
 商标分类
商标分类  商标转让
商标转让 
用于早期胃癌检测的标志物组合、试剂盒及其应用的制作方法
 2021-02-02 17:02:32|
2021-02-02 17:02:32| 424|
424| 起点商标网
起点商标网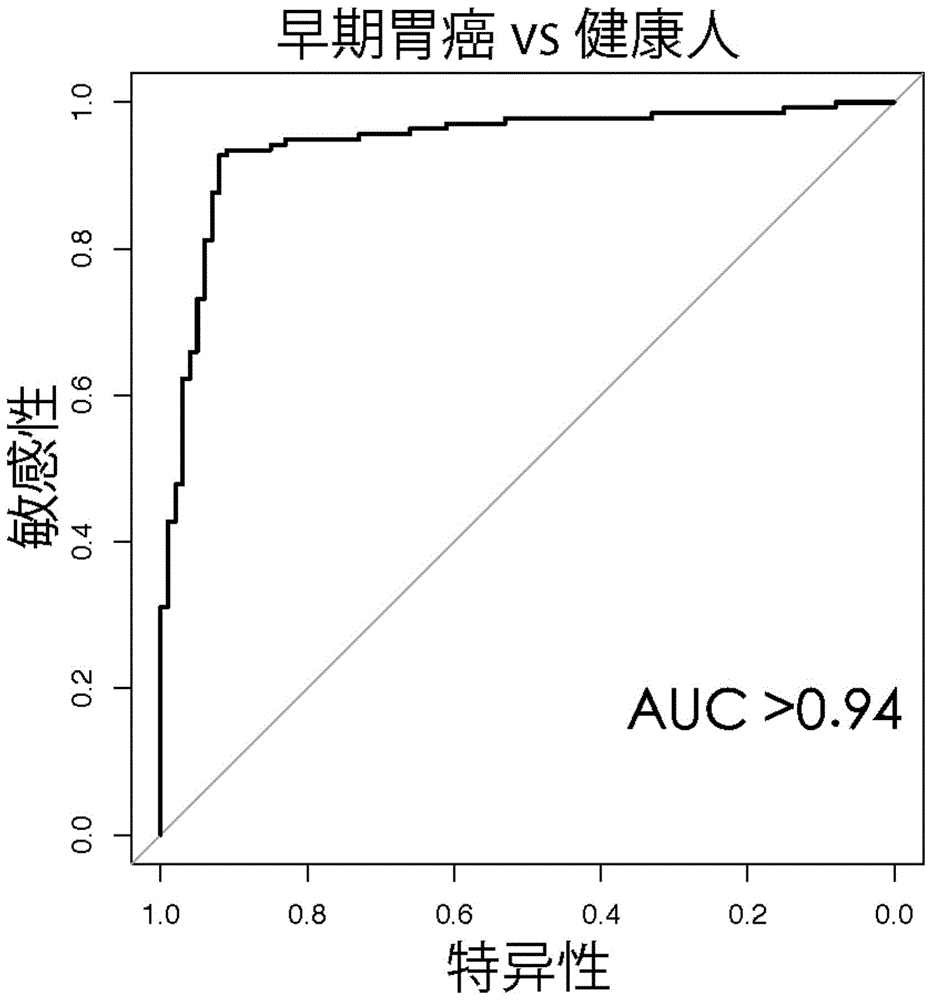
本发明涉及一种用于早期胃癌检测的标志物组合、试剂盒及其应用,属于生物技术领域。
背景技术:
胃癌是全世界最常见的恶性肿瘤之一,也是死亡率最高的恶性肿瘤之一。据近年来的统计资料显示,在中国,胃癌长期居于各类癌症死亡的三大主要原因之一。目前,显著改善的手术技术以及各种新近开发的治疗方法都使得早期胃癌患者的治疗效果得到了显著的提升,生存期亦有了明显的增加;但晚期胃癌患者的生存期仍然很不乐观,五年生存率远低于50%,且长期的高昂治疗费用为家庭和社会带来了沉重的负担。因此,胃癌的早期检测对于胃癌的治疗至关重要。
胃镜是目前诊断胃癌最为常用的工具。早期胃癌在胃镜下的表现包括黏膜颜色异常和表面血管消失、黏膜层凹陷或凸起增厚、溃疡周边不正常的黏膜褶皱、等等;在需要的情况下,亦可以切取胃部组织进行切片活检。尽管胃镜检查后进行组织活检是胃癌诊断的金标准,但由于胃镜具有侵入性,常会引起患者的不是与恐惧,症状不明显的患者常常不愿意接受胃镜检查。而症状严重之后再进行胃镜检查,很可能已经处于晚期胃癌阶段。
蛋白标志物可以作为胃癌诊断的参考依据,常用的胃癌蛋白标志物包括癌胚抗原(cea)、糖类抗原19-9(ca19-9)、糖类抗原50(ca50)和胃蛋白酶原等。但是,由于这些常规胃癌蛋白标志物的敏感性/特异性不够高,不适合被单独用作胃癌的诊断标准,对早期胃癌检测更是作用十分有限。
microrna(mirna)是真核生物中的一类内源性的具有调控功能的非编码短rna,其长度一般为19-25个核苷酸。过去的研究表明mirna参与了多重调节途径,包括发育、病毒防御、造血过程、器官形成、细胞增殖与死亡、等等。近年来,mirna的丰度变化与肿瘤发生和发展的密切关系已经在科学界形成了共识并成为了目前的研究热点。大量研究表明,mirna在不同肿瘤中有特异性的表达,根据一些mirna的表达状态可以区分正常与肿瘤组织。此外,也有不少研究证实,循环mirna可以作为包括癌症在内的各种疾病的诊断标志物,例如中山大学研发的基于血清mirna的肝癌检测试剂盒。然而,目前关于循环mirna作为胃癌诊断标志物的研究仍然存在一些不足,比如(1)很大一部分研究只是挑选了前人报道的在胃癌组织中表达失调的mirna作为候选指标,而这些mirna在血清中并不一定是最优的选择,以及(2)一些研究使用了microarray进行了mirna标志物的初步筛选,但与二代测序相比microarray的信噪比较差,因此其筛选出的mirna标志物并不一定是优选。因此,目前仍然有必要研发具有临床应用价值的早期胃癌检测标志物以及相对应的方法和试剂盒,以用于胃癌高风险人群的肿瘤检测,便于及早进行临床干预。
技术实现要素:
本发明的目的在于提供一种用于早期胃癌检测的标志物组合、试剂盒及其应用,其对于早期胃癌而言,具有更强的检测能力和检测准确性,并且操作难度较低。
为达到上述目的,本发明提供如下技术方案:一种早期胃癌标志物组合,所述早期胃癌标志物组合包括以下在人体血清中可检测的mirna:hsa-mir-17-5p,hsa-mir-18a-5p,hsa-mir-19b-3p,hsa-mir-20a-5p,hsa-mir-21-5p,hsa-mir-25-5p,hsa-mir-27a-5p,hsa-mir-29c-5p,hsa-mir-93-5p,hsa-mir-100-5p,hsa-mir-103a-3p,hsa-mir-106a-5p,hsa-mir-106b-5p,hsa-mir-148a-5p,hsa-mir-183-5p,hsa-mir-199a-3p,hsa-mir-218-5p,hsa-mir-222-5p,hsa-mir-337-3p,hsa-mir-365a-3p,hsa-mir-423-5p,hsa-mir-425-5p,hsa-mir-486-5p,hsa-mir-487b-3p,hsa-mir-532-3p,hsa-mir-590-5p,hsa-mir-615-3p,hsa-mir-744-5p。
本发明还提供一种用于早期胃癌检测的试剂盒,所述试剂盒用于检测人体血清中包括所述的早期胃癌标志物组合的水平,所述试剂盒包括衔接子ra3和衔接子ra5;所述衔接子ra3的序列如seqidno:1所示,所述衔接子ra5的序列包括固有结构s1-s2-s3,其中s1的碱基序列如seqidno:2所示,s2是长度为11~15个的随机核苷酸序列n11-n15,s2定义为随机标签序列,s3是长度为4个的固定碱基,且s3选自acga、ccga、cgau、cgua、cguu、gacg、gcca、gcgu、ggaa、gucg、gucu中的一种,所述s3的序列如seqidno:3至seqidno:13所示。
进一步地,所述衔接子ra3与mirna的3’端连接,所述衔接子ra5与mirna的5’端连接。
进一步地,还包括ra3反转录引物、ra3区域引物、ra5区域引物、超纯水、酶以及缓冲液;所述ra3反转录引物的序列如seqidno:14所示,所述ra3区域引物的序列如seqidno:15所示,所述ra5区域引物的序列如seqidno:16所示。
本发明还提供一种根据所述的早期胃癌标志物组合在用于制备早期胃癌检测试剂盒中的应用。
进一步地,所述早期胃癌标志物组合在早期胃癌患者血清中的水平显著高于在健康人血清中的水平。
进一步地,其逻辑回归公式为:
logit(p)=-8283.62+1.25×rpmhsa-mir-17-5p+7.45×rpmhsa-mir-18a-5p+2.14×rpmhsa-mir-19b-3p+1.64×rpmhsa-mir-20a-5p+0.23×rpmhsa-mir-21-5p+17.23×rpmhsa-mir-25-5p+12.39×rpmhsa-mir-27a-5p+38.27×rpmhsa-mir-29c-5p+0.81×rpmhsa-mir-93-5p+0.66×rpmhsa-mir-100-5p+2.08×rpmhsa-mir-103a-3p+33.45×rpmhsa-mir-106a-5p+3.05×rpmhsa-mir-106b-5p+17.95×rpmhsa-mir-148a-5p+1.95×rpmhsa-mir-183-5p+19.81×rpmhsa-mir-199a-3p+16.28×rpmhsa-mir-218-5p+47.91×rpmhsa-mir-222-5p+8.63×rpmhsa-mir-337-3p+5.95×rpmhsa-mir-365a-3p+2.91×rpmhsa-mir-423-5p+5.90×rpmhsa-mir-425-5p+10.45×rpmhsa-mir-486-5p+13.38×rpmhsa-mir-487b-3p+18.26×rpmhsa-mir-532-3p+14.89×rpmhsa-mir-590-5p+11.13×rpmhsa-mir-615-3p+7.03×rpmhsa-mir-744-5p;
其中,rpm为血清mirna的水平,p是罹患早期胃癌的概率,以logit(p)=0为分类阈值;当输出值大于0时,评估为阳性,患有早期胃癌;当输出值小于0时,评估为阴性,不患早期胃癌。
本发明还提供一种根据所述的试剂盒在人体血清mirna水平检测中的应用,采用如下测序文库的制备方法:
步骤1、提供所述试剂盒,从受试者处获得外周血,分离血清并从中提取游离rna作为受试样品;
步骤2、将衔接子ra3与步骤1中所述受试样品进行连接反应,形成核酸-衔接子ra3复合物,其中,所述衔接子ra3的序列如seqidno:1所示,且所述衔接子ra3与mirna的3’端连接;
步骤3、将衔接子ra5与步骤2中所述核酸-衔接子ra3复合物进行连接反应,形成衔接子ra5-核酸-衔接子ra3复合物,所述衔接子ra5的序列包括固有结构s1-s2-s3,其中s1的碱基序列如seqidno:2所示,s2是长度为11~15个的随机核苷酸序列n11-n15,s2定义为随机标签序列,s3是长度为4个的固定碱基,且s3选自acga、ccga、cgau、cgua、cguu、gacg、gcca、gcgu、ggaa、gucg、gucu中的一种,所述s3的序列如seqidno:3至seqidno:13所示,且所述衔接子ra5与mirna的5’端连接;
步骤4、将步骤3中所述衔接子ra5-核酸-衔接子ra3复合物与ra3反转录引物混合,进行反转录反应,得到dna第一链,其中,所述ra3反转录引物的序列如seqidno:14所示;
步骤5、将步骤4中所述dna第一链与ra3区域引物和ra5区域引物进行混合,获得扩增产物,其中,所述ra3区域引物的序列如seqidno:15所示,所述ra5区域引物的序列如seqidno:16所示;
步骤6、将步骤5中所述扩增产物进行6%聚丙烯酰胺凝胶电泳,胶块经染色后在紫外灯下识别各dna条带,割取所需的目的dna片段并回收,得到制备完成的测序文库。
进一步地,步骤6中,所述目的dna片段的长度为mirna的长度+测序接头的长度+s2的长度+s3的长度,其中,所述mirna的长度为15~30bp,且所述mirna平均长度为22bp,测序接头的长度为120bp,s2的长度为11~15bp,s3的长度为4bp。
进一步地,还包括如下分析方法:
