
 商标分类
商标分类  商标转让
商标转让 
通过语音命令的基于位置的语音识别系统的制作方法
 2021-01-28 12:01:25|
2021-01-28 12:01:25| 293|
293| 起点商标网
起点商标网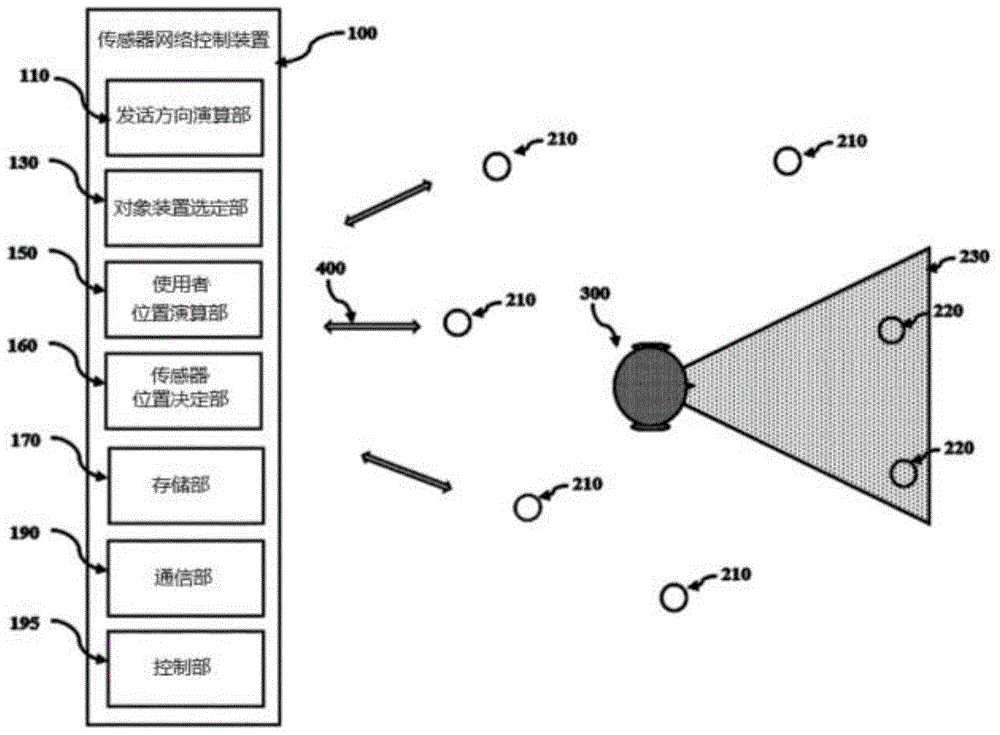
本发明涉及通过语音命令的位置追踪及基于位置的语音识别系统,特别是涉及一种在包括麦克风在内的多个装置以传感器网络连接的情况下容易地识别使用者语音命令的位置追踪装置及基于位置的语音识别服务。本研究是作为产业通商资源部事业化衔接技术开发项目获得支援的研究。
背景技术:
最近,通过语音命令来控制多样设备的技术正在逐渐普遍化。特别是语音命令的应用正在扩散到冰箱、tv等家电设备或照明等多样装置。但是,随着语音命令应用的扩散,发生使用者不希望的动作的可能性也渐渐提高。在多个设备使用相同语音命令的情况下,例如在诸如打开开关的动作等多个设备通过相同语音命令的发话而运转的情况下,在并非使用者所希望的设备会出现意外动作的可能性增大。
为了解决这种问题,现有技术使用通过照相机或红外线光标来掌握使用者的视线的方法(美国专利第9825773号、美国专利第6970824号),或利用在同一设备内安装多个麦克风来推定声源方向的方法(美国专利第9554208号)。
在如现有技术所示利用照相机或红外线光标的情况下,或在同一设备内安装多个麦克风的情况下,由于需要追加的传感器,因而从制造厂商立场而言,费用负担大,体现多种传感器设备所需的开发负担也大。
因此,迫切要求开发一种技术,能够在下达语音命令时掌握使用者的意图,通过语音来控制希望的设备的希望的动作。
技术实现要素:
为了解决上述问题,本发明旨在提供一种能够利用多个麦克风来决定使用者的发话方向,对处在所决定的发话方向范围内的命令对象设备进行特定的基于位置的语音识别服务。
特别是本方法的目的在于,在包括麦克风在内的多个装置通过传感器网络连接的情况下,容易地识别使用者的语音命令。因此,掌握成为语音命令对象的各装置的相对位置,通过语音命令接入的时间差异来追踪使用者的位置及方向。基于使用者的位置及方向,执行该命令的解析。
为了解决所述技术课题,本发明的基于位置的语音识别系统可以包括:分别包括至少一个麦克风的多个语音命令接收装置;及传感器网络控制装置,所述传感器网络控制装置通过传感器网络而与所述多个语音命令接收装置连;所述传感器网络控制装置可以包括:传感器位置决定部,所述传感器位置决定部决定所述多个语音命令接收装置的相对位置;使用者位置演算部,所述使用者位置演算部基于所述相对位置来演算使用者的位置;发话方向演算部,所述发话方向演算部基于所述多个语音命令接收装置各自的语音大小,演算换算语音大小,基于换算语音大小来决定所述使用者的发话方向范围;及对象装置选定部,所述对象装置选定部根据所述发话方向范围,选定所述多个语音命令接收装置中成为语音命令对象的对象语音命令接收装置;所述换算语音大小可以是假定所述多个语音命令接收装置处于距所述使用者相同距离时的语音大小。
此时,所述发话方向演算部可以利用声音衰减模型求出所述多个语音命令接收装置各自的语音大小后,基于所述多个语音命令接收装置各自的语音大小,演算换算语音大小。
现有技术作为用于类推发话方向的方法,使用使用者的视线或追加的照相机或红外线光标等。这种追加设备存在费用负担、体现及使用的困难等缺点。但是,本发明利用接收语音命令的麦克风,基于使用者的位置而容易地掌握意图。另外,本发明不仅利用使用者位置信息,还可以利用下达命令的发话方向信息,向使用者提供进一步提高的服务。
这种方法可以用于基于传感器网络(sensornetwork)、物物通信(machinetomachine:m2m)、机器类型通讯(machinetypecommunication:mtc)、物联网(internetofthings:iot)等技术的智能型服务(智能家庭、智能楼宇等)、数字教育、安保及安全相关服务等多样的服务。
以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
附图说明
图1是显示本发明实施例的基于位置的语音识别服务系统的框图;
图2是本发明实施例的基于位置的语音识别服务动作流程图;
图3是本发明实施例的发话方向决定动作流程图;
图4是显示本发明实施例的语音命令接收装置的图;
图5是显示本发明实施例的定向麦克风的极性图(polarpattern)的图表;
图6是用于说明本发明实施例的发话方向决定动作的图;
图7是用于说明本发明实施例的发话方向决定动作的图;
图8是本发明实施例的对象装置选定部的详细框图。
具体实施方式
以下内容只对发明的原理进行举例。因此,虽然在本说明书中未明确说明或图示,但从业人员也可以体现发明原理而发明发明的概念与范围所包括的多样装置。另外,本说明书中列举的所有附条件术语及实施例,原则上只用于明确理解发明的概念的意图,应理解为不对如此特别列举的实施例及状态进行限制。
通过与附图相关的如下详细说明,上述目的、特征及优点将更加明确,因此,发明所属技术领域的普通技术人员可以容易地实施发明的技术思想。下面参照附图进行说明。
图1是显示本发明实施例的基于位置的语音识别服务系统的框图。
如果参照图1,本发明实施例的基于位置的语音识别服务系统包括通过传感器网络连接的包括至少一个以上麦克风的语音命令接收装置210、220及传感器网络控制装置100。此时,传感器网络控制装置100可以为手机、人工智能秘书(智能音箱)、个人计算机(pc)、个别语音命令接收装置210、220中某一种、可穿戴设备(智能手表等)、服务器等能够执行计算功能的多样装置中某一种。
使用者300发出语音命令后,语音命令接收装置210、220接收使用者300的语音命令,将语音命令、语音到达时间及语音大小等传输给传感器网络控制装置100。其中,本发明的“语音命令”是全部涵盖通过使用者的语音发话而要求语音命令接收装置210、220运转的命令及要求语音命令接收装置210、220回答的提问的概念。例如,使用者朝向tv下达“转到7频道”命令及朝向tv提出“现在看的是哪个频道?”的提问,也包括于本发明的“语音命令”的范畴。
此时,传感器网络控制装置100在有使用者发话的情况下,可以确认发话内容是语音命令还是与传感器网络内的语音命令接收装置无关的内容。
其中,语音命令接收装置210、220可以意味着包括能够通过麦克风输入声音的传感器在内的所有装置。例如,包括照明开关、tv或冰箱等各种家电设备或移动电话等其他包括麦克风的各种设备及传感器,均属于语音命令接收装置。
根据图1,传感器网络控制装置100可以包括发话方向演算部110、对象装置选定部130、使用者位置演算部150、传感器位置决定部160、存储部170、通信部190及控制部195。此时,传感器网络控制装置100可以通过通信部190,连接到上述语音命令接收装置210、220和传感器网络400。
此时,传感器网络400既可以是通过共享器或路由器等连接的内部网,也可以是互联网、lora(longrange:远程)网、nb-iot(narrowband-internetofthings:窄带互联网)、lte网等外部网。另外,传感器网络控制装置100例如可以是服务器、pc、平板电脑、移动电话等具有计算功能的装置。
另外,通信部190作为用于与语音命令接收装置210、220进行通信的装置,可以为wifi(无线保真)、zigbee(紫蜂)、bluetooth(蓝牙)等无线通信装置,可以为plc(ethernet(以太网),powerlinecommunication(电力线传输))等有线通信装置。
下面参照图2至图6,对传感器网络控制装置100的具体动作进行说明。
传感器网络控制装置100首先可以演算、推定连接于传感器网络的各装置的相对位置。(步骤s510)
推定相对位置的方法例如可以使用如下方法。
1)传感器网络控制装置100的传感器位置决定部160可以基于向传感器网络400传递的信号大小,在传感器网络400上的语音命令接收装置中至少一个语音命令接收装置210、220中安装有信标(beacon)的情况下,可以基于信标信号大小,演算连接于传感器网络的各装置的相对位置。或者,语音命令接收装置210、220中某一者可以具备发生发挥信标作用的特定信号的装置,传感器位置决定部160可以基于不同语音命令接收装置接收的信号强度,演算该特定信号到达的方向及与发挥信标作用的语音命令接收装置210、220的相对位置,演算无线传感器网络400上的各语音命令接收装置210、220的相对位置。
此时,在取代信标信号,传感器网络400为无线通信网时,也可以利用无线通信信号的信号大小(例如,rssi(receivedsignalstrengthindication:接收信号强度指示)),演算连接于传感器网络的各装置的相对位置。
2)或者,传感器网络控制装置100的传感器位置决定部160可以在最初设置时,或在需要时,执行演算相对位置的模式。此时,在传感器网络400的各节点释放特定频率的声音,通过语音命令接收装置210、220的麦克风接收。释放的特定频率的声音,可以分析输入麦克风的值,制作关于根据各节点(语音命令接收装置)周围各位置决定的声音折射/反射/吸收等物理特征的图(map)。可以利用这种关于物理特征的图,演算各语音命令接收装置210、220的传感器网络上的相对位置。
此时,所述麦克风可以利用波束形成麦克风(beamformingmicrophone)。波束形成麦克风构成得根据其内部包括的麦克风阵列位置、声音入射角而决定其衰减率。可以基于波束形成麦克风及演算的衰减率,演算各语音命令接收装置210、220的传感器网络400上的相对位置。
3)或者,也可以通过使用各语音命令接收装置210、220的追加设备,演算相对位置。
例如,各语音命令接收装置210、220可以追加具备led灯。此时,各语音命令接收装置210、220根据特定规则使led灯点亮/熄灭。而且,便携装置的照相机接收led灯的点亮/熄灭。而且,传感器位置决定部160基于是否接收led灯点亮/熄灭、接收方向等,感知各语音命令接收装置210、220的相对位置。可以综合所感知的位置信息,演算传感器网络400上的语音命令接收装置210、220的相对位置。
4)或者,传感器网络400的传感器位置决定部160也可以由使用者300直接将各语音命令接收装置210、220的物理位置输入系统,从而利用该位置信息。
上面列举了传感器位置决定部160通过多样方法来决定语音命令接收装置210、220的相对位置的情形,但除上述方法外,从业人员也可以通过多样方法,掌握各语音命令接收装置210、220的相对位置。
然后,使用者300发出语音命令后,各语音命令接收装置210、220的麦克风接收语音命令210、220。(步骤s520)
另一方面,传感器网络控制装置100的使用者位置演算部150利用接入各语音命令接收装置内传感器(麦克风)的语音信号的接入(到达)时差(timedifferenceofarrival:tdoa)及各语音命令接收装置的相对位置信息,演算使用者300的相对位置。(步骤s530)
此时,可以在各语音命令接收装置内安装多个麦克风,增加位置追踪的容易性。
另一方面,当传感器网络内的语音命令接收装置210、220的总麦克风个数或接收语音命令的麦克风个数少而难以确定地求出使用者的位置时,可以利用如下方法进行近似推定。
1)例如,可以使用如下方法,即,将设置有传感器网络的室内空间划分为既定区域,根据接入麦克风的语音命令的大小来推定使用者的位置并映射于所划分的区间。
2)或者,例如可以基于从至少2个语音命令接收装置210、220演算的距离,将使用者的位置可能区域重叠的位置推定为使用者所在区域。
3)或者,可以基于传感器网络内的语音命令接收装置210、220所在位置的信息、相应场所的地图信息及关于语音命令在相应场所室内环境的哪个部分被反射/折射/吸收的追加信息,推定使用者的位置。
4)或者,使用者持有的移送设备发生无线信号或信标信号,传感器网络400上的各语音命令接收装置接收该信号。
此时,可以基于传感器网络400上的语音命令接收装置接收的信号大小、到达角度信息来推定使用者的位置。
5)或者,可以基于使用者的脚步声,类推关于使用者的步行速度、方向的信息,对该信息进行累积而类推使用者的当前位置。
6)或者,也可以在使用者持有的照相机拍摄的影像或图像、各无线网络的语音命令接收装置拍摄的影像或图像之间,通过特征点匹配来推定使用者的相对位置。
除上述方法之外,从业人员除声音之外,可以利用可见光、红外线、紫外线等来演算传感器网络400上的各语音命令接收装置的相对位置。
而且,传感器网络控制装置100的发话方向演算部110可以演算、决定使用者300的发话方向。(步骤s540)
下面参照图3至图6,说明关于决定发话方向的详细动作。
根据图3,发话方向演算部110应用基于各语音命令接收装置210、220的外壳的影响或麦克风的方向性的声音衰减模型,补正根据使用者300位置的相对方向决定的接入各语音命令接收装置210、220的音量。(步骤s532)
包括麦克风215的语音命令接收装置210、220通常具有外壳212,因而在接收语音的情况下,语音的接收强度会因方向而异。更具体而言,参照作为语音命令接收装置210、220以照明开关体现的实施例的图4进行说明。不过,本发明的语音命令接收装置210、220不限于此。
图4(a)是显示本发明实施例的语音命令接收装置210、220为照明开关时的图,图4(b)是显示图4(a)的照明开关的a-a'部分的截断面的图。
此时,通过麦克风215前方的开口部213传递的语音217与穿过外壳212传递的语音219具有大小的差异,声音衰减模型具有差异。
或者,当麦克风215具有方向性时,例如在使用波束形成(beamforming)麦克风的情况下,具有基于方向的极性图(polarpattern)。图5是对麦克风215表现出方向性的极性图的示例图表。因此,此时,定向麦克风在沿特定方向接入声音时,输入更大的声音。
因此,本发明的实施例为了导出准确的发话方向,应用基于麦克风215的方向性或外壳的影响的声音衰减模型,补正接入各语音命令接收装置210、220的音量。
此时,语音命令接收装置210、220为了导出准确的方向,还可以包括地磁传感器等辅助性方向传感器。
或者,在应用声音衰减模型的情况下,如果有不发生因方向导致的衰减或发生几乎可以无视的因方向导致衰减的语音命令接收装置210、220,则也可以甄别这种语音命令接收装置210、220,使用所甄别的语音装置210、220的声音大小。
然后,发话方向演算部110利用各语音命令接收装置210、220及所演算的使用者的位置信息,应用基于距离的声音衰减模型,换算、演算各装置处于相同距离时的音量。(步骤s534)
如果参照图6(a),在使用者300发话的情况下,脸朝向的方向(发话方向,
因此,为了利用声音大小来导出发话方向,步骤(s532)演算的语音大小如图6(b)所示,换算为假定语音命令接收装置在距使用者300相同距离处的语音大小。当是在发话方向的语音命令接收装置220时,换算的语音大小221算出得大,当是不在发话方向的语音命令接收装置210时,换算的语音大小211算出得相对较小。因此,可以通过这种语音大小的换算,准确地求出发话方向。
最后,基于换算的音量,应用不同发话方向的相同距离的各传感器接收的音量大小相关模型,演算、决定使用者的发话方向范围(参照图1的230)。
(步骤s536)
此时,发话方向范围可以以换算的语音大小211最大的方向为中心,确定为预先确定的范围(例如,以换算的语音大小211最大的方向为中心,向左/右侧的15度范围)。
另外,在换算的语音大小211最大的方向的语音命令接收装置与第二大的方向的语音命令接收装置彼此相邻的情况下,以两个语音命令接收装置的重心或中间角度为中心,预先确定的范围(例如,30度)可以成为发话方向。
此时,当接受语音输入的麦克风的个数难以确定地求出使用者方向时,利用如下近似推定的方法。
1)例如,如图6(a)所示,预先求出由发话方向决定的语音大小的比,算出基于发话方向的语音大小模型后,求出所换算的语音大小间的比,应用于基于发话方向的语音大小模型,可以近似求出使用者300的发话方向。
2)或者,存储不受外部因素影响的通常状态下的使用者语音命令大小后,可以基于无外部因素影响的语音命令大小,近似推定发话方向。
具体而言,当接入语音命令时,可以基于无外部影响的语音命令大小及由发话方向决定的大小衰减率的模型,类推该命令方向。或者,当接入语音命令时,可以利用室内环境下声音反射/吸收等物理特性的地图信息,类推使用者的发话方向。
3)或者,可以通过使用者输入波束形成麦克风的使用者语音命令方向信息、从使用者外部进入的外部声音的方向信息(不存在外部声音时,可以置换为各无线网络中人为地发生的声音)、各无线网络的语音命令接收装置观察的方向的信息,决定使用者的发话方向。此时,波束形成麦克风可以置换成外壳为特殊形态的麦克风,使得只能在特定方向接受声音。
4)或者,如图7所示,在各语音命令接收装置210、220位于所使用空间的边缘的情况下,假定使用者在该使用空间的内部下达命令后,可以比较各语音命令接收装置在使用空间内部感知的强度,类推使用者的发话方向。
5)或者,假定各语音命令接收装置在相同距离后,也可以基于换算音量大小,将换算音量大小最大的方向决定为发话方向。
如果再次参照图2,传感器网络控制装置100的对象装置选定部130在解析使用者300的语音命令的过程中,参照发话方向范围230及使用者300的位置信息,导出成为语音命令对象的语音命令接收装置220。(步骤s550)
此时,为了更容易地解析使用者300的语音命令,可以甄别使用者发话方向范围230包括的语音命令接收装置220,将语音命令对象限定为甄别的语音命令接收装置220,容易地进行语音命令对象决定过程。
如果参照图8,为了解析这种语音命令,对象装置选定部130包括对象装置学习部135及对象装置决定部137。
对象装置学习部135执行用于选定对象装置的机器学习。
机器学习时,参照语音命令的上下文(contextual)、环境(environmental)要素来执行学习。特别是为了参照上下文、环境要素,传感器网络控制装置100的对象装置学习部135可以具备关于各语音命令接收装置210、220的属性信息。
例如,所述属性信息可以包括相应语音命令接收装置210、220的相或绝对位置信息、功能信息、聚类信息、功能的运转顺序及语音命令历史。
