
 商标分类
商标分类  商标转让
商标转让 
一种用于潜水全面罩的实时信息交流装置的制作方法
 2021-02-10 00:02:35|
2021-02-10 00:02:35| 385|
385| 起点商标网
起点商标网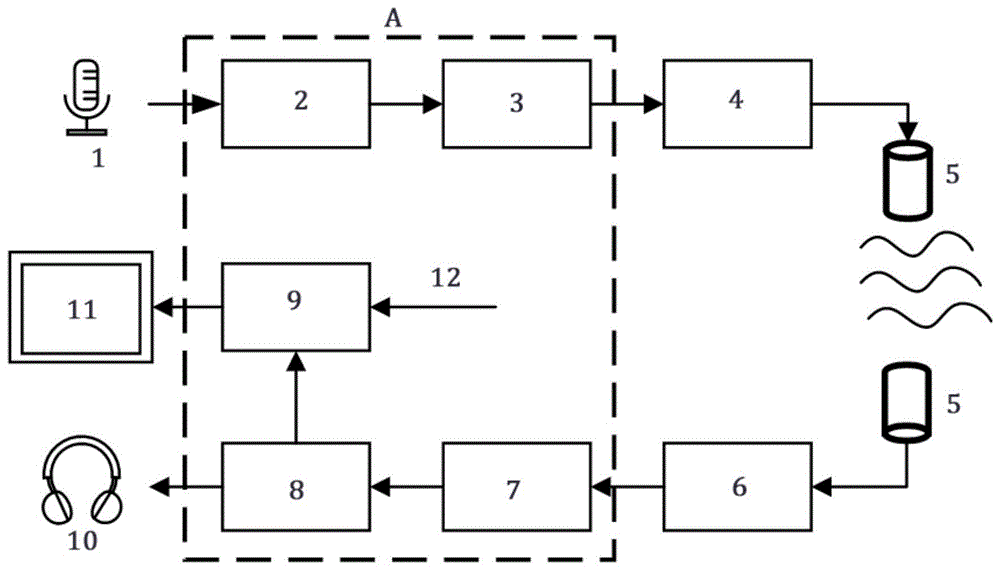
本发明属于水声通信,尤其是涉及一种用于潜水全面罩的实时信息交流装置。
背景技术:
水下蛙人或潜水员在水下作战作业时,需要解决看、听、说、行等难题,但是水下环境与陆上环境差异很大,通信不畅,信息交流不便,具有看、听、说能力的智能潜水全面罩自问世以来得到了潜水行业的青睐,能够极大地降低水下蛙人或潜水员水下作战作业时的风险。中国专利cn208915400u公开一种适配通讯装置的潜水面罩,将防水无线通讯模块集成到潜水面罩中,在发挥潜水面罩原有的保障潜水员呼吸顺畅作用的前提下,加入的防水通讯模块可进一步保障潜水员的安全。中国专利cn209290642u针对潜水员自身携带设备状态信息显示问题,公开一种操作方便的潜水信息显示目镜,将水下设备的各类显示信息实时显示在佩戴于面罩上的潜水目镜上,解放潜水员的双手,让各类水下设备的显示直投眼前,大大方便潜水员的水下作业。然而,要使潜水全面罩真正具备看、听、说的实时交互能力还需解决以下两个问题。首先是语音实时传输问题,其次是话音信息的提取问题。迄今为止,水声通信仍然是为业界所认可,最具灵活性和可行性的水下通信方案,但是水声带宽窄,通信可靠性不高,尤其实时语音所需求的数kbps的传输速率(如常用的g.729语音编码需要8kbps的传输速率),这一在陆地无线环境下能够轻松达成的通信速率在水声环境下却捉襟见肘。其次,面罩语音还受水下环境、潜水员自身呼吸等干扰,播放的语音可懂度不高,出现话音信息提取不准确等问题。针对语音实时传输问题,中国专利cn103310793a采用低速率语音编码技术实现了一种水声实时数字语音通信方法,在该方法中,水声通信系统仅需要提供大于600bps的传输速率就能够令收发双方进行实时语音通信,该方法没有考虑系统集成度问题,不以潜水全面罩作为应用背景,不以信息提取为目的。针对话音信息提取问题,杜桂明(杜桂明.基于神经网络的面罩语音识别方法研究[d].河北工业大学,2018)从解决海洋噪声干扰入手,将语音增强算法和语音识别算法级联起来,先对带噪面罩语音做增强处理,然后对增强后的面罩语音进行识别。该文献提出的算法其处理对象是面罩环境下的原始语音,不涉及传输问题。中国专利cn105845135a公开一种机器人系统的声音识别系统,本地语音编码后经过远程解码和语音识别,然后再生成操作指令,此操作指令通过网络传输至本地多媒体模块后执行来相应操作。该专利最大的特点是在云端进行语音识别。
目前,市场上还未有能够用于潜水全面罩,方便潜水员进行实时信息交流的装置。
技术实现要素:
本发明的目的在于针对现有技术存在的有限带宽下的实时语音通信和话音可懂度不高情况下的信息提取问题,提供一种用于潜水全面罩的实时信息交流装置。
本发明包括麦克风与扬声器模块、低速率语音编解码模块、信号调制解调模块、信号传输模块、语音识别模块和潜水信息显示目镜模块;所述麦克风与扬声器模块包括麦克风和扬声器,所述低速率语音编解码模块包括语音编码单元和语音解码单元,所述信号调制解调模块包括信号调制单元和信号解调单元,所述信号传输模块包括功率放大单元、水声换能器和前放单元,所述潜水信息显示目镜模块设有潜水信息显示目镜;
所述麦克风接语音编码单元的输入端,语音编码单元的输出端接信号调制单元的输入端,信号调制单元的输出端接功率放大单元,功率放大单元的输出端接水声换能器,水声换能器的输出端接前放单元,前放单元的输出端接信号解调单元的输入端,信号解调单元的输出端接语音解码单元,语音解码单元的输出端分别连接扬声器和语音识别模块,语音识别模块的输出端接潜水信息显示目镜;
所述麦克风用于实时接收潜水员的语音信号并输出语音数据至语音编码单元;
所述扬声器用于播放语音解码模块输出的语音数据流;
所述语音编码单元用于运行语音压缩算法,对量化后的语音数据流进行编码,输出低速率的语音编码数据流;所述语音解码单元用于对解调后的传输数据流进行解码,输出经过传输后的语音数据流。
所述信号调制单元用于对语音编码数据流进行信号调制处理,输出可在水声换能器规定频带内传输的波形信号;所述信号解调单元用于接收由前放单元输出的模拟信号,模数转换后进行信号解调处理,获得经过传输后的语音编码数据流;
所述功率放大单元用于对信号调制单元输出的波形进行功率放大,驱动水声换能器;所述水声换能器用于实现声-电转换,将具有特定带宽的输入电信号转换为相应频带的声信号,将接收端输入的声信号转换为电信号;前放单元用于放大水声换能器输出的微弱信号,输出到信号解调单元;
所述语音识别模块用于接受语音解码输入,对经过编码、传输并解码后的语音信号进行识别,采用语音识别模型对输入音频进行分析,并将识别的结果以文字的形式输出;
所述潜水信息显示目镜模块用于接受语音识别模块的输入,将语音识别模块输出的文字显示在潜水信息显示目镜上。
所述低速率语音编解码模块、信号调制解调模块、语音识别模块可集成于多核嵌入式芯片上,可采用市售商品,譬如国外德州仪器的am5708,博世用于物联网的mems传感器,greenwaves公司的gap9,国内瑞芯微公司的rk3228h,rk3399等芯片。
基于多核嵌入式芯片,可搭载嵌入式ai软件开发平台,如openailab的aid,在aid平台上包含了深度学习框架tengine,能够采用离线学习获得的模型进行推理输出。
本发明首先针对通信带宽有限,数据传输速率不高问题,采用了甚低速率语音编码技术,为潜水员提供了实时语音交互能力;其次,针对恶劣信道条件下经过语音编码后的语音可懂度不高问题,采用基于机器学习的语音识别技术对接收语音进行识别,转换为文本内容显示在潜水显示目镜上,为潜水员提供全面的信息交互;最后,此装置集成于多核嵌入式芯片上,采用微型机器学习方法,离线学习模型,在线推理输出,使装置小型化。本发明综合低速率语音编码、语音识别技术和已经面世的潜水显示目镜,为潜水员发明一种能够进行实时语音通信和信息显示的装置,该装置集成于潜水全面罩中,解放潜水员双手,为水下作业提供便利,保障潜水员安全。
附图说明
图1是本发明原理框图。
图2是离线语音识别训练系统原理框图。
图3是语音识别的实现流程框图。
具体实施方式
以下实施例将结合附图对本发明作进一步的说明。
图1是本发明所提出的用于潜水全面罩的实时信息交流装置原理框图,本发明实施例包括麦克风1、语音编码单元2、信号调制单元3、功率放大单元4、水声换能器5、前放单元6、信号解调单元7、语音解码单元8、语音识别模块9、扬声器10和潜水信息显示目镜11;所述麦克风1接语音编码单元2的输入端,语音编码单元2的输出端接信号调制单元3的输入端,信号调制单元3的输出端接功率放大单元4,功率放大单元4的输出端接水声换能器5,水声换能器5的输出端接前放单元6,前放单元6的输出端接信号解调单元7的输入端,信号解调单元7的输出端接语音解码单元8,语音解码单元8的输出端分别连接扬声器10和语音识别模块9,语音识别模块9的输出端接潜水信息显示目镜11。
所述麦克风1用于实时接收潜水员的语音信号,扬声器10用于播放语音解码模块输出的语音数据流;
所述语音编码单元2用于运行语音压缩算法,对量化后的语音数据流进行编码,输出低速率的语音编码数据流;语音解码单元8用于对解调后的传输数据流进行解码,输出经过传输后的语音数据流。
语音压缩算法的发展,一直致力于在编码比特率尽可能低的情况下,去还原较好的语音质量。按照编码速率的不同,常见的语音压缩算法可划分为高速率(16~64kbps)、中速率(4.8~16kbps)、低速率(2.4~4.8kbps)、甚低速率(小于2.4kbps)等,更低的编码速率能够在带宽有限的水声信道中获得更为可靠的传输,但是语音质量也随之下降。为了适配信号传输模块的数据通信速率,本发明采用甚低速率语音压缩算法,使信号传输模块能够实时传输语音编码数据流。
所述信号调制单元3对语音编码数据流进行信号调制处理,输出可在水声换能器规定频带内传输的波形信号;信号解调单元7接收由前放单元6输出的模拟信号,模数转换后进行信号解调处理,获得经过传输后的语音编码数据流。所采用的信号调制技术是正交频分复用(ofdm)调制技术,ofdm技术作为多载波调制的一种,能够有效地对抗水声信道多径时延扩展引起的符号间干扰。
所述信号传输模块包括功率放大单元4、水声换能器5和前放单元6。功率放大单元对信号调制单元输出的波形进行功率放大,驱动水声换能器;水声换能器实现声-电转换,将发送端输入的电信号转换为声信号,将接收端输入的声信号转换为电信号;前放单元放大水声换能器输出的微弱信号,输出到信号解调单元。所述水声换能器5可采用小型的水声换能器。
所述语音识别模块9,接受语音解码输入,对经过编码、传输并解码后的语音信号进行识别,采用语音识别模型12对输入音频进行分析,并将识别的结果以文字的形式输出。语音识别采用微型机器学习方法,基于通过离线方式训练好的语音识别模型12推理得到文字输出。语音识别通常包括信号处理、特征提取和声学模型三部分,信号处理和特征提取可以视作音频数据的预处理部分,实际研究中用到的语音片段都有噪声存在,所以在正式进入声学模型之前,需要通过消除噪声和信号增强等预处理技术,将信号从时域转化到频域,为之后的声学模型提取有效的特征向量。之后,声学模型会将预处理部分得到的特征向量转化为声学模型得分,并得到一个语言模型得分,最后解码搜索阶段会针对声学模型得分和语言模型得分进行综合,将得分最高的词序列作为最后的识别结果。随着人工智能的兴起,循环神经网络、长短时记忆人工神经网络(lstm)、编码-解码框架、注意力机制等基于深度学习的声学模型被广泛运用。基于深度学习的语音识别技术也正在逐渐成为语音识别领域的核心技术。
所述潜水信息显示目镜模块,接受语音识别模块的输入,将语音识别模块输出的文字显示在潜水信息显示目镜11上。
所述低速率语音编解码模块、信号调制解调模块、语音识别模块集成于多核嵌入式芯片上,市场上有多款商用芯片可实现以上模块功能,譬如国外德州仪器的am5708,博世用于物联网的mems传感器,greenwaves公司的gap9,国内瑞芯微公司的rk3228h,rk3399等芯片;基于这些多核嵌入式芯片,搭载嵌入式ai软件开发平台,如openailab的aid,在aid平台上包含了深度学习框架tengine,能够采用离线学习获得的语音识别模型进行推理输出。
所述水声换能器用于完成电声转换,发送端将输入的电信号转换为声信号,接收端将输入的声信号转换为电信号。
所述前端信号调理器放大接收端水声换能器输出的信号,并滤除带外噪声。
以下给出潜水员工作时的信号流程及原理:
步骤1,在发送端,需要通信时,潜水员朝面罩麦克风1讲话,麦克风1用于实时接收潜水员的语音信号并输出语音信号。
步骤2,语音信号传输到面罩中集成的多核嵌入式芯片a上,多核嵌入式芯片a集成语音编码单元2、语音解码单元8、信号调制单元3、信号解调单元7和语音识别单元9;首先,芯片上的语音编码单元对语音进行编码,压缩待传输的原始语音数据流,得到语音编码数据流,芯片上集成的信号调制单元对语音编码单元输出的数据流进行调制后送往功率放大器。
步骤3,经过功率放大器放大后的信号传送至水声换能器;
步骤4,水声换能器完成电-声转换后,输出放大的声信号到水声信道中传播。
步骤5,在接收端,水声换能器接收水中的声音信号,完成声-电转换,输出微弱的电信号。
步骤6,水声换能器输出的微弱电信号经过前放单元进行信号放大后,输入到多核嵌入式芯片的信号解调单元。
步骤7,芯片上的信号解调单元对放大后的信号进行解调,得到传输后的语音编码数据流,编码数据流再经过芯片上的语音解码单元合成语音信号。语音信号输入到芯片上的语音识别模块,同时输入到芯片外部的扬声器设备。
步骤8,扬声器播放输入语音信号,同时语音识别模块利用离线训练获得的语音识别模型对输入音频进行分析,并将识别的结果以文本的形式显示在面罩的潜水显示目镜上。
图2是离线语音识别训练系统原理框图,通过离线训练得到语音识别模型,以下对其进行详细说明。
步骤1,利用麦克风接收外部的语音信号。
步骤2,基于usrp和gnuradio构建图1中多核嵌入式芯片所完成的语音编码单元、语音解码单元、信号调制单元、信号解调单元、语音识别单元。其中在发送端,gnuradio中的信号调制进行数字基带信号调制,usrpn210主板完成信号调制的模数转换功能,子板lftx将信号调制成射频信号;
步骤3,功率放大器对射频信号进行功率放大。放大后的信号经过水声换能器转换成声信号后发射到水中;
步骤4,利用接收端的水声换能器接收外界的声信号,并将其转化为电信号。电信号经过前端信号调理器进行放大,并滤除带外噪声后传输到lftx射频前端接收子板中;
步骤5,lfrx子板将射频信号调制到中频信号。中频信号经过usrpn210完成模数转换并且调制到基带信号后传输到gnuradio。gnuradio中的信号解调模块对基带信号进行ofdm解调得到语音编码数据流。编码数据流再经过语音解码模块解调得到语音数据流后传输到语音识别模块;
步骤6,语音识别模块提取语音数据流中的mfcc作为特征向量,将提取的特征输入到由bi-lstm组成的rnn神经网络进行训练,最后得到用以识别的语音识别模型。
本实施例基于通用软件无线电平台usrp和开源软件框架gnuradio,搭建一个离线语音识别训练系统,用来训练语音识别模型。离线语音识别训练系统包含麦克风、usrp、gnuradio(pc机)、水声换能器、功率放大器和前端信号调理器。
所述麦克风用于接收语音信号。
所述usrp是由ni公司旗下ettusresearch开发生产的通用软件无线电外设,结合基于主机的处理器,利用现场可编程门阵列(fpga)和射频(rf)前端,可帮助用户快速设计,原型化和部署无线系统。usrp包含母板和子板,本离线训练系统采用n210作为主板,lftx和lfrx分别作为射频前端发射子板和接收子板。
所述gnuradio是一个免费的开源软件开发工具包,它提供各种信号处理模块来实现用户自定义的软件无线电。gnuradio通常与各种现有的通用无线电外设或者低成本rf硬件一起使用,来实现软件定义无线电,或者不使用外接硬件,利用其相关模块实现无线通信相关仿真。它被业余爱好者、学术研究机构和商业机构广泛用于研究和构建无线通信系统。gnuradio部署于pc机上,完成低速率语音编解码、信号调制解调、基于机器学习的语音识别模型训练等。
在gnuradio软件框架上可以实现低速率语音编码解码,实现信号调制解调,实现语音识别算法,语音编码模块运行语音压缩算法,对量化后的语音数据流进行压缩,输出低速率的语音编码数据流。语音解码模块对解调后的传输数据流进行解码,输出经过传输后的语音数据流。信号调制单元对语音编码数据流进行信号调制处理,输出可在水声换能器规定频带内传输的波形信号;前端信号调理器输出的模拟信号,模数转换后进行信号解调处理,获得经过传输后的语音编码数据流。所采用的信号调制技术是ofdm调制技术。语音识别算法将语音经过预处理后提取其梅尔倒谱系数(mfcc)特征向量,利用双向长短时记忆单元的递归结构进行声学建模,在语音识别后输出文本信息及识别正确率,此方法不仅可以解决梯度消失的问题,还可以同时利用当前和未来的信息。这意味着在语音识别中,双向长短时结构可获取语音特征序列上下文所含隐藏信息的能力。
所述功率放大器用于放大lftx子板输出的调制信号,驱动发送端水声换能器。
所述前端信号调理器放大接收端水声换能器输出的信号,并滤除带外噪声。
图3是图1和2中的语音识别模块的具体实现流程框图,以下对语音识别过程进行详细说明。
步骤1:获取接收端解调后的音频数据;
步骤2:对音频进行预处理,其中包括预加重、分帧、加窗;
步骤3:通过fft变换将音频数据从时域转到频域;
步骤4:在频域中计算音频的能量谱;
步骤5:将得到的能量谱通过mel滤波转为mel频域;
步骤6:将mel频域的能量谱取对数后获得音频的mfcc;
步骤7:利用已知文本内容的音频,作为训练集音频,由已知的文本内容组成语言模型,并将训练集音频的mfcc及对应文本作为训练集输入到由bi-lstm组成的rnn神经网络中进行训练用于建立声学模型;
步骤8:若训练误差大于阈值,则返回第一步,若训练误差小于阈值,输出声学模型,并将未知文本内容的测试音频的mfcc送入声学模型进行识别,最后结合语言模型输出识别结果。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



