的执行时长为半小时。
所述步骤s40中,所述通过websocket协议保持alexa语音助手的长连接,监控执行指令的执行情况具体包括:
步骤s41、设定一心跳周期,监测所述执行指令在执行时长内是否产生中断,若是,则进入步骤s42;若否,则进入步骤s20;
步骤s42、利用websocket协议,以所述心跳周期为间隔监测中断是否恢复,若是,则继续执行所述执行指令;若否,则继续以所述心跳周期为间隔监测中断是否恢复。
例如所述执行指令为播放音乐一小时,所述心跳周期为一分钟,当音乐播放到半小时时因网络原因产生了中断,则每隔一分钟监测一次网络是否恢复,若网络恢复了,则继续播放音乐,直至播放满一小时。
本发明一种基于alexa云服务的语音交互系统的较佳实施例,包括如下模块:
音箱初始化模块,用于设定音箱的唤醒词、各执行指令对应灯光展示的状态、各执行指令对应响应的界面、激活时长;通过设置各执行指令对应响应的界面,alexa语音助手基于接收的所述执行指令后,令显示屏跳转至对应的界面,实现智能音箱的界面响应,进而极大的提升了用户体验。
alexa语音助手激活模块,用于音箱对接收范围内的声音进行实时接收,并基于所述唤醒词对接收的声音进行验证后激活alexa语音助手;通过采用alexa语音助手,极大的提升了英文识别的准确度。
指令接收模块,用于音箱在所述激活时长内持续接收用户发出的语音指令,并将所述语音指令转换为执行指令后依次输入alexa语音助手;通过设置所述激活时长,使得用户在唤醒alexa语音助手后,在所述激活时长内可以连续的下发语音指令,不必每次下发所述语音指令均要唤醒alexa语音助手一次,即可与音箱进行连续交互,进而极大的提升了用户体验。
指令执行模块,用于alexa语音助手执行接收的所述执行指令,控制显示屏进行界面响应,控制灯光展示对应的状态,并通过websocket协议保持alexa语音助手的长连接,监测所述执行指令的执行情况。通过websocket协议保持alexa语音助手的长连接,监测所述执行指令的执行情况,当所述执行指令在执行时长内产生了中断,则以心态周期为间隔进行心跳测试,中断恢复后继续执行所述执行指令,实现智能音箱的长连接。
所述alexa语音助手激活模块具体为:
音箱利用拾音器对接收范围内的声音进行实时接收,利用语音引擎将接收的声音实时转换为文字,比对转换的文字与所述唤醒词是否一致,若是,则激活alexa语音助手;若否,则继续对接收范围内的声音进行接收和识别。
所述指令接收模块具体为:
音箱在所述激活时长内,利用拾音器持续接收用户发出的语音指令,利用声纹识别技术对所述语音指令进行分类,利用神经网络识别分类的所述语音指令的潜在意图后,利用语音引擎将所述语音指令转换为执行指令后依次输入alexa语音助手;所述执行指令为精确的文本指令。利用声纹识别技术对所述语音指令进行分类,使得音箱能够识别不同的用户,进而依据不同的用户进行偏好设置。例如同样是播放音乐,其中用户a偏好摇滚乐,用户b偏好影视金曲,当音箱接受到播放音乐的语音指令时,若利用声纹识别技术识别到发出该语音指令的人为用户a,则播放摇滚乐,使得音箱更加的智能,进而极大的提升了用户体验。利用神经网络识别分类的所述语音指令的潜在意图,极大的提升了所述语音指令的识别准确度。
所述指令接收模块中,所述执行指令包括执行时长,例如播放音乐半小时,则该执行指令的执行时长为半小时。
所述指令执行模块中,所述通过websocket协议保持alexa语音助手的长连接,监控执行指令的执行情况具体包括:
中断监测单元,用于设定一心跳周期,监测所述执行指令在执行时长内是否产生中断,若是,则进入心跳测试单元;若否,则进入alexa语音助手激活模块;
心跳测试单元,用于利用websocket协议,以所述心跳周期为间隔监测中断是否恢复,若是,则继续执行所述执行指令;若否,则继续以所述心跳周期为间隔监测中断是否恢复。
例如所述执行指令为播放音乐一小时,所述心跳周期为一分钟,当音乐播放到半小时时因网络原因产生了中断,则每隔一分钟监测一次网络是否恢复,若网络恢复了,则继续播放音乐,直至播放满一小时。
综上所述,本发明的优点在于:
1、通过websocket协议保持alexa语音助手的长连接,监测所述执行指令的执行情况,当所述执行指令在执行时长内产生了中断,则以心态周期为间隔进行心跳测试,中断恢复后继续执行所述执行指令,实现智能音箱的长连接;通过设置各执行指令对应响应的界面,alexa语音助手基于接收的所述执行指令后,令显示屏跳转至对应的界面,实现智能音箱的界面响应,进而极大的提升了用户体验。
2、通过采用alexa语音助手,极大的提升了英文识别的准确度。
3、通过设置所述激活时长,使得用户在唤醒alexa语音助手后,在所述激活时长内可以连续的下发语音指令,不必每次下发所述语音指令均要唤醒alexa语音助手一次,即可与音箱进行连续交互,进而极大的提升了用户体验。
4、利用声纹识别技术对所述语音指令进行分类,使得音箱能够识别不同的用户,进而依据不同的用户进行偏好设置。例如同样是播放音乐,其中用户a偏好摇滚乐,用户b偏好影视金曲,当音箱接受到播放音乐的语音指令时,若利用声纹识别技术识别到发出该语音指令的人为用户a,则播放摇滚乐,使得音箱更加的智能,进而极大的提升了用户体验。
5、利用神经网络识别分类的所述语音指令的潜在意图,极大的提升了所述语音指令的识别准确度。
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



