
 商标分类
商标分类  商标转让
商标转让 
NVOCPLUS高速宽带声码器的语音数据处理方法与流程
 2021-01-28 12:01:27|
2021-01-28 12:01:27| 263|
263| 起点商标网
起点商标网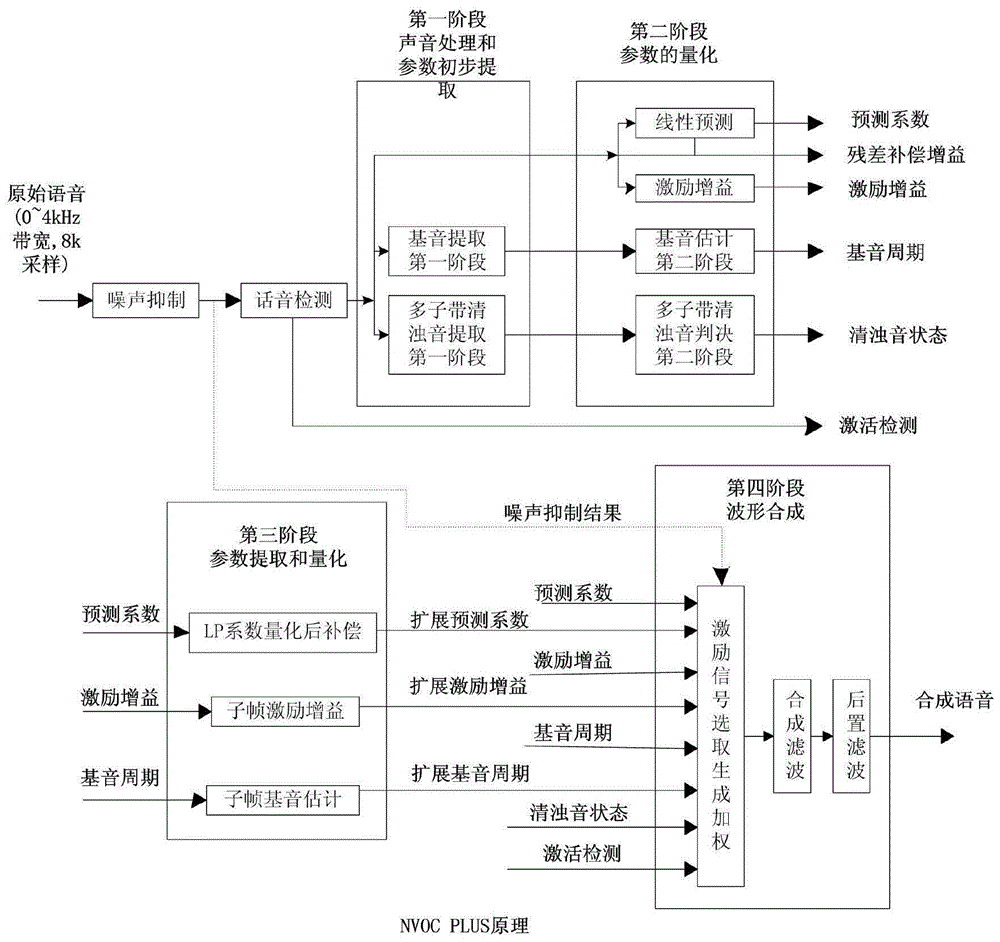
本发明属于声码器数字语音压缩技术领域,尤其是一种nvocplus高速宽带声码器的语音数据处理方法。
背景技术:
随着通信技术的高速发展,频率和资源显得尤为宝贵,与模拟语音通信系统相比,数字语音通信系统具有抗干扰性强、保密性号、易于集成等特点,而在这其中低速声码器担当着重要角色。
目前,语音编码算法大都建立在人类发声器官的声学模型基础上。人的发声器官由声门、声道和其它辅助器官组成。实际语音的产生过程是声门产生的振动被声道滤波器调制后经口鼻等辐射所得,可以用如下公式表示为
s(n)=h(n)*e(n)
其中,s(n)表示语音信号,h(n)为声道滤波器单位冲激响应,e(n)为声门振动信号。
为了清晰地表示语音信号,可以从频谱特点上分别描述声门和声道,如何高效量化声门和声道的特征参数,这是参数编码这一类算法要达到的目标。
声码器属于参数编码一类,高速宽带声码器就是压缩语音信号的数字表示,用较少的比特(bit)还原出与原是语音最为相似语音的方法。随着数字信号处理硬件的效率猛增,加上声码器的加速研究,使得声码器已经大量使用。
有别于现有的nvoc窄带声码器包括两种码率:2.4kbps、2.2kbps(用于加密),信道fec码率为1.2kbps,语音编解码和fec都以8k采样20毫秒为一帧进行编码和解码。nvoc宽带声码器实现12.2kbps高速,压缩后(200+bit)较窄带(40+bit)而言较多,编码后的数据携带更多有助于还原声音的信息。
现有宽带声码器领域,由于语音编码压缩比不高,在获得较好音质和准确率的前提下,仍存在如下问题:(1)利用时域相关性提取基因参数,容易算错;(2)由于声音不经过降噪,当有噪音时提取的声音参数不准确;(4)忽视了和低速窄带声码器的兼容性。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出一种设计合理、语音质量高且对方言适应性强的nvocplus高速宽带声码器的语音数据处理方法。
本发明解决其现实问题是采取以下技术方案实现的:
一种nvocplus高速宽带声码器的语音数据处理方法,包括以下步骤:
步骤1、编码端对原始语音数字信号的初始化配置和分析处理,首先对原始语音数字信号进行噪声抑制处理,然后判断当前语音信号是否为话音,若当前语音信号为话音,则提取话音中的基音后计算出基音周期和各子带清音和浊音数值参数;
步骤2、在步骤1计算得到的基音周期、清音和浊音数值参数的基础上对线谱对、基音值、增益参数、残差补偿增益和码本矢量的参数进行提取和量化,得到声音量化参数;
步骤3、提取步骤2的声音量化参数后,将该声音量化参数合成语音,经过压噪再提升语音质量,并当参数恢复失败后或语音合成失败后进行声音重建。
而且,所述步骤1具体步骤包括:
(1)对原始语音数字信号s(n)进行噪声抑制处理,得到噪声抑制后的语音数据s1(n)和原始数据s(n)的0~4000hz的声音频谱特性;
(2)采用vad激活检测技术判断噪声抑制处理后的当前语音信号是否为话音,得到话音数据s2(n);
(3)提取话音数据s2(n)的基音;
