
 商标分类
商标分类  商标转让
商标转让 
基于时序神经网络模型补全语音数据的方法与流程
 2021-01-28 12:01:29|
2021-01-28 12:01:29| 300|
300| 起点商标网
起点商标网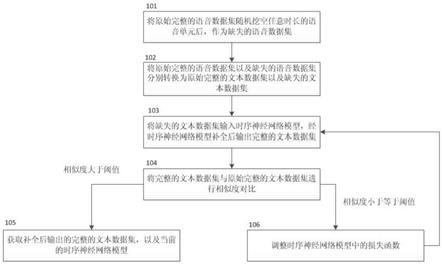
[0001]
本发明涉及语音技术领域,具体涉及一种基于时序神经网络模型补全语音数据的方法。
背景技术:
[0002]
随着互联网的快速发展,生活变得越来越智能化,因此人们也越来越习惯地使用智能终端完成各种需求。语音交互作为智能终端中人机交互主流的交流应用之一,也是越来越受到用户的青睐。智能终端都是基于使用的音频数据集对用户输入的语音进行识别,因此终端使用的语音数据集的准确性严重影响着智能终端所作出的反馈。
[0003]
由于语音采集输入语音过程中可能出现的意外,同时语音类数据集由于来源广且标注人员良莠不齐,常出现很多的错误。这些错误里最难以解决的就是语音数据本身的缺失。这样语音数据由于年龄、性别、音质、口音、使用场景、录音设备等原因而识别错误导致无法识别,还造成成段音频数据的缺失。对于这些实际场景,传统的修正方法是对语音反复多次的识别,人工在标注语音数据集时也反复确认,但实际效果并不理想。
[0004]
目前现有技术都是如何对语音进行高质量高效的识别,对语音数据的补全也仅仅是人工辅助的形式,效率非常低。
技术实现要素:
[0005]
本发明的目的是提供一种基于时序神经网络模型补全语音数据的方法,实现了对残缺语音数据自动补全,极大地提高了效率,并且同时对补全后的语音数据进行验证,保证了语音补全的正确率。
[0006]
本发明采取如下技术方案实现上述目的,基于时序神经网络模型补全语音数据的方法,包括:
[0007]
步骤(1)、将原始完整的语音数据集随机挖空任意时长的语音单元后,作为缺失的语音数据集;
[0008]
步骤(2)、将原始完整的语音数据集以及缺失的语音数据集分别转换为原始完整的文本数据集以及缺失的文本数据集;
[0009]
步骤(3)、将缺失的文本数据集输入时序神经网络模型,经时序神经网络模型补全后输出完整的文本数据集;
[0010]
步骤(4)、将完整的文本数据集与原始完整的文本数据集进行相似度对比,若相似度大于设置的阈值,则获取补全后输出的完整的文本数据集,以及当前的时序神经网络模型,否则进入步骤(5);
[0011]
步骤(5)、调整时序神经网络模型中的损失函数,进入步骤(3)。
[0012]
进一步的是,基于时序神经网络模型补全语音数据的方法,还包括:
[0013]
步骤(6)、提取任意时长与挖空的语音单元相邻的前后语音单元,并将挖空的语音单元转化为挖空的文本数据;
[0014]
步骤(7)、将提取出的语音单元转换为对应的文本数据,并提取出该语音单元的音色特征集;
[0015]
步骤(8)、将对应的文本数据输入所获取的时序神经网络模型,得到补全的部分文本数据;
[0016]
步骤(9)、将补全的部分文本数据与挖空的文本数据拼接起来,并将拼接后的文本数据转换为语音数据,再结合提取出的音色特征集来还原原始音频数据集;
[0017]
步骤(10)、将还原的原始音频数据集与原始完整的语音数据集进行对比来验证语音补全的相似度。
[0018]
进一步的是,在步骤(2)中,还包括对文本数据进行相应预处理,去掉多余的词组。
[0019]
进一步的是,所述时序神经网络模型包括多个lstm单元的补全神经网络,神经网络中遗忘率设置为0.05,dropout设置为0.1。
[0020]
进一步的是,所述lstm提取的特征会通过一个全连接层得到最后的补全词汇结果。
[0021]
本发明采用对完整语音数据集进行挖空,并将相关语音数据转化文本数据,利用文本数据上下文紧密的关系,对时序神经网络模型进行不断优化,直到补全后的完整数据集相似度达到要求,通过优化后的时序神经网络模型进行语音数据补全,实现了对残缺语音数据自动补全,在补全后通过提取挖空部分相邻语音单元的语音数据以及音色特征集来还原原音频数据集的方式来进行验证,保证了语音补全的正确率。
附图说明
[0022]
图1是本发明基于时序神经网络模型补全语音数据的方法的方法流程图。
[0023]
图2是本发明基于神经网络模型的文本补全原理示意图。
具体实施方式
[0024]
本发明基于时序神经网络模型补全语音数据的方法,其方法流程图如图1,包括:
[0025]
步骤101、将原始完整的语音数据集随机挖空任意时长的语音单元后,作为缺失的语音数据集;
[0026]
步骤102、将原始完整的语音数据集以及缺失的语音数据集分别转换为原始完整的文本数据集以及缺失的文本数据集;
[0027]
步骤103、将缺失的文本数据集输入时序神经网络模型,经时序神经网络模型补全后输出完整的文本数据集;
[0028]
步骤104、将完整的文本数据集与原始完整的文本数据集进行相似度对比;
[0029]
步骤105、获取补全后输出的完整的文本数据集,以及当前的时序神经网络模型;
[0030]
步骤106、调整时序神经网络模型中的损失函数,进入步骤103。
[0031]
为了实现对语音补全的验证,基于时序神经网络模型补全语音数据的方法,还包括:
[0032]
步骤107、提取任意时长与挖空的语音单元相邻的前后语音单元,并将挖空的语音单元转化为挖空的文本数据;
[0033]
步骤108、将提取出的语音单元转换为对应的文本数据,并提取出该语音单元的音
色特征集;
[0034]
步骤109、将对应的文本数据输入所获取的时序神经网络模型,得到补全的部分文本数据;
[0035]
步骤110、将补全的部分文本数据与挖空的文本数据拼接起来,并将拼接后的文本数据转换为语音数据,再结合提取出的音色特征集来还原原始音频数据集;
[0036]
步骤111、将还原的原始音频数据集与原始完整的语音数据集进行对比来验证语音补全的相似度。
[0037]
步骤102中,还包括对文本数据进行相应预处理,去掉多余的词组。
[0038]
本发明使用的时序神经网络模型包括多个lstm单元的补全神经网络,神经网络中遗忘率设置为0.05,dropout设置为0.1。
[0039]
其中,lstm提取的特征会通过一个全连接层得到最后的补全词汇结果。
[0040]
在具体实施时,采用完整的公开语音数据集作为数据样本,例如腾讯所公布的腾讯视频中各式各样的网络数据集。适用完整的数据集作为测试机,将样本按照8:2的比例随机裁剪,分为训练集和验证集。
[0041]
训练集:指的是用于语音训练的样本集合,用来训练补全网络中的参数。
[0042]
验证集:验证补全网络模型的数据集合。网络在训练集上训练结束后,通过数据集来比较判断网络模型的性能。
[0043]
在训练时,可以对于以30秒为一个单位的语音中,随机挖空一个5秒的单元,将原语音分解成待补全的语音a和挖出部分语音b;使用现今已有的准确率较高的语音转文字网络,将语音a和b都转化为对应的文本数据;对于语音a和b对应的文本数据做基本的预处理:去掉多余的词,并且通过添加基本的谓语动词可以将它们本身连接一个完整的句子,将连接成的完整句子称作文本数据c;通过文本数据c对时序神经网络模型进行训练,不断对时序神经网络模型进行优化,使得补全后的文本数据不断接近原始文本数据集。
[0044]
附图2为基于神经网络模型的文本补全原理示意图,其中,w为各类权重,x表示输入,y表示输出,h表示隐层处理状态,输入:what the,根据关联态,就会自动补全为:what is the problem。
[0045]
综上所述,本发明实现了对残缺语音数据自动补全,极大地提高了效率,并且同时对补全后的语音数据进行验证,保证了语音补全的正确率。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除
相关标签: 神经网络模型

 热门咨询
热门咨询




tips