
 商标分类
商标分类  商标转让
商标转让 
基于stacking算法的妊娠糖尿病预测方法与流程
 2021-01-08 11:01:19|
2021-01-08 11:01:19| 291|
291| 起点商标网
起点商标网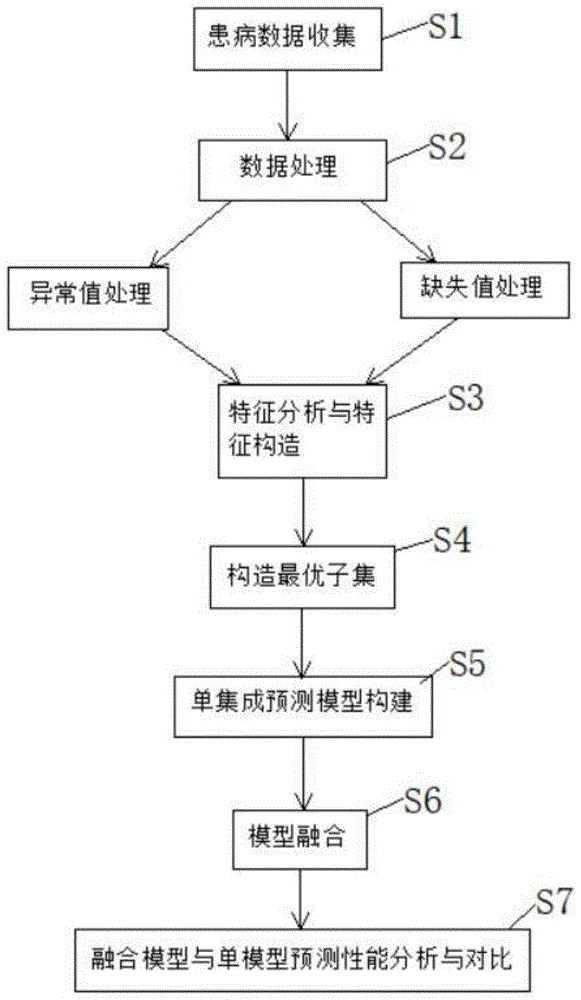
本发明涉及妊娠糖尿病预测技术领域,具体为基于stacking算法的妊娠糖尿病预测方法。
背景技术:
妊娠期糖尿病是导致二型糖尿病及其综合症蔓延全球的重要原因之一,根据研究表明,截止2019年我国患有妊娠期糖尿病的人数排名世界第二。妊娠期糖尿病(gdm)指的是孕妇在妊娠期表现的糖代谢异常,此类型的糖尿病是由于妊娠导致的暂时性病症,会影响到孕妇和胎儿的人身安全。妊娠期糖尿病患者容易患有高血压,原因是人体内的胰岛素分泌不足,血糖含量过高,从而影响到血管的弹性。除此之外,高浓度的血糖会促进孕妇分泌的羊水增加,并刺激到子宫内膜,容易使胎儿早产和窒息。高血糖还会影响到免疫系统,影响白细胞的吞噬能力,导致免疫能力下降,进而发生胎盘早剥的情况,目前的研究发现妊娠期糖尿病是导致孕妇不正常妊娠的原因之一,包括胎儿巨大症、胎儿肩难产。妊娠期糖尿病的影响不止于此,gdm会对母体和胎儿带来长期影响,有研究结果说明,患有gdm的孕妇在产后五年内,有13%-63%的概率患有二型糖尿病且糖耐量异常。
近年来,机器学习算法在医疗领域的应用频率和研究深度增长迅速,已经有学者应用机器学习算法实现对部分疾病患病率的预测,且效果显著,集成学习是机器学习算法中较有特点的一类,它是按照将弱分类器集成为强分类器的思路来组合基础模型,集成学习模型除了在稳定性和泛化能力上相比传统模型表现突出,在最终的预测准确率上也相对较高。
疾病预测在根据真实数据建模的过程中,往往会遇到数据质量差、缺失值较多、正负样本有偏等问题,在数据预处理过程中,选择怎样的处理方式将使预测精度最高的问题;使用stacking集成学习框架并加以改进,以解决样本标签不足可能会产生的过拟合问题,并使融合后的模型较单模型性能表现更好的缺点。
技术实现要素:
针对现有技术的不足,本发明提供了基于stacking算法的妊娠糖尿病预测方法,解决了上述背景技术中提出疾病预测在根据真实数据建模的过程中,往往会遇到数据质量差、缺失值较多、正负样本有偏等问题,在数据预处理过程中,选择怎样的处理方式将使预测精度最高的问题;使用stacking集成学习框架并加以改进,以解决样本标签不足可能会产生的过拟合问题,并使融合后的模型较单模型性能表现更好的问题。
为实现以上目的,本发明通过以下技术方案予以实现:基于stacking算法的妊娠糖尿病预测方法,包括以下步骤:
s1、患病数据收集;
s2、数据处理;
s3、特征分析与特征构造;
s4、构造最优子集;
s5、单集成预测模型构建;
s6、模型融合;
s7、融合模型与单模型预测性能分析与对比。
可选的,所述步骤s1、患病数据收集中,收集便携式计算机,通过便携式计算机登录阿里云医疗数据库,收集阿里云医疗真实数据,记录患病数据备份。
可选的,所述步骤s2、数据处理中,选用合适的数据预处理方法处理缺失值,处理和选择特征来构成特征子集,使构成的特征子集能在算法上表现更好的效果,以及构造有效的特征子集,选出对妊娠糖尿病有影响的特征变量作为模型的输入变量,使计算的复杂度简化并提升模型的预测效果。
可选的,所述步骤s3、特征分析与特征构造中,分别对比步骤s2、数据处理中异常值处理和缺失值处理,对数据进行数据处理及分析。
可选的,所述步骤s4、构造最优子集中,选取s3、特征分析与特征构造中,最优数据构建子集。
可选的,所述步骤s5、单集成预测模型构建中,用集成学习算法构建预测模型来预测妊娠糖尿病,以及根据数据集特点对模型参数进行调优,分别建立xgboost、随机森林、catboost、逻辑回归四个单集成妊娠糖尿病预测模型,并通过实验调参使单集成模型的预测效果达到最佳。
可选的,所述步骤s6、模型融合中,结合步骤s5、单集成预测模型构建中xgboost、随机森林、catboost、逻辑回归四者的优点,弥补不足,选择两层stacking集成学习框架进行模型融合,选取xgboost、随机森林与catboost这三种模型当做模型融合的基模型作为训练,并得出预测结果,将预测结果作为特征,应用到逻辑回归模型中进行训练,训练出最终预测模型。
可选的,所述步骤s7、融合模型与单模型预测性能分析与对比中,将步骤s6、模型融合中的预测结果与步骤s5、单集成预测模型构建中四种单集成预测模型预测结果进行汇总,对auc值进行比较,验证融合模型的预测表现是否优于其他模型。
本发明提供了基于stacking算法的妊娠糖尿病预测方法,具备以下有益效果:
1、该基于stacking算法的妊娠糖尿病预测方法基于集成学习建立一个有效的妊娠糖尿病预测糖尿病患病风险的模型,帮助医护人员预测处于妊娠糖尿病的患者,及时并准确的对高危人群采取针对性的措施,这将有助于妊娠期糖尿病的辅助诊断和预防,为智能诊断和减少不良妊娠作出贡献。
2、该基于stacking算法的妊娠糖尿病预测方法,将缺失值及冗余值进行处理,选出对妊娠糖尿病影响较大的特征变量,得到一个特征子集;利用stacking集成学习框架得到一个妊娠糖尿病的预测模型,并通过实验验证融合后的妊娠糖尿病预测模型是否比单模型预测的预测性能更好,泛化能力更强。
3、该基于stacking算法的妊娠糖尿病预测方法,基于stacking算法建立妊娠糖尿病预测模型,集成学习算法是机器学习众多算法的一种,它构建了特征之间非线性的关系,集成学习算法是一种将弱分类器提升为强分类器的算法,特点是每次计算的弱分类器都能被下次构建的弱分类利用,从而在这样的不断学习改进中将弱分类器改造成了强分类器,本课题拟采用的单集成模型xgboost,catboost,随机森林都是基于类似的弱变强原理,这三种集成模型的原理在细节处有不同的特色,且和本次研究的样本特点契合,即小样本,多分类且数据缺失情况较严重。此外,根据模型优化思路,本课题拟将stacking集成框架融合分为两层,第一层为三种单集成模型的基模型训练过程,第二层将基模型融合到逻辑回归模型中,之所以采用逻辑回归模型,是因第一层已经使用了复杂的非线性变换,所以在输出层采用了简单的分类模型来学习基分类器的权重从而降低过拟合的现象,而逻辑回归是一个很合适的选择,故融合模型的第二层使用逻辑回归。
附图说明
图1为本发明主视结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
请参阅图1,本发明提供一种技术方案:基于stacking算法的妊娠糖尿病预测方法,包括以下步骤:
s1、患病数据收集;
s2、数据处理;
s3、特征分析与特征构造;
s4、构造最优子集;
s5、单集成预测模型构建;
s6、模型融合;
s7、融合模型与单模型预测性能分析与对比。
步骤s1、患病数据收集中,收集便携式计算机,通过便携式计算机登录阿里云医疗数据库,收集阿里云医疗真实数据,记录患病数据备份。
步骤s2、数据处理中,选用合适的数据预处理方法处理缺失值,处理和选择特征来构成特征子集,使构成的特征子集能在算法上表现更好的效果,以及构造有效的特征子集,选出对妊娠糖尿病有影响的特征变量作为模型的输入变量,使计算的复杂度简化并提升模型的预测效果。
步骤s3、特征分析与特征构造中,分别对比步骤s2、数据处理中异常值处理和缺失值处理,对数据进行数据处理及分析。
步骤s4、构造最优子集中,选取s3、特征分析与特征构造中,最优数据构建子集。
步骤s5、单集成预测模型构建中,用集成学习算法构建预测模型来预测妊娠糖尿病,以及根据数据集特点对模型参数进行调优,分别建立xgboost、随机森林、catboost、逻辑回归四个单集成妊娠糖尿病预测模型,并通过实验调参使单集成模型的预测效果达到最佳。
步骤s6、模型融合中,结合步骤s5、单集成预测模型构建中xgboost、随机森林、catboost、逻辑回归四者的优点,弥补不足,选择两层stacking集成学习框架进行模型融合,选取xgboost、随机森林与catboost这三种模型当做模型融合的基模型作为训练,并得出预测结果,将预测结果作为特征,应用到逻辑回归模型中进行训练,训练出最终预测模型。
步骤s7、融合模型与单模型预测性能分析与对比中,将步骤s6、模型融合中的预测结果与步骤s5、单集成预测模型构建中四种单集成预测模型预测结果进行汇总,对auc值进行比较,验证融合模型的预测表现是否优于其他模型。
以上,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



