
 商标分类
商标分类  商标转让
商标转让 
单声道人声与背景音乐分离方法与流程
 2021-01-28 12:01:17|
2021-01-28 12:01:17| 322|
322| 起点商标网
起点商标网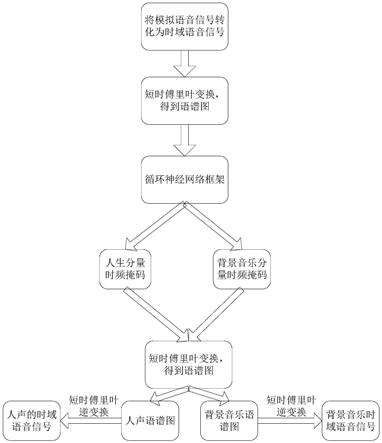
[0001]
本发明涉及音频处理技术领域,具体涉及单声道人声与背景音乐分离方法。
背景技术:
[0002]
在现实生活中,声音信号通常由来自多个声源的声音混合。例如,歌曲信息是人声和音乐背景音乐的混合信号。人耳可以从复杂的语音信息中有效的捕捉到自己感兴趣的信息,即便这些语音信号在频率上和时间上都配合得很“融洽”,例如歌唱声音的分离对人类来说就是很自然的听觉系统,然而用计算机上实现人耳的这个能力非常困难。
[0003]
单声道人声与背景音乐分离面临着许多挑战,最大的挑战是声音和背景音乐信号的非平稳特性,以及仅提供一个声道的信号。如果信号和干扰信号是平稳或变化缓慢的,则可以通过维纳滤波的方法解决。然而实际情况中大多数情况下的单声道信号并不是平稳或缓慢的,这就导致了在对单声道音频信号进行识别时,对人声的识别率,同时识别的准确率也非常低。
技术实现要素:
[0004]
本发明目的在于解决现有技术中在针对单声道人声与背景音乐分离时识别率和准确率低的问题,提供了单声道人声与背景音乐分离方法,显著的提高了分离过程的识别率和准确率,对单声道音频文件中的人声进行了有效的还原。
[0005]
本发明通过下述技术方案实现:
[0006]
单声道人声与背景音乐分离方法,包括以下步骤:
[0007]
步骤一、将待分离的时域模拟语音信号转化为时域数字语音信号;
[0008]
步骤二、对步骤一中的时域数字语音信号进行短时傅里叶变换,取其幅值信息得到语谱图;
[0009]
步骤三、建立循环神经网络框架;
[0010]
步骤四、将步骤二得到的语谱图输入步骤三中的循环神经网络框架,得到与语谱图尺寸相同人声时频掩模m
vocal
;
[0011]
步骤五、根据步骤四得到的人声时频掩模m
vocal
通过差分的方法计算得到背景音乐的时频掩模;
[0012]
步骤六、将步骤五中得到的两个时频掩模与步骤二得到的语谱图进行点乘,得到分离出的人声语谱图和背景音乐语谱图;
[0013]
步骤七、对人声语谱图和背景音乐语谱图进行短时傅里叶逆变换,分别得到人声的时域数字语音信号和背景音乐的时域数字语音信号。
[0014]
大量的移动设备只能够录制单声道的音频,并且只有专业音乐工作室才能够录制多声道的音频,因此在许多情况下需要处理单声道信号是必要的,现有的技术中在针对单声道音频文件中的人声和背景音乐分离时大多采用nmf算法,虽然起到了一定人声和背景音乐分离的效果,但是对单声道音频文件中的人声的识别率较低,识别准确度也不高,会造
成原始音频文件中人声的大量损失;针对上述问题,发明人设计了本发明,由于单声道语音信号表现形式如同随着时间变化的电压信号,是随时间变化的一维连续模拟信号,为方便对信号进行处理所以步骤一中将其转变成为时域数字语音信号,正常的时域数字语音信号虽然很直观,其幅值代表声音大小,频率高低影响音调的高低;由于背景音乐与人声在时域上为加性噪声且没个时间点上仅代表了信号的幅值信息,直接在时域上直接进行人声与背景音乐分离比较困难;为了更好的展示出语音信号中的幅值、频率与时间信息,步骤二中对时域上的语音信号进行短时傅里叶变换,取其幅值信息后得到语谱图;在现实世界的场景中,各种语音信号可能并不总是遵循高斯分布,线性模型的表达力不足以模拟复杂的模型来分离混合信号;混合信号之间的映射关系和分离的源作为非线性变换,所以步骤三中发明人建立了循环神经网络,音频信号本质上是一种时间序列,所以使用深度神经网络对单声道源分离