
 商标分类
商标分类  商标转让
商标转让 
基于语音交互的任务处理方法、装置及存储介质与流程
 2021-01-28 12:01:27|
2021-01-28 12:01:27| 304|
304| 起点商标网
起点商标网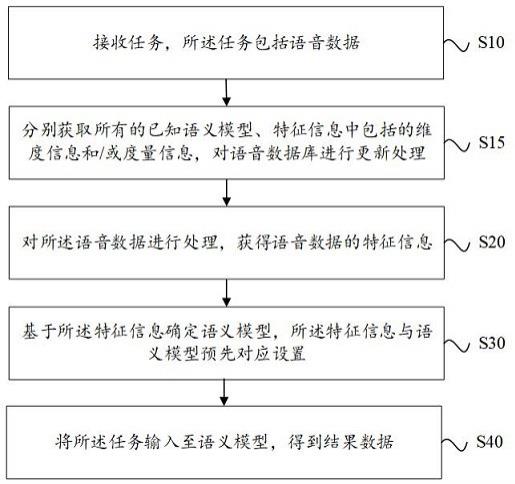
[0001]
本申请涉及大数据处理领域,具体而言,涉及基于语音交互的任务处理方法、装置及存储介质。
背景技术:
[0002]
在数据化的时代,如何通过olap(online analytical processing,联机处理处理)处理海量、复杂的数据以辅助商业决策,是商务智能和数据处理领域的重要课题;数据模型是olap处理的基础,数据模型则需要专业的建模人员根据任务处理需求,基于这些表设计数据模型供处理人员使用。处理人员的处理操作也是基于这个数据模型,最终都会转化为一系列针对数据表的sql (structured query language,结构化查询语言)查询。
[0003]
数据处理人员必须具备一定的技能知识,比如标准sql语句的语法,或者熟练使用bi(business intelligence,商业智能)产品的前提需要了解模型、维度、度量分别是什么,以便在bi产品的界面拖拉拽哪些才能得到目标数据图表。该数据处理方案完全依赖处理师对数据模型的熟悉,和业务需求的理解,且效率不高。尤其是在大数据实际场景中,整体数据规模大、维度和度量较多、业务需求复杂多变,加大了数据处理的难度和失去了最佳数据展示的可能。现在大数据人才缺乏,数据处理的门槛过高,面对一般的业务人员,没有匹配技能且有数据处理的需求,想要通过大数据平台获得数据处理对比结果,变得困难重重。
[0004]
维度建模是一种常见的人工数据建模方法,常用于处理性数据库、数据仓库、数据集市建模。维度建模把数据表分为两类:维度表和事实表。维度表主要表示对处理主题所属类型的描述,以订单处理为例,一个订单会包含以下若干维度:时间维度(下单时间)、地理维度(配送区域),且存在单独的表描述这些信息,如时间表、地理信息表等,即维度表。事实表表示处理主题的度量,如包含订单金额的订单表。事实表与维度表通过join方式关联。
[0005]
olap数据建模,极度依赖人工对数据表和业务需求的理解而实现,建模效率较低、成本较大。尤其在大数据实际场景中,整体数据规模大、维度和度量较多、业务需求复杂多变,加大的数据建模的难度和试错成本。这将可能导致数据处理应用的上线时间推迟,甚至对大数据多维处理的实际应用效率带来巨大影响。
[0006]
针对olap数据建模中如何降低使用大数据的门槛,减小人工建模代价的技术问题,目前尚未提出有效的解决方案。
技术实现要素:
[0007]
本申请的主要目的在于提供一种基于语音交互的任务处理方法,以解决由于大数据人才缺乏和数据处理的门槛过高,而造成的难于通过大数据平台获得数据处理比对结果的技术问题。
[0008]
为了实现上述目的,本申请提供了一种基于语音交互的任务处理方法、装置及存储介质。
[0009]
第一方面,本申请提供了一种基于语音交互的任务处理方法,包括:
接收任务,所述任务包括语音数据;对所述语音数据进行处理,获得语音数据的特征信息;基于所述特征信息确定语义模型,所述特征信息与语义模型预先对应设置;将所述任务输入至语义模型,得到结果数据。
[0010]
进一步的,接收任务,所述任务包括语音数据之后,还包括:分别获取所有的已知语义模型、特征信息中包括的维度信息和/或度量信息,对语音数据库进行更新处理,其中所述结果数据为语料库中的语料。
[0011]
进一步的,所述特征信息包括维度信息和/或度量信息;基于所述特征信息确定语义模型包括:获取所述维度信息和/或度量信息的文本;选择与维度信息和/或度量信息的文本对应的语义模型,其中所述维度信息和/或度量信息的文本与所述语义模型预先对应设置。
[0012]
进一步的,基于所述特征信息确定语义模型包括:获取所述任务包括的语音数据的所有文本;基于所述语音数据的所有文本选择与其对应的语义模型,其中每个语义模型分别具有与其对应的至少一个文本;判断选择的语义模型数量;其中,如果所述语义模型数量唯一,则所述语义模型对所述任务进行处理得到结果数据。
