
 商标分类
商标分类  商标转让
商标转让 
一种基于AdaBoost模型的水质特征矿泉水分类方法与流程
 2021-01-08 11:01:37|
2021-01-08 11:01:37| 303|
303| 起点商标网
起点商标网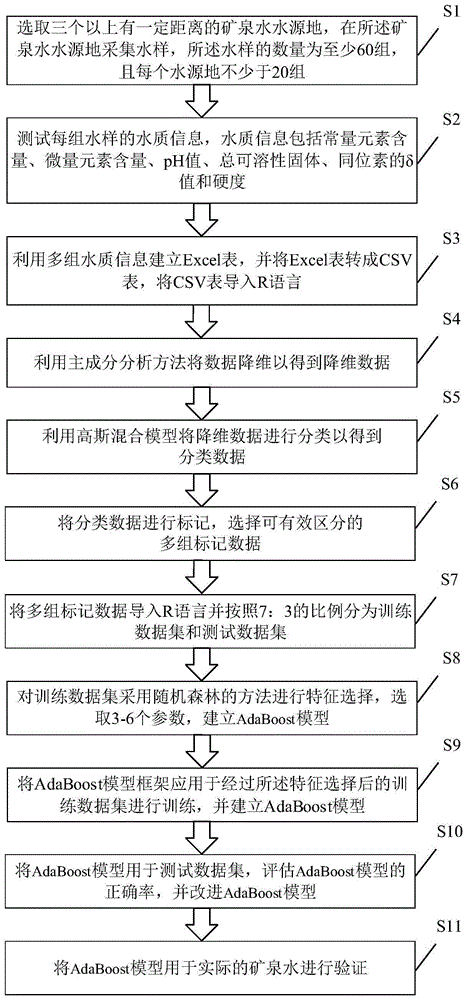
本发明涉及矿泉水分类技术领域,尤其是涉及一种基于adaboost模型的水质特征矿泉水分类方法。
背景技术:
矿泉水是一种宝贵的水资源,由于对人体有益,适合长期饮用,因而具有较大的资源保护价值与经济价值。矿泉水中的溶解物以无机质为主,其中常量元素包括k+、na+、ca2+、mg2+、cl-、so42-、hco3-等,重要的微量元素有se、sr、li、zn等。这些成分一方面代表了水质的不同,另外一方面也代表了其形成条件与形成过程的不同,与其所在地下含水层地质条件有关。
近五年全球矿泉水的销量以年均6.4%的速度增加。我国政府颁布了国家标准《饮用天然矿泉水》(gb8537—2018),对矿泉水的水质做出了一些规定。从目前的研究与较普遍接受的观点来看,矿泉水大致可分为偏硅酸矿泉水、锶矿泉水、锌矿泉水、锂矿泉水、硒矿泉水、溴矿泉水、碘矿泉水、碳酸矿泉水等。上述分类方法仅考察了矿泉水的某一方面的特性,考察并不全面,分类不够合理。
技术实现要素:
本发明提出了一种基于adaboost模型的水质特征矿泉水分类方法,利用所述基于adaboost模型的水质特征矿泉水分类方法可以提升矿泉水分类的合理性和科学性。
根据本发明实施例的基于adaboost模型的水质特征矿泉水分类方法,包括:步骤s1:选取三个以上有一定距离的矿泉水水源地,在所述矿泉水水源地采集水样,所述水样的数量为至少60组,且每个水源地不少于20组;步骤s2:测试每组所述水样的水质信息,所述水质信息包括常量元素含量、微量元素含量、ph值、总可溶性固体、同位素的δ值和硬度;步骤s3:利用多组所述水质信息建立excel表,并将所述excel表转成csv表,将所述csv表导入r语言;步骤s4:利用主成分分析方法将数据降维以得到降维数据;步骤s5:利用高斯混合模型将所述降维数据进行分类以得到分类数据;步骤s6:将所述分类数据进行标记,选择可有效区分的多组标记数据;步骤s7:将多组所述标记数据导入r语言并按照7:3的比例分为训练数据集和测试数据集;步骤s8:对所述训练数据集采用随机森林的方法进行特征选择,选取3-6个参数;步骤s9:将adaboost模型框架应用于经过所述特征选择后的训练数据集进行训练,并建立adaboost模型;步骤s10:将所述adaboost模型用于所述测试数据集,评估所述adaboost模型的正确率,并改进所述adaboost模型。
根据本发明实施例的基于adaboost模型的水质特征矿泉水分类方法,考虑到每个判别参量的重要性有所差别,使用主成分分析方法和高斯混合模型对数据进行特征选择,也就说可以在样本的角度选择更加具有代表性的数据,然后利用r语言并选取的数据按照7:3的比例分为训练数据集和测试数据集,使用训练数据集建立adaboost模型后,将adaboost模型用于所述测试数据集,评估所述adaboost模型的正确率,并改进adaboost模型,从而可以提升adaboost模型的准确性,进而提升矿泉水分类的合理性和科学性。
根据本发明的一些实施例,在所述步骤s2之后,且在所述步骤s3之前,所述方法还包括:将所述常量元素含量换算成当量浓度百分数,将所述微量元素含量换算成当量浓度。
根据本发明的一些实施例,所述步骤s4用所述r语言的psych包完成。
在本发明的一些实施例中,所述降维数据的维度为2-4个。
根据本发明的一些实施例,所述步骤s5用所述r语言的mclust包完成。
根据本发明的一些实施例,所述步骤s6中选取的所述标记数据为3-5组。
根据本发明的一些实施例,所述建立adaboost模型用所述r语言的adabag包完成。
根据本发明的一些实施例,在所述步骤s10后,所述方法还包括:将所述adaboost模型用于实际的矿泉水进行验证。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
图1是根据本发明实施例的基于adaboost模型的水质特征矿泉水分类方法的流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下文的公开提供了许多不同的实施例或例子用来实现本发明的不同结构。为了简化本发明的公开,下文中对特定例子的部件和设置进行描述。当然,它们仅仅为示例,并且目的不在于限制本发明。此外,本发明可以在不同例子中重复参考数字和/或字母。这种重复是为了简化和清楚的目的,其本身不指示所讨论各种实施例和/或设置之间的关系。此外,本发明提供了的各种特定的工艺和材料的例子,但是本领域普通技术人员可以意识到其他工艺的可应用于性和/或其他材料的使用。
下面参考附图描述根据本发明实施例的基于adaboost模型的水质特征矿泉水分类方法。
如图1所示,根据本发明实施例的基于adaboost模型的水质特征矿泉水分类方法,包括:步骤s1、步骤s2、步骤s3、步骤s4、步骤s5、步骤s6、步骤s7、步骤s8、步骤s9和步骤s10。
具体地,如图1所示,步骤s1为选取三个以上有一定距离的矿泉水水源地,在矿泉水水源地采集水样,水样的数量为至少60组,且每个水源地不少于20组。可以理解的是,水样的数量可以为60组、70组、80组或更多组。由此,可以提升样本的数量,从而提升模型的准确性。
如图1所示,步骤s2为测试每组水样的水质信息,水质信息包括常量元素含量、微量元素含量、ph值、总可溶性固体、同位素的δ值和硬度。
可以理解的是,不同类别的水样的常量元素含量、微量元素含量、ph值、总可溶性固体、同位素的δ值和硬度是不同的,通过对常量元素含量、微量元素含量、ph值、总可溶性固体、同位素的δ值和硬度的分析可以为水样的分类提供较多的分类依据。
如图1所示,步骤s3为利用多组水质信息建立excel表,并将excel表转成csv表,将csv表导入r语言。
如图1所示,步骤s4为利用主成分分析方法将数据降维以得到降维数据;步骤s5为利用高斯混合模型将降维数据进行分类以得到分类数据;步骤s6为将分类数据进行标记,选择可有效区分的多组标记数据;步骤s7为将多组标记数据导入r语言并按照7:3的比例分为训练数据集和测试数据集;步骤s8为对训练数据集采用随机森林的方法进行特征选择,选取3-6个参数;步骤s9为将adaboost模型框架应用于经过特征选择后的训练数据集进行训练,并建立adaboost模型;步骤s10为将adaboost模型用于测试数据集,评估adaboost模型的正确率,并改进adaboost模型。在本发明的一个示例中,上述建立adaboost模型在r语言的adabag包中完成。
矿泉水的资源分布是有其规律的。通过建立矿泉水的分类模型,有助于更加科学有效地管理矿泉水资源,指导公众合理鉴别及选择自己需要的矿泉水,同时对于矿泉水的进一步分析具有基础的指导作用。
可以理解的是,考虑到每个判别参量的重要性有所差别,使用主成分分析方法和高斯混合模型对数据进行特征选择,也就说可以在样本的角度选择更加具有代表性的数据,然后利用r语言并选取的数据按照7:3的比例分为训练数据集和测试数据集,使用训练数据集建立adaboost模型后,将adaboost模型用于测试数据集,评估adaboost模型的正确率,并改进adaboost模型,从而可以提升adaboost模型的准确性,进而提升矿泉水分类的合理性和科学性。
根据本发明的一些实施例,在步骤s2之后,且在步骤s3之前,方法还包括:将常量元素含量换算成当量浓度百分数,将微量元素含量换算成当量浓度。由此,可以降低计算的难度,提升计算的效率,节省计算的时长。ph值、总可溶性固体、同位素的δ值和硬度保持初始单位不变。
根据本发明的一些实施例,步骤s4在r语言的psych包中完成。由此,不仅可以节省时间,还可以提升结果的准确性。
具体地,在本发明的一个示例中,将csv表格数据导入r语言中,用主成分分析的方法将数据降维,计算方法如下,运算中用到r语言的psych包。
(1)、将数据x按照列中心化。
(2)、计算样本矩阵的协方差矩阵c。
(3)、求样本集矩阵x的协方差矩阵c的特征值和特征向量。
(4)、构建降维转换矩阵u。设原数据有n个变量,根据需要(地球化学专业分析)或计算结果(协方差矩阵),将数据降维至m个变量(m<n),则将按大小排列排名前m位的特征值对应的特征向量组成降维转换矩阵u。
(5)、由降维转换公式z=xu求得x的降维矩阵z,该矩阵用更低的维度(变量)来代表原数据集的信息。
在本发明的一些实施例中,降维数据的维度为2-4个。由此,在保证结果准确性的同时,可以降低计算的难度,提升计算的效率,节省计算的时长。例如,在本发明的一个示例中,降维数据的维度为2个、3个或4个。
根据本发明的一些实施例,步骤s5在r语言的mclust包中完成。由此,不仅可以节省时间,还可以提升结果的准确性。
具体地,在本发明的一个示例中,用高斯混合模型(gmm)将降维后的数据分类,计算方法如下:
(1)、设每一组水样数据符合高斯分布,其分布函数如式(2-a)所示:
其中k为分类的个数,πk为混合系数,μk为期望,σk为协方差矩阵,代表每个样品属于第m(m=1,2,…,k)组的概率,
(2)、样本集x(n个样本点)的联合概率如式(2-b)所示:
(3)、对数似然函数如式(2-c)所示:
用em算法解出模型中μ,σ,π,k的值。
根据本发明的一些实施例,步骤s6中选取的标记数据为3-5组。由此,在保证结果准确性的同时,可以降低计算的难度,提升计算的效率,节省计算的时长。例如,在本发明的一个示例中,标记数据为3组、4组或5组。
需要说明的是,建模的时候有多个参量需要设定及优化,比较重要的参数有划分时考虑的最大特征数、决策树最大深度、其它可能需要考虑的参数主要有内部节点再划分时所需的最小样本数、叶子节点最少样本数、叶子节点最少样本权重、最大叶子节点数等。例如,模型中有3-6个变量计,该参数可优化为2或3。具体参数的优化还需要根据模型的判别表现来确定。将adaboost模型回代,可以分析误判的数据,需要注意的是,除非明显错误,一般不再删除训练数据集中数据,如删除了部分数据,则需要再次训练数据。
在本发明的一个示例中,在步骤s8中,为方便使用计,尽量用常量元素作为建模使用的特征参数,如有具有明显区分特征的微量元素也可作为建模使用的特征参数。特征选择的步骤如下:
(1)、设数据集x共包含n各样本,使用自助法(bootstrap)从数据集中随机放回式抽取n各样本装入袋中,作为训练数据集。在这个过程中,每个样本没有被选中的概率是p=(1-1/n)n。在n趋于+∞时,p≈0.37。这说明在自助法采样时,约有37%的样品没有被选中,称为袋外数据(oob)。袋内数据用来训练模型,袋外数据用来评估模型。
(2)、共进行k次抽取,故可获得k个训练数据集。采用无剪枝的方法用每一个训练数据集建立决策树。在每一个节点的位置,从总数m个特征中随机选择m个特征,并计算m个特征中每一个特征的gini指数,gin指数越小时,说明该特征的区分效果越好,选择最优的特征作为该分支节点。按照这种策略建立一个完整的决策树。
(3)、用k个数据集共可得到k个决策树,形成一个随机森林的模型。模型的质量可以用袋外数据(oob)的预测准确率来评估。袋外数据的均方误差(mseoob)和决定系数(rrf2)如公式(1-a)和(1-b),其中均方误差越小,决定系数越大,则说明该模型越优秀。
其中,n是袋外数据的数量,yi是袋外数据的观测值,
(4)、使用平均不纯度减少值来选择重要的预测特征。在每一棵树的每个节点,应用公式(1-c)计算每个变量的gini指数,计算每一棵树每一个节点上各特征的gini指数,按照特征将所有的gini指数取平均值,计算平均不纯度减少值。然后对每一个特征进行排序,就可以对各特征在模型中的重要性进行评分,以选择合适的特征进行建模。
其中pi是某个样本属于第i枝的概率,n是该节点处枝的总数,igini是gini指数。综合随机森林的分析方法与地球化学的分析确定重要的变量,以备建模使用,重要变量的选择以常量元素为主,微量元素、同位素及其它参数作为辅助,数量一般为3-6个。
应用adaboost算法建立机器学习模型,步骤如下:
(1)设训练数据集有n条记录,初始化每条记录的权重为1/n
w1={w11,...,w1i,...,w1n},w1i=1/n,i=1,2,...,n
(2)对m=1,2,…,m(m是训练的轮数)
(2.1)根据记录的wm权重对d有放回抽样,训练数据集dm
(2.2)使用决策树算法训练dm得到模型gm(x)
(2.3)计算gm(x)的误分类率
(2.4)如果em>0.5,则返回步骤2.2
(2.5)对每条被正确分类的数据更新权重,令其乘以em/(1-em),然后对所有数据的权重规范化得到wm+1
(2.6)设定模型的权重
(3)获得m个模型gm(x)(m=1,2,…,m)及它们的权重αm(m=1,2,…,m)。用m个模型对待测数据进行计算,对计算结果进行加权汇总后得到最终结果,可表示为
需要说明的是,在步骤s10中,将模型回代,分析误判的数据,除非明显错误,一般不再删除训练数据集中数据,如删除了部分数据,则需要再次训练数据。
根据本发明的一些实施例,在步骤s10后,方法还包括:将adaboost模型用于实际的矿泉水进行验证(步骤s11)。由此,可以利用实际的矿泉水进一步验证adaboost模型的准确性。在本发明的一个示例中,通过检测结果适应性的修改模型,从而可以进一步提升检测结果的可靠性。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