(4)计算出基音周期和各子带清音和浊音数值参数。
而且,所述步骤1第(1)步的具体步骤包括:
①采用高通滤波器对语音数据去除直流成分,提高高频分量,对低频进行衰减;
②加窗信号,采用窗长为n的海明窗,通过交叠傅里叶变换以得到在频谱上的能量分布,得到噪声抑制后的语音数据s1(n)、噪声抑制结果参数和原始语音数字信号s(n)的0~4000hz的声音频谱特性。
而且,所述步骤1第(2)步的具体方法为:
根据人耳的听觉特性,对噪声抑制后的语音数据s1(n)进行子带滤波并计算子带信号的电平,根据下示公式估计信噪比,和预先设定的门限值比较,进而判断当前语音信号是否是话音:
式中,a是当前帧的信号电平值,b为根据前几帧估计得到的当前信号电平值;
而且,所述步骤1第(3)步的具体方法为:
使用截止频率为bhz的低通滤波器对话音数据s2(n)进行低通滤波,并采用二阶逆滤波器对低通滤波后的语音数据进行逆滤波后,根据如下公式计算二阶逆滤波的输出信号的自相函数,提取基音:
其中,n为所述步骤1所述(1)提及窗函数窗长,sw(i)为所述步骤1第(3)步所述二阶逆滤波输出信号。
而且,所述步骤1第(4)步的具体步骤包括:
①将频域上0~4000等间隔的分为5个频段,分别为[0-500]hz,
[500-1000]hz,[1000-2000]hz,[2000-3000]hz,[3000-4000]hz,利用如下公式计算每个区间内带通信号的自相关函数:
其中,“t”为连续时间自变量,”τ”为输入信号时延“*”是卷积算符,(·)*f*()为取共轭;
②将同一时间函数在瞬时t和t+a的两个值相乘积的平均值作为时间t的函数,它是信号与延迟后信号之间相似性的度量,当延迟时间为零时,则成为信号的均方值,此时它的值最大,用该函数的最大值作为浊音强度,计算出各子带清浊音数值;
而且,所述步骤2的具体步骤包括:
(1)采用截止频率为ahz的高通滤波器对经过噪声抑制的语音数据滤波得到s3(n),加窗,计算自相关系数,用levinson-durbin递归算法求解线谱对参数,并采用三级矢量量化方案对得到线谱对参数进行参数量化;
(2)将步骤1第(3)步中计算得到的基音值量化:将包含基音值的整数区间线性映射到[0~z]内,将z个数用m1比特表示;
(3)将步骤1第(2)步中话音检测到的语音数据s2(n)经过二阶逆滤波器得到去除共振峰的影响的预测误差信号r(n),其中二阶你滤波器的系数为a1、a2≈1,增益参数用r(n)的rms表示,量化在对数域完成;
(4)将步骤1第(4)步的计算频域分段后带通信号值的相关函数得到的最大值,量化为m2比特;
(5)计算残差补偿增益,使用量化后的lsf参数计算线性预测系数,构成预测误差滤波器对输入语音s2(n)滤波,得到残差信号,残差信号长度为160点;
(6)使用窗长为160点的哈明窗是对预测残差加窗,将加窗信号补0至512点,对其进行512点的复数fft,再利用频谱峰点检测算法找到前x次谐波对应的傅立叶变换值;
(7)设p是量化基音,给定第i个谐波的初始位置为512i/p,峰点检测寻找以各次谐波的初始位置为中心,宽度在512/p个频率抽样内的最大峰值,该宽度被截短成一个整数;搜索的谐波次数限定为x和p/4中的较小者;谐波对应的系数随后被归一化,对此x维矢量,采用一个m3∈[0,48]比特的矢量码本进行量化,量化结果为m3∈[0,48]比特。
而且,所述步骤3的将声音量化参数合成语音,的具体方法为:
通过分成几个频带分别形成激励后相加通过合成滤波器,得到合成语音,然后再对合成语音进行后置滤波,得到解码合成语音数据,其中合成滤波器h(z)和后置滤波器hpf(z)的z变换传递函数如下:
h(z)=1/a(z)
其中a(z)为1-az-1,a为滤波器系数,上述所有公式中的z为复变量,具有实部和虚部,可令z=ejw,γ=0.56,β=0.75,μ由反射系数决定,μ的值取决于
而且,在所述步骤3之前还包括如下步骤:
初始化配置解码端,包括速率选择、以及解码端算法的参数、滤波器系数的初始化配置。
而且,在初始化配置解码端步骤之前还包括如下步骤:
扩大步骤3中的线性预测系数、激励增益参数和基因周期参数,分别得到扩展参数;
其具体步骤包括:
(1)扩大步骤3中得到的增益值量化区间,分子帧进行计算,得到扩展激励增益参数;
(2)将步骤3中当前帧lsp参数和量化后的上帧lsp参数分别减去lsp参数均值得到去均值后的矢量分别记为
(3)扩大步骤3中得到的基因值量化bit位,分子帧进行计算,每两个子帧进行一次,即将步骤3中(2)所设区间分为对应子帧的两部分,按照步骤2中(3)中自相关函数分别求取最大值及索引i,分别用
本发明的优点和有益效果:
1、本发明是通过分析语音时域上的连续性和频域上的相关性而实现的算法,能在低速率的情况下提供优良的语音质量、能在丢失300hz以下语音频率的应用中提供良好的语音质量且对方言有很强的适应性。
2、本发明分两阶段进行实际参数的提取,更准确和更少的运算量,更准确的参数提取提高了声音质量,更少的运算量为使用者节省运算资源。
3、本发明有别于低速声码器的地方,扩展了线性预测系数、激励增益参数和基因周期参数,即使在信道质量不好的存在误码的情况下由于编码结果携带更多信息,使得声音重建度也比窄带要高很多。
4、本发明通过噪声抑制功能抑制了噪声,提高了有噪音时提取的声音参数准确性,保证了声音质量。
5、本发明采用基于各种地方话训练的码本,对方言适应性强。
6、本发明是基于标准代码进行开发,规范可持续,易于移植到各种硬件平台。
附图说明
图1为本发明的工作原理图。
具体实施方式
以下结合附图对本发明实施例作进一步详述:
本发明的一种nvocplus高速宽带声码器的语音数据处理方法的输入参数是采样率为8000hz(每秒采集的语音信号样本数),分辨率为16比特的线性pcm语音数字信号;时域上,每20毫秒分析,频域上0~4000分多个频段进行分析。
一种nvocplus高速宽带声码器的语音数据处理方法,如图1所示,包括以下步骤:
步骤1、初始化配置编码端,包括速率选择、编码端所用参数、系数以及滤波器编码端算法的初始化配置;
步骤2、编码端对原始语音数字信号的初始化配置和分析处理,首先对原始语音数字信号进行噪声抑制处理,然后判断当前语音信号是否为话音,若当前语音信号为话音,则提取话音中的基音后计算出基音周期和各子带清音和浊音数值参数;
所述步骤2具体步骤包括:
(1)噪声抑制:对原始语音数字信号s(n)进行噪声抑制处理,得到噪声抑制后的语音数据s1(n)和原始数据s(n)的0~4000hz的声音频谱特性;
所述步骤2第(1)步的具体步骤包括:
①采用高通滤波器对语音数据去除直流成分,提高高频分量,对低频进行衰减;
②加窗信号,采用窗长为n的海明窗,通过交叠傅里叶变换以得到在频谱上的能量分布,得到噪声抑制后的语音数据s1(n)、噪声抑制结果参数和原始语音数字信号s(n)的0~4000hz的声音频谱特性。
(2)话音检测:采用vad激活检测技术判断噪声抑制处理后的当前语音信号是否为话音,得到话音数据s2(n);
所述步骤2第(2)步的具体方法为:
根据人耳的听觉特性,对噪声抑制后的语音数据s1(n)进行子带滤波并计算子带信号的电平,根据下示公式估计信噪比,和预先设定的门限值比较,进而判断当前语音信号是否是话音:
式中,a是当前帧的信号电平值,b为根据前几帧估计得到的当前信号电平值;
(3)基因估计第一阶段:提取话音数据s2(n)的基音;
所述步骤2第(3)步的具体方法为:
使用截止频率为bhz的低通滤波器对话音数据s2(n)进行低通滤波,并采用二阶逆滤波器对低通滤波后的语音数据进行逆滤波后,根据如下公式计算二阶逆滤波的输出信号的自相函数,提取基音:
其中,n为所述步骤1所述(1)提及窗函数窗长,sw(i)为所述步骤2第(3)步所述二阶逆滤波输出信号。
在本实施例中,在频域,语音信号具有峰值和峰值的频率是基音的倍数关系,初步计算出可能的基音值或基音范围值;在时域,语音具有短时自相关性,若当原信号具有周期性,那么它的自相关函数也具有周期性,并且周期性与原信号的周期相同。且在周期整数倍时会出现峰值。清音信号无周期性,它的自相关函数会随着帧长的增大呈衰减趋势,浊音具有周期性,它的自相关函数在基因周期整数倍上具有峰值,使用截止频率为bhz的低通滤波器对语音数据s2(n)进行低通滤波,目的去除高频信号对基音提取的影响,其次采用二阶逆滤波器对低通滤波后的语音数据进行逆滤波,去除共振峰的影响,计算二阶逆滤波的输出信号的自相关函数,提取基音:
在该帧的自相关函数中,除去第一个最大值后,该帧的基音值即为采样率/出现最大值时的帧长。
(4)多子带清浊音判决第一阶段:计算出各子带清浊音数值
所述步骤2第(4)步的具体步骤包括:
①将频域上0~4000等间隔的分为5个频段,分别为[0-500]hz,[500-1000]hz,[1000-2000]hz,[2000-3000]hz,[3000-4000]hz,利用如下公式计算每个区间内带通信号的自相关函数:
其中,“*”是卷积算符,(·)*f*()为取共轭;
②将同一时间函数在瞬时t和t+a的两个值相乘积的平均值作为延迟时间t的函数,它是信号与延迟后信号之间相似性的度量,当延迟时间为零时,则成为信号的均方值,此时它的值最大,用该函数的最大值作为浊音强度,计算出各子带清浊音数值;
步骤3、在步骤2计算得到的基音周期、清音和浊音数值参数的基础上对线谱对、基音值、增益参数、残差补偿增益和码本矢量的参数进行提取和量化,得到声音量化参数;
所述步骤3的具体步骤包括:
(1)采用截止频率为ahz的高通滤波器对经过噪声抑制后的语音数据滤波得到s3(n),加窗长为n2的汉明窗,计算自相关系数,用levinson-durbin递归算法求解线谱对参数(即预测参数即lsf参数),并采用三级矢量量化方案对得到线谱对参数进行参数量化,得到m1比特;
(2)将步骤2第(3)步中计算得到的基音值量化:将包含基音值的整数区间线性映射到[0~z]内,将z个数用m2比特表示;
(3)将步骤2第(2)步中话音检测到的语音数据s2(n)经过二阶逆滤波器得到去除共振峰的影响的预测误差信号r(n),其中二阶滤波器的系数为a1、a2≈1,激励增益参数用r(n)的rms(平方的均值平凡根)表示,量化在对数域完成;
(4)将步骤2第(4)步的计算频域分段后带通信号值的相关函数得到的最大值(即清浊音状态值),量化为m3比特;
(5)计算频谱补偿增益,使用量化后的lsf参数计算线性预测系数,构成预测误差滤波器对输入语音s2(n)滤波,得到残差信号,残差信号长度为160点;
(6)使用窗长为160点的哈明窗是对预测残差加窗,将加窗信号补0至512点,对其进行512点的复数fft,再利用频谱峰点检测算法找到前x次谐波对应的傅立叶变换值;
(7)设p是量化基音,给定第i个谐波的初始位置为512i/p,峰点检测寻找以各次谐波的初始位置为中心,宽度在512/p个频率抽样内的最大峰值,这个宽度被截短成一个整数。要搜索的谐波次数限定为x和p/4中的较小者。这些谐波对应的系数随后被归一化,对此x维矢量,采用一个m4∈[0,48]比特的矢量码本进行量化,量化结果为m4∈[0,48]比特。
步骤4、扩大步骤3中的线性预测系数、激励增益参数和基因周期参数,分别得到扩展参数;
由于高速声码器带宽更大,所以可携带的比特位更多,为了提高基因检测的准确度,再提高基音检测的分辨率可靠性并分子帧进行计算。
在本实施例中,以12.2kbps为例,在这里子帧的含义表示为,每40个采样点(5ms数据)。
所述步骤4的具体步骤包括:
(1)扩大步骤3中得到的增益值量化区间,分子帧进行计算,得到扩展激励增益参数;
(2)将步骤3中当前帧lsp参数和量化后的上帧lsp参数分别减去lsp参数均值得到去均值后的矢量分别记为
(3)扩大步骤3中得到的基因值量化bit位,分子帧进行计算,每两个子帧进行一次,即将步骤3中(2)所设区间分为对应子帧的两部分,按照步骤2中(3)中自相关函数分别求取最大值及索引i,分别用
在本实施例中,上述所述扩展参数,均为原参数前提下增加扩展信息位后的结果。不单独作为编码得到的新参数。
步骤5、初始化配置解码端,包括速率选择(2.2kbps还是2.4kbps)、以及解码端算法的参数、滤波器系数等的初始化配置;
步骤6、提取步骤3和步骤4的声音量化参数后,将该声音量化参数合成语音,经过压噪再提升语音质量,并当参数恢复失败后或语音合成失败后进行声音重建。
所述步骤6的具体方法为:
每一帧信号编码后的结果均为含线谱对、增益、基因周期、清浊音、矢量码本等量化成bit位后组成的数值。这些参数中,噪声抑制结果参数决定当环境噪声过大的音频数据段,是否改用静音或者舒适的环境音替代,基音周期及清浊音值决定解码端用来合成语音信号的激励源,而根据上述编码端步骤1第(4)步,由于清浊音涵盖5个频段,故通过分成几个频带分别形成激励后相加通过合成滤波器及后置滤波,得到解码合成语音数据。其中,如果是清音帧,即清浊音数值bit全为0,采用随机数作为激励源,如果是浊音帧,则选取一周期性脉冲序列通过一个全通滤波器来生成激励源,激励源幅度受增益参数加权,样点长度取决于基因周期大小。全通滤波器h1(z)、合成滤波器h2(z)和后置滤波器hpf(z)的z变换传递函数如下:
其中a(z)为1-az-1,a为滤波器系数,由步骤4线性预测参数经p变换得到,p变换为高等数学变换,上述所有公式中的z为复变量,具有实部和虚部,可令z=ejw,γ=0.56,β=0.75,μ由反射系数决定,μ的值取决于
可理解的,编解码的算法是对应的,解码端的输入参数格式和编码端的输出参数格式也是对应的,解码器解码一帧输出160个采样值,调用时需要和编码器速率统一。
需要强调的是,本发明所述实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



