
 商标分类
商标分类  商标转让
商标转让 
交互控制方法、装置、计算机设备和存储介质与流程
 2021-01-11 14:01:41|
2021-01-11 14:01:41| 342|
342| 起点商标网
起点商标网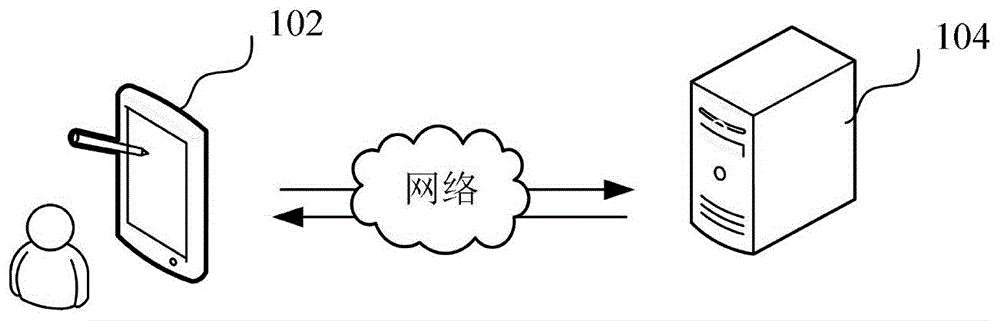
本申请涉及计算机
技术领域:
,特别是涉及一种交互控制方法、装置、计算机设备和存储介质。
背景技术:
:随着科学技术的不断发展,游戏逐渐成为人们热衷的娱乐节目,例如,用户可以通过相关游戏应用进行棋牌游戏,例如斗地主游戏。传统技术中,可以进行人机对战,由计算机设备模拟执行各种动作的结果来确定最终要执行的交互动作,然而,经常存在确定最终要执行的交互动作的复杂度高的情况,即确定交互动作的效率低。技术实现要素:基于此,有必要针对上述技术问题,提供一种交互控制方法、装置、计算机设备和存储介质。一种交互控制方法,所述方法包括:获取交互式任务当前的实际交互状态;根据当前交互状态确定各个候选交互动作对应的交互动作选择分数,其中,初始的当前交互状态为所述实际交互状态;根据各个所述候选交互动作对应的交互动作选择分数筛选得到模拟交互动作;模拟执行各个所述模拟交互动作,得到模拟交互状态;将所述模拟交互状态作为当前交互状态,返回所述根据当前交互状态确定各个候选交互动作对应的交互动作选择分数的步骤,直至完成交互式任务或者模拟深度达到深度阈值,得到目标博弈树,所述目标博弈树包括各个当前交互状态对应的状态节点,在母状态节点对应的交互状态下执行模拟交互动作,得到子状态节点对应的交互状态;根据所述目标博弈树从所述模拟交互动作中确定目标交互动作,控制目标虚拟对象执行所述目标交互动作。一种交互控制装置,所述装置包括:实际交互状态获取模块,用于获取交互式任务当前的实际交互状态;交互动作选择分数确定模块,用于根据当前交互状态确定各个候选交互动作对应的交互动作选择分数,其中,初始的当前交互状态为所述实际交互状态;模拟交互动作筛选模块,用于根据各个所述候选交互动作对应的交互动作选择分数筛选得到模拟交互动作;模拟交互状态得到模块,用于模拟执行各个所述模拟交互动作,得到模拟交互状态;返回模块,用于将所述模拟交互状态作为当前交互状态,返回所述根据当前交互状态确定各个候选交互动作对应的交互动作选择分数的步骤,直至完成交互式任务或者模拟深度达到深度阈值,得到目标博弈树,所述目标博弈树包括各个当前交互状态对应的状态节点,在母状态节点对应的交互状态下执行模拟交互动作,得到子状态节点对应的交互状态;目标交互动作确定模块,用于根据所述目标博弈树从所述模拟交互动作中确定目标交互动作,控制目标虚拟对象执行所述目标交互动作。一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述交互控制方法的步骤。一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述交互控制方法的步骤。上述交互控制方法、装置、计算机设备和存储介质,由于可以根据实际交互状态确定模拟交互动作,根据模拟交互动作进行模拟,得到模拟交互状态,将模拟交互状态作为当前交互状态,返回根据当前交互状态确定各个候选交互动作对应的交互动作选择分数的步骤,直至完成交互式任务或者模拟深度达到深度阈值,得到目标博弈树,因此目标博弈树是基于候选交互动作对应的交互动作选择分数进行了宽度剪枝的博弈树,而模拟交互动作是根据候选交互动作对应的交互动作选择分数确定的,因此基于该博弈树确定目标交互动作,既能够提高搜索博弈树的效率,又能够提高得到的目标交互动作的准确度。附图说明图1为一个实施例中交互控制方法的应用环境图;图2为一个实施例中交互控制方法的流程示意图;图3为一个实施例中目标博弈树的示意图;图4为另一个实施例中根据当前交互状态确定各个候选交互动作对应的交互动作选择分数的流程示意图;图5为一个实施例中输入到动作选择模型的特征的示意图;图6为一个实施例中基于规则确定模拟交互动作的示意图;图7为一个实施例中目标博弈树的示意图;图8为一个实施例中目标博弈树的示意图;图9为一个实施例中目标博弈树的示意图;图10为一个实施例中采用其他剪枝算法剪枝得到的博弈树的示意图;图11为一个实施例中基于alpha-beta算法以及基于动作选择模型进行剪枝得到的博弈树的的示意图;图12为一个实施例中cnn模型的示意图;图13为一个实施例中resnet34层的示意图;图14为一个实施例中resnet加上cbam模块的示意图;图15为一个实施例中cbam注意力模块的示意图;图16为一个实施例中cbam注意力模块的示意图;图17为一个实施例中交互控制装置的结构框图;图18为一个实施例中计算机设备的内部结构图。具体实施方式为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。本申请提供的交互控制方法,可以应用于如图1所示的应用环境中。其中,终端102通过网络与服务器104进行通信。终端102上可以安装有交互应用,例如斗地主游戏应用,通过该交互应用可以显示交互画面,终端102对应的用户可以通过操作控制虚拟对象执行对应的交互动作,从而改变交互画面。