
 商标分类
商标分类  商标转让
商标转让 
一种异构数据不依赖型蛋白质组学质谱分析系统及方法与流程
 2021-01-08 11:01:24|
2021-01-08 11:01:24| 316|
316| 起点商标网
起点商标网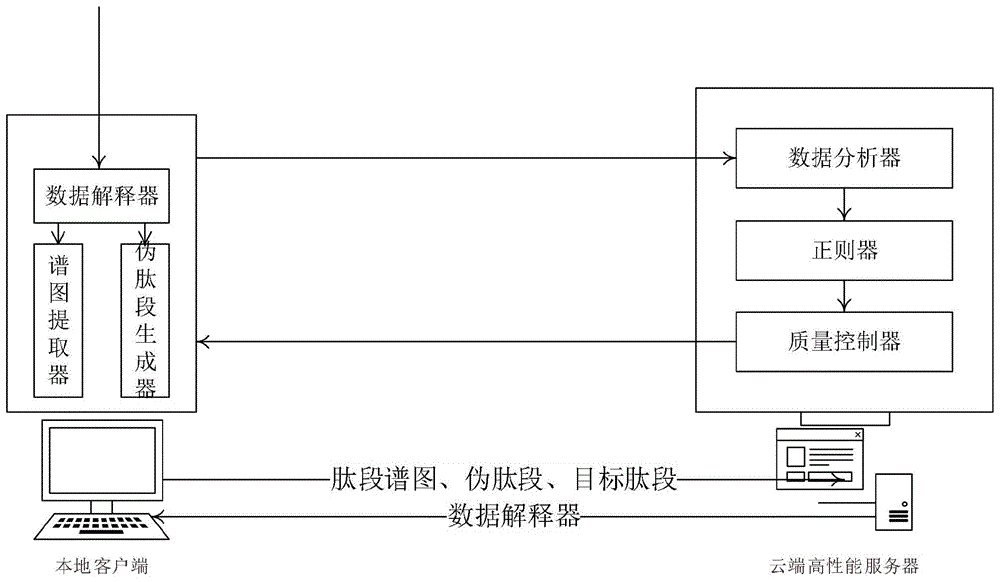
本发明属于蛋白质组学领域,更具体地,涉及一种异构库文件数据不依赖型蛋白质组学质谱分析系统及方法。
背景技术:
传统的蛋白质组学采用数据依赖采集(dda)策略,将蛋白质样品消化成肽段,离子化并通过质谱进行分析。在全扫描质谱图中,高于噪音的肽段信号被选择性裂解,产生随机(ms/ms)质谱,能够与数据库中的图谱相匹配。尽管这种方法非常强大,但它随机抽取肽段进行裂解,总是偏向于那些信号最强的峰。因此,低丰度肽段的定量仍是挑战。
此后发展出了定向分析技术——选择反应监测(srm)中,质谱仪能非常灵敏地检测到特定肽段,具有高的定量准确性。
蛋白质组研究界如今将目光集中在数据不依赖采集(dia)上,它在理论上综合了dda和srm的优势。在dia分析中,指定质荷比(m/z)窗口内的所有肽段都经过裂解;分析重复,直至质谱仪覆盖整个m/z范围。这实现了准确的肽段定量,而不限于分析预先定义的肽段。
数据不依赖型蛋白质组学质谱数据的分析,由于数据量极大因此必须依靠生物信息学算法进行回归拟合,然而随着检测手段的不断提升,数据不依赖型蛋白质组学质谱数据的形式和格式也在不断更新。旧有的分析系统无法做到可扩的兼容各种数据不依赖型蛋白质组学质谱数据的分析。同时,云端集中式的分析系统,会导致检测原始数据的泄露,不利于商业化推广,因此需要开发新一代数据不依赖型蛋白质组学质谱分析系统。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种异构数据不依赖型蛋白质组学质谱分析系统及方法,其目的在于通过本地服务和云服务的结合,实现可扩展的兼容复杂的数据不依赖型蛋白质组学质谱数据格式,同时在保证数据隐私安全性的前提下,缩短数据分析时间、降低本地对运算能力的要求,由此解决现有技术的分析软件不能可扩展的兼容不断更新的数据格式、对本地计算力要求高、分析时间长、有数据隐私泄露风险,不利于商业推广的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种异构数据不依赖型蛋白质组学质谱分析系统,包括本地客户端和云端高性能服务器;
所述本地客户端,用于获取数据不依赖型原始数据和目标检测数据,并分别根据从云端高性能服务器调取数据解释器,将所述数据不依赖型原始数据解释为标准格式的数据不依赖型蛋白质组学质谱数据,将所述目标检测数据解释为标准格式的库文件,并根据所述标准格式的数据不依赖型蛋白质组学质谱数据和标准格式的库文件生成肽段谱图数据、伪肽段以及目标检测肽段,提交给高性能服务器端;
所述云端高性能服务器,用于根据所述本地客户端提供的肽段谱图数据、伪肽段、以及目标检测肽段进行数据分析,对数据分析结果进行保留时间正则化,以及回归计算,获得目标检测肽段的子离子系列强度以及假阳性率作为蛋白质组学分析结果,返回给所述本地客户端。
优选地,所述异构数据不依赖型蛋白质组学质谱分析系统,其所述本地客户端还用于从云端高性能服务器获得蛋白质组学分析结果并展示。
优选地,所述异构数据不依赖型蛋白质组学质谱分析系统,其所述本地客户端包括:数据解释器、谱图提取器和伪肽段生成器;
所述数据解释器,从高性能服务器调取,用于读取所述数据不依赖型原始数据和目标检测数据,并识别当前所支持类型的数据不依赖型原始数据和目标检测数据并分别转换为标准格式的数据不依赖型蛋白质组学质谱数据和标准格式的库文件,将所述标准格式的数据不依赖型蛋白质组学质谱数据和标准格式的库文件提交给谱图提取器,将所述标准格式的库文件提交给伪肽段生成器;
所述谱图提取器,用于根据标准格式的库文件对所述标准格式的数据不依赖型蛋白质组学质谱数据进行合并处理,获得肽段谱图数据,提交给云端高性能服务器;
所述伪肽段生成器,用于对所述标准格式的库文件进行生成运算,获得伪肽段,将伪肽段和目标检测肽段提交给云端高性能服务器。
优选地,所述异构数据不依赖型蛋白质组学质谱分析系统,其所述卷积合并优选tophat卷积运算或bartlett卷积运算。
优选地,所述异构数据不依赖型蛋白质组学质谱分析系统,其所述生成运算维持肽段成分不变且改变氨基酸顺序的运算。
优选地,所述异构数据不依赖型蛋白质组学质谱分析系统,其所述云端高性能服务器,包括数据分析器、正则器、和质量控制器;
所述数据分析器,用于根据肽段谱图数据、伪肽段、以及目标检测肽段数据,进行基于色谱、质谱、和/或离子淌度的打分,并根据打分结果预测目标检测肽段和伪肽段的信号值,提供给正则器;
所述正则器,用于根据目标检测肽段和伪肽段的信号值进行保留时间正则化、以及回归算法,获得目标检测肽段和伪肽段的子离子系列强度,提交给质量控制器;
所述质量控制器,用于根据目标检测肽段和伪肽段的子离子系列强度,提取目标检测肽段的子离子系列强度并计算肽段假阳性率,返回本地客户端。
按照本发明的另一种方法,提供了一种异构数据不依赖型蛋白质组学质谱分析方法,其特征在于,应用本发明提供的异构数据不依赖型蛋白质组学质谱分析系统。
优选地,所述异构数据不依赖型蛋白质组学质谱分析方法,其包括以下步骤:
(1)本地客户端读取本地异构数据不依赖型蛋白质组学质谱数据,调用云端高性能服务器,获取数据解释器;
(2)本地客户端在本地完成数据解释及谱图提取、伪肽段生成后,将肽段谱图数据、伪肽段以及目标检测肽段,提交给高性能服务器端;
(3)所述高性能服务器,根据所述本地客户端提供的肽段谱图数据、伪肽段、以及目标检测肽段进行数据分析,对数据分析结果进行保留时间正则化、以及回归计算,获得目标检测肽段的子离子系列强度以及假阳性率作为蛋白质组学分析结果,返回给所述本地客户端。
优选地,所述异构数据不依赖型蛋白质组学质谱分析方法,其当处理高通量数据集时,所述步骤(1-2)和步骤(3)分布式或集成式进行。
优选地,所述异构数据不依赖型蛋白质组学质谱分析方法,其所述分布式进行,即:所述高性能服务器进行当前数据不依赖型蛋白质组学质谱数据数据分析时,本地客户端同时处理下一批数据不依赖型蛋白质组学质谱数据;
所述集成式进行,即:具有多个高性能服务器、以及一个或多个本地客户端,对于多个高性能服务器进行任务调度,实现总的处理时间最短或特定数据不依赖型蛋白质组学质谱数据的处理时间最短。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
本发明提供的方法及系统,采用本地客户端和云端高性能服务器,分别进行异构数据不依赖型蛋白质组学质谱数据的本地预处理和云端的分析,能兼顾原始数据不依赖型蛋白质组学质谱数据的私密性和强大的运算能力,避免全分析过程本地化带来的巨大时间成本以及计算性能需求,或者是全由云端高性能服务器完成,带来原始检测数据泄露风险和巨大数据传输带宽需求。
同时本发明由云端不断更新对数据不依赖型蛋白质组学数据和库文件的支持,从而可扩展的适配不同格式、不同检测手段获得的数据不依赖型蛋白质组学数据。
本发明提供的方法的优选方案,利用本地客户端和云端高性能服务器的计算能力,进行分布式或集成式任务调度,进一步压缩计算时间,特别适合高通量运算,理想状态下高通量数据的处理速度提高近一倍。
附图说明
图1是本发明提供的异构数据不依赖型蛋白质组学质谱分析系统结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明提供的异构数据不依赖型蛋白质组学质谱分析系统,如图1所示,包括本地客户端和云端高性能服务器;
所述本地客户端,用于获取数据不依赖型原始数据和目标检测数据,并分别根据从云端高性能服务器调取数据解释器,将所述数据不依赖型原始数据解释为标准格式的数据不依赖型蛋白质组学质谱数据,将所述目标检测数据解释为标准格式的库文件,并根据所述标准格式的数据不依赖型蛋白质组学质谱数据和标准格式的库文件生成肽段谱图数据、伪肽段以及目标检测肽段,提交给高性能服务器端;还用于从云端高性能服务器获得蛋白质组学分析结果并展示;
所述本地客户端包括:数据解释器、谱图提取器和伪肽段生成器;
所述数据解释器,从高性能服务器调取,用于读取所述数据不依赖型原始数据和目标检测数据,并识别当前所支持类型的数据不依赖型原始数据和目标检测数据并分别转换为标准格式的数据不依赖型蛋白质组学质谱数据和标准格式的库文件,将所述标准格式的数据不依赖型蛋白质组学质谱数据和标准格式的库文件提交给谱图提取器,将所述标准格式的库文件提交给伪肽段生成器;
所述谱图提取器,用于根据标准格式的库文件对所述标准格式的数据不依赖型蛋白质组学质谱数据进行合并处理,获得肽段谱图数据,提交给云端高性能服务器;所述合并处理包括循环扫描、卷积合并、降噪;所述卷积合并优选tophat卷积运算或bartlett卷积运算。
所述伪肽段生成器,用于对所述标准格式的库文件进行生成运算,获得伪肽段,将伪肽段和目标检测肽段提交给云端高性能服务器;所述生成运算包括:随机打乱、倒置、伪倒置、以及平移等,维持肽段成分不变且改变氨基酸顺序的运算。
所述云端高性能服务器,用于根据所述本地客户端提供的肽段谱图数据、伪肽段、以及目标检测肽段进行数据分析,对数据分析结果进行保留时间正则化,以及回归计算,获得目标检测肽段的子离子系列强度以及假阳性率作为蛋白质组学分析结果,返回给所述本地客户端;还包括用于存储和更新数据解释器的更新模块,所述更新模块根据当前数据不依赖型蛋白质组学质谱数据的类型不断更新数据解释器。
所述云端高性能服务器,包括数据分析器、正则器、和质量控制器;
所述数据分析器,用于根据肽段谱图数据、伪肽段、以及目标检测肽段数据,进行基于色谱、质谱、和/或离子淌度的打分,并根据打分结果预测目标检测肽段和伪肽段的信号值,提供给正则器;
所述正则器,用于根据目标检测肽段和伪肽段的信号值进行保留时间正则化、以及回归算法,获得目标检测肽段和伪肽段的子离子系列强度,提交给质量控制器。
所述质量控制器,用于根据目标检测肽段和伪肽段的子离子系列强度,提取目标检测肽段的子离子系列强度并计算肽段假阳性率,返回本地客户端。
应用本发明提供的异构数据不依赖型蛋白质组学质谱分析系统进行异构数据不依赖型蛋白质组学质谱分析的方法,包括以下步骤:
(1)本地客户端读取本地异构数据不依赖型蛋白质组学质谱数据,调用云端高性能服务器,获取数据解释器;
(2)本地客户端在本地完成数据解释及谱图提取、伪肽段生成后,将肽段谱图数据、伪肽段以及目标检测肽段,提交给高性能服务器端;
(3)所述高性能服务器,根据所述本地客户端提供的肽段谱图数据、伪肽段、以及目标检测肽段进行数据分析,对数据分析结果进行保留时间正则化、以及回归计算,获得目标检测肽段的子离子系列强度以及假阳性率作为蛋白质组学分析结果,返回给所述本地客户端。
当处理高通量数据集时,所述步骤(1-2)和步骤(3)分布式或集成式进行;
所述分布式进行,即:所述高性能服务器进行当前数据不依赖型蛋白质组学质谱数据数据分析时,本地客户端同时处理下一批数据不依赖型蛋白质组学质谱数据;
所述集成式进行,即:具有多个高性能服务器、以及一个或多个本地客户端,对于多个高性能服务器进行任务调度,实现总的处理时间最短或特定数据不依赖型蛋白质组学质谱数据的处理时间最短。
以下为实施例:
本发明提供的异构数据不依赖型蛋白质组学质谱分析系统,如图1所示,包括本地客户端和云端高性能服务器;
所述本地客户端,用于获取数据不依赖型原始数据和目标检测数据,并分别根据从云端高性能服务器调取数据解释器,将所述数据不依赖型原始数据解释为标准格式的数据不依赖型蛋白质组学质谱数据,将所述目标检测数据解释为标准格式的库文件,并根据所述标准格式的数据不依赖型蛋白质组学质谱数据和标准格式的库文件生成肽段谱图数据、伪肽段以及目标检测肽段,提交给高性能服务器端;还用于从云端高性能服务器获得蛋白质组学分析结果并展示;
所述本地客户端包括:数据解释器、谱图提取器和伪肽段生成器;
所述数据解释器,从高性能服务器调取,用于读取所述数据不依赖型原始数据和目标检测数据,并识别当前所支持类型的数据不依赖型原始数据和目标检测数据并分别转换为标准格式的数据不依赖型蛋白质组学质谱数据和标准格式的库文件,将所述标准格式的数据不依赖型蛋白质组学质谱数据和标准格式的库文件提交给谱图提取器,将所述标准格式的库文件提交给伪肽段生成器;
当前数据解释器支持的数据不依赖型原始数据格式为:raw、wiff、.d;当前数据解释器支持的库文件格式为:sptxt、blib、以及csv。标准格式的数据不依赖型蛋白质组学质谱数据为:mzml;标准格式的库文件格式为traml。
所述谱图提取器,类似于openswath(openswathenablesautomated,targetedanalysisofdata-independentacquisitionmsdata.naturebiotechnology,2014/3/10)的chromatogramextractor用于对所述标准格式的数据不依赖型蛋白质组学质谱数据进行合并处理,获得肽段谱图数据,提交给云端高性能服务器;所述合并处理包括循环扫描、卷积合并、降噪;所述卷积合并优选tophat卷积运算或bartlett卷积运算。
所述伪肽段生成器,类似于openswath的decoygenerator,用于对所述标准格式的库文件进行生成运算,获得伪肽段,将伪肽段和目标检测肽段提交给云端高性能服务器;所述生成运算包括:随机打乱、倒置、伪倒置、以及平移等,其维持肽段成分不变而改变氨基酸顺序的运算。
所述云端高性能服务器,用于根据所述本地客户端提供的肽段谱图数据、伪肽段、以及目标检测肽段进行数据分析,对数据分析结果进行保留时间正则化,以及回归计算,获得目标检测肽段的子离子系列强度以及假阳性率作为蛋白质组学分析结果,返回给所述本地客户端;还包括用于存储和更新数据解释器的更新模块,所述更新模块根据当前数据不依赖型蛋白质组学质谱数据的类型不断更新数据解释器。
所述云端高性能服务器,包括数据分析器、正则器、和质量控制器;
所述数据分析器,类似于openswath的analyzer,用于根据肽段谱图数据、伪肽段、以及目标检测肽段数据,进行基于色谱、质谱、和/或离子淌度的打分,并根据打分结果预测目标检测肽段和伪肽段的信号值,提供给正则器;
所述基于色谱打分项目包括:交叉验证(cross-correlationscore)、强度(intensityscore)、信噪比(signal-to-noisescore)、emg(exponentiallymodifiedgaussianscore,指数修正高斯)、相对强度(relativeintensityscore)、以及保留时间(retentiontimescore);所述基于质谱的打分项目包括:同位素(isotopescore)、质谱质量精度(massaccuracyscore)、以及子离子系列(ionseriesscore);所述基于离子淌度的打分项目包括:离子淌度(ionmobility)。
所述正则器,类似于openswath的rtnormalizer用于根据目标检测肽段和伪肽段的信号值进行保留时间正则化、以及lda线性回归算法,获得目标检测肽段以及伪肽段的子离子系列强度,提交给质量控制器;
所述质量控制器,用于根据目标检测肽段以及伪肽段的子离子系列强度,提取目标检测肽段的子离子系列强度并计算肽段假阳性率,返回本地客户端。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