步骤1、提供所述测序文库,对所述测序文库进行片段长度范围检测和浓度定量后上机测序并获得下机数据,再通过质控工具对所述下机数据进行数据质控和预处理以得到去除了低质量序列和测序接头的有效数据,随后将所述衔接子ra5中的所述随机标签序列以及固定碱基从有效数据的序列5’端移除,再将其与参考基因组序列比对,获得定位于所述参考基因组序列的位置信息;
步骤2、所述位置信息以及对应的所述随机标签序列,对结果pcr重复的序列去除,再将获得的已去除pcr重复的序列的位置与所述参考基因组中的mirna位置相比较,确定所述受试样品中所有mirna的表达量,即为所述血清mirna的水平。
与现有技术相比,本发明的有益效果在于:
1)相较于现有mirna标志物组合,本发明得到的mirna标志物组合覆盖的mirna更广,对于早期胃癌有更高的检测能力,检测可靠性经过了两个验证组的独立验证,且基于二代测序的实验成本亦处于可接受的范围;
2)使用本发明的mirna标志物组合,以及血清样本中的mirna标志物水平,采用较为简单的回归公式,即可判断个体是否罹患早期胃癌,计算方法并不复杂,因此可被普通技术人员较快掌握;
3)本发明中长度为11~15个随机核苷酸序列作为定量化标签,是衔接子ra5的一部分,与样品核酸片段连接之后,每个特定的碱基排列组合便成为每一条核酸片段的标签,不会在建库、测序以及后期生物信息学分析过程中丢失或混淆,在通过去除pcr重复序列的精准定量分析过程中起到关键性的作用,能够对血清mirna进行更好的定量,提高检测的准确性;
4)外周血样品更容易获得,临床可操作性强且创伤很小,有利于待测者接受这类检测,因此具有广阔的应用前景;
5)血清mirna的稳定性较好,含量也较大,提取、建库和测序的难度相对较低,所需都是常规实验技术以及容易购买到的试剂和药品。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
图1为本发明实施例1中mirna标志物组合对应的roc曲线图。
图2为本发明实施例2中mirna标志物组合对应的roc曲线图。
图3为本发明实施例3中mirna标志物组合对应的roc曲线图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
下列实施例中未注明具体条件的实验方法,按照常规实验条件,例如sambrook等人的分子克隆实验室手册(newyork:coldspringharborlaboratorypress,1989)中所述的条件,或按照制造厂商所建议的条件。除非另外说明,否则百分比和份数按重量计算。
本发明的早期胃癌标志物组合,包含了以下28个mirna:hsa-mir-17-5p,hsa-mir-18a-5p,hsa-mir-19b-3p,hsa-mir-20a-5p,hsa-mir-21-5p,hsa-mir-25-5p,hsa-mir-27a-5p,hsa-mir-29c-5p,hsa-mir-93-5p,hsa-mir-100-5p,hsa-mir-103a-3p,hsa-mir-106a-5p,hsa-mir-106b-5p,hsa-mir-148a-5p,hsa-mir-183-5p,hsa-mir-199a-3p,hsa-mir-218-5p,hsa-mir-222-5p,hsa-mir-337-3p,hsa-mir-365a-3p,hsa-mir-423-5p,hsa-mir-425-5p,hsa-mir-486-5p,hsa-mir-487b-3p,hsa-mir-532-3p,hsa-mir-590-5p,hsa-mir-615-3p,hsa-mir-744-5p。其中,所述的早期胃癌是指局限于胃黏膜层及黏膜下层的胃癌,所述mirna均指成熟mirna(下同)。
具体而言,本发明通过以下步骤获得了上述的28个mirna标志物组合:
(1)收集未经治疗的早期胃癌患者以及健康人的血清组成训练组,通过对血清mirna的二代测序以及数据分析确定可以区分早期胃癌和非癌对照的mirna标志物组合;
(2)收集未经治疗的早期胃癌患者以及健康人的血清组成验证组1,验证上述mirna标志物组合对于早期胃癌的检测效果;
(3)收集未经治疗的早期胃癌患者、胃溃疡患者以及健康人的血清组成验证组2,再次验证上述mirna标志物组合对于早期胃癌的检测效果。
另一方面,本发明还提供了一种基于上述28个mirna的早期胃癌评估方法,用于评估待测者是否罹患早期胃癌。进一步,本发明使用逻辑回归方法得到了如下的基于血清mirna水平的评估方法:
logit(p)=-8283.62+1.25×rpmhsa-mir-17-5p+7.45×rpmhsa-mir-18a-5p+2.14×rpmhsa-mir-19b-3p+1.64×rpmhsa-mir-20a-5p+0.23×rpmhsa-mir-21-5p+17.23×rpmhsa-mir-25-5p+12.39×rpmhsa-mir-27a-5p+38.27×rpmhsa-mir-29c-5p+0.81×rpmhsa-mir-93-5p+0.66×rpmhsa-mir-100-5p+2.08×rpmhsa-mir-103a-3p+33.45×rpmhsa-mir-106a-5p+3.05×rpmhsa-mir-106b-5p+17.95×rpmhsa-mir-148a-5p+1.95×rpmhsa-mir-183-5p+19.81×rpmhsa-mir-199a-3p+16.28×rpmhsa-mir-218-5p+47.91×rpmhsa-mir-222-5p+8.63×rpmhsa-mir-337-3p+5.95×rpmhsa-mir-365a-3p+2.91×rpmhsa-mir-423-5p+5.90×rpmhsa-mir-425-5p+10.45×rpmhsa-mir-486-5p+13.38×rpmhsa-mir-487b-3p+18.26×rpmhsa-mir-532-3p+14.89×rpmhsa-mir-590-5p+11.13×rpmhsa-mir-615-3p+7.03×rpmhsa-mir-744-5p;
其中,rpm为血清mirna的水平,p是罹患早期胃癌的概率,以logit(p)=0为分类阈值;当输出值大于0时,评估为阳性(即患有早期胃癌);当输出值小于0时,评估为阴性(即未患早期胃癌)。
具体的,上述血清mirna的水平通过以下的mirna测序文库制备和分析方法得到,其步骤如下:
(1)从待测者获得10ml以上的外周血,分离血清并从中提取50-500ng的游离rna;
(2)提供一种用于连接步骤(1)中所述的rna样品3’端的衔接子ra3,ra3的序列为5’-tggaattctcgggtgccaagg-3’;
(3)提供一种用于连接步骤(1)中所述rna样品5’端的衔接子ra5,衔接子ra5的序列包括固有结构s1-s2-s3,其中s1的碱基序列为5’-guucagaguucuacaguccgacgauc-3’,s2是长度为11~15个的随机核苷酸序列n11-n15,s2定义为随机标签序列,s3是长度为4个的固定碱基,且s3选自acga、ccga、cgau、cgua、cguu、gacg、gcca、gcgu、ggaa、gucg、gucu中的一种,所述s3的序列如seqidno:3至seqidno:13所示;
(4)取一定量步骤(1)所述的rna样品与适量步骤(2)所述的衔接子ra3混合进行连接反应,从而形成核酸-衔接子ra3的复合物;
(5)将步骤(4)中获得的核酸-衔接子ra3的复合物与衔接子ra5进行连接反应,从而形成衔接子ra5-核酸-衔接子ra3的复合物;
(6)将步骤(5)获得的衔接子ra5-核酸-衔接子ra3的复合物与特异性结合于衔接子ra3的反转录引物rtprimer混合,进行反转录反应,得到dna第一链,其中反转录引物rtprimer的序列为5’-ccttggcacccgagaattcca-3’;
(7)将步骤(6)获得的样品与特异性结合于衔接子ra3相应区域的引物primer1和特异性结合于衔接子ra5相应区域的引物primer2进行混合,进行pcr反应,获得扩增产物;其中,primer1的序列为5’-caagcagaagacggcatacgagatgtcgtgatgtgactggagttccttggcacccgagaattcca-3’,primer2的序列为5’-aatgatacggcgaccaccgagatctacacgttcagagttctacagtccga-3’,其中,primer1中的8个碱基“gtcgtgat”为index序列(索引序列,用于区分不同样品的测序数据);进一步的,所述的index序列至少还可用以下十种index序列替换:accactgt,tggatctg,ccgtttgt,tgctgggt,gaggggtt,aggttggg,gtgtggtg,tggtcaca,ttgaccct,ccactcct,如seqidno:17至seqidno:26所示;
(8)将步骤(7)获得的扩增产物进行6%聚丙烯酰胺凝胶电泳,胶块经染色后在紫外灯下识别各dna条带,割取所需的目的dna片段并回收,此即制备完成的测序文库;所述的目的dna片段的长度为mirna的长度+测序接头的长度+s2的长度+s3的长度,其中,所述的mirna的长度为15~30bp,且所述的mirna平均长度为22bp,测序接头的长度为120bp,s2的长度为11~15bp,s3的长度为4bp。所以,理论上,目的dna片段的长度分布在22bp+120bp+s2+4bp±10bp之间,因此,切胶范围设定为22bp+120bp+s2+4bp±10bp,即s2+146bp±10bp;
(9)对于步骤(8)获得的测序文库,在使用agilent2100bioanalyzer进行片段长度范围检测以及invitrogenqubit进行浓度定量之后,送至illumina高通量测序平台进行测序,并获得下机数据(英文全称为rawdata);其中,所述测序平台为illuminahiseq、novaseq或nextseq测序平台;进一步的,测序读长在50bp到150bp之间,测序模式为单端测序或者双端测序;
(10)对步骤(9)获得的下机数据,使用质控工具(如fastqc,cutadpat,trimmomatic)进行数据质控和预处理以得到去除了低质量序列和测序接头的有效数据(英文全称为cleandata);随后将ra5中的随机标签序列s2以及固定碱基s3从有效数据的序列5’端移除;随后使用序列比对软件(如bowtie)将得到的序列再比对到参考基因组序列上,获得定位于参考基因组的位置信息;进一步的,参考基因组为人类参考基因组;
(11)根据步骤(10)获得的序列比对位置以及对应的随机标签序列s2,对结果进行pcr重复序列的去除。具体而言,被序列比对软件比对到参考基因组同一位置(即序列的5’和3’端在参考基因组的位置相同)的序列若带有相同的随机标签序列s2,则视为pcr重复,并将其合并为同一条序列;
(12)将步骤(11)中获得的已去除pcr重复的序列的位置与参考基因组中的mirna位置相比较,确定样品中所有mirna的表达量。其中,mirna位置信息取自于mirbase数据库;当某序列的5’端与某mirna的5’端位置一致时,此序列记为此mirna的测序序列;每个mirna表达量rpm(readspermillion)为该mirna测序序列的总量占该样品所有可比对至参考基因组的测序序列总量的百万分比。
(13)使用步骤(12)获得的表达量rpm作为上述血清mirna的水平。实施例1:使用训练组样本确定血清mirna标志物组合
发明人于2015年3月至2018年2月采集了未经治疗的早期胃癌患者的外周静脉血样品共138例,每一例样品均含有20ml的外周血,其中男性91例,女性47例,年龄分布为31–78岁;同期,发明人采集了健康人外周静脉血样品共100例,每一例样品均含有20ml的外周血,其中男性66例,女性34例,年龄分布为32–78岁;这两组样品满足性别和年龄匹配的原则。
对于每一份外周血样品,均采用以下方法进行血清mirna的文库制备和测序数据分析,从而得到血清mirna的水平:
(1)外周血样品在用干燥采血管采集后于4℃静置半小时以上,随后400g,4℃离心10分钟取上清,进一步1800g,4℃离心10分钟取上清,得到血清样品,保存于-80℃冰箱中;
(2)使用qiagenmirneasyserum/plasmakit(货号:217184)从上述血清样品抽提50–200ng的血清游离rna,用超纯水(无dna酶和rna酶,下同)稀释至总体积为4μl,并置于200μl薄壁pcr管中;
(3)在步骤(2)获得的溶液中加入1μl浓度为10μm的衔接子ra3,混匀后于70℃反应2分钟,立即置于冰上冷却;
(4)在步骤(3)获得的溶液中均加入2μlhml(ligationbuffer)(illumina,货号15013206),1μlrnaseinhibitor(illumina,货号15003548),1μlt4rnaligase2deletionmutant(epicentre,货号lr2d11310k)混匀,28℃孵育1小时;
(5)在步骤(4)获得的溶液中均加入1μlstp(stopsolution)(illumina,货号15016304)混匀,28℃孵育15分钟;
(6)取一支新的pcr管,加入1.1μl衔接子ra5(其中s1的碱基序列为5’-guucagaguucuacaguccgacgauc-3’,s2是长度为13的随机核苷酸序列n13,s3选用acga),ra5浓度为10μm,70℃孵育2分钟,反应后立即置于冰上冷却;
(7)在步骤(6)获得的溶液中加入1.1μl10mmatp(illumina,货号15007432),再加入1.1μlt4rna连接酶(illumina,货号1000587)并混匀;
(8)从步骤(7)获得的溶液取3μl加入步骤(5)获得的溶液并混匀,28℃反应1小时;
(9)往步骤(8)获得的溶液中加入1μlrnartprimer(10μm)并混匀,70℃反应2分钟,反应后立即置于冰上冷却;
(10)往步骤(9)获得的溶液中加入2μl5×firststrandbuffer(thermo,货号1889832),0.5μldntpmix(12.5mm,illumina,货号11318102),1μl100mmdtt(thermo,货号1850670),1μlrnaseinhibitor和1μlsuperscriptiireversetranscriptase(thermo,货号2008270)混匀,50℃孵育1小时;
(11)往步骤(10)获得的溶液中加入25μlpml(pcrmix)(illumina,货号15022681),2μlprimer1(10μm)和2μlprimer2(10μm),混匀后进行pcr反应,98℃预变性30s,98℃变性10s,60℃退火30s,72℃延伸15s,执行18个循环后,72℃延伸10min,4℃保存;其中,所有文库primer1序列中的index序列均从gtcgtgat,accactgt,tggatctg,ccgtttgt,tgctgggt,gaggggtt,aggttggg,gtgtggtg,tggtcaca,ttgaccct,ccactcct中选取且使用同样index序列的文库不会混合在一起上机测序;
(12)将步骤(11)获得的pcr产物进行6%聚丙烯酰胺凝胶电泳,电压120v,时间1h,万分之一gelred染液染色5分钟,然后置紫外灯下观察并拍照,割取149~169bp之间的条带并回收,在使用agilent2100bioanalyzer进行片段长度范围检测(片段长度基本分布于149~169bp间)以及invitrogenqubit进行浓度定量(大于1ng/μl)之后,送至illuminanextseq500测序平台进行测序(测序读长为75bp,测序模式为单端测序)并获得下机数据;
(13)对步骤(12)获得的下机数据,使用fastqc,cutadpat和trimmomatic进行数据质控和预处理(使用默认参数)以得到去除了低质量序列和测序接头的有效数据;随后将ra5中的随机标签序列s2以及固定碱基s3从有效数据的序列5’端移除;随后使用序列比对软件bowtie将得到的序列再比对到人类参考基因组序列上(允许最多1个碱基错配),获得定位于参考基因组的位置信息;
(14)根据步骤(13)获得的序列比对位置以及对应的随机标签序列s2,对结果进行pcr重复序列的去除。具体而言,被bowtie比对到参考基因组同一位置(即序列的5’和3’端在参考基因组的位置相同)的序列若带有相同的随机标签序列s2,则视为pcr重复,将其合并为同一条序列,即在后续表达值的计算中只算一条序列;
(15)将步骤(14)中获得的已去除pcr重复的序列的位置与人类参考基因组中的mirna位置相比较,确定样品中所有mirna的表达量。其中,mirna位置信息取自于mirbase数据库;当某序列的5’端与某mirna的5’端位置一致时,此序列记为此mirna的测序序列;每个mirna表达量rpm(readspermillion)为该mirna测序序列的总量占该样品所有可比对至参考基因组的测序序列总量的百万分比;进一步,所述表达量rpm即为血清mirna的水平。
基于血清mirna的水平,发明人使用edger包(r语言包,使用默认参数)找到早期胃癌患者与健康人相比,在前者血清中有显著高表达的42个mirna(p值小于0.05且变化倍数大于2);随后,以这些mirna的水平作为自变量,使用r语言stats包进行逻辑回归建模,采用向后剔除的方法选择自变量,最终确认其中28个mirna的系数具有统计学显著性(p值小于0.05)。将这28个mirna作为用于早期胃癌检测的标志物组合,得到的逻辑回归方程为:
logit(p)=-8283.62+1.25×rpmhsa-mir-17-5p+7.45×rpmhsa-mir-18a-5p+2.14×rpmhsa-mir-19b-3p+1.64×rpmhsa-mir-20a-5p+0.23×rpmhsa-mir-21-5p+17.23×rpmhsa-mir-25-5p+12.39×rpmhsa-mir-27a-5p+38.27×rpmhsa-mir-29c-5p+0.81×rpmhsa-mir-93-5p+0.66×rpmhsa-mir-100-5p+2.08×rpmhsa-mir-103a-3p+33.45×rpmhsa-mir-106a-5p+3.05×rpmhsa-mir-106b-5p+17.95×rpmhsa-mir-148a-5p+1.95×rpmhsa-mir-183-5p+19.81×rpmhsa-mir-199a-3p+16.28×rpmhsa-mir-218-5p+47.91×rpmhsa-mir-222-5p+8.63×rpmhsa-mir-337-3p+5.95×rpmhsa-mir-365a-3p+2.91×rpmhsa-mir-423-5p+5.90×rpmhsa-mir-425-5p+10.45×rpmhsa-mir-486-5p+13.38×rpmhsa-mir-487b-3p+18.26×rpmhsa-mir-532-3p+14.89×rpmhsa-mir-590-5p+11.13×rpmhsa-mir-615-3p+7.03×rpmhsa-mir-744-5p;
其中,rpm为血清mirna的水平,p是罹患早期胃癌的概率,以logit(p)=0为分类阈值,高于0则将待测者判断为早期胃癌,低于0则判断为健康人。基于该回归方程,早期胃癌的检测敏感性为0.93,特异性为0.92。随后,使用r语言rocr包绘制roc曲线(中文全称为受试者工作特征曲线),对应的auc(英文全称为areaundercurve)大于0.94,如图1所示。这说明,上述28个血清mirna组合可以在训练组中将早期胃癌患者与健康人很好的区分开。
实施例2:使用验证组1样品验证mirna标志物组合的效果
发明人于2018年3月至2019年3月采集了未经治疗的早期胃癌患者的外周静脉血样品共61例,每一例样品均含有20ml的外周血,其中男性40例,女性21例,年龄分布为32–76岁;同期,发明人采集了健康人外周静脉血样品共50例,每一例样品均含有20ml的外周血,其中男性32例,女性18例,年龄分布为32–77岁;这两组样品满足性别和年龄匹配的原则。
在训练组中确立的血清mirna标志物组合被用于验证组1的早期胃癌检测。同样的,采用实施例1中的方法进行血清mirna的文库制备和测序数据分析,从而得到血清mirna的水平。使用实施例1中的逻辑回归方程计算logit(p),并以logit(p)=0为分类阈值将待测者进行分类;相应的,验证组1样本的检测敏感性为0.90,特异性为0.90。使用r语言rocr包绘制roc曲线,对应的auc大于0.92,如图2所示。这说明,上述28个血清mirna组合亦可以在验证组1中将早期胃癌患者与健康人进行很好的区分。
实施例3:使用验证组2样品验证mirna标志物组合的效果
发明人于2019年4月至2020年5月采集了未经治疗的早期胃癌患者的外周静脉血样品共51例,每一例样品均含有20ml的外周血,其中男性32例,女性19例,年龄分布为33–79岁;同期,发明人采集了健康人外周静脉血样品共50例,每一例样品均含有20ml的外周血,其中男性33例,女性17例,年龄分布为34–77岁;同期,发明人采集了未经治疗的胃溃疡患者的外周静脉血样品共62例,每一例样品均含有20ml的外周血,其中男性40例,女性22例,年龄分布为34–78岁;这三组样品满足性别和年龄匹配的原则。
在训练组中确立的血清mirna标志物组合被用于验证组2的早期胃癌检测。同样的,采用实施例1中的方法进行血清mirna的文库制备和测序数据分析,从而得到血清mirna的水平。使用实施例1中的逻辑回归方程计算logit(p),并以logit(p)=0为分类阈值将待测者进行分类;在早期胃癌患者对健康人的分析中,得到的检测敏感性为0.92,特异性为0.92,使用r语言rocr包绘制早期胃癌患者对健康人的roc曲线,其auc大于0.93(如图3a所示)。在早期胃癌患者对胃溃疡患者的分析中,得到的检测敏感性为0.88,特异性为0.89,使用rocr包绘制早期胃癌患者对胃溃疡患者的roc曲线,其auc大于0.90(如图3b所示)。这说明,在验证组2中,上述28个血清mirna组合不仅可以将早期胃癌患者与健康人进行很好的区分,亦能将早期胃癌患者与胃溃疡患者进行很好的区分。
综上所述,本发明的有益效果在于:
1)相较于现有mirna标志物组合,本发明得到的mirna标志物组合覆盖的mirna更广,对于早期胃癌有更高的检测能力,检测可靠性经过了两个验证组的独立验证,且基于二代测序的实验成本亦处于可接受的范围;
2)使用本发明的mirna标志物组合,以及血清样本中的mirna标志物水平,采用较为简单的回归公式,即可判断个体是否罹患早期胃癌,计算方法并不复杂,因此可被普通技术人员较快掌握。
3)本发明中长度为11~15个随机核苷酸序列作为定量化标签,是衔接子ra5的一部分,与样品核酸片段连接之后,每个特定的碱基排列组合便成为每一条核酸片段的标签,不会在建库、测序以及后期生物信息学分析过程中丢失或混淆,在通过去除pcr重复序列的精准定量分析过程中起到关键性的作用,能够对血清mirna进行更好的定量,提高检测的准确性;
4)外周血样品更容易获得,临床可操作性强且创伤很小,有利于待测者接受这类检测,因此具有广阔的应用前景;
5)血清mirna的稳定性较好,含量也较大,提取、建库和测序的难度相对较低,且所需都是常规实验技术以及容易购买到的试剂和药品。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
序列表
<110>苏州京脉生物科技有限公司
<120>用于早期胃癌检测的标志物组合、试剂盒及其应用
<160>26
<170>siposequencelisting1.0
<210>1
<211>21
<212>dna
<213>人工序列-衔接子ra3(artificialsequence)
<400>1
tggaattctcgggtgccaagg21
<210>2
<211>26
<212>rna
<213>人工序列-衔接子ra5s1(artificialsequence)
<400>2
guucagaguucuacaguccgacgauc26
<210>3
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>3
acga4
<210>4
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>4
ccga4
<210>5
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>5
cgau4
<210>6
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>6
cgua4
<210>7
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>7
cguu4
<210>8
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>8
gacg4
<210>9
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>9
gcca4
<210>10
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>10
gcgu4
<210>11
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>11
ggaa4
<210>12
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>12
gucg4
<210>13
<211>4
<212>rna
<213>人工序列-衔接子ra5s3(artificialsequence)
<400>13
gucu4
<210>14
<211>21
<212>dna
<213>人工序列-衔接子ra3反转录引物(artificialsequence)
<400>14
ccttggcacccgagaattcca21
<210>15
<211>65
<212>dna
<213>人工序列-衔接子ra3区域引物(artificialsequence)
<400>15
caagcagaagacggcatacgagatgtcgtgatgtgactggagttccttggcacccgagaa60
ttcca65
<210>16
<211>50
<212>dna
<213>人工序列-衔接子ra5区域引物(artificialsequence)
<400>16
aatgatacggcgaccaccgagatctacacgttcagagttctacagtccga50
<210>17
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>17
accactgt8
<210>18
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>18
tggatctg8
<210>19
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>19
ccgtttgt8
<210>20
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>20
tgctgggt8
<210>21
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>21
gaggggtt8
<210>22
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>22
aggttggg8
<210>23
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>23
gtgtggtg8
<210>24
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>24
tggtcaca8
<210>25
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>25
ttgaccct8
<210>26
<211>8
<212>dna
<213>人工序列-索引序列(artificialsequence)
<400>26
ccactcct8
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