相应语音命令接收装置210、220的相对或绝对位置信息,意味着在最初步骤s510中掌握的各语音命令接收装置的相对位置或绝对位置。
功能信息可以还包括相应语音命令接收装置210、220的种类(例如是照明装置还是扬声器等)、各装置的详细功能信息(例如冰箱故障去除功能或空调的送风/制冷模式等详细功能信息)。
聚类信息意味着划分室内空间的信息,例如可以为卧室、里屋、客厅等室内空间信息。
功能的运转顺序用于掌握上下文意义,例如,当一个语音命令接收装置210、220为电饭锅时,可以为最初加热、焖饭模式及保温模式等运转顺序。或者,也可以为多种语音命令接收装置210、220的统合运转顺序。例如,可以是洗衣机运转后烘干机进行运转,或者冰箱门打开后微波炉进行运转的信息。
语音命令历史可以包括使用者信息、发话方向、发话内容、使用者发话位置信息及语音命令是否成功,可以每当发出语音命令时进行存储。
使用者信息是从通过使用者既定时间分量的语音发声而输入的语音命令,提取与使用者语音特征相应的信息后,将其用于训练数据而生成说话者模型,将相应说话者登记为使用者,从而构成说话者识别器,以此为基础,用于利用使用者发出的语音,在登记使用者中识别特定使用者。
发话方向、发话内容及使用者发话位置信息,意味着在发出语音命令时,发话方向演算部110掌握的发话方向、文本形态的语音命令及使用者位置演算部150演算的发话位置。
语音命令是否成功是掌握语音命令是否正常解析的信息,在特定时间区间,可以按特定发话方向、相同发话内容执行连续命令,或者根据连续命令中是否存在否定语(例如“不”等)而决定。例如,当在发出“关掉他”的命令后,在tv关闭后,接续“不,关闭照明”的命令时,“关掉他”的语音命令可以存储为对象未正常选定的情形。
对象装置学习部135可以利用上述属性信息,演算并存储特定使用者向某发话方向、对某对象装置下达何种内容命令的几率是否高。例如,在使用者a晚上9点向天花板方向发出关闭照明的语音命令的可能性高的情况下,可以基于特定使用者的命令内容/发话方向,演算选择特定对象装置的几率。
对象装置学习部135例如可以通过支持向量机(supportvectormachine)、隐马尔可夫模型(hiddenmarkovmodel)、回归分析(regression)、神经网络(neuralnetwork)、朴素贝叶斯分类(naivebayesclassification)等方法进行学习。
对象装置决定部137基本上参照发话方向范围230及使用者300的位置信息,导出成为语音命令对象的语音命令接收装置220。但是,追加地,对象装置决定部137可以基于上述对象装置学习部135进行机器学习的属性信息来掌握语音命令的上下文意义。
此时,在语音命令的意图与所指定的语音命令接收装置210、220明确的情况下,可以无需上下文意义的解析而执行语音命令。
例如,当为“关掉里屋照明”的命令时,执行的语音命令的意图(关掉)与将执行语音命令的语音命令接收装置210、220明确,因而不需要另外的上下文意义解析。
但是,在为将代词放入语音命令等不明确命令的情况下,可以利用发话方向及使用者位置来解析语音命令的上下文意义。
例如,在有“关掉他”的语音命令的情况下,由于对象语音命令接收装置210、220不明确,需要上下文解析。
此时,为了解析代词“他”,可以利用上述属性信息、使用者位置及发话方向信息。
在使用者位置在里屋,使用者朝向照明器具所在的天花板方向发出语音命令的情况下,可以通过上下文解析,关掉照明器具。
特别是当为连续命令时,在发话方向的变化为预先确定的范围以内的情况下,可以视为向通过上下文地同一语音命令接收装置210、220下达命令。例如,在“打开里屋照明”命令后,当使用者的发话方向变化在预先确定的范围以内再次接入“再关掉他”的语音命令时,可以根据上下文解析,将对象设备决定为照明器具。
或者,将其他追加要素的位置(例如,床、书桌的位置)存储于传感器网络控制装置100的存储部,使用者300在床上下命令时,也可以参照在床上发出语音命令这一点,甄别对象语音命令接收装置。
最后,传感器网络控制装置100的存储部170可以存储语音命令对象装置、使用者的位置及发话方向的信息。(步骤s560)因此,存储的信息在稍后有语音命令时,作为解析语音命令所需的数据,可以由对象装置学习部135进行利用。
例如,将关于在哪个位置、朝向哪个方向、出于何种意图对对象下达命令的信息作为历史(history)进行积累、存储及学习,相应命令反复或进来类似命令时,以这种学习的内容为基础,容易地对其进行解析。例如,使用者300夜间时段在床上将天花板方向作为发话方向反复进行关闭照明开关的行为时,可以组合这种信息,在下次使用者发出语音命令时,在甄别对象语音命令接收装置并进行控制方面加以参照。
追加地,控制部195可以向选定的对象语音命令接收装置220发送控制信号。例如,控制部195在对象语音命令接收装置220为照明开关或照明系统时,可以通过控制信号,控制照明开关的点亮/熄灭。或者,例如当对象语音命令接收装置220为电视机时,控制部195可以发送电视机的开启/关闭、调节音量、变更频道等多样的控制信号。或者,当对象语音命令接收装置220为音响时,控制部195可以发送音响的开启/关闭、调节音量、变更频道等多样的控制信号。
不过,如前所述,调节音量、变更频道等对音响、tv而言可能是重复的命令,开启/关闭(点亮/熄灭)对照明、音响、tv等而言可能是重复的命令。因此,语音命令的内容可能重复。但是,根据本发明,由于考虑了使用者的发话方向,可以防止并非所愿的设备因重复的语音命令而进行并非所愿的运转。
因此,本发明只利用接收语音命令的麦克风,根据该使用者的位置及方向而容易地掌握意图。不仅是基于位置的信息,还可以使用下达命令的方向信息,向使用者提供进一步提高的服务。
这种方法作为用于传感器网络(sensornetwork)、物物通信(machinetomachine:m2m)、机器类型通讯(machinetypecommunication:mtc)、物联网(internetofthings:iot)的方法,可以用于智能型服务(智能家庭、智能楼宇等)、数字教育、安保及安全相关服务等。
以上说明只不过是示例性说明本发明的技术思想,本发明所属技术领域的普通技术人员可以在不超出本发明本质特性的范围内,进行多样修订、变更及置换。
因此,本发明公开的实施例及附图,并非用于限定而是用于说明本发明的技术思想,本发明技术思想的范围不由这种实施例及附图所限定。本发明的保护范围应根据下面的权利要求书进行解释,处于与之同等范围内的所有技术思想应解释为包含于本发明的权利范围。
工业实用性
现有技术作为用于类推发话方向的方法,使用使用者的视线或追加的照相机或红外线光标等。这种追加设备存在费用负担、体现及使用的困难等缺点。但是,本发明利用接收语音命令的麦克风,基于使用者位置而容易地掌握意图。另外,本发明不仅利用使用者位置信息,还可以利用下达命令的发话方向信息,向使用者提供进一步提高的服务。
这种方法可以用于基于传感器网络(sensornetwork)、物物通信(machinetomachine:m2m)、机器类型通讯(machinetypecommunication:mtc)、物联网(internetofthings:iot)等技术的智能型服务(智能家庭、智能楼宇等)、数字教育、安保及安全相关服务等多样的服务。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