[0013]
进一步的,其中,如果所述语义模型数量不唯一,输出补充数据。
[0014]
进一步的,在其中,如果所述语义模型数量不唯一,输出补充数据后,还包括:二次接收任务,所述二次接收的任务包括二次语音数据;对所述二次语音数据进行处理,获取与二次语音数据对应的文本;基于先前所述语音数据的所有文本以及二次语音数据对应的文本选择与其对应的语义模型;其中,如果所述语义模型数量不唯一,则再次输出补充数据,重复以上步骤。
[0015]
进一步的,其中,如果所述语义模型小于一,则获取语音数据的特征信息,所述特征信息包括维度信息和度量信息;基于所述维度信息和度量信息生成新的语义模型,所述新的语义模型用于获取与所述维度信息和度量信息对应的维度值及度量值;所述语义模型基于所述维度值和度量值生成结果数据,所述结果数据包括维度值和度量值的显示图表。
[0016]
进一步的,将所述任务输入至语义模型,得到结果数据包括:所述语义模型获取维度信息和度量信息,获取与所述维度信息和度量信息对应的维度值及度量值;所述语义模型基于所述维度值和度量值生成结果数据,所述结果数据包括维度值和度量值的显示图表。
[0017]
第二方面,本申请提供了一种基于语音交互的任务处理装置包括:接收装置,用于接收任务,所述任务包括语音数据;
处理装置,用于对所述语音数据进行处理,获得语音数据的特征信息;确定装置,用于基于所述特征信息确定语义模型,所述特征信息与语义模型预先对应设置;结果获得装置,用于将所述任务输入至语义模型,得到结果数据。
[0018]
第三方面,本申请提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一方面提供的基于语音交互的任务处理方法的步骤。
[0019]
第四方面,本申请提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现第一方面提供的基于语音交互的任务处理方法的步骤。
[0020]
在本申请实施例中,基于语音交互的方式,采用识别语音的维度信息和度量信息,通过建立多维度的语义模型,达到自动建模或数据查询的目的,从而实现了降低大数据使用门槛并减小人工建模代价的技术效果,进而解决了由于大数据人才缺乏和数据处理的门槛过高,而造成的难于通过大数据平台获得数据处理比对结果的技术问题。
[0021]
本发明提供的方法和装置能够对语音数据输入任务进行处理,获得相应的维度和度量信息,通过语义模型对维度和度量信息进行处理得到相应的图表。本发明将自然语言处理、人工智能以及图表生成相结合,可以通过自然语言交互的方式得到不同维度、度量的相关图表数据。
附图说明
[0022]
构成本申请的一部分的附图用来提供对本申请的进一步理解,使得本申请的其它特征、目的和优点变得更明显。本申请的示意性实施例附图及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:图1为基于语音交互的任务处理方法的第一种实施方式的流程图;图2为结果数据的展示示意图;图3为基于语音交互的任务处理方法的第二种实施方式的流程图;图4为基于语音交互的任务处理方法的第三种实施方式的流程图;图5为基于语音交互的任务处理方法的第四种实施方式的流程图;图6为语音数据和补充数据的展示结构示意图;图7为基于语音交互的任务处理装置的第一种实施方式的流程图。
具体实施方式
[0023]
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
[0024]
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清
楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
[0025]
在本申请中,术语“上”、“下”、“左”、“右”、“前”、“后”、“顶”、“底”、“内”、“外”、“中”、“竖直”、“水平”、“横向”、“纵向”等指示的方位或位置关系为基于附图所示的方位或位置关系。这些术语主要是为了更好地描述本发明及其实施例,并非用于限定所指示的装置、元件或组成部分必须具有特定方位,或以特定方位进行构造和操作。
[0026]
并且,上述部分术语除了可以用于表示方位或位置关系以外,还可能用于表示其他含义,例如术语“上”在某些情况下也可能用于表示某种依附关系或连接关系。对于本领域普通技术人员而言,可以根据具体情况理解这些术语在本发明中的具体含义。
[0027]
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
[0028]
根据本发明实施例,提供了一种基于语音交互的任务处理方法,如图1所示,包括:步骤s10、接收任务,所述任务包括语音数据。其中语音数据可以通过智能语音机器人的方式进行收录。一个任务里面可以包括一个或多个的语音数据。
[0029]
步骤s20、对所述语音数据进行处理,获得语音数据的特征信息。其中语音的特征信息可以是由任意的字、词以及数字组成的维度信息、度量信息等等。
[0030]
维度信息是指一种视角,是一个判断、说明、评价和确定一个事物的多方位、多角度、多层次的条件和概念。
[0031]
实例的,在银行业务中,主体维度包括:机构、客户、雇员;公共维度有时间;业务维度包括:产品、期限、资产质量和担保方式。
[0032]
具体的,度量信息是指在实际业务中可衡量的、不可枚举穷尽的各类标准或统计数值。是一个可进行运算、统计的数值。一个限定了范围的业务对象、主体或者业务活动都具有一组度量值来对其进行描述。
[0033]
实例的,在银行业务中,基础度量包括:数量、余额、完成率、日均余额、利息、手续费;衍生度量括:比上日增长、月初、比月初、比上年增长。
[0034]
实例的,对语音数据“1年期不良贷款余额”进行处理,得到维度信息“1年期”、“不良”和度量信息“贷款余额”步骤s30、基于所述特征信息确定语义模型,所述特征信息与语义模型预先对应设置。其中语义模型具有很多,例如有些语义模型是处理银行的产品(维度)、数量(度量)的,有些语义模型是客户(维度)、数量(度量)的,这两种不同维度的处理方式可能会采取不同的语义模型。通过特征信息能够选取相应的语义模型。
[0035]
步骤s40、将所述任务输入至语义模型,得到结果数据。通过确定的语义模型对任务进行处理,得到结果数据。在本事实例中,结果数据可以是图表的数据形式,例如图2所示。上述步骤,在大数据可视化处理平台kyligence insight应用该语义模型,通过对维度信息和度量信息的处理之后,创建对应的图表。
[0036]
步骤s15、接收任务,所述任务包括语音数据之后,还包括:分别获取所有的已知语义模型、特征信息中包括的维度信息和/或度量信息,对语音数据库进行更新处理,其中所述结果数据为语料库中的语料。
[0037]
本发明提供的方法和装置方案能够对语音数据输入任务进行处理,获得相应的维度和度量信息,通过任务处理模型语义模型对维度和度量信息进行处理得到相应的图表,
实现语义模型的智能多维回答,并且在语音交互的过程中能够智能增强语义模型。实现了降低大数据使用门槛并减小人工建模代价的技术效果,进而解决了解决了由于大数据人才缺乏和数据处理的门槛过高,而而造成的难于通过大数据平台获得数据处理比对结果的技术问题。
[0038]
在一个实施例中,如图3所示,所述特征信息包括维度信息和/或度量信息;在步骤s30中,还包括:s301、获取所述维度信息和/或度量信息的文本。其中本事实例中的文本可以是汉子的文本、英文的文本以及机器语言的文本,在此不做限制,只要文本能够与维度信息和/或度量信息进行对应即可。
[0039]
s302、选择与维度信息和/或度量信息的文本对应的语义模型,其中所述维度信息和/或度量信息的文本与所述语义模型预先对应设置。通过将文本与维度信息和/或度量信息预先对应,使得在接收到维度信息和/或度量信息的文本后,既可以快速寻找到相应的语义模型。
[0040]
在一个实施例中,如图4所示,在步骤s30中,还包括:s311、获取所述任务包括的语音数据的所有文本。其中一个任务可能会包括若干语音数据。若干语音数据可能会具有若干的文本。
[0041]
s312、基于所述语音数据的所有文本选择与其对应的语义模型,其中每个语义模型分别具有与其对应的至少一个文本。其中每个语义模型分别具有至少一个文本,例如说一个语义模型对应的文本含义是会员(维度)、数量(度量),则当输入的语音数据的所有文本具有会员(维度)、数量(度量)时,即输出该语义模型。
[0042]
s313、判断选择的语义模型数量。根据使用者输入的语音数据的所有文本不同,可能会产生不同的模型数量。
[0043]
s314、其中,如果所述语义模型数量唯一,则所述语义模型对所述任务进行处理得到结果数据。此时能够确定与任务相对应的语义模型。
[0044]
在一个实施例中,s400、其中,如果所述语义模型数量不唯一,输出补充数据。例如说例如说一个语义模型对应的文本含义是数量(度量),这个具有度量但是并没有维度,所以此时具有这个数量(度量)的模型会具有多个,此时输出补充数据,其中补充数据可以是进行提醒,需要输入的任务包括的语音数据需要包括维度或度量。
[0045]
在一个实施例中,如图5所示,在其中,如果所述语义模型数量不唯一,输出补充数据后,还包括:s401、二次接收任务,所述二次接收的任务包括二次语音数据。其中二次语音数据也可以是多个。如图6所示,例如说先前接收任务的语音数据为“销售额是多少”,这个时候确定了“销售额是多少”这个度量,但是没有维度,会进行输出补充数据为“您想要什么时候的销售额”,这个时候对使用者进行提醒。
[0046]
s402、对所述二次语音数据进行处理,获取与二次语音数据对应的文本。
[0047]
s403、基于先前所述语音数据的所有文本以及二次语音数据对应的文本选择与其对应的语义模型;s404、其中,如果所述语义模型数量不唯一,则再次输出补充数据,重复以上步骤。
[0048]
在一个实施例中,其中,如果所述语义模型小于一,则获取语音数据的特征信息,
所述特征信息包括维度信息和度量信息。当语义模型小于1时,则证明此时不具有处理该任务的语义模型,此时需要建立新的模型。
[0049]
基于所述维度信息和度量信息生成新的语义模型,所述新的语义模型用于获取与所述维度信息和度量信息对应的维度值及度量值。通过以上方式能够建立新的模型。通过模型将维度信息或度量信息转换为编程语言,将并输入至具有自动建模功能的大数据olap处理引擎,自动建立语义模型。
[0050]
在大数据olap处理引擎kyligence enterprise上应用该模型,进行维度和度量的处理之后,将多维度的语义模型转成标准sql语句,然后就可接到kyligence enterprise的自动建模功能。
[0051]
所述语义模型基于所述维度值和度量值生成结果数据,所述结果数据包括维度值和度量值的显示图表。
[0052]
在一个实施例中,将所述任务输入至语义模型,得到结果数据包括:所述语义模型获取维度信息和度量信息,获取与所述维度信息和度量信息对应的维度值及度量值;所述语义模型基于所述维度值和度量值生成结果数据,所述结果数据包括维度值和度量值的显示图表。
[0053]
根据本发明实施例,还提供了一种用于实施上述基于语音交互的任务处理方法的基于语音交互的任务处理装置,如图7所示,该装置包括接收装置,用于接收任务,所述任务包括语音数据;处理装置,用于对所述语音数据进行处理,获得语音数据的特征信息;确定装置,用于基于所述特征信息确定语义模型,所述特征信息与语义模型预先对应设置;结果获得装置,用于将所述任务输入至语义模型,得到结果数据。
[0054]
从以上的描述中,可以看出,本发明实现了如下技术效果:降低了用户获得大数据图表的门槛,不用理解业务中对应的维度信息或度量信息的具体字段名,解放了用户的双手,不用反复拖拽查询建立图表。使用语音输入自然语言,就可以获得对应的图表结果。
[0055]
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
[0056]
显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
[0057]
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips