
 商标分类
商标分类  商标转让
商标转让 
一种自闭症语音特征辅助识别机器人及方法与流程
 2021-01-28 12:01:08|
2021-01-28 12:01:08| 321|
321| 起点商标网
起点商标网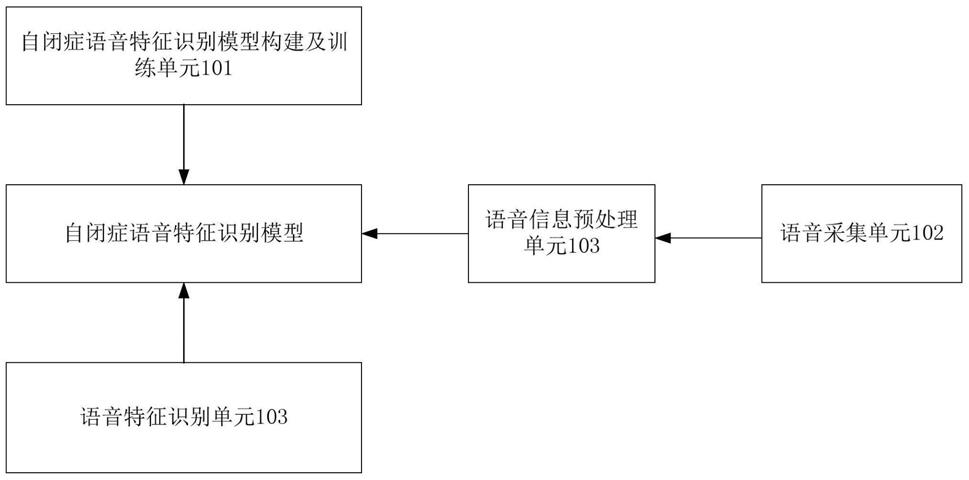
[0001]
本发明涉及语音情感识别技术领域,特别是涉及一种基于lstm(long short-term memory,长短期记忆网络)与cnn(convolutional neural networks,卷积神经网络)的自闭症语音特征辅助识别机器人及方法。
背景技术:
[0002]
孤独症谱系障碍(autism spectrum disorder,asd)又称自闭症,已经越来越被社会所关注。在中国,0至14岁的自闭症儿童患者数量在300万至500万之间。目前对孤独症的评估方法,主要集中在语言交流障碍、社会交往障碍、重复刻板行为三方面。对asd进行有效的、准确的评估需要临床经验丰富的专业医疗人员对儿童进行观察,并一同进行试验。这样的方法需要大量的人力对数据进行整理,效率低下并存在一定的人为主观性,评估结果的误差会比较大。
[0003]
另一方面,现有的语音情感识别方法中,主要有基于深度信念网络的语音情感识别方法、基于长短期记忆网络(lstm)的语音情感识别方法和基于卷积神经网络(cnn)的语音情感识别方法。上述三种方法中,存在的主要缺点是无法兼顾各个网络模型的优点。比如,深度信念网络可以将一维序列用作输入,但是无法利用序列前后间的相关性;长短期记忆网络虽然能够利用序列前后间的相关性,但是提取的特征维数较高;卷积神经网络无法直接对语音序列进行处理,需先对语音信号进行傅里叶变换,将其转换为频谱后作为输入。传统的语音情感识别方法在特征提取和分类发展前景小,以及现有的基于深度学习的语音情感方法网络结构比较单一。
[0004]
综上所述,现有自闭症筛查技术中,人工筛查依然是主导,但人工筛查需要花费大量的人力整理数据,并且人工筛查存在一定的主观性,因此筛查结果有一定的误差,而现有自闭症语音特征识别技术中,只是单纯将语音里的内容转换成文字内容,这种方法只适合低功能自闭症对象,并不适合高功能自闭症对象;另一方面,现有语音情感识别技术中,大部分人使用支持向量机(svm)、隐马尔可夫模型(hmm)进行语音识别,但是模型精度不高,容易受噪声的影响。
技术实现要素:
[0005]
为克服上述现有技术存在的不足,本发明之目的在于提供一种自闭症语音特征辅助识别机器人及方法,以辅助解决现有自闭症筛查中存在的人工筛选误差大、效率低的问题,并提高了语音特征识别的鲁棒性和准确性。
[0006]
为达上述及其它目的,本发明提出一种自闭症语音特征辅助识别机器人,包括:
[0007]
自闭症语音特征识别模型构建及训练单元,利用长短记忆神经网络和卷积神经网络构建自闭症语音特征识别模型,以量化的语音特征作为传感信号输入所述自闭症语音特征识别模型,对语音特征在传感信号的表现特征进行学习,并利用反向传播法对所述自闭症语音特征识别模型进行训练,实现分类器在网络权重的优化,最终获得可用于语音信号
识别的自闭症语音特征识别模型;
[0008]
语音采集单元,用于采集机器人与被测者互动过程中被测者的语音信息;
[0009]
语音信息预处理单元,用于将采集的语音信息进行预处理,将语音特征量化为m维的语音特征向量;
[0010]
语音特征识别单元,用于利用训练好的自闭症语音特征识别模型,对经所述语音采集单元采集、所述语音信息预处理单元处理后的语音信号进行语音特征识别。
[0011]
优选地,所述所述自闭症语音特征识别模型由输入层、lstm网络层、bn1层、cnn网络层、池化层、bn2层、flatten层、dropout层、全连接层、输出层依次连接。