服务器104可以执行本申请实施例提供的交互控制方法,控制服务器所需要控制的目标虚拟对象执行交互动作,从而实现与终端102控制的虚拟对象进行交互。可以理解,也可以由终端102执行本申请实施例提供的方法。其中,服务器104所控制的目标虚拟对象可以是需要进行游戏托管的虚拟对象。例如,假设用户a、b以及c进行斗地主游戏,其中用户c对应的虚拟对象进入托管状态,需要由游戏ai(artificialintelligence)代替用户c对虚拟对象进行控制,则可以由服务器104执行本申请实施例提供的方法。其中,进入托管状态可以是根据用户c的操作设置的也可以是自动设置的。例如,当用户c的终端所处的网络环境不佳时,可以自动进入托管状态。服务器所控制的目标虚拟对象也可以是人机对战模式下分配给游戏ai的虚拟对象,例如,当接收到用户与游戏ai进行游戏对战的请求时,可以为游戏ai分配预设角色,例如是农民。其中,终端102可以但不限于是各种个人计算机、笔记本电脑、智能手机、平板电脑和便携式可穿戴设备,服务器104可以用独立的服务器或者是多个服务器组成的服务器集群来实现。在一个实施例中,如图2所示,提供了一种交互控制方法,以该方法应用于图1中的服务器为例进行说明,包括以下步骤:步骤s202,获取交互式任务当前的实际交互状态。其中,交互式任务可以是指需要通过虚拟对象进行交互的任务,例如可以是多玩家的对局类游戏,如棋牌类游戏。棋牌类游戏例如可以是斗地主游戏、升级游戏和跑得快游戏等等。当前的实际交互状态是指当前时刻,所处的实际的交互状态。交互状态可以包括当前各虚拟对象持有的资源或者已经使用的资源的至少一个。对于棋牌类游戏,交互状态可以包括当前已经出过的牌以及当前持有的牌。具体地,当需要确定目标虚拟对象所需要执行的目标交互动作时,可以获取交互式任务当前的实际交互状态。例如,当托管的对象为地主时,若轮到地主出牌,则获取交互式任务当前的实际交互状态,以确定地主当前要怎么出牌。在一些实施例中,对于斗地主游戏,当前游戏状态可以包括当前持有的牌、虚拟对象所处的位置、未出的牌以及已出的牌的至少一种。虚拟对象所处的位置例如为“地主”、“上家”或者“下家”。步骤s204,根据当前交互状态确定各个候选交互动作对应的交互动作选择分数。其中,初始的当前交互状态为实际交互状态。即在第一次确定模拟交互动作时,将实际交互状态作为当前交互状态。对于棋牌类游戏,候选交互动作可以根据要出的牌型以及对应的牌确定。例如候选交互动作可以为“出顺子3、4、5、6、7”,表示牌型为“顺子”,牌为“3、4、5、6、7”。交互动作选择分数代表交互动作被选择的可能度,分数越高,则交互动作被选择的可能性越高。例如,交互动作选择分数可以用概率表示,可以将人工智能模型输出的交互动作被选择的概率作为交互动作选择分数。交互动作选择分数也可以是模型输出的或者根据预设动作评分规则进行评分的至少一种得到的。当前交互状态是指当前的交互状态。在进行交互模拟时,当前交互状态不断的进行更新。候选交互动作是指候选的交互动作,候选交互动作是根据目标虚拟对象所持有的资源确定的,可以为多个。例如,假设目标虚拟对象手中持有的牌包括一个3以及3个2,则候选交互动作包括“出单牌3”、“出三带,3个2带1个3”、“出一对2”以及“出单牌2”等4个候选交互动作。具体地,服务器可以获取当前交互状态,根据当前交互状态确定交互状态特征,将交互状态特征输入到已训练的交互动作确定模型(动作选择模型)中,得到各个候选交互动作对应的交互动作选择分数。服务器也可以根据当前交互状态,基于预设的动作评分规则进行评分,得到候选交互动作对应的交互动作选择分数。服务器也可以将交互动作确定模型输出的交互动作选择分数以及动作评分规则评分得到的交互动作选择分数进行加权求和,得到各个候选交互动作对应的交互动作选择分数。例如,假设交互动作确定模型输出的交互动作选择分数为0.8,对应的权重为9,而动作评分规则评分得到的交互动作选择分数为10,对应的权重为1,则该候选交互动作对应的交互动作选择分数为0.8*9+10*1=17.2。步骤s206,根据各个候选交互动作对应的交互动作选择分数筛选得到模拟交互动作。具体地,模拟交互动作是指需要进行模拟交互的动作。即该动作在交互式任务中不是实际进行,而是由服务器进行模拟,假设执行该交互动作,所得到的交互状态是怎么样。候选交互动作可以为多个,模拟交互动作是从候选交互动作中选择的,也可以为多个。服务器可以对各个候选交互动作对应的交互动作选择分数按照从大到小的顺序进行排序,将排序在第一排序之前的交互动作选择分数对应的候选交互动作作为模拟交互动作。第一排序可以根据需要设置,例如在正常交互的情况下可以是第3,在残局情况下为第5。例如,假设有8个候选交互动作,则可以选择在分数在第3或者第5名之前的候选交互动作作为需要模拟的交互动作,以对博弈树进行剪枝。步骤s208,模拟执行各个模拟交互动作,得到模拟交互状态。具体地,模拟交互状态是指模拟执行模拟交互动作之后,所得到的交互状态。得到模拟交互动作之后,则可以模拟执行该动作,得到模拟交互状态。步骤s210,判断是否完成交互式任务或者模拟深度达到深度阈值。具体地,模拟深度可以通过模拟的轮次表示也可以通过模拟的次数表示,模拟深度也可以称为搜索深度。各个虚拟对象均模拟执行一次交互动作为一轮。例如,在斗地主中,两个农民以及一个地主均出牌一次为一轮。完成交互式任务是指交互式任务已经结束,深度阈值可以根据需要设置,例如为5。通过设置次数阈值,可以提高确定目标交互动作的效率。如果交互式任务或者模拟深度达到深度阈值,则得到最终的目标博弈树,并进入步骤s212。否则,可以将模拟交互状态作为当前交互状态,返回根据当前交互状态确定各个候选交互动作对应的交互动作选择分数的步骤,直至完成交互式任务或者模拟深度达到深度阈值,得到目标博弈树。目标博弈树包括各个当前交互状态对应的状态节点,在母状态节点对应的交互状态下执行模拟交互动作,得到子状态节点对应的交互状态。母状态节点与子状态节点是相对而言的,相邻的存在路径的连接的状态节点中,在先的状态节点为母状态节点,在后的状态节点为该目标状态节点的子状态节点。步骤s212,根据目标博弈树从多个模拟交互动作中确定目标交互动作,控制目标虚拟对象执行目标交互动作。具体地,目标交互动作可以为1个。得到目标博弈树后,可以基于博弈树进行回溯,得到使得目标虚拟对象的收益最大的模拟交互动作,作为目标交互动作,并控制目标虚拟对象执行目标交互动作,例如,假设目标交互动作是“出1个3”,目标虚拟对象为斗地主游戏中的农民a,则控制农民a出一个3。在一些实施例中,还可以基于alpha-beta剪枝算法对博弈树进行剪枝,alpha-beta剪枝算法是一个搜索算法,旨在减少在其搜索树中,被极大极小算法评估的节点数。它的基本思想是根据上一层已经得到的当前最优结果,决定目前的搜索是否要继续下去。上述交互控制方法,由于可以根据实际交互状态确定模拟交互动作,根据模拟交互动作进行模拟,得到模拟交互状态,将模拟交互状态作为当前交互状态,返回根据当前交互状态确定各个候选交互动作对应的交互动作选择分数的步骤,直至完成交互式任务或者模拟深度达到深度阈值,得到目标博弈树,因此目标博弈树是基于候选交互动作对应的交互动作选择分数进行了宽度剪枝的博弈树,而模拟交互动作是根据候选交互动作对应的交互动作选择分数确定的,因此基于该博弈树确定目标交互动作,既能够提高搜索博弈树的效率,又能够提高得到的目标交互动作的准确度。如图3所示,为一些实施例中的目标博弈树的示意图,假设目标虚拟对象为斗地主中的地主,因此根节点为地主对应的节点,叶子节点可以是上家、下家或者地主所对应的节点,叶子节点下的数字表示最终的收益值(交互激励分数)。其中,上家以及下家是相对于地主而言的,地主出牌之后,再出牌的虚拟对象称为下家。上家是指该虚拟对象出牌之后,地主再出牌。例如,斗地主游戏中,有三个虚拟对象,地主、农民a以及农民b,假设地主出牌之后农民a出牌,农民a出牌之后农民b出牌。则农民a为下家,农民b为上家。“α-β剪枝”是指利用alpha-beta剪枝算法进行剪枝。由图3可以看出,状态节点所对应的要出牌的虚拟对象随着游戏而变化,“α:100”表示α-β剪枝中的α值为100,“β:100”表示α-β剪枝中的β值为20。服务器可以基于出牌策略以及游戏状态确定模拟交互动作,出牌策略可以是残差网络(resnet)、cnn(convolutionalneuralnetworks,卷积神经网络)网络或者规则策略的一个,例如可以输出模型输出的动作被选择的概率s(a’)或者根据预设规则进行评分得到的分数p(a’)。因此服务器可以根据模型输出的动作被选择的概率或者根据预设规则进行评分得到的分数选择前3个动作作为模拟交互动作,前3个动作是指分数或者概率按照从大到小的顺序进行排序,排序在前3的动作。可以理解,还可以是根据具体的情况确定模拟交互动作的数量。例如,当是正常对局时,可以选择前3个动作,在残局的情况下可以选择前5个。可以重复执行确定模拟交互动作的过程,直至搜索深度达到预设深度阈值k。然后可以进行回溯,得到执行a1动作、a2动作以及a3动作可以达到的收益,然后选择收益最大的动作作为目标交互动作。在一个实施例中,如图4所示,根据当前交互状态确定各个候选交互动作对应的交互动作选择分数包括:步骤s402,根据各个历史交互动作对应的历史交互资源以及历史交互资源对应的历史交互动作类型,得到第一交互特征。其中,历史交互动作是指交互式任务中,处于当前交互状态时,已经执行的动作。历史交互资源是指该历史交互动作所使用的资源。历史交互动作类型是指该动作的类型。交互资源对应的历史交互动作类型可以是历史交互资源组合得到的,例如可以是顺子、对子、火箭或者炸弹。例如,假设历史交互动作出的牌为“3、4、5、6、7”,则历史交互资源为“3、4、5、6、7”,历史交互动作类型为“顺子”。交互特征可以用特征值表示,例如可以获取历史交互资源对应的特征值以及历史交互动作类型对应的特征值,组成第一交互特征。在一些实施例中,根据各个历史交互动作对应的历史交互资源以及历史交互资源对应的历史交互动作类型,得到第一交互特征包括;根据各个历史交互动作对应的历史交互资源确定资源特征值;根据历史交互资源对应的历史交互动作类型确定历史动作类型特征值;根据历史交互动作类型对交互收益值的影响确定第一收益影响特征值;根据资源特征值、历史动作类型特征值以及收益影响特征值得到第一交互特征。具体地,资源特征值是表示资源的特征值,例如如果存在该资源,则对应的特征值为第一预设值例如1,不存在则为第二预设值例如为0。历史动作类型特征值是指表示交互动作类型的特征值,例如,历史交互动作类型对应的特征值为第一预设值例如1,不是历史交互动作类型,则对应的特征值为第二预设值例如为0。历史交互动作类型对交互收益值的影响是根据交互式应用的收益确定规则确定的。收益是执行交互式任务所带来的,例如收益可以是获取得到欢乐豆或者是积分。例如,斗地主游戏中,“炸弹”会增加赢的倍数,假设该历史交互动作类型为炸弹,则对应的收益影响特征值是1。假设该历史交互动作类型不是炸弹,不会增加赢的倍数,则对应的收益影响特征值是0。可以将资源特征值、历史动作类型特征值以及收益影响特征值可以进行拼接,得到第一交互特征。通过引入收益影响特征值,可以使得动作选择模型对收益的获取更加敏感,可以使得动作选择模型选择的动作更加准确。在一些实施例中,可以根据历史动作类型对收益的影响程度确定收益影响特征值。例如,对于炸弹动作类型,假设该炸弹增加的赢的倍数是1倍,则收益影响特征值是1,假设该炸弹增加的赢的倍数是2倍,则收益影响特征值是2。步骤s404,根据目标虚拟对象当前持有的交互资源确定第二交互特征。具体地,可以获取目标对象当前持有的交互资源以及交互资源对应的交互动作类型,得到第二交互特征。例如,获取当前持有的交互资源对应的特征值以及对应的交互动作类型对应的特征值,组成第二交互特征。交互资源可以对应的交互动作类型是指当前交互资源可以组合得到的动作类型,对于斗地主游戏中,也可以称为牌型。当前持有的交互资源组合得到的交互动作类型可以有多个,则可以获取每一个交互动作类型对应的特征值,组合得到第二交互特征。例如,对于“三个2”,其对应的牌型可以是单牌、对子以及三带。在一些实施例中,还可以根据目标虚拟对象当前持有的交互资源组合得到的交互动作类型,对交互收益值的影响确定第二收益影响特征值。具体可以参照得到第一收益影响特征值的方式,在此不再赘述。步骤s406,将第一交互特征以及第二交互特征输入到动作选择模型中,得到各个候选交互动作对应的交互动作选择分数。具体地,动作选择模型可以是深度学习模型,动作选择模型可以是残差网络模型或者卷积网络模型。得到第一交互特征以及第二交互特征之后,可以将第一交互特征以及第二交互特征输入已训练得到的动作选择模型中,得到候选交互动作对应的交互动作选择分数。本申请实施例中,通过历史交互动作对应的信息得到第一交互特征,以及持有的交互资源得到第二交互特征,可以使得模型能够结合历史以及当前情况得到准确的动作选择分数。通过根据历史交互动作类型得到历史动作类型特征值,可以使得模型学习到执行动作类型的规律,提高了得到的动作选择分数的准确度。以斗地主为例,加入对动作类型例如15种牌型的表示可以使得动作选择模型对牌型分布更敏感,有利于捕捉到对手和队友的大致牌型分布,有助于在玩家主动出牌时选择一个合适的牌型进行出牌,因为主动出牌的时候牌型的选择对于出牌决策是非常重要的,如果从出牌记录中感知到对手常常使用对子,队友常常使用单牌,那么模型预测会倾向于单牌的选择。表1牌型示意表牌型符号例子单牌solo3,4,5,0,k顺子soloc34567,4567890j对子pair33,44,55连对pairc334455,77889900jj三张trio333,777飞机trioc333444,666777888三带单triok3334,888k飞机带单triock33344456,6667778889jk三带对triopk33344,888kk飞机带对triocpk3334445566,66677788899jjkk四带单bombk333344,88889k四带对bombpk33334455,888899kk炸弹bomb3333,8888,2222王炸rocketww过passpass例如,斗地主游戏中,如图5所示,为一些实施例中输入到动作选择模型的特征的示意图。可以使用15行以及20列来表示牌面信息,使用22层牌面信息来表示当前已出的牌、历史出牌记录、未知牌、当前手牌和当前玩家。15行的每一行分别对应15种卡牌:3、4、5、6、7、8、9、0、j、q、k、a、2、w、w,其中0表示10,w表示小王,w表示大王。20列中,分别对应卡牌数量(第1-4列)、是否是炸弹(第5列),15种牌型(第6-20列),其中15种牌型(交互动作类型)如表1所示,牌型表示可组合的所有牌型,在对应牌型位置进行标记。由于炸弹可压制非炸弹之外的任何牌型,因此可以进行特征标记使得模型更好利用此特征学习出牌规律。举个例子,假设当前玩家手牌(当前持有的牌)为“3、3、3、4、5、w、w”,且为主动出牌,那么使用一个15行20列二维矩阵的具体表示如表2,空白处表示0值。表2手牌二维矩阵表示0123456789101112131516171819203111111141151167890jqka2w111w1111其中第一列中的“3-w”表示牌从3到大王依次增加,列“0-3”表示每张卡牌的数量,列“4”表示该卡牌是否可以组成炸弹,列“6-20”表示该卡牌可组成的牌型分布。例如,行“3”的“11100101010100000000”表示大小为3的牌有3张,非炸弹,其中可以组成单牌、对子、,三带、三带单这些牌型。行“4”的“10000100000000000000”表示大小为4的牌有1张,非炸弹,可组成牌型为单牌。在形状为15x20x22三维数据结构中,其中第1、20以及22层可以使用表2进行表示,记录手牌可组成的牌型。而对于第2-19层的出牌记录,则可以只需记录实际玩家的出牌牌型即可。例如上一次出牌为33,那么只需要表示为3:11000001000000000000。即大小为3的牌有2张,牌型为对子。对于卡牌4~w处则全部为0。最后一层表示当前玩家,可以使用-1,0,1表示三个玩家,假设为地主则15行20列全部为0,假设为上家全部为-1,假设为下家全部为1,具体如表3所示。表3游戏玩家-下家数据表示111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111在一些实施例中,交互动作选择分数还可以是根据预设的规则策略得到的,根据当前交互状态确定各个候选交互动作对应的交互动作选择分数包括:获取目标虚拟对象当前持有的当前交互资源;根据预设的多个资源拆分策略对当前交互资源进行拆分,得到各个资源拆分策略对应的候选资源拆分集合;根据候选资源拆分策略对应的候选资源拆分集合中,各个交互动作类型对应的动作类型分数得到候选资源拆分集合对应的拆分集合评分;根据候选资源拆分集合对应的拆分集合评分筛选得到目标资源拆分集合;确定目标资源拆分集合对应的候选交互动作的交互动作选择分数。具体地,目标虚拟对象是指当前需要确定交互动作的虚拟对象。当前持有的当前交互资源根据实际情况确定,对于棋牌游戏,拆分是将当前持有的牌拆分为由一种或者多种牌型组合得到的集合,资源拆分集合是指拆分得到的集合。一个资源拆分集合中可以包括多个拆分得到的交互动作类型(牌型),例如假设持有的牌为“3、3、3、4、5、w、w”。则其中的一个资源拆分集合可以包括“3个3带一个4”、“单牌5”以及“王炸ww”三种交互动作类型,即三种牌型。资源拆分策略可以是预先设置的,例如,如图6所示,可以预设先按照两种基础顺序:1、火箭>顺子>炸弹>三带>对子>单牌。2、火箭>炸弹>三带>顺子>对子>单牌,分别将目标虚拟对象当前持有的资源最多拆分成四种手牌组合,再按照多顺子拆牌策略、多三张拆牌策略、多对子拆牌策略以及多炸弹拆牌策略重新拆分,得到每个策略分别对应的候选资源拆分集合。多顺子拆牌是指拆牌时倾向于得到更多的顺子。多三张拆牌策略是指拆牌时倾向于得到更多的三张。多对子拆牌策略是指拆牌时倾向于得到更多的对子。多炸弹拆牌策略是指拆牌时倾向于得到更多的炸弹。服务器中可以预先设置有每个交互动作类型对应的分数,具体可以根据需要设置,例如可以表4所示。将每个候选资源拆分集合中的交互动作类型的分数进行相加,得到该候选资源拆分集合的分数(拆分集合评分)。可以将拆分集合评分最高的候选资源拆分集合作为目标资源拆分集合。将目标资源拆分集合对应的动作作为候选交互动作,并获取候选交互动作对应的选择分数。其中候选交互动作对应的选择分数是根据出牌次数得到的,如图6所示,可以获取以各个候选交互动作为出牌动作时,所对应的最小出牌次数,所对应的出牌次数越小,则对应的交互动作选择分数越高,例如,可以设置出牌次数与分数的对应关系,当出牌次数为10时,则分数为0,当出牌次数为5时,则分数为60。表4牌型评分表牌型分数单牌1对子2三带3单顺4连对5飞机6炸弹7火箭8在一些实施例中,根据目标博弈树从多个模拟交互动作中确定目标交互动作包括:确实目标虚拟对象对应的目标角色,根据目标博弈树的叶子节点对应的交互状态以及目标角色,确定叶子节点对应的交互激励分数;根据叶子节点对应的交互激励分数从叶子节点开始进行回溯,得到目标博弈树的根节点对应的交互激励分数;将根节点对应的交互激励分数所对应的模拟交互动作,作为目标交互动作。目标虚拟对象对应的目标角色可以是“地主”或者农民,角色也可以称为阵营。叶子节点是指目标博弈树中没有子节点的节点。叶子节点对应的交互激励分数是从目标角色对应的角度计算的。例如,当目标角色是地主时,则计算的是地主对应的收益。当目标角色是农民时,则计算的是农民对应的整体收益,例如,当有两个农民时,则计算两个农民的整体收益。当叶子节点是交互式任务的最终节点,叶子节点对应的交互状态可以是输或者赢。例如最终确定游戏的输赢的节点,则激励分数可以根据交互式任务的最终结果确定。例如如果目标角色赢了,则激励分数可以是第一分数,当目标角色输了,则激励分数可以是第二分数,第一分数大于第二分数,例如第一分数为正的,第二分数为负的。回溯时,目标角色与目标博弈树的母节点对应的角色一致时,获取母节点的子节点对应的最大交互激励分数,作为母节点对应的交互激励分数,当目标角色与目标博弈树的母节点对应的角色不一致时,获取母节点的子节点对应的最小交互激励分数,作为母节点对应的交互激励分数。即母节点的交互激励分数是根据其对应的子节点的交互激励分数确定的。如果母节点对应的角色与目标角色一致,例如皆为农民,母节点下有三个子节点,则取三个子节点对应的交互激励分数中,最大的交互激励分数作为母节点的交互激励分数。如果母节点对应的角色与目标角色不一致,例如一个为农民,一个为地主,母节点下有三个子节点,则取三个子节点对应的交互激励分数中,最小的交互激励分数作为母节点的交互激励分数。通过不断的进行回溯,可以得到根节点对应的交互激励分数,获取得到该根节点对应的交互激励分数所对应的模拟交互动作,作为目标交互动作。本申请实施例中,当目标角色与目标博弈树的母节点对应的角色不一致时,获取母节点的子节点对应的最小交互激励分数,作为母节点对应的交互激励分数。相当于假设对手(另一角色)每一步都会将我方引入从当前看理论上价值最小的格局方向,即对手具有完美决策能力。因此我方的策略应该是选择那些对方所能达到的让我方最差情况中最好的,也就是让对方在完美决策下所对我造成的损失最小。而通过当目标角色与目标博弈树的母节点对应的角色一致时,获取母节点的子节点对应的最大交互激励分数,作为母节点对应的交互激励分数,能够使得在我方决策时要让决策使我方获得的收益越大。故能够得到收益好的目标交互动作。本申请实施例中,通过计算角色对应的激励,即从整体上计算得到交互式任务中,各个角色对应的整体收益,能够更好的反映交互式任务真正的结果,提高了选择目标交互动作的准确度。以斗地主游戏为例,斗地主游戏中,存在着合作和竞争的关系,假设斗地主中有两个农民和一个地主,且按照位置进行出牌,因此可以构造3个智能体(游戏ai)来确定博弈树,即上家对应的游戏ai、下家对应的游戏ai以及地主对应的游戏ai,每个游戏ai负责确定其所对应的虚拟对象的出牌动作。因此农民方这一角色在博弈过程中选择有利于两个农民共同利益的行为,而非只是有利于自己,甚至农民方有时可以损失自己的利益而最大化共同利益,例如上家会顶地主的牌,可以帮助下家过小牌而逼迫地主出大牌,从而使得地主的牌力越来越弱,下家的牌力越来越强。因此通过本申请实施例确定交互激励分数的步骤,可以到农民合作对抗地主的效果。如图7所示,为根节点对应的目标虚拟对象为地主的目标博弈树的示意图。表示当前要确定目标交互动作的虚拟对象为地主。则在计算叶子节点的交互激励分数时,计算的可以是地主对应的收益。如果博弈树中的节点是下家或上家,那么回溯时,该节点会选择地主奖励最小的行为。例如图7中对于包括交互激励分数为“-150”以及“50”的母节点,由于母节点是上家,为农民角色,与地主角色不一致,故该对应的交互激励分数是“-150”。这样,经过不断回溯,计算得到执行模拟交互动作a1对应的交互激励分数为50、执行模拟交互动作a2对应的交互激励分数为-150,执行模拟交互动作a3对应的交互激励分数为-1000,故可以将模拟交互动作a1作为目标交互动作,“下家执行min”是指下家执行的是使激励分数最小的动作,“地主执行max”是指地主执行的是使激励分数最大的动作。如图8所示,为根节点对应的目标虚拟对象为下家的目标博弈树的示意图。表示当前要确定目标交互动作的虚拟对象为下家。在模拟对战中,每个节点采取不同的出牌动作都会计算农民方整体奖励,如果该母节点是下家或上家,那么会采取是最大化农民方整体奖励的行为,如果是地主则会选择最小化农民方整体奖励的行为。参考上述确定根节点对应的交互激励分数的方法,可以得到执行的是目标交互动作为模拟交互动作a2或者模拟交互动作a3。当a2以及a3的分数一致时,可以选取a2或者a3的任意的一个作为目标交互动作。如图9所示,为根节点对应的目标虚拟对象为上家的目标博弈树的示意图。表示当前要确定目标交互动作的虚拟对象为上家。在模拟对战中,地主对应的节点最小化农民方奖励,农民对应的节点最大化农民方共同奖励。参考上述确定根节点对应的交互激励分数的方法,可以得到执行的是目标交互动作为模拟交互动作a2或者模拟交互动作a1。在一些实施例中,叶子节点对应的交互激励分数还可以根据从根节点到叶子节点所执行的模拟交互动作或者模拟的深度的至少一个确定。其中,模拟的深度与交互激励分数成负相关关系。可以根据模拟交互动作对应的角色配合度以及对收益的影响度确定交互激励分数。配合度与交互激励分数成正相关关系,收益的影响度与交互激励分数根据输赢结果确定。例如,假设农民有使用炸弹炸队友,导致模拟对战农民方输,说明配合度差,则可以减少交互激励分数。如果使用了炸弹,炸弹会导致输赢翻倍,如果对战结果为赢,则使用炸弹的次数越多,交互激励分数越高。如果对战结果为输,则使用炸弹的次数越多,交互激励分数越低。在计算最终的交互激励分数时,可以根据各个交互激励分数以及对应的权重进行加权求和得到。例如,可以将权重划分为4个等级,分别用极高、高、中、低表示,具体的权重值可以根据需要设置,影响因素对应的分数可以根据需要设置。·游戏输赢(极高):农民任一方赢都为赢,输赢作为第一目标。·是否炸队友(高):农民有没有使用炸弹炸队友,导致模拟对战农民方输,在不确定稳赢的阶段应该尽量不使用炸弹。·炸弹数量(高):炸弹会导致输赢翻倍,所以需要特别注意模拟对战中可能产生的炸弹数量,赢时越多越好,输时越少越好。·是否是春天(高):春天是可以输赢翻倍的,所以可以等同于炸弹的效果·是否主动出炸弹(高):如果不是特殊情况的赢法,应尽量减少这种情况·是否压制敌方出牌(中):农民方有没有在可以压牌的情况下没有压牌,放过了地主出牌,或者地主放过了农民出牌。·是否压制队友出牌(中):农民方有没有在没必要的情况下压制队友,从而给敌方造成更多优势。·模拟对战轮次(低):从当前游戏状态到游戏结束或到达指定深度所经历的出牌轮次,应该是出牌越少越好。如图10所示,为一些实施例中采用其他剪枝算法剪枝得到的博弈树的示意图,a、b以及c表示模拟交互动作。图11为一些实施例中通过本申请实施例提供的基于alpha-beta算法以及基于动作选择模型进行剪枝得到的博弈树的示意图。框中的数字表示交互激励分数,从图10以及图11可以看出,通过普通剪枝算法得到的博弈树需要搜索18个叶子节点,而通过alpha-beta算法以及基于动作选择模型进行剪枝后,只需要搜索9个叶子节点便可以获得最优路径,且利用alpha-beta算法剪枝后并不会影响最优解。在博弈树剪枝中,对于出牌动作即宽度方向的剪枝可以使用深度学习模型,也可以使用规则策略进行剪枝。其中深度学习模型可以使用cnn模型,resnet残差网络或resnet+cbam(convolutionalblockattentionmoduleconvolutionalblockattentionmodule)的网络结构。cnn模型对应的结构可以如图12所示,包含3-5个卷积模块(block),每个卷积block包括2个卷积层(con),大小为3*3,维度为64、2个归一化层(batchnorm)以及一个激活层(relu),按照图示顺序进行堆叠。最后通过一个平均池化层(avgpool)和全连接层(fc),再进行softmax预测出每个出牌动作的概率,计算出牌动作的概公式如公式(1)所示,s(i)表示第i个候选交互动作对应的概率,ei表示动作选择模型输出的概率,n为候选交互动作的数量。其中卷积层的卷积核大小可以为3x3的大小窗口,具有64个过滤器以及步长为1。图13为resnet34层的残差网络模型,图14是resnet+cbam模块的残差网络模型。残差网络的一个区别于普通cnn的特点在于,每个卷积block的输出会加上卷积block的输入传输到下一个卷积block,公式如公式(2)所示。这样在深度模型训练中可以有效的避免梯度消失,加快模型收敛速度。其中在resnet中每个卷积block中卷积层之间加上基于通道的注意力权重和空间注意力注意力模块,可以有效地使得模型聚焦于每一层重要信息,获得更好的特征表示。y=f(x)+x(2)其中cbam注意力模块的具体结构如图15以及16所示,其中基于通道的注意力权重(channelattentionmc)使用共享的多层感知机(sharedmlp)计算注意力向量,而空间注意力(spatialattentionms)使用7x7的卷积层计算注意向量,mc和ms的计算公式如公式(3)以及(4)所示,“σ”表示激活函数。“avgpool”表示平均池化,“maxpool”表示最大池化。conv7x7表示利用7*7卷积核进行卷积,f表示输入的特征(inputfeature)。mcf=σ(mlp(avgpool(f))+mlp(maxpool(f)))(3)msf=σ(conv7x7([avgpool(f));mlp(maxpool(f)])(4)以上三种模型训练样可以使用100万局400万有效样本数据,由于在实际样本中单牌,对子的样本对比例远高于其他的牌型,若不做均衡处理则导致机器人很少会出顺子、连对以及飞机等牌型。因此样本选择时进行了样本的均衡处理。模型的损失函数采用的是对数交叉熵,公式如公式(5)所示,其中yi为类别的one-hot表示,xi为全连接层输入的特征值,w为全连接层的模型参数。当然也可以使用hingeloss等损失函数,或者加入l2loss等正则化损失项。模型训练的优化器对比了adam,adadelta,sgdm三种优化器,以resnet为基础的模型为例,其中sdgm表现最优。初期adam和adadelta训练速度快于sgdm,不过达到70%左右准确率之后便无法继续优化,而sgdm虽然慢于其他两种优化器,却可以到达约80%的准确率,而加上cbam注意力模块可以可以达到82%左右的准确率,其中普通cnn模型的准确率可以达到74.5%。以下是三种模型对比。其中三种模型的top3(前3)基本都可以达到97%,top5可以达到99%。因此可以利用模型预测top3-top5的模拟交互动作作为博弈树的宽度剪枝的原因。利用博弈树的搜索来弥补top120%+左右的误差率,可以极大的提升机器人的智能程度。其中从cnn,resnet到resnet+cbam模型,模型参数量逐渐增大,训练时间也逐渐增长。在1080p的gpu,cpu4核16g的机器上,其中cnn的训练时间大约为12小时,resnet为72小时,resnet+cbam为96小时。应该理解的是,虽然上述流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,上述流程图中的至少一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。在一个实施例中,如图17所示,提供了一种交互控制装置,包括以下模块:实际交互状态获取模块1702,用于获取交互式任务当前的实际交互状态;交互动作选择分数确定模块1704,用于根据当前交互状态确定各个候选交互动作对应的交互动作选择分数,其中,初始的当前交互状态为实际交互状态;模拟交互动作筛选模块1706,用于根据各个候选交互动作对应的交互动作选择分数筛选得到模拟交互动作;模拟交互状态得到模块1708,用于模拟执行各个模拟交互动作,得到模拟交互状态;返回模块1710,用于将模拟交互状态作为当前交互状态,返回根据当前交互状态确定各个候选交互动作对应的交互动作选择分数的步骤,直至完成交互式任务或者模拟深度达到深度阈值,得到目标博弈树,目标博弈树包括各个当前交互状态对应的状态节点,在母状态节点对应的交互状态下执行模拟交互动作,得到子状态节点对应的交互状态;目标交互动作确定模块1712,用于根据目标博弈树从模拟交互动作中确定目标交互动作,控制目标虚拟对象执行目标交互动作。在一些实施例中,模拟交互动作筛选模块用于:将各个候选交互动作对应的交互动作选择分数按照从大到小的顺序进行排序,将排序在第一排序之前的交互动作选择分数对应的候选交互动作作为模拟交互动作。在一些实施例中,交互动作选择分数确定模块包括:第一交互特征得到单元,用于根据各个历史交互动作对应的历史交互资源以及历史交互资源对应的历史交互动作类型,得到第一交互特征;第二交互特征得到单元,用于根据目标虚拟对象当前持有的交互资源确定第二交互特征;交互动作选择分数确定单元,用于将第一交互特征以及第二交互特征输入到动作选择模型中,得到各个候选交互动作对应的交互动作选择分数。在一些实施例中,第一交互特征得到单元用于:根据各个历史交互动作对应的历史交互资源确定资源特征值;根据历史交互资源对应的历史交互动作类型确定历史动作类型特征值;根据历史交互动作类型对交互收益值的影响确定第一收益影响特征值;根据资源特征值、历史动作类型特征值以及收益影响特征值得到第一交互特征。在一些实施例中,交互动作选择分数确定模块用于:获取目标虚拟对象当前持有的当前交互资源;根据预设的多个资源拆分策略对当前交互资源进行拆分,得到各个资源拆分策略对应的候选资源拆分集合;根据候选资源拆分策略对应的候选资源拆分集合中,各个交互动作类型对应的动作类型分数得到候选资源拆分集合对应的拆分集合评分;根据候选资源拆分集合对应的拆分集合评分筛选得到目标资源拆分集合;确定目标资源拆分集合对应的候选交互动作的交互动作选择分数。在一些实施例中,目标交互动作确定模块用于:确实目标虚拟对象对应的目标角色,根据目标博弈树的叶子节点对应的交互状态以及目标角色,确定叶子节点对应的交互激励分数;根据叶子节点对应的交互激励分数从叶子节点开始进行回溯,得到目标博弈树的根节点对应的交互激励分数;其中,当目标角色与目标博弈树的母节点对应的角色一致时,获取母节点的子节点对应的最大交互激励分数,作为母节点对应的交互激励分数;当目标角色与目标博弈树的母节点对应的角色不一致时,获取母节点的子节点对应的最小交互激励分数,作为母节点对应的交互激励分数;将根节点对应的交互激励分数所对应的模拟交互动作,作为目标交互动作。关于交互控制装置的具体限定可以参见上文中对于交互控制方法的限定,在此不再赘述。上述交互控制装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。在一个实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图18所示。该计算机设备包括通过系统总线连接的处理器、存储器和网络接口。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于存储交互控制数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种交互控制方法。本领域技术人员可以理解,图18中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。在一个实施例中,提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现上述交互控制方法的步骤。在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述交互控制方法的步骤。本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。非易失性存储器可包括只读存储器(read-onlymemory,rom)、磁带、软盘、闪存或光存储器等。易失性存储器可包括随机存取存储器(randomaccessmemory,ram)或外部高速缓冲存储器。作为说明而非局限,ram可以是多种形式,比如静态随机存取存储器(staticrandomaccessmemory,sram)或动态随机存取存储器(dynamicrandomaccessmemory,dram)等。以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips