
 商标分类
商标分类  商标转让
商标转让 
用于控制火箭的着陆过程的方法与流程
 2021-02-13 14:02:00|
2021-02-13 14:02:00| 361|
361| 起点商标网
起点商标网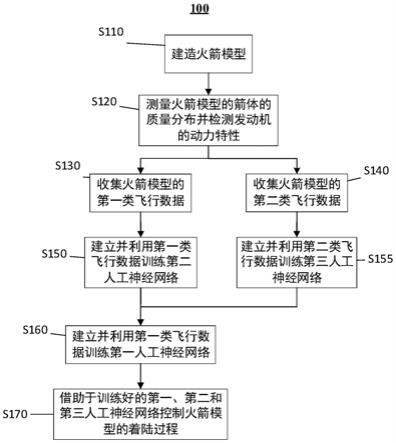
[0001]
本发明涉及火箭领域。特别地,本发明涉及一种用于控制火箭的着陆过程的方法。
背景技术:
[0002]
可回收火箭是一种可以实现重复利用的航天发射运载器。现有的可回收火箭的技术难点在于着陆阶段的控制,因其不仅需要按照预定的落点精准软着陆,而且还要求着陆时速度趋近于0。在现有技术中,为了使探月航天器实现软着陆,一般使用重力转弯制导等控制方式。现有的可回收火箭在近地面处,一般使用基于pid或凸优化的算法进行控制。但着陆段往往面临着复杂的空气动力和火箭与地面之间的作用力等相互作用,这些相互作用难以用简单的物理公式计算出。
[0003]
现有的制导算法具有较为严格的理论和物理依据,但物理模型中包含大量假设,存在不精确性。基于pid的控制方法在实践中有着长期应用,但参数的调节需要大量工程经验,难以实现对极端环境和突变环境的自适应。基于数值方法的控制又难以做到实时和鲁棒。因此,现有建模方法和控制技术在火箭在着陆段的控制存在一定缺陷,难以满足精确性和实时性的要求。
[0004]
进一步而言,在近地面处,火箭所受到的垂直方向的作用力为f=mg+f
residual
,其中mg代表火箭自身的重力,f
residual
代表除重力以外的其它形式的作用力的合力,例如空气阻力、风力,甚至包括与特定障碍物的相互作用力。但是这些其它形式的作用力不仅难以测量,而且由于具有很大的随机性而难以通过现有的计算方法来预估。
[0005]
因此,期待提供一种能在考虑火箭所受到的其它形式的作用力的基础上精确且实时地控制火箭的着陆过程的技术方案。
技术实现要素:
[0006]
本发明的目的通过一种用于控制火箭的着陆过程的方法来实现,所述方法至少包括以下步骤:
[0007]
i)使得火箭在近地面空间内在不同的环境状态下通过手动控制的方式平稳着陆并记录着陆过程中产生的第一类飞行数据;
[0008]
ii)建立并利用所收集的第一类飞行数据训练第一人工神经网络,第一人工神经网络被训练成能计算出火箭在着陆过程中在到达各位置点处时在遭遇不同的环境状态情况下的实时控制策略,第一人工神经网络的输入参数包括火箭在当前时刻的位置r
n
和当前风速w
n
,输出参数包括用于操控火箭的动力系统的实时控制参数值u
n
;和
[0009]
iii)在火箭启动自动着陆过程后,经训练的第一人工神经网络依据火箭的实时位置和实时风速确定出实时控制参数值u
n
,并且依据确定出的实时控制参数值u
n
操控火箭的动力系统,直至火箭完成着陆
[0010]
在此需要说明的是,在本文的上下文中,除非有相反地描述,否则术语“火箭”可以广义地理解成包括真实的火箭、模型火箭、玩具火箭、仿真火箭、虚拟火箭等各种可能形式
的火箭。
[0011]
根据本发明的一可选实施例,所述方法还包括:建立并利用所收集的第一类飞行数据训练第二人工神经网络,第二人工神经网络被训练成能基于火箭在当前时刻的位置r
n
和当前风速w
n
计算出火箭在当前时刻的理想速度v
n*
和理想加速度a
n*
。
[0012]
根据本发明的一可选实施例,第二人工神经网络输出的火箭在当前时刻的理想速度v
n*
和理想加速度a
n*
被第一人工神经网络调用,以用作第一人工神经网络的输入参数。
[0013]
根据本发明的一可选实施例,所收集的第一类飞行数据被分成第一子集和第二子集,其中,第一子集用作第一人工神经网络的训练集,而第二子集用作第二人工神经网络的训练集。
[0014]
根据本发明的一可选实施例,所述方法还包括:
[0015]
i
’
)使得火箭在近地面空间内在不同的环境状态下以随机控制参数值飞行并记录飞行过程中产生的第二类飞行数据;和
[0016]
ii
’
)建立并利用所收集的第二类飞行数据训练第三人工神经网络,第三人工神经网络被训练成能基于火箭在当前时刻的位置r
n
和控制参数值u
n
以及当前风速w
n
计算出火箭在下一时刻的预测加速度a
n+1
’
。
[0017]
根据本发明的一可选实施例,第三人工神经网络输出的火箭在下一时刻的预测加速度a
n+1
’
被第一人工神经网络调用,以用作第一人工神经网络的输入参数。
[0018]
根据本发明的一可选实施例,第一类和第二类飞行数据均包括飞行过程中各时刻火箭的运动学数据和控制参数数据以及环境状态数据。
[0019]
根据本发明的一可选实施例,实时控制参数值u
n
包括风扇转速和/或发动机推力。
[0020]
根据本发明的一可选实施例,所述方法还包括:借助于火箭的导航模块计算出火箭在下一时刻应当到达的位置坐标r
n+1
,该位置坐标r
n+1
被第一人工神经网络调用,以用作第一人工神经网络的输入参数。
[0021]
根据本发明的一可选实施例,采用以下方式执行步骤iii):将第一人工神经网络所输出的实时控制参数值u
n
提供给用于操控火箭的动力系统的至少一个动力部件的控制模块。
[0022]
通过本发明,实现了:基于深度学习的控制可以更好地描述火箭在近地面处所受的复杂作用力,且能够推广到未知受力的情况(如突发的阵风)。训练好的神经网络在树莓派上运行,可以实现毫秒级的控制,相比传统控制方法,满足精确性和实时性要求。
[0023]
从说明书、附图和权利要求书中,本发明主题的其他优点和有利实施例是显而易见的。
附图说明
[0024]
本发明的更多特征及优点可以通过下述参考附图的具体实施例的详细说明来进一步阐述。所述附图为:
[0025]
图1示出根据本发明的一示例性实施例的用于控制火箭的着陆过程的控制设备的示意性结构图;
[0026]
图2示出根据本发明的一示例性实施例的制导模块的示意性结构图;
[0027]
图3示出根据本发明的一示例性实施例的用于控制火箭的着陆过程的方法的流程
图;
[0028]
图4示出根据本发明的一示例性实施例的第一人工神经网络的示意图;
[0029]
图5示出根据本发明的一示例性实施例的第二人工神经网络的示意图;
[0030]
图6示出根据本发明的一示例性实施例的第三人工神经网络的示意图;
[0031]
图7示出根据本发明的一示例性实施例的用于控制火箭的着陆过程的闭环控制流程;和
[0032]
图8示出根据本发明的一示例性实施例的用于控制火箭的着陆过程的方法的一个步骤的流程图。
具体实施方式
[0033]
为了使本发明所要解决的技术问题、技术方案以及有益的技术效果更加清楚明白,以下将结合附图以及多个示例性实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,而不是用于限定本发明的保护范围。在附图中,相同或类似的附图标记指代相同或等价的部件。
[0034]
图1示出根据本发明的一示例性实施例的用于控制火箭的着陆过程的控制设备1的示意性结构图。控制设备1配置成能使火箭返回预定的落地位置。控制设备1包括导航模块10,导航模块10配置成能基于火箭的运动目的地、例如落地位置由火箭在当前时刻n的位置r
n
计算出火箭在下一时刻n+1应该到达的位置r
n+1
。
[0035]
控制设备1还包括制导模块20,制导模块20配置成基于由导航模块10计算出的火箭在下一时刻n+1应该到达的位置r
n+1
计算出用于控制火箭的至少一个功能部件、尤其是诸如风机和发动机的动力部件的实时控制策略。
[0036]
在一示例性实施例中,制导模块20被编程为包括将在下文予以详细描述的第一、第二和第三人工神经网络21、22和23,如图2所示。
[0037]
控制设备1还包括控制模块30,控制模块30配置成响应于由制导模块20计算出的实时控制策略操控火箭的相应的功能部件,例如使风机改变转速和/或使发动机改变输出功率。
[0038]
根据本发明的一示例性实施例,控制设备1可以至少部分地集成在火箭箭体内。特别地,控制模块30可以作为火箭控制器集成在火箭箭体内。附加地或替代地,控制设备1可以至少部分地作为地面设备与火箭无线通信连接。
[0039]
根据本发明的一示例性实施例,导航模块10、制导模块20和控制模块30可以彼此分立地布置,也可以以任意适当的方式彼此集成。
[0040]
图2示出根据本发明的一示例性实施例的用于控制火箭的着陆过程的方法100的流程图。
[0041]
在步骤s110中,建造火箭模型。
[0042]
根据本发明的一示例性实施例,火箭模型被构造成三自由度火箭模型。
[0043]
接下来,在步骤s120中,测量火箭模型的箭体的质量分布并检测火箭模型的发动机的动力特性并将由此获得的数据提供给控制设备1的制导模块20,以作为制导模块20中的制导计算的基础。
[0044]
根据本发明的一示例性实施例,在制导计算中,火箭模型的动力学方程可以表示
如下:
[0045][0046][0047][0048]
其中,r和v分别表示火箭模型在运动过程中的位置矢量和速度矢量,g表示重力加速度矢量,t表示火箭模型发动机推力矢量,m表示火箭模型的质量,a
d
表示火箭模型所受到的气动阻力矢量,i
sp
表示火箭模型发动机比冲,g0表示地球海平面处的重力加速度常数。
[0049]
在步骤s130中,收集火箭模型的第一类飞行数据,具体是使得火箭模型在近地面空间内在不同的环境状态下通过手动控制的方式平稳着陆并以预定的时间间隔记录着陆过程中产生的第一类飞行数据。示例性地,第一类飞行数据包括飞行过程中各时刻火箭模型的运动学数据和控制参数数据以及环境状态数据。
[0050]
在本发明的一示例中,可以采用以下方式来执行步骤s130:使火箭模型在环境状态能被可控地调节的实验室内飞行。附加地或替代地,可以采用使火箭模型在自然环境中飞行的方式执行步骤s130,因为自然环境的环境状态本身是随时间和空间可变的。
[0051]
在本发明的一示例中,环境状态可以被表征为风速,相应地,所记录的环境状态数据包括风速测量值。为此,火箭模型上装载有用于测量风速的风速传感器。在实验室内执行步骤s130的情况下,可以通过调节实验室内的风速来建立不同的环境状态。在自然环境中执行步骤s130的情况下,可以通过选择不同的飞行时间和飞行地点来建立不同的环境状态。
[0052]
在本发明的一示例中,控制参数是与火箭的相应的功能部件关联的参数,例如风机转速和发动机推力。
[0053]
在本发明的一示例中,被记录的运动学数据包括火箭模型在飞行过程中各时刻的速度、加速度和位置坐标。
[0054]
在步骤s140中,收集火箭模型的第二类飞行数据,具体是使得火箭模型在近地面空间内在不同的环境状态中以随机控制参数值飞行并以预定的时间间隔记录飞行过程中产生的第二类飞行数据。示例性地,第二类飞行数据包括飞行过程中各时刻火箭模型的运动学数据和控制参数数据以及环境状态数据。
[0055]
步骤s140和s130的区别之处仅在于前者是收集随机控制飞行中的飞行数据,而后者是收集手动控制着陆过程中的飞行数据。除此之外,上文对于步骤s130所解释的特征和细节均适用于步骤s140,并由此在此不再予以赘述。
[0056]
进一步而言,所收集的第一和第二类飞行数据应当分别涵盖最大可能的风速范围。在为真实火箭训练将在下文予以详细解释的第一、第二和第三人工神经网络时,所收集的第一和第二类飞行数据可以涵盖真实火箭在预设的着陆过程中所可能经历的各位置点在预设的着陆时间内的所有可能的风速。所述可能的风速例如可以借助于实地测量和/或参考历史气象数据来确定。
[0057]
在本发明的一示例中,用于记录第一类和第二类飞行数据的预定的时间间隔可以
为0.1秒。
[0058]
接下来,在步骤s150中,建立并利用步骤s130中收集的火箭模型的第一类飞行数据训练第二人工神经网络22。第二人工神经网络22用于从大量的第一类飞行数据中学习出火箭模型在到达各位置点处时在遭遇不同的风速情况下的不同的理想速度和理想加速度。
[0059]
在一示例中,如图5所示,第二人工神经网络22的输入参数包括火箭模型在当前时刻n的位置r
n
和当前风速w
n
,输出参数包括火箭模型在当前时刻n的理想速度v
n*
和理想加速度a
n*
。
[0060]
在一示例中,为了训练第二人工神经网络22,可以将第一类飞行数据中的速度数据和加速度数据视为理想速度值和理想加速度值,并由此将第二人工神经网络22的损失函数可以设计成真实的速度、加速度与由第二人工神经网络22计算出的速度、加速度之间的均方误差。附加地或替代地,第二人工神经网络22的损失函数可以设计成归一化的速度、加速度均方误差。
[0061]
接下来,在步骤s160中,建立并利用步骤s130中收集的火箭模型的第一类飞行数据训练第一人工神经网络21。第一人工神经网络21用于从大量的第一类飞行数据中学习出火箭模型在到达各位置点处时在遭遇不同的风速情况下的理想的实时控制策略。实时控制策略例如包括由至少一个控制参数值组成的控制参数值集合。
[0062]
在一示例中,如图4所示,第一人工神经网络21的输入参数包括火箭模型在当前时刻n的位置r
n
和当前风速w
n
,输出参数包括火箭模型在当前时刻n的控制参数值u
n
,比如风扇转速u
1n
和发动机推力u
2n
等。
[0063]
在本发明的一示例中,可以借助于wgs-84坐标系来标定火箭模型的位置r。在这种情况下,记录且被输入第一、第二和第三人工神经网络21、22和23的位置r
n
可以包括x
n
、y
n
和z
n
,其中,x
n
表示在wgs-84坐标系中的x轴上的位置坐标,y
n
表示在wgs-84坐标系中的y轴上的位置坐标,z
n
表示在wgs-84坐标系中的z轴上的位置坐标。此外,也可以采用其它合适的坐标系、例如“wgs84 web墨卡托”和“北京54坐标系”等来标定火箭模型的位置r。
[0064]
附加地,第一人工神经网络21的输入参数除了r
n
和w
n
之外,还可以包括以下数据中的一种或任意多种:
[0065]-v
n
,其代表火箭模型在当前时刻n的实际速度;
[0066]-v
n*
,其代表由第二人工神经网络22计算出的火箭模型在当前时刻n的理想速度;
[0067]-a
n
,其代表火箭模型在当前时刻n的实际加速度;
[0068]-a
n*
,其代表由第二人工神经网络22计算出的火箭模型在当前时刻n的理想加速度;
[0069]-δx
n+1
=x
n+1-xn
,其代表火箭模型从当前时刻n到下一时刻n+1在x轴上的位置变化量;
[0070]-δy
n+1
=y
n+1-y
n
,其代表火箭模型从当前时刻n到下一时刻n+1在y轴上的位置变化量;
[0071]-δz
n+1
=z
n+1-z
n
,其代表火箭模型从当前时刻n到下一时刻n+1在z轴上的位置变化量;
[0072]-m
n
,其代表火箭模型在当前时刻n的实际质量;
[0073]-m
n+1
,其代表火箭模型在下一时刻n+1的质量;和
[0074]-δm
n+1
=m
n+1-m
n
,其代表火箭模型从当前时刻到下一时刻的质量变化量。
[0075]
在一示例中,为了训练第一人工神经网络21,可以将第一类飞行数据中的控制参数数据视为理想控制参数值,并由此将第一人工神经网络21的损失函数可以设计成由第一人工神经网络21计算出的控制参数值和真实控制值的均方误差。
[0076]
在一示例中,可以将步骤s130中收集的第一类飞行数据分成第一子集和第二子集,其中,利用第一子集训练第一人工神经网络21,而利用第二子集训练第二人工神经网络22。
[0077]
可选地,在执行步骤s160之前,可以执行步骤s155:建立并利用步骤s140中收集的火箭模型的第二类飞行数据训练第三人工神经网络23。第三人工神经网络23用于基于火箭模型在当前时刻的测量数据预测火箭模型在下一时刻的加速度。
[0078]
在一示例中,如图6所示,第三人工神经网络23的输入参数包括火箭模型在当前时刻n的位置r
n
、当前风速w
n
和当前控制参数值u
n
,输出参数包括火箭模型在下一时刻n+1的预测加速度a
n+1
’
。
[0079]
附加地,第三人工神经网络23的输入参数还可以包括火箭模型在当前时刻n的速度v
n
,输出参数包括火箭模型在下一时刻n+1的预测速度v
n+1
’
。
[0080]
根据一示例,在训练和使用第一人工神经网络21时,也可以调用来自第三人工神经网络23的输出数据a
n+1
’
和v
n+1
’
以作为第一人工神经网络21的附加的输入数据。
[0081]
在本发明的一示例中,第一、第二和第三人工神经网络21、22和23可以是卷积神经网络等。本发明对此不作限定。
[0082]
图2示出了第一、第二和第三人工神经网络21、22和23三者的一种示例性耦合关系。在训练这三个人工神经网络时,可以一个训练完毕后再训练另一个,也可以彼此跃层耦合地训练。本发明对训练顺序不作限定。
[0083]
然后,在步骤s170中,通过上述控制设备1借助于训练好的第一、第二和第三人工神经网络21、22和23控制火箭模型的着陆过程。
[0084]
进一步而言,步骤s170可以包括(参见图7和8):
[0085]
在步骤s171中,火箭模型响应于着陆指令启动着陆过程,其中,着陆指令包含目标落地位置的坐标r
target
;
[0086]
在步骤s172中,利用装载于火箭模型上的传感器、例如速度传感器、加速度传感器、风速传感器、位置传感器等实时获取代表火箭模型的运动学状态和环境状态的测量数据;
[0087]
在步骤s173中,导航模块10基于目标落地位置的坐标r
target
根据所测量的火箭模型在当前时刻n的位置r
n
确定火箭模型在下一时刻n+1应该到达的位置r
n+1
,例如x
n+1
、y
n+1
和z
n+1
;
[0088]
在步骤s174中,经训练的第二人工神经网络22基于火箭模型在当前时刻n的位置r
n
和当前风速w
n
计算火箭模型在当前时刻n的理想速度v
n*
和理想加速度a
n*
;经训练的第三人工神经网络23基于火箭模型在当前时刻n的位置r
n
、风速w
n
、控制参数u
n
和速度v
n
计算出火箭模型在下一时刻n+1的预测加速度a
n+1
’
和预测速度v
n+1
’
;经训练的第一人工神经网络21基于当前的测量数据(例如v
n
、a
n
、r
n
、w
n
、x
n
、y
n
、z
n
和/或m
n
)和来自导航模块10的输出数据(例如x
n+1
、y
n+1
、z
n+1
和/或m
n+1
)并调用第二和第三人工神经网络的输出数据(例如v
n*
、a
n*
、
a
n+1
’
和/或v
n+1
’
)确定火箭模型的实时控制参数值u
n
,并且,确定出的实时控制参数值u
n
被提供给控制模块30;
[0089]
接下来,在步骤s175中,控制模块30以实时控制参数值u
n
操控火箭模型的功能部件;
[0090]
然后,在步骤s176中判断火箭模型是否着陆。如果火箭模型已着陆,则结束方法100;如果还未着陆,则不断重复执行步骤s172至s175,直至火箭模型成功着陆。
[0091]
尽管上文所描述的方法100是用于控制火箭模型的着陆过程,但是其也可以适用于其它形式的火箭,比如真实的可回收火箭、玩具火箭、仿真火箭、虚拟火箭等。
[0092]
在本发明的一示例中,第二和第三人工神经网络22和23可以被省略。
[0093]
在本发明的一示例中,第一、第二和第三人工神经网络中相继的两个时刻n+1和n的时间间隔可以设置为0.1秒。
[0094]
尽管一些实施例已经被说明,但是这些实施例仅仅是以示例的方式予以呈现,而没有旨在限定本发明的范围。所附的权利要求和它们的等价形式旨在覆盖落在本发明范围和精神内的所有改型、替代和改变。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除
 热门咨询
热门咨询




tips