[0012]
优选地,所述lstm网络用于对长序列语音进行处理,其由lstm1层、lstm2层依次连接,所述lstm1层与所述lstm2层激活函数均为tanh,所述lstm网络输出为语音特征序列。
[0013]
优选地,所述lstm网络的lstm1层和lstm2层分别包括输出门、输入门、遗忘门,通过各个门的参数来控制输出信息输入门i
t
由当前输入数据x
t
和前一时刻单元输出h
t-1
决定,遗忘门f
t
控制历史信息的传递,输出门o
t
计算lstm网络的输出值h
t
。
[0014]
优选地,所述cnn网络为卷积层,将经过上层处理的特征向量和当前层的卷积核执行卷积运算,增强原始信号的特征并减少噪声,最后由激活函数给出卷积计算结果。
[0015]
优选地,所述cnn网络由conv1d1层、池化层、conv1d2层依次连接。
[0016]
优选地,所述语音信息预处理单元进一步包括:
[0017]
预加重处理模块,用于对输入的语音信号进行预加重;
[0018]
分帧加窗模块,用于将语音信号分段来分析其特征参数,分析出由每一帧特征参数组成的特征参数时间序列;
[0019]
快速傅立叶变换模块,用于对每一帧信号,通过快速傅立叶变换得到对应的频谱;
[0020]
三角带通滤波模块,用于将经过快速傅里叶得到的频谱通过一组mel尺度的三角形滤波器组,得到mel频谱;
[0021]
计算对数能量模块,用于计算每一帧信号的对数能量,以区分清音和浊音、判断每一帧中的无声段和有声段;
[0022]
离散余弦变换模块,用于将计算出的对数能量代入离散余弦变换公式,计算出l阶的mel倒普参数c(n)。
[0023]
优选地,所述预加重中语音通过的数字滤波器为:
[0024]
h(z)=1-μz-1
[0025]
其中μ为预加重系数,z为一个复数,指的是语音信号的频率;
[0026]
预加重网络的输出和输入的语音信号s(n)的关系为:
[0027][0028]
其中a也为预加重系数。
[0029]
优选地,所述分帧加窗模块用可移动的有限长度窗口进行加权的方式来实现的,加窗信号为:
[0030]
s_w(n)=s(n)*w(n)
[0031]
窗函数为:
[0032][0033]
为达到上述目的,本发明还提供一种自闭症语音特征辅助识别方法,包括如下步骤:
[0034]
步骤s1,基于长短记忆神经网络和卷积神经网络构建自闭症语音特征识别模型,以量化的语音特征作为传感信号输入所述自闭症语音特征识别模型,对语音特征在传感信号的表现特征进行学习,并利用反向传播法对所述自闭症语音特征识别模型进行训练,实现分类器在网络权重的优化,最终获得可用于语音信号识别的自闭症语音特征识别模型;
[0035]
步骤s2,采集机器人与被测者互动过程中被测者的语音信息;
[0036]
步骤s3,将采集的语音信息进行预处理,将语音特征量化为m维的语音特征向量;
[0037]
步骤s4,对经步骤s2采集、步骤s3处理后的语音信号利用训练好的自闭症语音特征识别模型进行语音特征识别。
[0038]
与现有技术相比,本发明提供一种自闭症语音特征辅助识别机器人及方法,通过利用长短期记忆神经网络(lstm)和卷积神经网络(cnn)设计自闭症语音特征识别模型。采集自闭症语音特征,以语音传感信号作为传感信号输入,利用上述自闭症识别模型对自闭症语音特征在传感信号的表现特征进行学习,利用反向传播法对所述的自闭症语音特征识别模型进行训练,实现分类器在网络权重的优化,最终获得自闭症语音特征识别模型,然后利用所获取的自闭症语音特征识别模型,对自闭症患者的语音信号进行识别,可辅助解决目前自闭症筛查技术中人工筛选误差大、效率低的问题,同时本发明通过将长短期记忆神经网络(lstm)和卷积神经网络(cnn)结合,对语音序列进行处理,提高了语音特征识别的鲁棒性和准确性。
附图说明
[0039]
图1为本发明一种自闭症语音特征辅助识别机器人的系统架构图;
[0040]
图2为本发明具体实施例中所构建的自闭症语音特征识别模型的结构示意图;
[0041]
图3为本发明一种自闭症语音特征辅助识别方法的步骤流程图;
[0042]
图4为本发明实施例中实验场地的布局示意图;
[0043]
图5为本发明实施例的流程图。
具体实施方式
[0044]
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
[0045]
图1为本发明一种自闭症语音特征辅助识别机器人的系统架构图。如图1所示,本发明一种自闭症语音特征辅助识别机器人,包括:
[0046]
自闭症语音特征识别模型构建及训练单元101,利用长短记忆神经网络(lstm)和卷积神经网络(cnn)构建自闭症语音特征识别模型,以量化的语音特征作为传感信号输入所述自闭症语音特征识别模型,对语音特征在传感信号的表现特征(例如描述语音特征的
量有音量、音调、期间语音的停顿时长等等,在传感信号中可以表现为达到某一个值或者是某一类特定的序列矩阵)进行学习,并利用反向传播法对所述自闭症语音特征识别模型进行训练,实现分类器在网络权重的优化,最终获得可用于语音信号识别的自闭症语音特征识别模型。
[0047]
在本发明中,所述自闭症语音特征识别模型由输入层、lstm网络层、bn1层、cnn网络层、池化层、bn2层、flatten层、dropout层、全连接层、输出层依次连接,如图2所示。
[0048]
其中,所述输入层用于获取量化的m维语音特征向量,在本发明中,所述输入层为nxn的特征矩阵,即获取语音信息预处理单元103量化处理后转换为n
×
n的特征矩阵的m维特征向量。
[0049]
lstm网络作为传统递归神经网路的一种改进网络,对语音信息进行长时存储,是一种具有记忆功能的神经网络,能对时间序列数据建模。在本发明中,所述lstm网络,由lstm1层、lstm2层依次连接,所述lstm1层,输出维度50,所述lstm2层输出维度为30,激活函数均为tanh;所述lstm网络的作用为对长序列语音进行处理,所述lstm网络模型输出的是一个维度为30的语音特征序列。
[0050]
具体地,所述lstm网络的lstm1层和lstm2层分别包括:输出门,输入门,遗忘门,通过各个门的参数来控制输出信息用x
t
和h
t
分别表示lstm网络的输入值与输出值,t时刻候选记忆单元信息计算如下:
[0051][0052]
输入门i
t
由当前输入数据x
t
和前一时刻单元输出h
t-1
决定,计算公式为:
[0053][0054]
遗忘门f
t
控制历史信息的传递,计算公式为:
[0055][0056]
输出门o
t
计算lstm单元的输出值h
t
,计算公式为:
[0057][0058]
所述cnn网络,即卷积层可视为模糊滤波器,它将经过上层处理的特征向量和当前层的卷积核执行卷积运算,增强原始信号的特征并减少噪声。最后由激活函数给出卷积计算结果。所述卷积层可描述为:
[0059][0060]
其中信号x(n)为语音信号经过两层lstm层和一层bn层后输出的维度为30的语音特征序列,w(n)为卷积核,通过将信号x(n)与大小为l的卷积核w(n)进行卷积来获得该卷积层的输出结果z(n)。
[0061]
在本发明具体实施例中,所述cnn网络由conv1d1层、池化层、conv1d2层依次连接,所述conv1d1层滤波器个数为512,卷积核大小为3,所述conv1d2层滤波器个数为256,卷积核大小为3,激活函数均为relu;所述最大池化层的池大小为2;cnn网络输出层则是经过滤波以后的语音特征序列。
[0062]
当然,所述自闭症语音特征识别模型还包括池化层、bn2层、flatten层、dropout层、全连接层、输出层,其中池化层主要是用于去除冗杂信息、对特征进行压缩并简化神经网络的复杂程度,bn2层,主要是用于加快网络的训练和收敛速度并防止过拟合,flatten层,主要是将多维的输入一维化,全连接层,主要用于对信息进行分类,输出层,主要是指从全连接层输出序列,由于池化层、bn2层、flatten层、dropout层、全连接层、输出层等不是本发明的重点,其实现与现有技术相同,因此在此不予追述,本发明关键在于lstm层和cnn层的结合。
[0063]
当建立好上述自闭症语音特征识别模型后,则以语音采集单元102、语音信息预处理单元103获得的量化的语音特征作为传感信号输入所述自闭症语音特征识别模型,对语音特征在传感信号的表现特征进行学习,利用反向传播法对所述自闭症语音特征识别模型进行训练,实现分类器在网络权重的优化,最终获得可用于语音信号识别的自闭症语音特征识别模型。
[0064]
语音采集单元102,用于采集机器人与被测者互动过程中被测者的语音信息。
[0065]
在本发明具体实施例中,语音采集单元102可通过机器人内置的麦克风或评估者、被试者身上的可穿戴麦克风采集机器人与被测者互动筛查过程中的语音信息。本发明中,机器人作为筛查过程中的主体,具有类人的特点,通过向被试者展示歌曲和舞蹈吸引被试者的兴趣,并引导被试者尽可能地发出更多语音信息。
[0066]
语音信息预处理单元103,用于将采集的语音信息进行预处理,将语音特征量化为m维的语音特征向量。
[0067]
具体地,语音信息预处理单元103进一步包括:
[0068]
预加重处理模块,用于对输入的语音信号进行预加重。
[0069]
在本发明具体实施例中,采用数字滤波器实现预加重,预加重中语音通过的数字滤波器为:
[0070]
h(z)=1-μz-1
[0071]
其中μ为预加重系数,z为一个复数,指的是语音信号的频率。
[0072]
预加重网络的输出和输入的语音信号s(n)的关系为:
[0073][0074]
其中a也为预加重系数。
[0075]
分帧加窗模块,用于将语音信号分段来分析其特征参数,分析出由每一帧特征参数组成的特征参数时间序列。
[0076]
在本发明具体实施例中,分帧加窗是用可移动的有限长度窗口进行加权的方式来实现的,也就是用一定的窗函数w(n)来乘s(n),加窗信号为:
[0077]
s_w(n)=s(n)*w(n)
[0078]
本发明所用的是汉明窗,窗函数为:
[0079][0080]
快速傅立叶变换模块,用于对每一帧信号,通过快速傅立叶变换(fft)得到对应的频谱。具体地说,在分帧加窗模块中语音信号s(n)乘上汉明窗后,每帧还必须再经过快速傅
里叶变换以得到在频谱上的能量分布,也就是得到对应的频谱。
[0081]
三角带通滤波模块,用于将经过快速傅里叶得到的频谱通过一组mel尺度的三角形滤波器组,得到mel频谱,本发明中定义一共有m个滤波器的滤波器组,采用的滤波器为三角滤波器,m通常取22-26。三角带通滤波模块目的是对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。
[0082]
计算对数能量模块,用于计算每一帧信号的对数能量,以区分清音和浊音、判断每一帧中的无声段和有声段,所述对数能量指的是音量,计算方法是一帧内信号的平方和,再取以10为底的对数值,再乘以10,使得每一帧基本的语音特征多一维。
[0083]
能量对数s(m)
[0084][0085]
离散余弦变换(dct)模块,用于将上述的对数能量代入离散余弦变换公式,求出l阶的mel倒普参数c(n)。l是语音特征阶数,通常取12-16,m是三角滤波器个数。下面是离散余弦变换的公式:
[0086][0087]
其中,c(n)则为最终所需要的语音特征,即m维特征向量转换成的nxn的特征矩阵。
[0088]
语音特征识别单元103,用于利用训练好的自闭症语音特征识别模型,对经语音采集单元102采集、语音信息预处理单元103处理后的语音信号进行语音特征识别。在本发明具体实施例中,所述自闭症语音特征识别模型输出的情感分类结果包括但不限制于:高兴、生气、害怕、悲伤、惊讶、中性。
[0089]
图3为本发明一种自闭症语音特征辅助识别方法的步骤流程图。如图3所示,本发明一种自闭症语音特征辅助识别方法,包括如下步骤:
[0090]
步骤s1,基于长短记忆神经网络(lstm)和卷积神经网络(cnn)构建自闭症语音特征识别模型,以量化的语音特征作为传感信号输入所述自闭症语音特征识别模型,对语音特征在传感信号的表现特征进行学习(例如描述语音特征的量有音量、音调、期间语音的停顿时长等等,在传感信号中可以表现为达到某一个值或者是某一类特定的序列矩阵),并利用反向传播法对所述自闭症语音特征识别模型进行训练,实现分类器在网络权重的优化,最终获得可用于语音信号识别的自闭症语音特征识别模型。
[0091]
在本发明中,所述自闭症语音特征识别模型由输入层、lstm网络层、bn1层、cnn网络层、池化层、bn2层、flatten层、dropout层、全连接层、输出层依次连接。
[0092]
其中,所述输入层用于获取量化的m维语音特征向量,在本发明中,所述输入层为nxn的特征矩阵,即获取语音信息预处理单元103量化处理后转换为n
×
n的特征矩阵的m维特征向量。
[0093]
lstm网络作为传统递归神经网路的一种改进网络,对语音信息进行长时存储,是一种具有记忆功能的神经网络,能对时间序列数据建模。在本发明中,所述lstm网络,由lstm1层、lstm2层依次连接,所述lstm1层,输出维度50,所述lstm2层输出维度为30,激活函数均为tanh;所述lstm网络的作用为对长序列语音进行处理,所述lstm网络模型输出的是一个维度为30的语音特征序列。
[0094]
具体地,所述lstm网络的lstm1层和lstm2层分别主要包括:输出门,输入门,遗忘
门,通过各个门的参数来控制输出信息用x
t
和h
t
分别表示lstm网络的输入值与输出值,t时刻候选记忆单元信息计算如下:
[0095][0096]
输入门i
t
由当前输入数据x
t
和前一时刻单元输出h
t-1
决定,计算公式为:
[0097][0098]
遗忘门f
t
控制历史信息的传递,计算公式为:
[0099][0100]
输出门o
t
计算lstm单元的输出值h
t
,计算公式为:
[0101][0102]
所述cnn网络,即卷积层可视为模糊滤波器,它将经过上层处理的特征向量和当前层的卷积核执行卷积运算,增强原始信号的特征并减少噪声。最后由激活函数给出卷积计算结果。所述卷积层可描述为:
[0103][0104]
其中信号x(n)为语音信号经过两层lstm层和一层bn层后输出的维度为30的语音特征序列,w(n)为卷积核,通过将信号x(n)与大小为l的卷积核w(n)进行卷积来获得该卷积层的输出结果z(n)。
[0105]
在本发明具体实施例中,所述cnn网络由conv1d1层、池化层、conv1d2层依次连接,所述conv1d1层滤波器个数为512,卷积核大小为3,所述conv1d2层滤波器个数为256,卷积核大小为3,激活函数均为relu;所述最大池化层的池大小为2;cnn网络输出层则是经过滤波以后的语音特征序列。
[0106]
当然,所述自闭症语音特征识别模型还包括池化层、bn2层、flatten层、dropout层、全连接层、输出层,其中池化层主要是用于去除冗杂信息、对特征进行压缩并简化神经网络的复杂程度,bn2层,主要是用于加快网络的训练和收敛速度并防止过拟合,flatten层,主要是将多维的输入一维化,全连接层,主要用于对信息进行分类,输出层,主要是指从全连接层输出序列,由于池化层、bn2层、flatten层、dropout层、全连接层、输出层等不是本发明的重点,其实现与现有技术相同,因此在此不予追述,本发明关键在于lstm层和cnn层的结合。
[0107]
当建立好自闭症语音特征识别模型后,则以语音采集单元102、语音信息预处理单元103获得的量化的语音特征作为传感信号输入所述自闭症语音特征识别模型,对语音特征在传感信号的表现特征进行学习,利用反向传播法对所述自闭症语音特征识别模型进行训练,实现分类器在网络权重的优化,最终获得可用于语音信号识别的自闭症语音特征识别模型。
[0108]
步骤s2,采集机器人与被测者互动过程中被测者的语音信息。
[0109]
在本发明具体实施例中,可通过机器人内置的麦克风或评估者、被试者身上的可穿戴麦克风采集机器人与被测者互动筛查过程中的语音信息。本发明中,机器人作为筛查
过程中的主体,具有类人的特点,通过向被试者展示歌曲和舞蹈吸引被试者的兴趣,并引导被试者尽可能地发出更多语音信息。
[0110]
步骤s3,用于将采集的语音信息进行预处理,将语音特征量化为m维的语音特征向量。
[0111]
具体地,步骤s3进一步包括:
[0112]
步骤s300,对输入的语音信号进行预加重。
[0113]
在本发明具体实施例中,采用数字滤波器实现预加重,预加重中语音通过的数字滤波器为:
[0114]
h(z)=1-μz-1
[0115]
其中μ为预加重系数,z为一个复数,指的是语音信号的频率。
[0116]
预加重网络的输出和输入的语音信号s(n)的关系为:
[0117][0118]
其中a也为预加重系数。
[0119]
步骤s301,将语音信号分段来分析其特征参数,分析出由每一帧特征参数组成的特征参数时间序列。
[0120]
在本发明具体实施例中,分帧加窗是用可移动的有限长度窗口进行加权的方式来实现的,也就是用一定的窗函数w(n)来乘s(n),加窗信号为:
[0121]
s_w(n)=s(n)*w(n)
[0122]
本发明所用的是汉明窗,窗函数为:
[0123][0124]
步骤s302,对每一帧信号,通过快速傅立叶变换(fft)得到对应的频谱。具体地说,在步骤s301的分帧加窗中语音信号s(n)乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布,也就是得到对应的频谱。
[0125]
步骤s303,将经过快速傅里叶得到的频谱通过一组mel尺度的三角形滤波器组,得到mel频谱,本发明中定义一共有m个滤波器的滤波器组,采用的滤波器为三角滤波器,m通常取22-26。三角带通滤波模块目的是对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。
[0126]
步骤s304,计算每一帧信号的对数能量,以区分清音和浊音、判断每一帧中的无声段和有声段,所述对数能量指的是音量,计算方法是一帧内信号的平方和,再取以10为底的对数值,再乘以10,使得每一帧基本的语音特征多一维。
[0127]
能量对数s(m)
[0128][0129]
步骤s305,将上述的对数能量代入离散余弦变换公式,求出l阶的mel倒普参数c(n)。l是语音特征阶数,通常取12-16,m是三角滤波器个数。下面是离散余弦变换的公式:
[0130][0131]
其中,c(n)则为最终所需要的语音特征,即m维特征向量转换成的nxn的特征矩阵。
[0132]
步骤s4,对经步骤s2采集、步骤s3量化处理后的语音信号利用训练好的自闭症语音特征识别模型,进行语音特征识别。在本发明具体实施例中,所述自闭症语音特征识别模型输出的情感分类结果包括但不限制于:高兴、生气、害怕、悲伤、惊讶、中性。
[0133]
实施例
[0134]
图4为本发明实施例中实验场地的布局示意图。如图1场景中,本发明之机器人设计为人形机器人,实验场景中有被试者一名、评估者一名、人形机器人一台,本发明之人形机器人置于试验场地的桌面,正面正对被试者,背对评估者,人形机器人与被试者面对面相隔0.7-1米距离。
[0135]
如图5所示,本实施例的处理流程如下:
[0136]
步骤s1,人机互动,全程主要由人形机器人参与。
[0137]
步骤s1.1,人形机器人向被试进行简单的自我介绍,同时测试相关设备的运行情况。
[0138]
步骤s1.2,人形机器人向被试进行简单的提问,如“你好,我是xxx机器人,请问你叫什么名字?”等等。
[0139]
步骤s1.3,人形机器人向被试展示歌曲,对于疑似低功能自闭症对象,可由评估者向机器人发出相应的语音指令进行触发,若对于疑似高功能自闭症对象,评估者可以对被试作一定的引导,通过被试的语音信息来触发指令。评估者可以通过现场观察被试的的反应,做相关记录。
[0140]
步骤s1.4,人形机器人向被试展示舞蹈,对于疑似低功能自闭症对象,可由评估者向人形机器人发出相应的语音指令进行触发,若对于疑似高功能自闭症对象,评估者可以对被试作一定的引导,通过被试的语音信息来触发指令。评估者可以通过现场观察被试的的反应,做相关记录。
[0141]
步骤s2,数据采集,在互动的过程中,人形机器人内置的麦克风、被试者和评估者身上的可穿戴麦克风会全程录音。通过软件wincsp,从pc端获取人形机器人系统里保存到的录音文件。
[0142]
步骤s3,预处理,在pc端上对语音进行相关处理。
[0143]
步骤s3.1,采用数字滤波器实现预加重,预加重网络的输出和输入的语音信号s(n)的关系为:
[0144][0145]
步骤s3.2,分帧,将语音信号分段来分析其特征参数,分析出由每一帧特征参数组成的特征参数时间序列。
[0146]
步骤s3.3,加窗,对抽样n附近的语音波形加以强调而对波形的其余部分加以减弱。
[0147]
步骤s3.4,快速傅立叶变换,当分帧加窗中语音信号s(n)乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布,也就是得到对应的频谱。
[0148]
步骤s5,特征量化,包括三角带通滤波、计算对数能量以及离散余弦变换,具体步骤已在说明书中说明,本部分不再赘述。
[0149]
步骤s6,识别分析,运用自闭症语音特征识别模型对被试者的语音特征进行识别。
[0150]
步骤s7,将所有实验过程中的语音文件进行预处理后存入数据集文件夹。
[0151]
步骤s7.1,再次提取更新后的数据集中的语音特征。
[0152]
步骤s7.2,再次训练语音特征识别模型,根据训练结果不断调整模型结构。
[0153]
综上所述,本发明提供一种自闭症语音特征辅助识别机器人及方法,通过利用长短期记忆神经网络(lstm)和卷积神经网络(cnn)设计自闭症语音特征识别模型。采集自闭症语音特征,以语音传感信号作为传感信号输入,利用上述自闭症识别模型对自闭症语音特征在传感信号的表现特征进行学习,利用反向传播法对所述的自闭症语音特征识别模型进行训练,实现分类器在网络权重的优化,最终获得自闭症语音特征识别模型,然后利用所获取的自闭症语音特征识别模型,对自闭症患者的语音信号进行识别,可辅助解决目前自闭症筛查技术中人工筛选误差大、效率低的问题,同时本发明通过将长短期记忆神经网络(lstm)和卷积神经网络(cnn)结合,对语音序列进行处理,提高了语音特征识别的鲁棒性和准确性。
[0154]
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips