
 商标分类
商标分类  商标转让
商标转让 
番茄miR172a初级体编码小肽miPEP172a的预测、鉴定与原核表达方法与流程
 2021-02-02 15:02:46|
2021-02-02 15:02:46| 360|
360| 起点商标网
起点商标网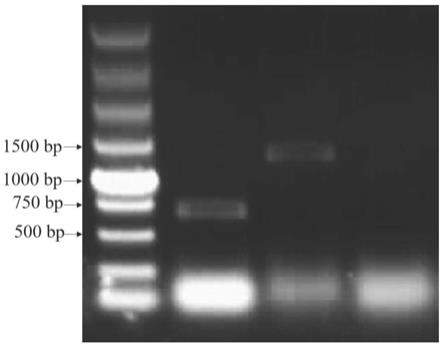
番茄mir172a初级体编码小肽mipep172a的预测、鉴定与原核表达方法
技术领域
[0001]
本发明涉及植物基因工程技术领域,更具体地说,涉及一种由番茄mir172a初级体编码小肽mipep172a的预测、鉴定与原核表达方法。
背景技术:
[0002]
番茄植株在生长过程中,常常受到真菌、卵菌、病毒和细菌等病原体的侵染,引起多种病害,给番茄的生产带来了巨大的损失。近年来,随着设施番茄种植规模的扩大,不同病原菌群间的有性重组机会增多,变异速度加快,导致一些品种的抗性丧失。因此,挖掘番茄抗病分子、查明其作用机制尤为重要。这将有助于番茄优良品种的培育和抗病措施的改善,对提高产量、增加农民收入等都将起到积极的作用。
[0003]
microrna(mirna)是非编码小rna,长度为20
–
24个核苷酸。它在植物体内普遍存在,细胞核中的内源性mirna基因在启动子的驱动下由rna聚合酶ii转录形成初级转录产物pri-mirna(primary mirna transcript),然后在dgcr8或drosha蛋白及其辅助因子pasha的共同作用下被剪切形成具有发夹结构的pre-mirna,再经核质运输体exportin-5将其从细胞核运输到细胞质,经dicer或trbp又被加工成mirna/mirna*双链复合体。随后,解旋的双链复合体中的一条链被选择性的结合到rna介导的沉默复合体risc(rna-induced silencing complex)上形成成熟的mirna。成熟的mirna通过与多个靶基因的互补配对结合,并与ago1的作用来剪切靶基因或阻遏其翻译,在转录或转录后水平调控靶基因的表达,进而影响番茄的抗病及抗逆反应。
[0004]
近年来,随着人们对植物体内mirna研究的不断深入,陆续发现有些pri-mirna能够编码小肽并具备功能,并植物在生长发育过程中发挥着各种调节作用。研究者首次报导了苜蓿pri-mir171b可以编码生成一种能促进相应成熟体mirna表达,进而抑制下游靶基因转录的小肽(micrornas encoded regulatory peptide,mipep)。研究者对拟南芥的多个pri-mirna进行了相关的研究,同样发现了类似的现象。此外,目前的研究均表明pri-mirna5
’
端第一个atg开头的开放阅读框往往是小肽的编码序列。mipep的发现改变了传统观念中pri-mirna不编码的观点,为基因调控研究开辟了新的领域,特别是为mirna的调控提出了新的作用方式。而后续有研究者利用人工合成的mipep172c体外处理大豆激发了mir172c的表达,进而促进了大豆的结瘤过程,这一发现表明mipep还对农业生产具有重要的应用价值。尽管由smorfs编码的小肽在植物生长发育及抗逆、抗病过程中的作用研究已经有不少报道,遗憾的是,对于由pri-mirna编码生成的小肽,我们仍然了解太少。
[0005]
mir172是植物中一类保守的mirna分子,自首次从拟南芥发现至今,已经在许多植物中鉴定得到。该家族主要包括两个成员:mir172a和mir172b。植物中mir172主要靶向一类apetala2(ap2)蛋白,后者为ap2/erf转录因子家族中的一个重要的成员,在植物生长发育及抗逆过程中起着非常重要的作用。对番茄中由mir172初级体所编码的小肽(mipep172a)进行筛选鉴定及表达应用具有重要的理论和生产价值,然而目前现有的对mirna初级体所
编码小肽的鉴定方法成本高昂,以及目前尚无相关的原核表达方法,限制了对其在农业上的生产应用。因此提出一种成本低、能够成规模生产的番茄mir172a初级体所编码小肽的预测、鉴定与原核表达方法成为当务之急。
技术实现要素:
[0006]
本发明提供了一种由番茄mir172a初级体所编码小肽mipep172a的预测、鉴定与原核表达方法,以解决现有的对mirna初级体所编码小肽的鉴定方法成本高昂的问题,以及目前尚未相关的原核表达方法,限制了对其在农业上的生产应用的问题。
[0007]
为了实现上述目的,本发明提供一种番茄mir172a,其成熟体序列如seq id no.1所示,其前体序列如seq id no.2所示,并提供一种对其初级体所编码小肽mipep172a的预测、鉴定与原核表达方法。
[0008]
其中,一种由番茄mir172a初级体编码小肽mipep172a的预测、鉴定方法,包括以下步骤:
[0009]
s1、对mir172a前体序列即seq id no.2设计特异性引物1:
[0010]
上游引物172a-f:ccaagcttggtactagtgcaaatatctacattca;
[0011]
下游引物172a-r:cgggatcccgtctcgtgagtttcaaatagc;
[0012]
s2、以野生型番茄早粉2号的dna以及cdna为模板进行pcr扩增:
[0013]
提取番茄总rna,并作为模板进行反转录合成cdna,再以番茄cdna以及dna为模板,用特异性引物2,进行pcr扩增;
[0014]
所述特异性引物2如下:
[0015]
上游引物172a-1-f:ccaagcttggcttccttcgtttggtattgt;
[0016]
下游引物172a-1-r:cgggatcccggtgagtttcaaatagccagc;
[0017]
上游引物172a-2-f:ccaagcttggcaatagatgtcgtaatccgtg;
[0018]
下游引物172a-2-r:cgggatcccgctcgtgagtttcaaatagcc;
[0019]
上游引物172a-3-f:ccaagcttggtactagtgcaaatatctacattca;
[0020]
下游引物172a-3-r:cgggatcccgtctcgtgagtttcaaatagc;
[0021]
上游引物172a-4-f:aaaggaatcagcagtcttca;
[0022]
下游引物172a-4-r:gctggctatttgaaactcac;
[0023]
上游引物172a-5-f:cttcaattaattaattatagacta;
[0024]
下游引物172a-5-r:gctggctatttgaaactcac;
[0025]
s3、结合mir172a初级体所编码的小肽mipep172a的开放阅读框的预测进行筛选鉴定。
[0026]
优选的,步骤s3中所述开放阅读框的预测标准包括:起始密码子为atg,开放阅读框位于mir172a初级体序列的5
’
端,开放阅读框长度介于12-303个核苷酸,符合三联密码子规则。
[0027]
一种由番茄mir172a初级体编码小肽mipep172a的原核表达方法,包括以下步骤:
[0028]
s1.将mipep172a的候选编码序列连接到载体上,构建原核表达载体;
[0029]
s2.用重组表达质粒转化大肠杆菌感受态细胞;
[0030]
s3.提取被转化的阳性感受态细胞dh5α的质粒转化大肠杆菌bl21;
[0031]
s4.将所述转化的大肠杆菌bl21菌落接种于卡纳霉素浓度为50mg/l的培养基37℃培养8-12h,转接入卡纳霉素浓度为50mg/l的培养基中37℃培养至od600=0.6,再加入异丙基-β-d-硫代半乳糖苷至终浓度为0.5mmol/l,然后诱导,再100℃煮沸10min,在12000转/min下离心10min,取离心上清液,即实现番茄mir172a初级体所编码小肽mipep172a核酸的原核表达。
[0032]
优选的,步骤s2中所述载体为pet32a。
[0033]
优选的,步骤s2中所述大肠杆菌感受态细胞为dh5α。
[0034]
优选的,步骤s4中所述诱导温度为33℃。
[0035]
本发明通过构建表达载体,借由原核表达技术实现对小肽的大量获得,并且大幅度降低现有技术的生产成本。本发明所提出的鉴定预测方法解决了当前对mirna初级体所编码小肽筛选方法的成本问题,使小肽的快速、低价鉴定成为可能,为其他植物中mirna初级体所编码小肽的研究提供了依据;本发明提出的原核表达方法,显著降低了小肽的合成成本,操作简单,对小肽的大量生产应用具有重要价值。
附图说明
[0036]
图1是本发明pre-mir17a前体上游序列的分段pcr琼脂糖凝胶电泳图;
[0037]
图2是本发明mipep172a原核表达样品的sds-page蛋白电泳图。
具体实施方式
[0038]
下面结合附图和实施例对本发明做进一步详细说明。
[0039]
为了使本发明的目的、方案、流程和优点更加清楚明晰,结合实施例对本发明做进一步的详细说明,需要说明的是,此处具体实施例仅作为解释说明本发明,并不用于限定本发明。下述实施例中,如无特殊说明,所使用的实验方法均为常规方法。
[0040]
实施例一
[0041]
番茄mir172a初级体所编码小肽的预测鉴定
[0042]
1.番茄pre-mir172a上游1500bp序列的获得
[0043]
以番茄pre-mir172a的序列为模板,使用blast程序与番茄基因组序列进行比对,比对结果表明pre-mir172a位于第6号染色体的42922097-422922202,据此提取其上游1500bp(42920597-42922096)的序列。前1500bp的dna分子序列如seq id no.3所示。
[0044]
2.番茄pre-mir172a上游序列开放阅读框的预测
[0045]
使用get-orf工具对pre-mir172a上游1500bp的序列进行开放阅读框的预测,得到该范围内所有可能的小肽编码序列。预测标准包括:起始密码子为atg,开放阅读框位于mir172a初级体序列的5
’
端,长度介于12-303个核苷酸,符合三联密码子规则。
[0046]
3.番茄dna的提取
[0047]
(1)剪取约0.1g的番茄叶片迅速置于研钵中,加入液氮后充分研磨至粉末为止。
[0048]
(2)将上述样品加入到700μl预热温度为65℃的gp1缓冲液中,迅速颠倒混匀6次后,将离心管放在65℃水浴中20min,水浴过程中多次颠倒离心管以混匀样品。
[0049]
(3)将700μl氯仿加入至上述水浴后的混合液中,颠倒混匀6次后,12000rpm离心5min。
[0050]
(4)将离心后的液体上层水相吸入到一个新的离心管中,加入700μl的gp2缓冲液,充分混匀6次。
[0051]
(5)将上述混匀的液体移至吸附柱cb3中,12000rpm离心1min后,弃废液。
[0052]
(6)将500μl的gd缓冲液加入上述吸附柱cb3中,12000rpm离心1min,弃废液。
[0053]
(7)将600μl的漂洗液pw加入吸附柱cb3中,12000rpm离心1min,弃废液。
[0054]
(8)重复步骤(7),直到将吸附柱上包括乙醇等的杂质都通过离心收集到离心管中。
[0055]
(9)将吸附柱放回收集管中,12000rpm离心2min,弃掉废液,室温放置,直至晾干残留在吸附柱中的pw。
[0056]
(10)将吸附柱重置于一个新的离心管中,并向吸附柱膜中央滴加50μl预热温度为50℃的ddh2o,室温放置2-5min,12000rpm离心2min,之后将管底液体重新移至到吸附柱cb3中,12000rpm离心2min,管底部收集到的液体即番茄基因组dna。
[0057]
4.番茄pre-mir172a上游序列的pcr扩增
[0058]
对mir172a前体序列即seq id no.2设计引物,以番茄早粉2号的dna为模板,应用特异性引物,进行pcr扩增。
[0059]
所用特异性引物如下:
[0060]
172a-f:ccaagcttggtactagtgcaaatatctacattca
[0061]
172a-r:cgggatcccgtctcgtgagtttcaaatagc
[0062]
反应条件如下:
[0063][0064]
4.pcr扩增产物的回收纯化
[0065]
1%琼脂糖凝胶电泳检测上述pcr产物后,用切胶回收试剂盒(购自takara)回收符合目标片段大小的pcr产物。
[0066]
5.目标片段与克隆载体连接
[0067]
将上述回收得到的目标片段与克隆载体pmd-19t(购自takara)连接,反应体系如下:
[0068][0069]
16℃连接8h,即得到连接产物。
[0070]
6.连接产物转化大肠杆菌
[0071]
(1)将10μl的连接产物加入至200μl的大肠杆菌感受态细胞中,吹打混匀后,冰水
浴30min;
[0072]
(2)将上述冰水浴后的混合液立即转移至42℃水浴锅中,90s后再次冰水浴2min;
[0073]
(3)向上述混合液中加入1ml新鲜的lb培养基,于37℃恒温摇床中,180rpm振荡培养1.5h;
[0074]
(4)将上述菌液于4000r/min离心10min,吸去1ml上清,留下200μl菌液,将其充分吹打悬浮后,均匀涂布于lb平板上(含100mg/l氨苄青霉素、24mg/l的iptg以及20mg/l的x-gal),于37℃恒温培养箱中培养过夜;
[0075]
(5)挑取白色单菌落,接至lb液体培养基(含100mg/l氨苄青霉素)中,于37℃恒温摇床中180rpm振荡培养过夜。
[0076]
7.质粒的提取
[0077]
依据质粒小提试剂盒(购自tiangen)的说明,提取上述菌液中所含有的目的质粒。取5μl的质粒样品进行1%琼脂糖凝胶电泳检测。
[0078]
8.测序
[0079]
将得到的质粒送至测序,与基因组序列进行比对,判断是否克隆得到目的序列,经测序可知克隆得到的目的片段序列是否与基因组序列相同。
[0080]
9.番茄总rna的提取
[0081]
(1)将样品放入研钵中,加入液氮充分研磨至粉末。
[0082]
(2)取适量粉末,置于1.5ml的rnase/dnase free离心管中,同时迅速加入1ml预冷温度为4℃的trizol,摇匀,室温静置5min。
[0083]
(3)向离心管中加入200μl氯仿,摇匀,室温静置5min、4℃、12000r/min离心15min。
[0084]
(4)将其上清液转移至新离心管中,并加入等体积的异丙醇,轻轻颠倒混匀,-20℃静置20min后,在4℃下、12000r/min离心10min。
[0085]
(5)弃去上清,加入1ml预冷温度为4℃的75%乙醇,清洗沉淀,4℃、12000r/min离心5min。
[0086]
(6)小心弃去上清,在室温下开盖放置,待乙醇完全挥发后,加入20μl的rnase free dh
2
o溶解沉淀。
[0087]
(7)取5μl rna,1%琼脂糖凝胶电泳检测。
[0088]
10.番茄cdna的合成
[0089]
以总rna作为模板进行反转录,操作应用reverse transcriptase m-mlv(rnase h-)(购自takara)参照说明书完成。
[0090]
11.番茄pre-mir172a上游序列的分段pcr
[0091]
以番茄cdna及dna为模板,应用特异性引物,进行pcr扩增。
[0092]
所用特异性引物如下:
[0093]
172a-1-f:ccaagcttggcttccttcgtttggtattgt
[0094]
172a-1-r:cgggatcccggtgagtttcaaatagccagc
[0095]
172a-2-f:ccaagcttggcaatagatgtcgtaatccgtg
[0096]
172a-2-r:cgggatcccgctcgtgagtttcaaatagcc
[0097]
172a-3-f:ccaagcttggtactagtgcaaatatctacattca
[0098]
172a-3-r:cgggatcccgtctcgtgagtttcaaatagc
[0099]
172a-4-f:aaaggaatcagcagtcttca
[0100]
172a-4-r:gctggctatttgaaactcac
[0101]
172a-5-f:cttcaattaattaattatagacta
[0102]
172a-5-r:gctggctatttgaaactcac
[0103]
反应条件如下:
[0104][0105]
12.番茄mipep172a编码序列的筛选获得
[0106]
步骤11中的分段pcr扩增结果表明mir172的初级体的5
’
端起始位点位于其前体上游的1000-1500bp范围内,结合步骤2中开放阅读框的预测结果,确定mipep172a的编码序列。
[0107]
实施例二:番茄mir172a初级体所编码小肽的原核表达
[0108]
1.将mipep172a的候选编码序列连接到pet32a载体上,构建原核表达载体。
[0109]
2.用重组表达质粒pet32a-mipep172a转化得到含有表达质粒pet32a-mipep172a的大肠杆菌感受态细胞dh5α,通过dh5α对目的质粒进行大量扩增。
[0110]
3.提取被转化的阳性感受态细胞dh5α的质粒转化大肠杆菌bl21(de3)。
[0111]
4.经转化的大肠杆菌bl21菌落涂布在含有50mg/l卡那霉素的lb固体培养基上,挑取单菌落进行菌液pcr验证;将验证正确的大肠杆菌bl21菌落接种于含有卡那霉素的lb液体培养基中37℃培养8-12h,然后吸取500μl菌液转接入卡纳霉素浓度为50mg/l、体积为50ml的lb液体培养基中37℃培养至od600=0.6,再加入异丙基-β-d-硫代半乳糖苷(iptg)至培养液中异丙基-β-d-硫代半乳糖苷终浓度为0.5mmol/l,然后置于33℃环境中诱导6h,之后取菌液100℃煮沸10min,再在12000转/min条件下离心10min,取离心上清液,即实现番茄mir172a初级体所编码小肽的核酸的原核表达。
[0112]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips