
 商标分类
商标分类  商标转让
商标转让 
一种儿童功能性构音音韵异常的AI辅助矫正方法与流程
 2021-01-08 11:01:25|
2021-01-08 11:01:25| 254|
254| 起点商标网
起点商标网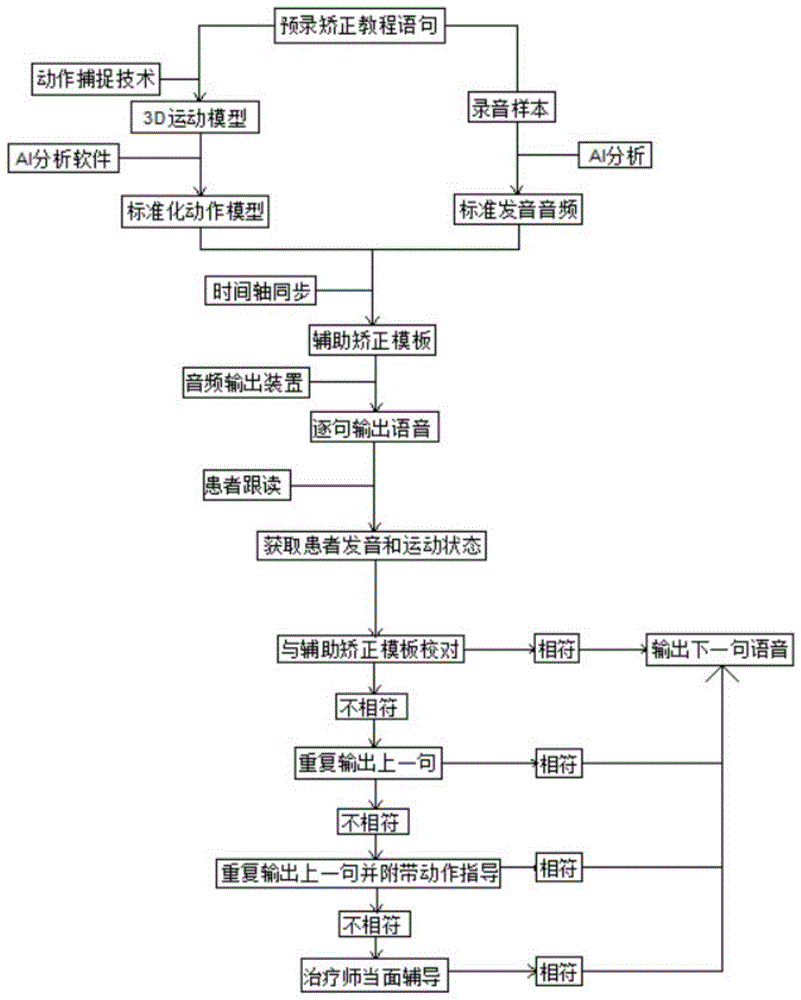
本发明涉及康复医疗领域,具体地说,是一种儿童功能性构音音韵异常的ai辅助矫正方法。
背景技术:
语言是人类表达思想、传递信息、参与社会人际交往的一项重要能力。它通过应用符号达到交流的能力,是复杂神经心理活动的结果,按照语言社会建立的常规来实现。符号包括口头的和书面的以及姿势的,如手势、表情等,由此产生了理解、传入、表达、传出四种基本的语言行为方式。言语是指口语能力,是个体利用语言进行交际的活动过程,需要口唇和舌的协调运动。
构音障碍(articulationdisorders)是指由于发音器官神经肌肉的病变或构造的异常使发声、发音、共鸣、韵律异常。表现为发声困难、发音不准、咬字不清,声响、音调及速率、节律等异常和鼻音过重等言语听觉特征的改变。严重时言不分音、语不成句,难以听懂,最严重时完全不能说话,出现构音不能。
而在儿童群体中最容易发生的构音障碍为功能性构音障碍,相比于由于发音器官神经肌肉的病变或构造的异常导致的病理性构音障碍,功能性构音障碍是指构音错误呈固定状态,但找不到明显原因的构音障碍,比如口吃,说话鼻音重,大舌头,口齿不清等现像,光从舌头,嘴唇,口腔,软腭,硬腭,声带来检查,很难发现有问题.但就是不正常正常说话表达.这就是功能性构音障。功能性构音障碍的发病机理目前还不十分清楚,一般认为是幼儿在学习发音的过程中因某种原因学会了错误的构音动作,而且这种构音动作成为了习惯,再这种情况下,多数幼儿不会注意到自己的发音错误。有资料显示与语音的听觉接受,辨别、认知因素有关。在生活中,有很多小朋友发音不清,影响正常沟通和交流,甚至影响正常入园或者入小学,部分儿童因此还会产生心理上的自卑感和不适感,会极大影响孩子的心理健康,且呈现在儿童群体身上的这种功能性构音障碍如果不及时纠正,孩子的构音障碍随着成长过程中逐渐形成习惯,长大以后会变得极难更正。
现有技术中还没有能够实现以ai技术为支撑的自动化矫正系统,矫正工作一般都是由治疗师为患儿一对一辅导为主。
为解决这一问题,我们需要一种利用ai技术辅助解决儿童功能性构音音韵异常问题的技术方案。
技术实现要素:
发明目的:本发明的目的是针对上述背景技术或现有技术中存在的诸多缺陷与不足,对此进行了改进和创新,目有在于提供一种利用ai技术辅助解决儿童功能性构音音韵异常问题的技术方案,为解决上述问题并达到上述发明目的,本发明通过以下设计结构及技术方案来实现:
一种儿童功能性构音音韵异常的ai辅助矫正方法,包括以下步骤:
s1、选择若干名发音正常的治疗师分别预录矫正教程中的语句,录制时采用动作捕捉技术采集治疗师在发音过程中面部、口腔和胸腔的运动模式并分别建立3d运动模型;
s2、利用ai分析软件分析s1中获取的若干份3d运动模型样本,筛除因个人体型及发音习惯造成的差异化点并将其抹消后进行模型合成,构建标准化动作模型;
s3、将s1中获取的若干份录音样本进行ai分析后选取最为标准的语音语调构建发音标准,通过人声合成的方式构建标准发音音频;
s4、将s2中获得的标准化动作模型和s3中获得的标准发音音频依照时间轴同步后进行合成后再以单句为间隔点进行分割,构建标准化的辅助矫正模板,然后再由治疗师根据辅助矫正模板逐句讲解每个音发音时的胸腔、口腔、舌部和喉部在发声时的动作指导,随后将构建完成的辅助矫正模板录入作为系统处理交互终端中的存储装置中;
s5、进行矫正工作时,患者在系统处理交互终端上按照自身课程进度选择对应的课程,系统处理交互终端从存储装置中释放对应课程的辅助矫正模板并按照时间轴逐句通过音频输出装置进行输出;
s6、音频输出后患者进行跟读,跟读的同时系统处理交互终端上的收音装置和摄像装置同时获取患者的发音和跟读时面部、口腔和胸腔的运动状态并与辅助矫正模板中的标准化动作模型及标准发音音频进行校对,判断二者之间是否相符,若不相符则执行s7,若相符则执行s10;
s7、当患者的发音和跟读时面部、口腔和胸腔的运动状态并与辅助矫正模板中的标准化动作模型及标准发音音频不符合时,系统处理交互终端驱动音频输出装置重新输出上一句语音并由患者再次进行跟读并判断与辅助矫正模板是否相符,若不相符则执行s8,若相符则执行s10;
s8、若s7中再次跟读时患者的发音和跟读时面部、口腔和胸腔的运动状态并与辅助矫正模板中的标准化动作模型及标准发音音频依旧不符合,则再次重新输出上一句语音,语音输出完成后通过音频输出装置输出与这句语音对应的发声时的动作指导,患者根据动作指导再次跟读并判断与辅助矫正模板是否相符,若不相符则执行s9,若相符则执行s10;
s9、若还是不相符,则系统处理交互终端会通知可用的治疗师对患者进行当面辅导,直到患者的发音与辅助矫正模板相符;
s10、当患者的发音与辅助矫正模板相符后,系统处理交互终端从存储装置中释放对应下一语句的辅助矫正模板并通过音频输出装置进行输出。
作为优选的,s1中动作捕捉采集时采集点包括嘴唇、面颊、喉部、颈部、肩部及胸腔处肺部位置。
作为优选的,所述摄像装置包括动作捕捉装置。
作为优选的,s6~9中采用动作捕捉装置捕捉患者在发音时的动作状态后生产临时3d动作模型并与辅助矫正模板中的标准化动作模型进行对比。
作为优选的,s6~10中患者跟读的发音及发声动作录音录像留档,当单元课程完成后将所有单句的录音录像汇总并发送给指定的治疗师,进行人工复核以确保矫正课程的执行效果。
作为优选的,所述系统处理交互终端可以通过网络连接个人pc终端。
本发明相比于现有技术具有以下有益效果:依靠ai算法辅助,通过多样本取样获取更为标准的标准化动作模型和标准发音音频,避免因为治疗师个人倾向导致治疗效果有所偏差,同时利用ai设备设置好训练程序,在进行矫正治疗时可以实现逐句跟读逐句矫正,相比于治疗师人工辅导矫正更为细致,准确度更高,同时可以有效降低人工成本,减轻治疗师工作负担。
附图说明
图1本发明一种儿童功能性构音音韵异常的ai辅助矫正方法的流程结构示意图。
具体实施方式
下面结合附图对本发明作进一步的说明,但并不因此将本发明限制在所述的实施例范围之中。
实施例1:s1、选择50名发音正常的治疗师分别预录矫正教程中的语句,录制时采用动作捕捉技术采集治疗师在发音过程中面部、口腔和胸腔的运动模式并分别建立3d运动模型;
s2、利用ai分析软件分析s1中获取的50份3d运动模型样本,筛除因个人体型及发音习惯造成的差异化点并将其抹消后进行模型合成,构建标准化动作模型;
s3、将s1中获取的50份录音样本进行ai分析后选取最为标准的语音语调构建发音标准,通过人声合成的方式构建标准发音音频;
s4、将s2中获得的标准化动作模型和s3中获得的标准发音音频依照时间轴同步后进行合成后再以单句为间隔点进行分割,构建标准化的辅助矫正模板,然后再由治疗师根据辅助矫正模板逐句讲解每个音发音时的胸腔、口腔、舌部和喉部在发声时的动作指导,随后将构建完成的辅助矫正模板录入作为系统处理交互终端中的存储装置中;
s5、进行矫正工作时,患者在系统处理交互终端上按照自身课程进度选择对应的课程,系统处理交互终端从存储装置中释放对应课程的辅助矫正模板并按照时间轴逐句通过音频输出装置进行输出;
s6、音频输出后患者进行跟读,跟读的同时系统处理交互终端上的收音装置和动作捕捉装置同时获取患者的发音和跟读时面部、口腔和胸腔的运动状态,采用动作捕捉装置捕捉患者在发音时的动作状态后生产临时3d动作模型,并与辅助矫正模板中的标准化动作模型及标准发音音频进行校对,判断与标准化动作模型及标准发音音频相符;
s7、当患者的发音与辅助矫正模板相符后,系统处理交互终端从存储装置中释放对应下一语句的辅助矫正模板并通过音频输出装置进行输出。
实施例2:s1、选择50名发音正常的治疗师分别预录矫正教程中的语句,录制时采用动作捕捉技术采集治疗师在发音过程中面部、口腔和胸腔的运动模式并分别建立3d运动模型;
s2、利用ai分析软件分析s1中获取的50份3d运动模型样本,筛除因个人体型及发音习惯造成的差异化点并将其抹消后进行模型合成,构建标准化动作模型;
s3、将s1中获取的50份录音样本进行ai分析后选取最为标准的语音语调构建发音标准,通过人声合成的方式构建标准发音音频;
s4、将s2中获得的标准化动作模型和s3中获得的标准发音音频依照时间轴同步后进行合成后再以单句为间隔点进行分割,构建标准化的辅助矫正模板,然后再由治疗师根据辅助矫正模板逐句讲解每个音发音时的胸腔、口腔、舌部和喉部在发声时的动作指导,随后将构建完成的辅助矫正模板录入作为系统处理交互终端中的存储装置中;
s5、进行矫正工作时,患者在系统处理交互终端上按照自身课程进度选择对应的课程,系统处理交互终端从存储装置中释放对应课程的辅助矫正模板并按照时间轴逐句通过音频输出装置进行输出;
s6、音频输出后患者进行跟读,跟读的同时系统处理交互终端上的收音装置和动作捕捉装置同时获取患者的发音和跟读时面部、口腔和胸腔的运动状态,采用动作捕捉装置捕捉患者在发音时的动作状态后生产临时3d动作模型,并与辅助矫正模板中的标准化动作模型及标准发音音频进行校对,判断与标准化动作模型及标准发音音频不相符;
s7、系统处理交互终端驱动音频输出装置重新输出上一句语音并由患者再次进行跟读并判断出与辅助矫正模板相符;
s8、系统处理交互终端从存储装置中释放对应下一语句的辅助矫正模板并通过音频输出装置进行输出。
实施例3:s1、选择50名发音正常的治疗师分别预录矫正教程中的语句,录制时采用动作捕捉技术采集治疗师在发音过程中面部、口腔和胸腔的运动模式并分别建立3d运动模型;
s2、利用ai分析软件分析s1中获取的50份3d运动模型样本,筛除因个人体型及发音习惯造成的差异化点并将其抹消后进行模型合成,构建标准化动作模型;
s3、将s1中获取的50份录音样本进行ai分析后选取最为标准的语音语调构建发音标准,通过人声合成的方式构建标准发音音频;
s4、将s2中获得的标准化动作模型和s3中获得的标准发音音频依照时间轴同步后进行合成后再以单句为间隔点进行分割,构建标准化的辅助矫正模板,然后再由治疗师根据辅助矫正模板逐句讲解每个音发音时的胸腔、口腔、舌部和喉部在发声时的动作指导,随后将构建完成的辅助矫正模板录入作为系统处理交互终端中的存储装置中;
s5、进行矫正工作时,患者在系统处理交互终端上按照自身课程进度选择对应的课程,系统处理交互终端从存储装置中释放对应课程的辅助矫正模板并按照时间轴逐句通过音频输出装置进行输出;
s6、音频输出后患者进行跟读,跟读的同时系统处理交互终端上的收音装置和动作捕捉装置同时获取患者的发音和跟读时面部、口腔和胸腔的运动状态,采用动作捕捉装置捕捉患者在发音时的动作状态后生产临时3d动作模型,并与辅助矫正模板中的标准化动作模型及标准发音音频进行校对,判断与标准化动作模型及标准发音音频不相符;
s7、系统处理交互终端驱动音频输出装置重新输出上一句语音并由患者再次进行跟读并判断出与辅助矫正模板不相符;
s8、再次重新输出上一句语音,语音输出完成后通过音频输出装置输出与这句语音对应的发声时的动作指导,患者根据动作指导再次跟读并判断出与辅助矫正模板相符;
s9、系统处理交互终端从存储装置中释放对应下一语句的辅助矫正模板并通过音频输出装置进行输出。
实施例4:s1、选择50名发音正常的治疗师分别预录矫正教程中的语句,录制时采用动作捕捉技术采集治疗师在发音过程中面部、口腔和胸腔的运动模式并分别建立3d运动模型;
s2、利用ai分析软件分析s1中获取的50份3d运动模型样本,筛除因个人体型及发音习惯造成的差异化点并将其抹消后进行模型合成,构建标准化动作模型;
s3、将s1中获取的50份录音样本进行ai分析后选取最为标准的语音语调构建发音标准,通过人声合成的方式构建标准发音音频;
s4、将s2中获得的标准化动作模型和s3中获得的标准发音音频依照时间轴同步后进行合成后再以单句为间隔点进行分割,构建标准化的辅助矫正模板,然后再由治疗师根据辅助矫正模板逐句讲解每个音发音时的胸腔、口腔、舌部和喉部在发声时的动作指导,随后将构建完成的辅助矫正模板录入作为系统处理交互终端中的存储装置中;
s5、进行矫正工作时,患者在系统处理交互终端上按照自身课程进度选择对应的课程,系统处理交互终端从存储装置中释放对应课程的辅助矫正模板并按照时间轴逐句通过音频输出装置进行输出;
s6、音频输出后患者进行跟读,跟读的同时系统处理交互终端上的收音装置和摄像装置同时获取患者的发音和跟读时面部、口腔和胸腔的运动状态并与辅助矫正模板中的标准化动作模型及标准发音音频进行校对,判断二者之间是否相符,若不相符则执行s7,若相符则执行s10;
s7、音频输出后患者进行跟读,跟读的同时系统处理交互终端上的收音装置和动作捕捉装置同时获取患者的发音和跟读时面部、口腔和胸腔的运动状态,采用动作捕捉装置捕捉患者在发音时的动作状态后生产临时3d动作模型,并与辅助矫正模板中的标准化动作模型及标准发音音频进行校对,判断与标准化动作模型及标准发音音频不相符;
s7、系统处理交互终端驱动音频输出装置重新输出上一句语音并由患者再次进行跟读并判断出与辅助矫正模板不相符;
s9、系统处理交互终端会通知可用的治疗师对患者进行当面辅导,直到患者的发音与辅助矫正模板相符;
s10、当患者的发音与辅助矫正模板相符后,系统处理交互终端从存储装置中释放对应下一语句的辅助矫正模板并通过音频输出装置进行输出;
s11、患者跟读的发音及发声动作录音录像留档,当单元课程完成后将所有单句的录音录像汇总并发送给指定的治疗师,进行人工复核以确保矫正课程的执行效果。
实施例5:s1、选择50名发音正常的治疗师分别预录矫正教程中的语句,录制时采用动作捕捉技术采集治疗师在发音过程中面部、口腔和胸腔的运动模式并分别建立3d运动模型;
s2、利用ai分析软件分析s1中获取的50份3d运动模型样本,筛除因个人体型及发音习惯造成的差异化点并将其抹消后进行模型合成,构建标准化动作模型;
s3、将s1中获取的50份录音样本进行ai分析后选取最为标准的语音语调构建发音标准,通过人声合成的方式构建标准发音音频;
s4、将s2中获得的标准化动作模型和s3中获得的标准发音音频依照时间轴同步后进行合成后再以单句为间隔点进行分割,构建标准化的辅助矫正模板,然后再由治疗师根据辅助矫正模板逐句讲解每个音发音时的胸腔、口腔、舌部和喉部在发声时的动作指导,随后将构建完成的辅助矫正模板录入作为系统处理交互终端中的存储装置中;
s5、进行矫正工作时,患者在个人pc终端上进行操作,通过网络连接在在系统处理交互终端上并按照自身课程进度选择对应的课程,系统处理交互终端从存储装置中释放对应课程的辅助矫正模板并按照时间轴逐句通过音频输出装置进行输出;
s6、音频输出后患者进行跟读,跟读的同时系统处理交互终端上的收音装置和摄像装置同时获取患者的发音和跟读时面部、口腔和胸腔的运动状态并与辅助矫正模板中的标准化动作模型及标准发音音频进行校对,判断二者之间是否相符,若不相符则执行s7,若相符则执行s10;
s7、当患者的发音和跟读时面部、口腔和胸腔的运动状态并与辅助矫正模板中的标准化动作模型及标准发音音频不符合时,系统处理交互终端驱动音频输出装置重新输出上一句语音并由患者再次进行跟读并判断与辅助矫正模板是否相符,若不相符则执行s8,若相符则执行s10;
s8、若s7中再次跟读时患者的发音和跟读时面部、口腔和胸腔的运动状态并与辅助矫正模板中的标准化动作模型及标准发音音频依旧不符合,则再次重新输出上一句语音,语音输出完成后通过音频输出装置输出与这句语音对应的发声时的动作指导,患者根据动作指导再次跟读并判断与辅助矫正模板是否相符,若不相符则执行s9,若相符则执行s10;
s9、若还是不相符,则系统处理交互终端会通知可用的治疗师对患者进行当面辅导,直到患者的发音与辅助矫正模板相符;
s10、当患者的发音与辅助矫正模板相符后,系统处理交互终端从存储装置中释放对应下一语句的辅助矫正模板并通过音频输出装置进行输出。
实施例1~4中是患者直接在注入康复中心、医院等医疗环境中进行矫正治疗时多阶段的治疗流程,实施例5为患者处于居家环境中进行远程矫正治疗的使用场景。
本发明的技术方案体现出以下优点:(1)依靠ai算法辅助,通过多样本取样获取更为标准的标准化动作模型和标准发音音频,避免因为治疗师个人倾向导致治疗效果有所偏差,同时利用ai设备设置好训练程序,在进行矫正治疗时可以实现逐句跟读逐句矫正,相比于治疗师人工辅导矫正更为细致,准确度更高,同时可以有效降低人工成本,减轻治疗师工作负担;
(2)也可以引入线上教育,只要有网络或者相应设备,可以随时随地开展学习,从而实现了多场景矫正治疗执行,便于患者的日常复习巩固;
(3)实现了ai辅助治疗与治疗师矫正治疗的协同工作,有效提高了矫正治疗的效率与准确性。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