任务建模时间信息,要捕获音频信号之间的上下文信息,连接相邻时间的音频特征,幅度谱,作为深度神经元的输入特征网络;但是,这样一来神经网络参数的数量与输入的维度和相邻时间成比例增加;所以本发明中发明人采用的建模是循环神经网络;循环神经网络可以被视为有无限层的深度神经网络,步骤四再将步骤二得到的语谱图输入步骤三中的循环神经网络框架,得到与语谱图频率成分相同的人声分量和背景音乐分量在语音信号的分离中,神经网络直接输出期望的幅值比较困难,所以本发明中输出是采用时频掩模,再将步骤五中得到的两个时频掩模与步骤二得到的语谱图进行点乘,得到分离出的人声语谱图和背景音乐语谱图;最后进行短时傅里叶逆变换,分别得到人声的时域数字语音信号和背景音乐的时域数字语音信号。
[0015]
进一步的,步骤一中将时域模拟语音信号转化为时域数字语音信号的过程中,其采样频率满足香农采样定律;f
s
>2f
max
,f
s
表示采样频率,f
max
表示时域模拟语音信号的最高频率。对于语音信号,为了提高其信号的清晰度和还原度,采样率越高,其语音的真实度就越高,为了保证时域数字语音信号能够有较高的清晰度和还原度,所以本发明中f
s
>2f
max
,具体的本发明中语音信号的格式为wav格式,采样频率为16000hz或44100hz。
[0016]
进一步的,步骤二的具体步骤如下:
[0017]
步骤2.1、将步骤一得到的时域数字语音信号切分成n个信号段,每个信号段的时间为20ms~40ms,且相邻信号段之间的重叠率为α,45%<α<55%;
[0018]
步骤2.2、对每一信号段加汉宁窗,窗函数的长度与信号段长度相等;
[0019]
步骤2.3、对每一信号段进行短时傅里叶变换,得到短时傅里叶变换后的结果:
[0020][0021]
其中:x(n)为信号段,w(n)为窗函数。
[0022]
由于分段后一段语音信号整体上看不是平稳的,但是在局部上可以看作是平稳的,在后期的语音处理中需要输入的是平稳信号,所以要对整段语音信号分帧,也就是将含普通话语音段切分成很多的小段,每个小段中的信号可以看成是平稳的,对每个小段进行一定频率的采样,通常为8khz、16khz等,再将该小段中的所有采样点集合成一个观测单位,称为帧,语音去噪的单位就是帧,这里定义该小段中采样点的个数为n;通常情况下n的值为256或512,涵盖的时间约为20-30ms,所以不同的程序中一帧的长度不一样。由于分帧后帧
与帧之间的连续性就降低了,为了避免相邻两帧的变化过大,因此会让两帧之间有一定的重叠区域,重叠区域包含m个采样点,m一般为n的1/2或1/3;由于分帧后,每一帧的起始段和末尾端会出现不连续的地方,所以分帧越多与原始信号的误差也就越大,加窗就是为了解决这个问题,使分帧后的信号变得连续,每一帧就会表现出周期函数的特征,加窗的目的就是一次仅处理窗中的数据,因为实际的语音信号是很长的,我们不能也不必对非常长的数据进行一次性处理,故而在语音信号处理中采用了加汉明窗的方式,因为加上汉明窗,只有中间的数据体现出来了,两边的数据信息丢失了,所以在移窗时,移动1/3或1/2窗,这样被前一帧或二帧丢失的数据又重新得到了体现;正常的时域数字语音信号虽然很直观,其幅值代表声音大小,频率高低影响音调的高低,但是由于背景音乐与人声在时域上为加性噪声且每个时间点上仅代表了信号的幅值信息,直接在时域上直接进行人声与背景音乐分离比较困难;为了更好的展示出语音信号中的幅值、频率与时间信息,我们对时域上的语音信号进行短时傅里叶变换,取其幅值信息后得到语谱图,短时傅里叶变换后得到的值包含了语音信号的幅值信息和相角信息,其值为复数;短时傅里叶变换后得到的语谱图不同于傅里叶变换,它在分析其语音信息在不同频率的信息的同时,保留其随时间变化而变化的信息;其在语音分离中发挥了非常巨大的作用。
