
 商标分类
商标分类  商标转让
商标转让 
基于卷积循环神经网络的单通道人声与背景声分离方法与流程
 2021-01-28 12:01:59|
2021-01-28 12:01:59| 310|
310| 起点商标网
起点商标网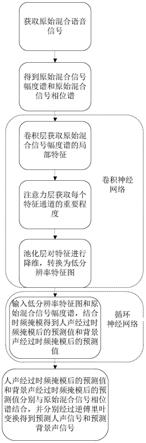
[0001]
本发明涉及人声与背景声分离,具体是基于卷积循环神经网络的单通道人声与背景声分 离方法。
背景技术:
[0002]
语音分离的目的是从背景干扰中分离出目标语音,由于麦克风采集到的声音中可能包括 噪声、其他人说话的声音,背景音乐等干扰项,不做语音分离直接进行识别的话,会影响到 识别的准确率。因此分离识别出的源在人声,在自动语音识别等信号处理领域有重要价值, 单通道下的人声与背景音乐分离是语音分离中一个基础而重要的分支。
[0003]
近些年来,随着软硬件性能的提高和机器学习算法的普及,深度学习渐渐在自然语言处 理和图像等领域上展示了极高的效果。基于深度学习的语音分离,是从训练数据中学习语音、 说话人和噪音的特征,构建整体的神经网络从而实现语音分离的目标。语音信息可以同时体 现在时间域和频率域,语音的时间域和频率域信息都是宝贵的特征信息,但是对于语音分离 来说,大部分深度学习的方法都是利用单一的卷积神经网络或者循环神经网络来进行分离, 还没有统一的可泛化通用的框架来进行语音分离,无法准确提取混合语音中的时间域和频率 域信息,混合语音的人声与背景声分离效果差。
技术实现要素:
[0004]
本发明的目的在于克服现有技术无法准确提取语音中的时间域和频率域信息,混合语音 中人声与背景声分离效果差的不足,提供了一种基于卷积循环神经网络的单通道人声与背景 声分离方法,通过在卷积神经网络中设计了两种不同大小的卷积核,捕获语音的时间域和频 率域信息,同时进行特征降维和提取其局部特征并与原始混合信号幅度谱结合成的多尺度特 征输入循环神经网络中,能准确分离混合语音的人声信号和背景声信号。
[0005]
本发明的目的主要通过以下技术方案实现:
[0006]
基于卷积循环神经网络的单通道人声与背景声分离方法,包括步骤:
[0007]
s1、获取原始混合语音信号,所述原始语音信号为单通道的人声、背景声的混合信号;
[0008]
s2、将获取的原始混合语音信号经过分帧加窗、时频转换,得到原始混合信号幅度谱和 原始混合信号相位谱;
[0009]
s3、将原始混合信号幅度谱输入卷积神经网络,所述卷积神经网络包括依序设置的卷积 层和池化层;卷积层获取原始混合信号幅度谱的局部特征,池化层对特征进行降维,转换为 低分辨率特征图并输出;所述卷积层包括两层,且两层卷积层中的卷积核大小不同;
[0010]
s4、将低分辨率特征图和原始混合信号幅度谱输入循环神经网络,结合时频掩模得到人 声经过时频掩模后的预测值和背景声经过时频掩模后的预测值;
[0011]
s5、将人声经过时频掩模后的预测值和背景声经过时频掩模后的预测值分别与原始混合 信号相位谱结合,并分别经过逆傅里叶变换得到预测人声信号和预测背景声信号;
[0012]
所述卷积神经网络和循环神经网络均设有原始混合信号幅度谱通道。
[0013]
现有技术在采用深度学习进行语音分离时,无法准确提取混合语音中的语音的时间域和 频率域信息,混合语音分离效果差。为了解决这一技术问题,本技术方案提供了一种语音分 离方法,将卷积神经网络作为前端,输入单通道的人声、背景声的混合信号,旨在对声谱图 进行降维和提取其局部特征,然后将提取的特征与原始声谱图结合成的多尺度特征一起送入 后端循环神经网络中,最后利用时频掩模得到预测的人声和背景音乐的声谱图;通过设置卷 积核数目可以使网络的输出通道增加,本技术方案根据音频信号的特性,在卷积神经网络中 设计了两种不同大小的卷积核,目的在于从输入声谱图中捕获时间域和频域二者的上下文信 息,能准确分离混合语音的人声信号和背景声信号,在对原始混合信号幅度谱进行卷积操作 时,第一次卷积是分别针对声谱图的时域和频域特征进行卷积操作,第一次卷积操作完成后 立即对得到的这两种特征进行融合,便于后续卷积操作。随着卷积层数的增加,网络变得更 深,这样使得融合的时域特征和频域特征进一步得到深层次的表达。具体的,在获取音频信 号特征的基础上,本技术方案中还加入了直连通道,原始混合信号幅度谱通道,利用提取特 征和原始声谱图结合的“多尺度信息”,将提取的特征与原始声谱图结合成的多尺度特征一起 送入后端循环神经网络中,所谓尺度指图像的分辨率,由于原始声谱图的分辨率为513
×
64, 而通过卷积池化操作之后的图像会变成256
×
64,即时域维度上不变而频域上减半,将二者结 合起来的操作是时域上对齐,频域上相加;结合后的维度即(513+256)
×
64,这样处理在维 持原始整体特征信息的完整性的同时,又增加了更低分辨率特征的输入,体现了二者的互补 性;本技术方案在卷积神经网络设计中,为了压缩数据和参数的数量,在卷积层之后使用池 化层来进行特征降维,减小网络的过拟合,提高模型的泛化性;本技术方案的神经网络模型 没有改变原始语音频谱图的相位,而是将人声经过时频掩模后的预测值和背景声经过时频掩 模后的预测值分别与原始混合信号相位谱结合,并分别经过逆傅里叶变换得到预测人声信号 和预测背景声信号,利用时频掩模添加了预测结果的总和等于原始混合这一约束。本技术方 案通过在卷积神经网络中设计了两种不同形状的滤波器,捕获语音的时间域和频率域信息, 同时利用池化层来进行特征降维和提取其局部特征并与原始混合信号幅度谱结合成的多尺度 特征输入循环神经网络中,能准确分离混合语音的人声信号和背景声信号。
[0014]
需要说明的是,本技术方案中时频转换采用短时傅里叶变换,本技术方案中循环神经网 络采用的结构为gru,gru的模型比标准的lstm模型要简单,且参数减少,不容易产生 过拟合;所述卷积循环神经网络是联合采用卷积神经网络和循环神经网络的神经网络。
[0015]
进一步的,所述两层卷积层中的卷积核均为矩形长条状的滤波器。由于一般正方形的卷 积核不能很好的利用音频的时频域特征信息,因此本技术方案中的卷积核分别是两个矩形长 条状的滤波器。
[0016]
进一步的,第一层卷积层的卷积核尺寸为2
×
10,第二层卷积层的卷积核尺寸为10
×
2。在 处理语音这种序列型数据时,普通的卷积核如3
×
3无法充分有效地利用语音的特征,因为3x3 这种是针对普通的图像,因为普通的图像横纵轴没有具体的含义,而原始混合信号幅度谱横 坐标代表时间,纵坐标代表频率,所以本技术方案采用2
×
10的卷积核可以
提取语音信号的频 域特征,10
×
2的卷积核可以提取时域特征。
[0017]
进一步的,在两层卷积层之后均设有批处理归一化层,批处理归一化层使用leaky-relu 激活函数,leaky-relu激活函数公式如下:其中x
i
为自变量,而a
i
是 (1,+∞)区间内的固定参数。通过设置批处理归一化层来加快模型的训练时间,使模型更 快地收敛。
[0018]
进一步的,所述池化层卷积核尺寸为2
×
1。本技术方案将池化层设置的卷积核大小为2
×
1, 使特征经过池化层后时间维度不变,频率维度减半;采用这样可以减小数据量,不断地减小 数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。
[0019]
进一步的,所述s3中卷积神经网络的输入的谱图大小为10
×
513,其中513=1024/2+1, 采样率为16000hz。
[0020]
从音频文件中读取出来的原始语音信号是一维数组,其长度由音频长度和采样率决定。 对原始语音信号进行分帧加窗后,可以得到很多帧,对每一帧做快速傅里叶变换,即把时域 信号转为频域信号,把每一帧傅里叶变换后的频域信号在时间上堆叠起来就可以得到声谱图。 傅里叶变换后具有n个频点,由于其自身的对称性,当n为偶数时取n/2+1个点,当n为 奇数时,取(n+1)/2个点。本技术方案采用10帧输入对卷积循环神经网络建模训练,设置傅 里叶变换的窗长n_fft为1024点,使用50%的重叠来提取声谱表示。因此本文神经网络的输 入为10
×
513大小的谱图。其中513=1024/2+1,采样率为16000hz。
[0021]
进一步的,所述卷积神经网络的卷积层和池化层之间还有注意力层,注意力层通过学习 的方式自动获取每个特征通道的重要程度,并依据重要程度提升有用特征通道的权重,降低 对当前任务用处不大的特征通道的权重。
[0022]
现有技术中采用神经网络进行分离工作,一般都是从空间维度,即通过多尺度特征信息、 或不同分辨率特征图相结合来提升网络性能,却很少关注到特征通道之间的关系;发明人在 对混合语音分离研究后发现,通过设置卷积核数目可以使网络的输出通道增加,然而这些通 道并不是都是同等重要的,过多冗余的特征通道会影响网络的表达能力,本技术方案中通过 添加注意力层,通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要 程度去提升有用的特征并抑制对当前任务用处不大的特征,使卷积后的特征通道有不同的权 重,且将冗余的特征通道对应的权值相应地降低,从而提高网络的表达能力。
[0023]
进一步的,所述注意力层采用最大池化法进行全局池化。
[0024]
本技术方案中注意力层采用最大池化法进行全局池化,使不同特征通道对应的权值具有 区分性。本技术方案提供的卷积循环神经网络结构可以分成卷积层——注意力层——池化层 ——循环层,这四大部分,其中注意力层采用全局最大池化,池化层仅采用最大池化,所述 循环层即为循环神经网络。
[0025]
进一步的,所述卷积神经网络和循环神经网络采用均方误差损失函数,如下: ,其中为超参数,是人声经过时频掩模后的预测值,是背 景声经过时频掩模后的预测值,o
1t
和o
2t
分别代表人声和背景声的真实值;或采用均方
误差与 源-干扰比结合损失函数,如下: ,其中γ为超参数,是人 声经过时频掩模后的预测值,是背景声经过时频掩模后的预测值,o
1t
和o
2t
分别代表人声和 背景声的真实值。其中时刻t指第t帧。
[0026]
优选的,本技术方案采用均方误差与源-干扰比结合损失函数,均方误差与源-干扰比结 合损失函数不仅仅使预测的人声信号更接近于真实人声信号,而且使预测的人声信号中包含 更少的背景信号;优选的,γ为0.05。
[0027]
进一步的,s4中人声经过时频掩模后的预测值和背景声经过时频掩模后的预测值计算方 法如下:其中
⊙
定义为元素相乘,是人 声经过时频掩模后的预测值,是背景声经过时频掩模后的预测值,m
t
为原始混合信号幅 度谱,代表卷积循环神经网络预测的人声在时刻t的输出,是卷积循环神经网络的 背景声在时刻t的输出,为人声经过时频掩模后的预测值的时频掩模和 为背景声经过时频掩模后的预测值的时频掩模。本技术方案中利用时频掩蔽技术 进一步平滑源分离结果,使预测结果之和等于原始混合的约束。
[0028]
综上所述,本发明与现有技术相比具有以下有益效果:
[0029]
1、本发明提供了一种语音分离方法,将卷积神经网络作为前端,输入单通道的人声、背 景声的混合信号,旨在对声谱图进行降维和提取其局部特征,然后将提取的特征与原始声谱 图结合成的多尺度特征一起送入后端循环神经网络中,最后利用时频掩模得到预测的人声和 背景音乐的声谱图;通过设置卷积核数目可以使网络的输出通道增加,本发明根据音频信号 的特性,在卷积神经网络中设计了两种不同形状的卷积核,目的在于从输入声谱图中捕获时 间域和频域二者的上下文信息,能准确分离混合语音的人声信号和背景声信号。
[0030]
2、本发明通过添加注意力层,通过学习的方式来自动获取到每个特征通道的重要程度, 然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征,使卷积后的特 征通道有不同的权重,且将冗余的特征通道对应的权值相应地降低,从而提高网络的表达能 力。
附图说明
[0031]
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不 构成对本发明实施例的限定。在附图中:
[0032]
图1为基于卷积循环神经网络的单通道人声与背景声分离方法的流程图;
声经过时频掩模后的预测值,是背景声经过时频掩模后的预测值,o
1t
和o
2t
分别代表人声和 背景声的真实值;优选的,采用均方误差与源-干扰比结合损失函数,均方误差与源-干扰比 结合损失函数不仅仅使预测的人声信号更接近于真实人声信号,而且使预测的人声信号中包 含更少的背景信号;优选的,γ为0.05。
[0050]
优选的,s4中人声经过时频掩模后的预测值和背景声经过时频掩模后的预测值计算方法 如下:其中
⊙
定义为元素相乘,是人声 经过时频掩模后的预测值,是背景声经过时频掩模后的预测值,m
t
为原始混合信号幅度 谱,代表卷积循环神经网络预测的人声在时刻t的输出,是卷积循环神经网络的背 景声在时刻t的输出,为人声经过时频掩模后的预测值的时频掩模和为背景声经过时频掩模后的预测值的时频掩模。
[0051]
本实施例提供的语音分离方法,将卷积神经网络作为前端,输入单通道的人声、背景声 的混合信号,旨在对声谱图进行降维和提取其局部特征,然后将提取的特征与原始声谱图结 合成的多尺度特征一起送入后端循环神经网络中,最后利用时频掩模得到预测的人声和背景 音乐的声谱图;通过设置卷积核数目可以使网络的输出通道增加,本实施例根据音频信号的 特性,在卷积神经网络中设计了两种不同大小的卷积核,目的在于从输入声谱图中捕获时间 域和频域二者的上下文信息,能准确分离混合语音的人声信号和背景声信号。具体的,本实 施例选择卷积核两个为矩形长条状的滤波器,通过设置卷积核数目可以使网络的输出通道增 加,再结合对尺寸的选择,提升了网络的表达能力;在获取音频信号特征的基础上,本实施 例还加入了直连通道,原始混合信号幅度谱通道,利用提取特征和原始声谱图结合的”多尺度 信息”,这样处理在维持原始整体特征信息的完整性的同时,又增加了更低分辨率特征的输入, 体现了二者的互补性;本实施例在卷积神经网络设计中,为了压缩数据和参数的数量,在卷 积层之后使用池化层来进行特征降维,减小网络的过拟合,提高模型的泛化性,还通过设置 批处理归一化层来加快模型的训练时间,使模型更快地收敛;本实施例的神经网络模型没有 改变原始语音频谱图的相位,而是将人声经过时频掩模后的预测值和背景声经过时频掩模后 的预测值分别与原始混合信号相位谱结合,并分别经过逆傅里叶变换得到预测人声信号和预 测背景声信号,利用时频掩模添加了预测结果的总和等于原始混合这一约束。本实施例通过 在卷积神经网络中设计了两种不同形状的滤波器,捕获语音的时间域和频率域信息,同时利 用池化层来进行特征降维和提取其局部特征并与原始混合信号幅度谱结合成的多尺度特征输 入循环神经网络中,能准确分离混合语音的人声信号和背景声信号。
[0052]
实施例2:
[0053]
如图1和2所示,本实施例在实施例1基础上,还包括:所述卷积神经网络的卷积层
和 池化层之间还有注意力层,注意力层通过学习的方式自动获取每个特征通道的重要程度,并 依据重要程度提升有用特征通道权重,抑制对当前任务用处不大的特征通道。图2表示的是 注意力层。所述注意力层设置在卷积层和池化层之间。
[0054]
优选的,所述注意力层采用最大池化法进行全局池化。
[0055]
图2提供了本实施例注意力层的示意图,给定一个输入x,其特征通道数为c_1,通过一 系列卷积等一般变换后得到一个特征通道数为c_2的特征。与传统的cnn不一样的是,接下 来本实施例通过三个操作来重标定前面得到的特征。首先是挤压操作,顺着空间维度来进行 特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野, 并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且 使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。其次是 激励操作,它是一个类似于循环神经网络中门的机制,通过参数w来为每个特征通道生成权 重,其中参数w被学习用来显式地建模特征通道间的相关性。最后是一个校正权重的操作, 将激励操作的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐 通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
[0056]
从图2可以看出,本实施例考虑到了不同通道之间所占的重要性可能不一样,而以前的 网络中并没有考虑到这一点,而是把所有通道的重要性当成一样来处理的。不同的通道的重 要性是通过学到的一组权值来缩放的,相当于经过加入权值进来之后,对原来的特征的一个 重新的标定。
[0057]
实施例1中使用两层卷积核组合时的效果会比单一卷积核的效果有所提升,发明人在对 混合语音分离研究后发现,通过设置卷积核数目可以使网络的输出通道增加,然而这些通道 并不是都是同等重要的,过多冗余的特征通道会影响网络的表达能力,本实施例通过添加注 意力层,通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去 提升有用的特征并抑制对当前任务用处不大的特征,使卷积后的特征通道有不同的权重,且 将冗余的特征通道对应的权值相应地降低,从而提高网络的表达能力。本实施例在实施例1 基础上继续添加了注意力模块后,性能会有进一步提升。另外,发明人在使用最大池化,在 卷积循环神经网络的最后一层卷积层后加入了注意力模块,模块使用最大池化函数来做全局 池化,使得不同通道对应的权值具有区分性,而使用平均池化可能会弱化掉不同通道之间的 重要程度,可见采用本实施例的注意力层并在注意力层采用最大池化的混合语音分离效果更 好。
[0058]
1、验证及对比试验:为了验证实施例2方法的分离效果,发明人采用mir-1k数据集, 其中mir-1k数据集的音频包括2个文件夹,一个是undividedwavfile,包括1000首4-13秒 的音频数据,另一个是wavfile,包括110首音频数据。这些片段是从110首由男性和女性演 唱的中国卡拉ok歌曲中提取的。发明人使用了特定男性和特定女性作为训练集,总共包含 175个片段。其余825个片段作为测试集。采样率均为16000hz,采样点均为16位。
[0059]
(1)、性能评估指标:使用mir_eval包中的bss_eval_sources来作为评价指标,采用如下 四个指标评价分离效果,
[0060]
源-失真比(sdr):
[0061]
源-干扰比(sir):
[0062]
源-噪声比(snr)
[0063]
源-算法引入伪像比(sar):
[0064]
其中,e
target
(t)是预测信号,e
interf
(t)是干扰信号,e
noise
(t)是噪声信号,e
artif
(t)是算法引 入的伪像;sdr从比较全面的角度评估分离算法的分离效果,sir从干扰的角度分析分离效 果,snr从噪声的角度分析分离效果,sar从伪像的角度分析分离效果;sdr、sir、snr、 sar的数值越大,说明人声和背景音乐的分离效果越好。全局nsdr(gnsdr)、全局sir (gsir)和全局sar(gsar)分别为nsdr、sir和sar的加权平均值,其权重为音源长 度。其中标准化的sdr定义为:nsdr(t
e
,t
o
,t
m
)=sdr(t
e
,t
o
)-sdr(t
m
,t
o
),其中t
e
定义为模型估 计出的人声/背景音乐,t
o
为原始信号中纯净的人声/背景音乐,t
m
为原始混合信号。
[0065]
表:均方误差与源-干扰比结合的损失函数下的算法对比
[0066]
[0067][0068]
上表中,方法1~8采用的是常规的混合语音分离方法,方法9是在实施例1基础上将两 层卷积核替换为一层卷积核,方法10是实施例1的方法,方法11实施例2的方法;方法12 是在实施例2基础上将注意力层采用的最大池化替换为平均池化,且将两层卷积核替换为一 层卷积核;方法13在实施例1基础上将两层卷积核替换为一层卷积核,且将注意力层采用的 最大池化替换为平均池化;方式14在实施例2基础上将注意力层采用的最大池化替换为平均 池化。
[0069]
从表中可以看出,采用实施例1方法(方法10)和实施例2方法(方法11)获得的混合 语音分离效果均由于采用现有技术的方法1~8;从方法9和方法10中来看,当使用两层卷积 核组合时的效果会比单一卷积核的效果有所提升,方法11在此基础上继续添加了注意力模块 后,性能会有进一步提升。另外,发明人在上表中使用了两个池化方法——平均池化和最大 池化,对比方法11和方法14的混合语音分离效果来看使用平均池化的效果综合来说没有最 大池化效果好,这是由于在卷积循环神经网络的最后一层卷积层后加入了注意力模块,模块 使用最大池化函数来做全局池化,使得不同通道对应的权值具有区分性,而使用平均池化可 能会弱化掉不同通道之间的重要程度,可见采用实施例2注意力层并在注意力层采用最大池 化的混合语音分离效果更好。
[0070]
发明人在研究过程中还发现,缩减比r是注意力层中的重要超参数,当r值取得较小时, 对性能提升没有帮助,当设置r=64可实现在gnsar,gsir,gsar三个指标上性能的提升。
[0071]
此外,发明人对述卷积神经网络和循环神经网络采用均方误差与源-干扰比结合损失函数 中不同取值的γ研究后发现,当γ为0.05时,在gnsar、gsir、gsar上有均衡;gnsar、 gsir、gsar这三个评价指标,每个越大说明信噪比越高,分离的效果越好。然而并不是随 着超参数的改变,这三个指标同时增大或者缩小,为了让三者均衡,即都比较大,而不是仅 仅只考虑某一个,所以选择0.05。
[0072]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说 明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护 范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应
包含在本 发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips