
 商标分类
商标分类  商标转让
商标转让 
基于语义的家庭医疗咨询决策支持方法与流程
 2021-01-08 11:01:23|
2021-01-08 11:01:23| 324|
324| 起点商标网
起点商标网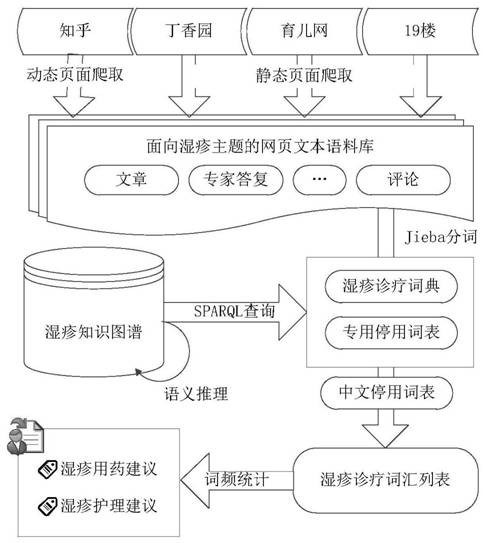
本发明涉及家庭医疗技术领域,具体涉及一种基于语义的家庭医疗咨询决策支持方法。
背景技术:
近年来,随着公众健康意识的增强、政策红利的驱动以及老龄化问题日益凸显,家庭医疗保健场景变得越来越普及。然而医学知识的欠缺,使得家庭医疗很难真正大范围的普及,这也是造成“有病就去大医院”、“小病大看”等就医习惯的根本原因。通常情况下,临床实践大多以经验和推论为主,随着信息技术在医疗领域的深入发展,电子病历系统在各个医疗机构中已经普及,临床经验以文档或结构化数据的形式被存储起来。目前已有很多研究致力于从健康医疗数据中总结经验,辅助临床的决策支持。
健康医疗数据分为院内数据与院外数据两种类型。院内数据由电子病历系统等院内医疗信息系统采集并存储,也是目前医学数据研究的主要对象,其在质量和规模上具有竞争力。但是院内数据的缺点体现在其隐私安全问题和信息壁垒问题上。因此,基于院内数据分析的结果主要服务于本地机构的临床决策支持。而院外数据以前主要集中在智能硬件设备的检测数据和政府收集的个人健康档案。随着互联网技术在日常医疗场景中的渗透,人们越来越习惯于在互联网上求助和分享临床经验,因此互联网上积累了大量的、开放的网络医学数据。例如丁香园、知乎和微医等国内网站的流量快速增长,在搜索引擎中检索高血压、糖尿病等常见疾病,搜索结果都已经超过了1亿条。可以看出当前的网络数据规模庞大、增长快速,且其数据的开放性能够更加便捷地服务于公众。目前互联网上的医学数据以文本形式为主,来源复杂且缺乏整合,质量参差不一。由于医学术语繁多复杂,采用传统的中文分词方法根本无法从本文中发现医学关键信息。
那么如何从网络文本中挖掘出有效信息并进行知识表达,从而使公众获取有效的医学知识是家庭医疗中亟待解决的问题。
技术实现要素:
针对上述存在的问题,本发明旨在提供一种基于语义的家庭医疗咨询决策支持方法,通过探索基于互联网医学数据的临床决策支持方法,为公众在家庭治疗和日常保健中提供决策参考。
为了实现上述目的,本发明引入了语义技术构建医学知识模型,明确了诊疗方案中的关键信息要素以支撑中文分词,最终从文本中提炼出可为公众提供决策参考的诊疗建议,为此本发明所采用的技术方案如下:
基于语义的家庭医疗咨询决策支持方法,其特征在于,包括以下步骤:
步骤1:通过python的主题网络爬虫获取互联网上的某种疾病的医学数据,并将对应的网页内容保存到本地;
步骤2:基于语义技术构建疾病知识图谱,得到疾病诊疗过程中的关键要素,并生成自定义词典;
步骤3:基于所述自定义词典,利用jieba库对网页文本进行中文分词,统计关键词词频,计算诊疗环节各种诊疗手段的概率分布;
步骤4:根据诊疗环节中各种诊疗手段的概率分布,确定该诊疗环节采用何种诊疗手段,最终用于辅助决策。
进一步地,步骤1的具体操作步骤包括:
步骤11:通过预设主题关键词和待爬取的url列表作为种子,通过检索关键词得到相应的结果页面;
步骤12:针对所述结果页面的异构网页组织形式,将网页分为静态页面和动态页面;
步骤13:如果待爬取的页面为静态页面,则利用python中的beautifulsoup和lxml来进行网页解析,提取目标url;如果待爬取的页面为动态页面先通过selenium对象模拟浏览器的页面交互操作,进而获取动态页面的数据,再利用python中的beautifulsoup库进行页面解析,提取目标url;
步骤14:将得到的网页结果以html文本形式保存到本地。
进一步地,步骤2中的具体操作步骤为:
步骤21:基于本体编辑工具protégé构建疾病disease、诊断diagnosis和诊疗方案careplan对应的类,得到本体模型;
步骤22:基于本体模型添加疾病、诊断、诊疗方案的实例和属性,并对各个属性赋值以建立实例间的关系;
步骤23:提取实例中的rdfs:label和rdfs:comment属性值,将其导出最终生成自定义词典。
进一步地,步骤3的具体操作步骤包括:
步骤31:对得到的网页文本进行预处理,通过正则表达式提取所有的中文文本并过滤掉<head>、<script>等网页标签;
步骤32:利用jieba精准模式对所述中文文本进行分词,设定分词的自定义词典为步骤23中生成的词典;
步骤33:利用jieba中的中文停用词表进行停用词过滤,并将处理结果保存到网页文本文件中;
步骤34:基于中文分词结果,利用统计学的方法统计疾病相关医学术语出现的频次;
步骤35:依据计算出的词频得到诊疗环节不同诊疗手段的概率分布。
进一步地,步骤34中所述的统计各种医学术语出现的频次的词频计算表达式为:
其中,n为某诊疗环节的不同诊疗手段数量,m为某种诊疗手段在互联网数据中的不同种表达方式,且xi,j(i=1,2,...,m;j=1,2,...,n)为每种表达方式在互联网数据中出现的频次。
本发明的有益效果包括:
第一,本发明中的方法通过构建疾病知识图谱明确关键诊疗环节,为中文文本分词提供自定义词典,根据分词结果统计关键诊疗环节在互联网医学数据中的频次,最终为家庭医疗场景提供临床决策支持;
第二,本发明中的方法将网络爬虫技术、语义技术、分词和统计方法相结合,从互联网数据中发现诊疗规律、提炼治疗路径,提出了一种基于互联网医学数据辅助诊疗的技术方法,是对院内数据挖掘的有效补充和拓展;
第三,本发明中的方法与医学指南相结合,有助于补充和细化指南标准路径中的诊疗环节,为医学指南在家庭医疗场景中的推广应用打下基础。
综上所述,通过本发明提出的基于语义的家庭医疗咨询决策支持方法,能够针对互联网医疗数据进行挖掘并提供临床决策支持,是对院内数据的有效补充和拓展,为建立医学大数据科研辅助分析引擎打下基础,将在家庭医疗领域发挥重要的作用。
附图说明
图1为疾病类中名称为acuteappendicitis的实例;
图2为基于疾病知识图谱的文本分词和知识发现过程示意图;
图3为面向湿疹疾病的家庭医疗咨询决策支持过程示意图;
图4为湿疹知识图谱中诊疗方案实例与药物实例的关联示意图;
图5为实施例中按类统计每种药物的词频示意图;
图6为湿疹护肤品牌的频次统计结果图。
具体实施方式
为了使本领域的普通技术人员能更好的理解本发明的技术方案,下面结合附图和实施例对本发明的技术方案做进一步的描述。
院内数据可以直接从电子病历系统的数据库中导出结构化数据,面向多源异构系统时采用语义技术进行数据的标准化和统一化处理,语义技术在院内数据分析领域已有大量的研究经验。而面向互联网中的医学数据,涉及到数据获取、整合和分析,整个过程更加复杂。首先需要明确数据来源并主动获取:
基于语义的家庭医疗咨询决策支持方法,包括以下步骤:
步骤1:通过python的主题网络爬虫获取互联网上的某种疾病的医学数据,并将对应的网页内容保存到本地;
进一步地,步骤1的具体操作步骤包括:
步骤11:通过预设主题关键词和待爬取的url列表作为种子,通过检索关键词得到相应的结果页面;
由于各个网站平台的网页组织形式不同,将其分为静态页面和动态页面两种类型,不同类型的页面,数据爬取过程呈现明显的差异,需要加载不同的python第三方库;
步骤12:针对所述结果页面的异构网页组织形式,将网页分为静态页面和动态页面;
静态页面以丁香园平台为例,使用浏览器在丁香园网站搜索“湿疹”,查看搜索结果,找到约12982条结果,分页显示,每页显示15个结果,每条结果链接到一个独立的页面。对于静态页面,页面编号通常作为参数包含在url之中,根据携带页面编号参数的url可获取到每个结果页面的内容,进一步分离目标url获取详细信息作为文本语料库的内容。静态页面的数据获取较为简单,直接使用requests对象的get方法可获取对应url的页面内容,主要的难点在于对网页html结构的分析。在丁香园网站中,所有的搜索结果都位于class属性值为“main-itemj-main-it”的div标签之中,而目标url的位置是由div.h3.a标签的href属性所决定的。每个平台都有自己独立的页面组织结构,数据获取过程需要对页面进行解析;
动态页面的内容是随着时间、环境或者用户操作的结果动态改变的,通过requests对象从页面中get的方式只能获取到第一次加载的页面内容,页面信息有限。对于此类网页,首先通过selenium对象模拟浏览器的页面交互操作,进而获取动态页面的数据。以知乎平台为例,首次加载时,页面只显示了最新的28个结果,需要多次模拟浏览器的下拉操作,尽可能多地让页面下载数据到浏览器端;
步骤13:如果待爬取的页面为静态页面,则利用python中的beautifulsoup和lxml来进行网页解析,提取目标url;如果待爬取的页面为动态页面先通过selenium对象模拟浏览器的页面交互操作,进而获取动态页面的数据,再利用python中的beautifulsoup库进行页面解析,提取目标url;
步骤14:将得到的网页结果以html文本形式保存到本地;
无论是静态页面还是动态页面,步骤1要完成的是分析网站类型和网页结构,尽可能地获取到所有与主题相关的结果并保存到本地。
步骤2:基于语义技术构建疾病知识图谱,得到疾病诊疗过程中的关键要素,并生成自定义词典;
由于传统的中文分词方法无法识别复杂的医学术语,更别说提炼出关键诊疗信息。因此,本文引入了语义技术,构建疾病知识图谱。语义网为数据的共享和重用提供了通用框架。在语义网中,网络内容被表达为自然语言,不仅易于被人们理解,而且易于被机器处理,使得信息的发现、共享和集成更加智能。语义技术包括了描述知识图谱的网络本体语言(webontologylanguage,owl)、支持语义推理的语义网规则语言(semanticwebrulelanguage,swrl)以及jena语义网框架等。
将语义技术应用于医学知识建模,构建面向疾病的知识图谱,明确定义疾病诊疗方案实例,细化疾病诊疗过程中的关键要素。这些关键要素将作为网页文本分词自定义词典的重要组成部分,为从文本数据中提取关键诊疗信息提供基础。
进一步地,为有效地表达面向疾病的诊疗方案,步骤2的具体操作步骤包括:
步骤21:基于本体编辑工具protégé构建疾病disease、诊断diagnosis和诊疗方案careplan对应的类,得到本体模型;
步骤22:基于本体模型添加疾病、诊断、诊疗方案的实例和属性,并对各个属性赋值以建立实例间的关系;
步骤23:提取实例中的rdfs:label和rdfs:comment属性值,将其导出最终生成自定义词典,此时自定义词表中包含了药物的名称、成分和别名等医学术语信息。
以急性阑尾炎为例,acuteappendicitis是疾病类disease的一个实例,通过数据属性hasicd_10code设定其icd10编码为dn00114,中文标签“急性阑尾炎”,在protégé中实例定义如附图1所示;
appendectomycp是诊疗方案类careplan的一个实例,用来记录疾病acuteappendicitis的诊疗方案,其中包含了明确的关键诊疗环节,例如化验项血常规(completebloodcount,cbc)、注射项青霉素(penicillin)和手术项阑尾切除术(appendectomy)等;
疾病知识图谱的构建对文本分析来说非常重要,对于每个疾病种类,只有明确了其中的关键诊疗环节,才能为文本分词提供准确的自定义词典。
步骤3:基于所述自定义词典,利用jieba库对网页文本进行中文分词,统计关键词词频,计算诊疗环节各种诊疗手段的概率分布;
本发明中的中文文本的分词过程借助了jieba库,jieba是用于文本分析的主流python第三方生态库,其分词原理是利用一个中文词库,将带分词的内容与分词词库进行比对,通过图结果和动态规划方法找到最大概率的词组。除了分词,jieba库还提供了自定义中文词典的功能,使用此功能可支持对医学专用语的识别。jieba分词支持三种模式:①精准分词模式将句子精确地划分,不产生冗余词组,适用于文本分析;②全模式切分句子中所有可能的词组组合,但存在冗余;③搜索引擎模式在精准模式的基础上对长词再次切分以提高召回率;本发明使用了精准模式对文本库中的网页文本进行分词;
经过自定义词典的建立和jieba库中文分词,得到了所有网页文本的词语列表,接着基于统计学的方法,对知识模型中定义的医学知识术语进行词频统计;
进一步地,步骤3的具体操作步骤包括:
步骤31:对得到的网页文本进行预处理,通过正则表达式提取所有的中文文本并过滤掉<head>、<script>等网页标签;
步骤32:利用jieba精准模式对中文文本进行分词,设定分词的自定义词典为步骤23中生成的词典;
步骤33:利用jieba中的中文停用词表进行停用词过滤,并将处理结果保存到网页文本文件中;
步骤34:基于中文分词结果,利用统计学的方法统计疾病相关医学术语出现的频次;
步骤35:依据计算出的词频得到诊疗环节不同诊疗手段的概率分布。
疾病知识图谱准确描述了关键诊疗环节的定义、属性和关系,基于此得到的自定义词典中包含了对关键诊疗环节的多种表达方式,例如诊疗药物“糠酸莫米松乳膏”,常见的表达有糠酸莫米松、艾洛松和糠酸等。疾病可能有多种诊疗方案,对于婴幼儿湿疹,存在多种外用药物。在湿疹患者的家庭护理诊疗过程中,需要对药物进行选择,通过词频统计来表示药物的使用率。假定对于疾病d存在n种激素类药物可供选择,每种激素类药物在数据中可能存在m种不同的表达方式,每种表达方式在互联网数据中出现的频次为xi,j(i=1,2,...,m;j=1,2,...,n),那么,某种激素类药物在文章中的词频计算式可以表示为:
步骤4:根据各个诊疗环节的概率分布,得出家庭诊疗的临床决策;
一个诊疗环节可能有多种诊疗手段,通过统计不同诊疗手段的概率分布,有助于确定该诊疗环节采用何种诊疗手段,例如在某个诊疗环节采用药物治疗手段,包括具体使用了什么药物,或者在某个诊疗环节采用了物理治疗手段,包括使用什么物理治疗方法,通过确定在诊疗环节采用何种诊疗手段,进而达到辅助决策支持的目的。
综上所述,附图2描述了基于疾病知识图谱的中文文本分词和知识发现过程,可以看出,首先使用主题网络爬虫获取网页医学文本,其次,建立疾病知识图谱,并通过构建的疾病知识图谱中的实例设置自定义词典,最后,基于自定义词典利用jieba库精准模式对文本库中的网页文本进行中文分词和词频统计,最终生成各个诊疗环节的概率分布,进而为公众提供辅助家庭诊疗的临床决策支持。
实施例:
在本实施例中,通过以湿疹的用药建议为例,进一步地说明如何通过疾病知识图谱的建立来解决医学术语中繁多复杂难以进行分词的问题。
湿疹是一种慢性炎症瘙痒性皮肤病,具有发病率高、病程长和易反复的特点,通常需要长期治疗。近年来婴幼儿湿疹的发病率更是逐年上升,对患者及家属造成了严重的困扰。
根据卫生部发布的荨麻疹临床路径,其治疗周期一般为7天,糖皮质激素药物局部外用是治疗轻中度湿疹的主要手段,过程中同时使用抗过敏药物、消炎药物来辅助治疗。常见的糖皮质激素包括糠酸莫米松、氢化可的松、可的松和倍他米松等;抗过敏药物包括美能、拓尔敏片等;消炎外用药物主要是百多邦。其中,氢化可的松、倍他米松等是激素类药物的主要成分,美能、拓尔敏片和百多邦是常见药物的别名。医学领域术语繁多,单就药物的称谓,每种药物包含药物名称、主要成分和别名。而且,这些词都不属于常用词,直接使用传统分词方法根本无法有效识别这些信息。
以湿疹的治疗方案为例,表1中列出了湿疹治疗常用药物,包括了常见的5种激素类药物、4种抗过敏药物和1种抗生素消炎药物,表格中各列分别给出了药物名称、主要成分、主要别名和类型。
表1湿疹常用药物列表
由于湿疹的病程长、易反复和婴幼儿常发的特性,湿疹的诊疗过程主要依赖于家庭护理。但是湿疹治疗药物种类繁多,难以选择是湿疹家庭护理中现存的主要问题。附图3为面向湿疹疾病的家庭医疗咨询决策支持过程,可以看出:
首先,要在互联网上采集相关的湿疹数据信息。
目前国内热门的亲子网站主要有育儿网、丁香园、19楼亲子论坛等,根据数据量规模,选取丁香园、知乎、育儿网和19楼四个平台作为数据来源目标网站。在这四个平台中输入“湿疹”关键词进行检索,各个平台给出的检索结果列表列出了“湿疹”相关的文章或者问诊信息。通过对不同的网页html结构进行解析,编写面向各个平台的网络爬虫从这些平台收集数据。
对于丁香园、育儿网和19楼三个平台,检索结果以静态页面方式组织,通过遍历访问每个页面获取页面中每篇文章的链接进行访问并获取详细数据;对于知乎平台,检索结果以动态页面方式组织,通过selenium来模拟浏览器下拉操作,动态加载数据并获取链接信息进行访问。
表2中详细列出了网站名称、url地址以及通过网络爬虫获取的目标网页数量。需要说明的是,目标网页中除了正文之外,还包含了大量的评论和回复信息。
表2平台名称、url地址以及爬虫采集到的目标网页数量
其次,当湿疹数据采集完成之后,建立湿疹知识图谱。
构建一个良好的医学知识模型是实现文本分析关键信息提取的基础。基于卫生部发布的荨麻疹临床路径,分析路径结构和内容,明确诊疗过程中的关键信息要素;针对关键信息要素,采用知识工程方法构建面向湿疹的本体模型,定义类和属性。
在此基础上,为湿疹定义eczema疾病实例,基于湿疹诊疗过程中的关键信息要素,构建诊疗方案实例eczemacp。湿疹知识图谱中,诊疗方案实例与药物实例的关联如图4所示,其中前缀cp是诊疗方案(careplan)的简写,是整个本体模型命名空间的名称。
从附图4可以看出,最上方的框体中列出了诊疗方案实例eczemcp和它的三个重要属性。对象属性usedfordisease的值说明该实例适用病症为疾病eczema;数据属性hasduration的值代表该实例治疗周期为7天;对象属性hasorderevert包含了多个属性值,每个属性值代表了湿疹诊疗过程中的一个关键诊疗环节,例如hormonesevent、antiallergicevent和antibioticsevent分别代表激素药物治疗、抗过敏药物治疗和抗生素药物治疗,均属于医嘱类型中的处方类实例。
每个医嘱实例又拥有自己的属性,通过hasrelatedterm对象属性关联到具体的药物。例如,激素药物治疗实例hormonesevent关联到的药物实例包括momeiasone、hydrocortisone、desonide、triancinolone和betamethasone,分别对应到表1中列出的五种常见激素药物。每个药物实例通过定义其label属性和comment属性,设置了药物的中文名称、主要成分名称和别名附。图4其下方框体给出了momeiasone药物实例在protégé工具中的定义。
基于湿疹知识图谱的实体关系,执行语义推理,完成is_a、sub_class等关系的继承和匹配,生成湿疹知识库推理模型。基于湿疹知识推理模型中的实体关系,使用如下所示的sparql语句即可获取湿疹诊疗方案实例eczemacp相关药物的医学术语信息。
select?object
where{
cp:eczemacpcp:hasorderevent?order
?ordercp:hasrelatedterm?drug
?drugrdfs:label?object
}
最后,根据湿疹知识图谱,对湿疹诊疗方案进行提取和统计。
基于湿疹数据和湿疹知识图谱提取和统计湿疹诊疗方案的过程可分为以下几步:
第一,通过sparql语义检索,从湿疹知识图谱中获取各个药物实例的label和comment属性值,导出作为分词的中文自定义词典,此时自定义词表中包含了药物的名称、成分和别名等医学术语信息;
第二,对湿疹数据进行预处理,通过正则表达式提取所有中文文本,过滤掉网页标签等元素;
第三,使用jieba库的load_userdict方法加载第一步中导出的中文自定义词典,使用精准分词lcut方法对第二步中提取出的中文文本进行分词;
第四,为提升统计效率,根据中文停用词表进行停用词过滤,并将最终结果保存到文件中;
第五,基于中文分词结果,采用统计学的方法统计各医学术语出现的频次。
通过以上步骤对湿疹诊疗方案进行提取和统计后,得到了湿疹常用药物的频次统计结果,如表3所示。第1列为药物类型,第2列是药物在知识库中的实例名称,从湿疹知识图谱药物实例的label属性值中读取药物的主要成分以及别名,第3列是各药物实例的合计频次统计结果,其值等于成分频次和别名频次的总和。
表3湿疹常用药物的频次统计结果
通过词频计算式(1)按类别统计激素类药物、抗过敏类药物中每种药物的词频,进而分析各类别药物中哪些药物的受关注度或者使用率更高,计算结果如附图5所示。
实验结果:
基于表3和附图5的结果,可以得出以下结论:
1、在图5(a)所示的激素类药物中,尤卓尔的频次最高,合计461次,约占所有激素类药物的56%,其次为艾洛松,合计217次,约占所有激素类药物的27%,这两种激素类药物的频次远远高于其他激素类药物;
2、在图5(b)所示的抗过敏药物中,扑尔敏片出现的词频最高,占82%。合计频次32次,整体上来看所有抗过敏药物出现的频次远低于激素类药物,表明在激素类药物作为湿疹主要治疗手段的前提下,抗过敏药物配合使用的频率比较低;
3、抗生素药物主要考查了百多邦这一种药物,出现频次82次,可以看出,相对于抗过敏药物,百多邦作为抗生素消炎药物,更常配合激素类药物共同使用。
上述的这些结论对于为药物选择困扰的公众来说,将提供直观、友好的建议,为最终诊疗方案的确定提供临床决策支持。
相对于院内数据,互联网上的医学数据通常包含有更多的日常保健、护理等非处方类诊疗信息。对于湿疹而言,除了药物治疗之外,日常护肤也是主要的诊疗手段,对应到湿疹知识图谱中的skincareevent实例,属于非处方类医嘱。护肤产品的选择对于诊疗结果有十分重要的作用。目前市场上常见的护肤品牌主要有加州宝宝(californiababy)、强生(johnsonandjohnson)、妙思乐(mustela)、丝塔芙(cetaphil)和郁美净(ymj)等,将这些品牌的护肤产品定义在医嘱实例skincareevent对应的医学术语之中,通过自定义词典进行分词并统计其频次,得到结果如图6所示,可以看出,国产品牌郁美净在网页文本中出现的频次最高,合计877次,占所有品牌频次的75%。可见公众对于国产品牌郁美净作为湿疹护肤产品是非常认可的态度。在国外品牌中,丝塔芙的频次统计结果141次是最高的。
另外,在对各平台分词结果的统计过程中发现:不同的网站平台,用户使用药品名称的习惯呈现明显的差异。对于19楼论坛而言,相对于成分,用户更加倾向于使用别名,例如,氢化可的松乳膏,用户使用别名尤卓尔的概率是96.7%,使用成分氢化可的松的概率仅为3.3%;对于知乎平台,用户更能接受使用成分来代替药品名称,同样是氢化可的松乳膏,用户使用别名尤卓尔的概率是60.8%,使用成分氢化可的松的概率为39.2%,远高于其他互联网平台使用成分的概率。
结果分析:
基于互联网医学数据的辅助诊疗方法主要面向家庭诊疗的需求,适用于像湿疹这样慢性、病程长和易复发的疾病,其诊疗方案以药物和日常护理为主,而且通常存在药物产品种类多难以选择的问题。本发明提出的方法并不局限于湿疹这一种疾病,其对于慢性病、老年人日常保健也能提供对应的辅助诊疗支持。
相对于院内数据,互联网数据的优势主要在于其开放性和日益增长的特性。这些数据公开在网络之上,能够更好的被公众查阅、使用,而不涉及患者隐私的披露问题。基于互联网数据的研究更加侧重于数据的统计结果,而非独立的个体数据。本发明所提出的方法是对基于互联网数据提取辅助诊疗方案的改进,并提供了一个基础的技术框架。随着信息技术的发展及互联网应用的进一步普及,互联网上的医疗数据必将越来越多,也会越来越规范,这部分数据将是对临床数据的重要补充,辅助医学发展。例如实验结果中提到的护理品牌频次分析,这些非处方数据无法从院内系统中获取,却可以通过互联网平台得到,是对临床诊疗方案的重要补充和扩展。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