[0023]
进一步的,步骤五中计算背景音乐的时频掩模的公式如下:m
background
=1-m
vocal
。人声与背景音乐的分离可以看作是一个二分类问题;需要分类的对象是语谱图上的每一个点,语谱图中的每一个点蕴含着某一频率在某一时刻所包含的幅值信息,而幅值信息正好是人声与背景音乐能量的叠加;所以本发明中分离任务的主要工作在于区分语谱图上某一像素点上,有多少能量属于人声,有多少能量属于背景音乐;时频掩模是一个与语谱图拥有相同行宽,且每一个点上的数值都在0与1之间,在本发明中,人声的时频掩模与背景音乐的时频掩模之和为一个全1的矩阵。
[0024][0025]
时频掩模是神经网络的输出,通过时频掩模将语谱图分为人声和背景音乐的语谱图,后续便可通过分离得到地语谱图通过短时傅里叶逆变换还原为时域信号。
[0026]
进一步的,还包括如下步骤:
[0027]
步骤a、利用步骤四得到的人声时频掩模m
vocal
,计算出该语音信号中的人声分量语谱图利用步骤五得到的背景音乐时频掩模m
background
计算出该语音信号中背景音乐分量语谱图
[0028]
步骤b、建立纯净人声样本并进行短时傅里叶变换,得到纯净人声语谱图y
1t
;
[0029]
步骤c、建立纯净背景音乐样本并进行短时傅里叶变换,得到纯净背景音乐语谱图y
2t
;
[0030]
步骤d、建立引入sir正则化的均方根损失函数:
[0031][0032]
步骤e、通过损失函数对循环神经网络进行反向传播,使逼近y
1t
,逼近y
2t
;
[0033]
所述步骤a、b、c、d依次设置于步骤四和步骤五之间。
[0034]
为了进一步的提高提取出的人声语谱图和背景音乐语谱图的辨识率和准确率,发明人又增加了步骤a、b、c、d,通过损失函数对神经网络进行反向传播,求得神经网络中各个参数的导数并进行梯度下降,使逼近y
1t
,逼近y
2t
;从而提高了人声语谱图和背景音乐语谱图的还原度。
[0035]
本发明与现有技术相比,具有如下的优点和有益效果:
[0036]
1、通过引入循环神经网络和时频掩模,显著的提高了分离过程的识别率和准确率,对单声道音频文件中的人声进行了有效的还原。
[0037]
2、通过加入损失函数,同时通过损失函数对循环神经网络进行反向传播,使逼近y
1t
,逼近y
2t
,从而提高了人声语谱图和背景音乐语谱图的还原度。
附图说明
[0038]
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
[0039]
图1为本发明的数据处理流程图;
[0040]
图2为本发明中循环神经网络的结构示意图。
具体实施方式
[0041]
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
[0042]
实施例:
[0043]
如图1及图2所示,单声道人声与背景音乐分离方法,包括以下步骤:
[0044]
步骤一、将待分离的时域模拟语音信号转化为时域数字语音信号;
[0045]
步骤二、对步骤一中的时域数字语音信号进行短时傅里叶变换,取其幅值信息得到语谱图;
[0046]
步骤三、建立循环神经网络框架;
[0047]
步骤四、将步骤二得到的语谱图输入步骤三中的循环神经网络框架,得到与语谱图尺寸相同人声时频掩模m
vocal
;
[0048]
步骤五、根据步骤四得到的人声时频掩模m
vocal
通过差分的方法计算得到背景音乐的时频掩模;
[0049]
步骤六、将步骤五中得到的两个时频掩模与步骤二得到的语谱图进行点乘,得到分离出的人声语谱图和背景音乐语谱图;
[0050]
步骤七、对人声语谱图和背景音乐语谱图进行短时傅里叶逆变换,分别得到人声的时域数字语音信号和背景音乐的时域数字语音信号。
[0051]
本实施例中,步骤一中将时域模拟语音信号转化为时域数字语音信号的过程中,其采样频率满足香农采样定律;f
s
>2f
max
,f
s
表示采样频率,f
max
表示时域模拟语音信号的最高频率。步骤二的具体步骤如下:
[0052]
步骤2.1、将步骤一得到的时域数字语音信号切分成n个信号段,每个信号段的时间为20ms~40ms,且相邻信号段之间的重叠率为α,α=50%;
[0053]
步骤2.2、对每一信号段加汉宁窗,窗函数的长度与信号段长度相等;
[0054]
步骤2.3、对每一信号段进行短时傅里叶变换,得到短时傅里叶变换后的结果:
[0055][0056]
其中:x(n)为信号段,w(n)为窗函数。
[0057]
为了更好的展示出语音信号中的幅值、频率与时间信息,我们对时域上的语音信号进行短时傅里叶变换,取其幅值信息后得到语谱图,短时傅里叶变换后得到的值包含了语音信号的幅值信息和相角信息,其值为复数。如图1所示,将随时间变化的每一帧当作语谱图的列,将不同频段当作语谱图的行,如果某一帧某一频率上具有越大的幅值,其在语谱图上颜色则越深。
[0058]
步骤五中计算背景音乐的时频掩模的公式如下:m
background
=1-m
vocal
。
[0059]
循环神经网络的输入是经过短时傅里叶变换后的语谱图,其中语谱图的频率为输入循环神经网络的特征,每一个时间帧上的数据会传递到下一个时间帧。最后将循环神经网络的值通过两个一层全连接层,激活函数为relu,分别得到与语谱图频率成分相同的人声分量和伴奏分量。
[0060]
如图2所示,所示有三个隐藏层的循环神经网络层;它将当前时间帧计算得到的数据h
t
传递到下一个时间帧,顶部的两行的点代表全连接层的输出值,其目的是分别得到各个时间点各频率点上人声分量和伴奏分量
[0061]
本实施还包括如下步骤:步骤a、利用步骤四得到的人声时频掩模m
vocal
,计算出该语音信号中的人声分量语谱图利用步骤五得到的背景音乐时频掩模m
background
计算出该语音信号中背景音乐分量语谱图具体的,人声分量语谱图和背景音乐分量语谱图的计算公式如下:
[0062][0063][0064]
步骤b、建立纯净人声样本并进行短时傅里叶变换,得到纯净人声语谱图y
1t
;
[0065]
步骤c、建立纯净背景音乐样本并进行短时傅里叶变换,得到纯净背景音乐语谱图y
2t
;
[0066]
步骤d、建立引入sir正则化的均方根损失函数:
[0067][0068]
步骤e、通过损失函数对循环神经网络进行反向传播,使逼近y
1t
,逼近y
2t
;
[0069]
所述步骤a、b、c、d依次设置于步骤四和步骤五之间。
[0070]
对照组
[0071]
本对照组采用nmf算法对单声道音频文件中的人声和背景音乐进行分离。
[0072]
并对各组实施例及对照组最后的分离效果进行了评估,评估从失真比、干扰比、信噪比、识别率和准确率五个方面入手,得出了下列表格;
[0073]
表1分离结果失真比中位值及平均值
[0074][0075]
表2分离结果干扰比中位值及平均值
[0076][0077]
表3分离结果噪声比中位值及平均值
[0078][0079]
表4分离的识别率及准确率
[0080] 识别字数准确字数识别率准确率纯标准中文917917//对照组1924520.93%4.91%本实施例56437861.50%41.31%
[0081]
通过表1至表4可知,与现有的nmf算法对单声道音频文件中的人声和背景音乐进行分离相比,本发明能够显著的提升识别率和准确率,相比现有技术具有显著的进步。
[0082]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips