
 商标分类
商标分类  商标转让
商标转让 
内质网靶向信号的制作方法
 2021-02-01 22:02:26|
2021-02-01 22:02:26| 417|
417| 起点商标网
起点商标网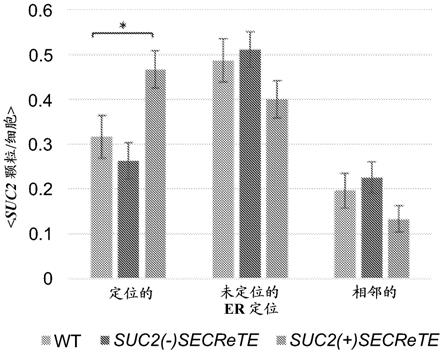
内质网靶向信号
[0001]
相关申请本申请要求2018年1月31日提交的以色列专利申请第257269号的优先权的权益,其内容通过参考以其全部结合至本文中。
[0002]
发明领域和背景在其一些实施方案中,本发明涉及增强重组蛋白,并且更具体地讲(但非排他地)分泌型重组蛋白的表达的方法。
[0003]
mrna靶向和定位翻译为提供蛋白合成的时空控制的重要机制。将mrna递送至特定的亚细胞区室在各种生物体和细胞类型的极性建立中起主要作用,并且已证明对于细胞的适当功能至关重要。有趣的是,mrna的定位通常受嵌入在mrna序列内的顺式作用元件(zipcode)的控制(martin和ephrussi, 2009; buxbaum等人, 2014)。rna结合蛋白(rbp)识别这种序列,并与“分子马达”共同起作用,以将mrna引导至其目的地。
[0004]
内质网(er)为分泌型和膜蛋白(smp;分泌蛋白质组)的合成位点。根据教条,编码smp的mrna (msmp)通过经信号识别颗粒(srp)途径进行的不同翻译依赖性机制递送至er。根据该模型,蛋白翻译在细胞质中开始,并且当smp转录物进行翻译时,存在于其多肽氨基末端的信号肽会从翻译核糖体的出口通道中出现,并被srp识别。然后将srp募集到er膜上的其受体,并发生核糖体-mrna-新生蛋白链复合体从细胞质到er的易位。在那里,翻译核糖体与易位子相互作用以使得共翻译蛋白易位和mrna锚定。因此,srp模型将msmp描述为在er易位过程中没有积极作用的组件。
[0005]
然而,多种证据表明,还有另外的途径可将mrna递送至er。首先,srp途径的丧失不会导致酵母和哺乳动物细胞的致命性,也不会对膜蛋白合成以及细胞质和er之间的整体mrna分布具有显著影响。其次,对胞质溶胶多核糖体和er结合的多核糖体之间编码可溶性和膜蛋白的mrna分布的全基因组分析表明,两个部分中mrna的组成存在显著重叠,并且表明在er上广泛展现胞质溶胶蛋白编码mrna。这意味着缺少编码信号序列的mrna可定位于er。与这些发现一致,信号序列的去除和翻译的抑制不破坏msmp定位于er (pyhtila等人, 2008; chen等人, 2011; kraut-cohen等人, 2013)。第三,已知分泌蛋白质组蛋白的子集以srp非依赖性途径定位于er。这些蛋白被认为在胞质溶胶中翻译之后易位到er中。在一项利用特异性摧毁er结合的核糖体的技术的研究中(jan等人, 2014),发现er膜上编码srp依赖性蛋白的mrna的富集与编码srp非依赖性蛋白的mrna相比较没有显著差异。另外,在信号序列出现之前,核糖体的子集设法到达er。对于这些观察结果的可能解释可能是,mrna以srp非依赖性机制在核糖体之前到达er。如果直到信号肽出现才开始mrna靶向er,则膜结合的核糖体不应翻译信号肽上游的转录物部分。然而,情况并非如此,因为发现翻译膜结合的核糖体在整个转录物中均匀分布(chartron等人, 2016)。这表明mrna在翻译起始之前定位于er。
[0006]
尽管难以鉴定出在mrna内将其引导至er的清晰的顺式元件,但已经鉴定出msmp的特定序列特征。例如,对编码信号序列的区域进行序列分析揭示,腺嘌呤的低使用而无法在该序列内产生a延伸(palazzo等人, 2007)。另外,与编码胞质溶胶蛋白的mrna相比较,编码
膜蛋白的mrna具有高度的尿嘧啶富集以及嘧啶使用(wolfenden等人, 1979; prilusky和bibi, 2009; kraut-cohen和gerst, 2010; polyansky等人, 2013)。这些发现增加er定位基序以更弥散的普遍的方式存在于mrna分子的序列组成中的可能性。
[0007]
发明概述本发明的一个方面提供一种包含转录单位的分离的多核苷酸,其中所述转录单位包括:(i) 编码目标分泌蛋白的核酸序列;(ii) 如seq id no: 2所示的内质网(er)靶向序列,所述er靶向序列与所述目标分泌蛋白异源;(iii) 启动子;和(iv) 转录终止位点,其中编码目标蛋白的核酸序列和er靶向序列位于启动子和转录终止位点之间;其中当er靶向序列包含在编码目标蛋白的核酸序列中时,该核酸序列已被密码子优化以包含er靶向序列。
[0008]
本发明的一个方面提供一种产生蛋白的方法,其包括根据本文所述的方法表达蛋白并分离蛋白,从而产生该蛋白。
[0009]
本发明的一个方面提供从本文所述的多核苷酸转录的rna。
[0010]
本发明的一个方面提供包含本文所述的分离的多核苷酸的细胞。
[0011]
本发明的一个方面提供一种表达构建体,其包含本文所述的多核苷酸。
[0012]
本发明的一个方面提供一种表达构建体,其包含如seq id no: 2中所示的核酸序列和克隆位点,其中选择克隆位点的位置,使得在将编码目标蛋白的序列插入到克隆位点中后,在细胞中表达后,转录编码目标蛋白并进一步包含所述核酸序列的转录产物的mrna,其中seq id no: 2不包含在编码蛋白的序列中。
[0013]
本发明的一个方面提供一种在细胞中表达蛋白的方法,方法包括将本文所述的分离的多核苷酸引入到细胞中,从而表达蛋白。
[0014]
根据一个实施方案,er靶向序列不包含编码目标分泌蛋白的核苷酸。
[0015]
根据本发明的实施方案,er靶向序列不包含编码如seq id no: 5中所示的序列的核苷酸。
[0016]
根据本发明的实施方案,er靶向序列不包含如seq id no: 6中所示的序列。
[0017]
根据本发明的实施方案,er靶向序列不包含序列tg的超过5个连续重复。
[0018]
根据本发明的实施方案,er靶向序列包含序列nny的至少15个连续重复,其中n为任何碱基和y为嘧啶。
[0019]
根据本发明的实施方案,er靶向序列不包含超过10个连续的胸腺嘧啶。
[0020]
根据本发明的实施方案,er靶向序列位于编码目标蛋白的核酸序列的3
’
。
[0021]
根据本发明的实施方案,er靶向序列核酸序列位于编码目标蛋白的核酸序列的5
’
。
[0022]
根据本发明的实施方案,转录单位进一步编码信号肽序列。
[0023]
根据本发明的实施方案,信号肽序列与目标蛋白异源。
[0024]
根据本发明的实施方案,目标蛋白为人类蛋白。
[0025]
根据本发明的实施方案,目标蛋白选自抗体、胰岛素、干扰素、生长激素、促红细胞生成素、生长激素、促卵泡激素、因子viii、低密度脂蛋白受体(ldlr)α半乳糖苷酶a和葡糖脑苷脂酶。
[0026]
根据本发明的实施方案,细胞属于选自细菌物种、真菌物种、植物物种、昆虫物种和哺乳动物物种的物种。
[0027]
根据本发明的实施方案,细菌物种的细胞包括大肠杆菌(e.coli)细胞。
[0028]
根据本发明的实施方案,哺乳动物物种的细胞包括中国仓鼠卵巢(cho)细胞。
[0029]
根据本发明的实施方案,真菌物种的细胞包括酿酒酵母(s. cerevisiae)细胞。
[0030]
根据本发明的实施方案,表达构建体进一步包含适合于在细胞中表达目标蛋白的启动子。
[0031]
根据本发明的实施方案,细胞属于选自细菌物种、真菌物种、植物物种、昆虫物种和哺乳动物物种的物种。
[0032]
根据本发明的实施方案,细菌物种的细胞包括大肠杆菌细胞。
[0033]
根据本发明的实施方案,哺乳动物物种的细胞包括中国仓鼠卵巢(cho)细胞。
[0034]
根据本发明的实施方案,真菌物种的细胞包括酿酒酵母细胞。
[0035]
除非另外定义,否则本文使用的所有技术和/或科学术语具有与本发明所属领域的普通技术人员通常理解的相同含义。尽管与本文描述的那些类似或等同的方法和材料可用于本发明实施方案的实践或测试中,但是以下描述示例性的方法和/或材料。在有冲突的情况下,以专利说明书(包括定义)为准。另外,材料、方法和实施例仅为说明性的,并且不旨在一定是限制性的。
[0036]
附图的几个视图的简述本文仅通过实例并参考附图描述本发明的一些实施方案。现具体地详细参考附图,要强调的是,所示的细节是作为实例并且出于对本发明实施方案的说明性讨论的目的。在这方面,结合附图进行的描述使得本领域技术人员显而易见的是可如何实践本发明的实施方案。
[0037]
在附图中:图1a-c. 确定nny重复数以用作secrete的阈值。(a) secrete数与转录物长度之间的相关性。通过根据所示阈值并在所有三个框中对转录物序列中存在的连续nny重复数进行计数,计算每个酵母基因的总secrete得分(得分为5904)。散点图表示secrete得分和基因长度之间的相关性。secrete得分与超过10个nny重复的阈值(secrete10)的基因长度无关。r得分代表皮尔逊相关系数。(b) secrete基序在编码分泌蛋白质组蛋白的mrna比编码非分泌蛋白质组蛋白的mrna中更丰富。根据所示阈值,对编码分泌蛋白质组(蓝色)和非分泌蛋白质组(灰色)蛋白的mrna中的secrete的存在进行评分。条形表示所示阈值下secrete阳性转录物的分数。分泌蛋白质组mrna中的secrete丰度明显更高。*p≤2.28e-13。(c) secrete10最大化区分分泌蛋白质组转录物的能力。针对每个所示阈值绘制roc曲线。分泌蛋白质组转录物用作“真阳性”集,而非分泌蛋白质组转录物用作“真阴性”集。secrete10的auc (曲线下面积)最高。
[0038]
图2a-c. msmp中的secrete丰度为跨膜结构域(tmd)非依赖性的。(a) secrete在密码子的第二位置丰富。分别计算每个密码子位置的secrete丰度。在第二密码子位置中,
msmp中的secrete丰度最显著,但在第三位置中也检测到显著差异,*p≤9.9e-10。(b) secrete在编码可溶性分泌蛋白质组蛋白的mrna中也高度丰富。分别对含有tmd的蛋白和可溶性分泌蛋白检查secrete10的存在。与有或没有tmd的非分泌蛋白质组转录物(有tmd的非分泌蛋白质组,深灰色;无tmd的非分泌蛋白质组,浅灰色)相比较,编码可溶性分泌蛋白的mrna (无tmd的分泌蛋白质组,青色)中的更高分数含有secrete。在第三密码子位置(nny),可溶性分泌蛋白的分数甚至比含有tmd的分泌蛋白质组蛋白更高并且显著,*p≤3.03e-3。(c) 去除tmd序列之后,secrete在第三位置丰富。在去除编码的tmd之后,对编码膜蛋白的mrna中的secrete10的存在进行评分。即使在去除tmd序列之后,secrete10在编码分泌蛋白质组蛋白(蓝色)比非分泌蛋白质组蛋白(灰色)的mrna中的第三位置(nny)明显更丰富。*p =0.01。
[0039]
图3a-d. 细胞壁蛋白高度富含secrete。(a) 对含有secrete10的基因进行的go注释分析。编码细胞壁蛋白以及膜蛋白的基因显示最高和最显著的富集得分。(b) 对含有secrete15的基因进行的go注释分析。编码细胞壁蛋白的基因最富含secrete。(c) 基因的不同组中的secrete10丰度。超过90%编码注释为定位于细胞壁的蛋白的mrna含有secrete。除尾锚定性(ta)蛋白之外,其他分泌蛋白质组中也注意到了高secrete丰度。线粒体mrna (mito)具有低secrete丰度。条形上方的数字代表每组中的基因数。(d) 细胞壁转录物的meme分析。使用meme揭示了在细胞壁转录物中类似于secrete的基序。x轴上的数字表示碱基数。
[0040]
图4a-e. 在人类基因组中发现secrete。(a) secrete10最大化对人类分泌蛋白质组基因进行分类的能力。针对每个所示阈值绘制roc曲线。分泌蛋白质组基因用作真阳性集和非分泌蛋白质组基因用作真阴性集。secrete10的auc (曲线下面积)最高。b. secrete在人类分泌蛋白质组蛋白的mrna中高度丰富。分别计算每个密码子位置的secrete10丰度。人类msmp中的secrete丰度在密码子的第二位置最显著,但在第三位置也检测到高度显著的差异。*p≤3.73e-68。c. secrete在编码人类可溶性分泌蛋白质组蛋白的mrna中高度丰富。分别对含有tmd的蛋白和可溶性分泌蛋白检查secrete10的存在。与有或没有tmd的非分泌蛋白质组转录物(有tmd的非分泌蛋白质组,深灰色;无tmd的非分泌蛋白质组,浅灰色)相比较,编码可溶性分泌蛋白的mrna (无tmd的分泌蛋白质组,青色)中的更高分数含有secrete。在第三位置具有secrete的可溶性分泌蛋白分数大于含有tmd的非分泌蛋白质组蛋白(nny)并且显著。条形上方的数字代表每组中的基因数。*p≤3.49e-12。(d) 基因的不同组中的secrete10丰度。除尾锚定性(ta)蛋白之外,对其他分泌蛋白质组蛋白组也观察到高secrete丰度。线粒体mrna (mito)具有低secrete丰度。条形上方的数字代表每组中的基因数。(e) 枯草芽孢杆菌(b. subtilis)中的secrete10丰度。对secrete10的丰度进行评分,并且与编码分泌蛋白质组(non-sec)蛋白的那些相比较,在对编码分泌蛋白质组蛋白(即ss&tmd、tmd和ss)的基因进行编码的mrna中观察到更高丰度。条形下方的数字代表每组中的基因数。
[0041]
图5a-f. 内源性和外源性蛋白的分泌水平受secrete强度的影响。(a) secrete增强在蔗糖上生长的能力。通过跌落测试(drop-test)检查wt、suc2
△
、suc2(+)secrete和suc2(-)secrete酵母在蔗糖上生长的能力。将细胞在含有葡萄糖的ypd培养基上生长至对数中期,之后连续稀释并铺板到含有蔗糖的合成培养基或ypd上。使细胞在照相记录之前生
长2天。suc2(-)secrete突变体与wt细胞相比表现出生长减少,而suc2(+)secrete细胞表现出生长更好。suc2δ细胞无法在含有蔗糖的培养基上生长。(b) secrete增强转化酶的分泌。将来自a的所示菌株进行转化酶分泌测定。内部和分泌型转化酶活性两者均以葡萄糖去抑制之后的单位进行测量。两者活性在suc2(-)secrete细胞中均降低,而在suc2(+)secrete细胞中升高。误差棒代表来自3次实验重复的标准偏差。*p<0.05。(c) secrete增强在calcofluor white上生长的能力。wt、hsp150δ、hsp150(+)secrete和hsp150(-)secrete细胞在cfw上生长的能力通过跌落测试进行检查。将细胞在ypd上生长至对数中期,之后连续稀释并在单独的ypd或含有cfw的ypd板上铺板并在30℃下温育。使细胞在照相记录之前生长2天。与wt细胞相比较,hsp150(-)secrete突变体呈现出超敏性,而hsp150(+)secrete细胞则较不敏感。hsp150δ细胞在含有cfw的培养基上生长不佳。(d) secrete增强hsp150分泌。将来自c的所示菌株进行hsp150分泌测定。细胞在37℃下生长至对数中期持续4小时,并使用抗hsp150抗体通过western分析进行细胞裂解物(内部)或培养基(外部)的检查。与wt相比较,hsp150(-)secrete细胞中的外部hsp150减少,而hsp150(+)secrete菌株中则增加。与wt细胞相比较,hsp150(-)secrete细胞中的内部hsp150减少,而hsp150(+)ertm细胞中也略微减少。分别在源自hsp150δ细胞的裂解物或培养基中未检测到内部和外部hsp150。使用imagej量化条带强度,并呈现在下方直方图中。图表显示所有样品的强度相对于wt强度的比率。(e) secrete增强在潮霉素b上生长的能力。wt、ccw12δ和ccw12(-)secrete细胞在hb上生长的能力通过跌落测试进行检查。使细胞在含有葡萄糖的ypd培养基上生长至对数中期,之后连续稀释并铺板到含有hb的ypd或单独的ypd上。使细胞在照相记录之前生长2天。与wt细胞相比较,ccw12(-)secrete菌株对hb应激更为敏感。ccw12δ细胞无法在含有hb的培养基上生长。(f) secrete增强外源性蛋白ssgas1-gfp的分泌。使从质粒表达ssgas1-gfp3
’
utrgas1(+)secrete、ssgas1-gfp、sskar2-gfp、gfp和ssgas1-lacz的酵母在含有2%棉子糖的合成培养基上生长至对数中期,并转移至含有3%半乳糖的培养基上保持4小时。使从不同菌株表达的蛋白从培养基中进行tca沉淀,并且沉淀物通过sds-page分离。gfp用抗gfp抗体检测,而hsp150用抗hsp150抗体检测并用作上样对照。使用imagej量化条带强度;相对于ssgas1-gfp分泌对强度进行评分。添加经突变含有secrete的gas1 3
’
utr可改善ss-gas1的分泌,并且与sskar2-gfp的分泌相当。缺少ss的gfp没有分泌,并且ssgas1-lacz用作阴性对照。
[0042]
图6a-b. secrete增强suc2 mrna定位至er。(a) 使用smfish可视化内源性表达的suc2(+)secrete和suc2(-)secrete mrna。从质粒内源性表达wt suc2、suc2(+)secrete或suc2(-)secrete和sec63-gfp的酵母在含有2%葡萄糖的sc培养基上生长至对数中期,之后将细胞转移至含有低葡萄糖的培养基(0.05%葡萄糖)以诱导suc2表达。使用与suc2互补的非重叠、tamra标记的fish探针对细胞进行smfish标记处理。b. suc2(+)secrete和suc2(-)secrete mrna定位于er的量化。对每个细胞中共定位于、未共定位于或相邻于sec63-gfp标记的er的颗粒的百分比进行评分。直方图显示每个菌株至少~60个细胞和~250个suc2颗粒的平均得分,*p =0.019。
[0043]
图7a-b. 潜在secrete结合蛋白的鉴定。(a) 在rna结合蛋白摧毁研究中含有secrete10的转录物的鉴定。显示来自结合至所示rbp的总mrna中含有secrete10的mrna的数目和分数。用于生成直方图的微阵列分析数据发表于(colomina等人, 2008; hasegawa
等人, 2008; hogan等人, 2008)中。(b) 潜在secrete结合配偶体的鉴定。将wt细胞和缺失编码所示rbp (例如whi3和khd1)的基因的wt或hsp150(+)secrete细胞在30℃下于ypd上生长至对数中期,之后连续稀释并铺板到固体ypd培养基或含有cfw的ypd上。使酵母在照相记录之前生长2天。
[0044]
图8. secrete在蛋白分泌中起积极作用。含有secrete的转录物(1)结合sbp (2)和诱导mrna靶向er (3)和/或赋予mrna稳定作用(4)。靶向er可提供空间调控和mrna稳定作用(5),从而导致蛋白产生(6)和分泌(7)的随后增加。
[0045]
图9a-d. secrete的丰度不依赖于密码子组成。进行排列分析以评估secrete对密码子使用的依赖性。为此,保持密码子组成并将序列随机改组1000次。计算每个基因的z得分,以评价secrete10随机出现的可能性(对于z得分的计算,请参见材料和方法)。z得分越高,secrete随机出现的可能性越小。(a) 分泌蛋白质组编码mrna中的secrete富集与密码子组成无关。z得分的分布图显示,编码分泌蛋白质组蛋白的mrna的值高于非分泌蛋白质组蛋白。(b) 在编码可溶性和膜型分泌蛋白质组转录物两者的mrna中的secrete富集与密码子组成无关。z得分的分布图显示,编码分泌蛋白质组蛋白的mrna (msmp;有或没有tmd)的值高于非分泌蛋白质组蛋白(即有或没有tmd)。(c) 密码子第二和第三位置的secrete富集与密码子使用无关。编码分泌蛋白质组蛋白的mrna的显著z得分(即≥1.96)的分数大于非分泌蛋白质组蛋白。(d) 密码子的第二和第三位置的secrete富集与密码子使用和tmd存在两者无关。在有或没有tmd的情况下,编码分泌蛋白质组蛋白的mrna的显著z得分(即≥1.96)的分数大于非分泌蛋白质组蛋白。
[0046]
图10a-c. suc2、hsp150和ccw12中secrete和secrete突变的图解说明。图表比较在天然和突变secrete基因中使用(下部示意图)或未使用(上部示意图) 10个连续nny重复的阈值的情况下沿着基因长度发现的nny重复数。(a) suc2。(b) hsp150。(c) ccw12。
[0047]
图11a-c. secrete中的突变不一定会影响mrna水平。通过qrt-pcr量化所示菌株中天然或突变suc2、ccw12和hsp150的mrna水平。计算相对于wt水平的倍数变化。(a) suc2 mrna水平由于secrete突变而改变。使细胞在30℃下于含有2%葡萄糖的sc培养基上生长至对数中期,之后将细胞转移至低葡萄糖培养基保持1.5小时。收获并提取rna之后,引物用于扩增编码分泌蛋白的suc2的长转录物。肌动蛋白的引物用于标准化。suc2(-)secrete细胞显示出比wt低的suc2 mrna水平,而suc2(+)secrete细胞产生的水平更高。误差棒代表3次生物学重复的标准偏差。(b) ccw12 mrna的水平不会由于secrete突变而改变。使细胞在30℃下于ypd培养基上生长至对数中期,之后收获并提取rna。用于扩增ubc6的引物用于标准化。ccw12 mrna水平并没有由于secrete改变而明显变化。(c) hsp150 mrna水平不会由于secrete突变而改变。使酵母菌株在26℃或37℃下于ypd培养基上生长至对数中期,之后收获并提取rna。ubc6用于标准化。hsp150 mrna水平并没有由于secrete改变而明显变化。
[0048]
图12a-b. 潜在secrete结合蛋白的鉴定。将wt细胞和缺失编码所示rbp [例如puf2、she2 (a)和puf1(b)]的基因的wt或hsp150(+)secrete细胞在30℃下于ypd上生长至对数中期,之后连续稀释并铺板到固体ypd培养基或含有cfw的ypd上。使酵母在照相记录之前生长2天。
[0049]
图13为可用于表达gfp的示例性序列
ꢀ-ꢀ
(seq id no: 4)。
[0050]
本发明具体实施方案的描述
在其一些实施方案中,本发明涉及增强重组蛋白,并且更具体地讲(但非排他地)分泌型重组蛋白的表达的方法。
[0051]
在详细解释本发明的至少一个实施方案之前,应当理解,本发明并不一定将其应用限于以下描述中阐述的或由实施例举例说明的细节。本发明能够具有其他实施方案,或者能够以各种方式实践或实施。
[0052]
将蛋白分选到其正确目的地对于细胞组织和正常功能至关重要。尽管蛋白定位的信息可存在于蛋白序列(例如蛋白靶向序列)内,但mrna的空间定位对于正确的蛋白细胞内靶向也可为重要的。
[0053]
本发明人现已鉴定出表征所有分泌型和膜蛋白(smp)的特征,并且发现由>10个连续nny重复组成的重复基序。该基序本文称为“secrete”,不限于编码含有跨膜结构域(tmd)的蛋白的转录物,而是可在从原核生物(例如枯草芽孢杆菌)到酵母(酿酒酵母和粟酒裂殖酵母(s. pombe))到人类的所有分泌蛋白质组转录物中以较高丰度发现(图1a-c和4a-e)。
[0054]
通过改变secrete在编码smp的以下3种mrna中的富集来探索其生理相关性:suc2、hsp150和ccw12 (图5)。尽管氨基酸序列不会由于突变而改变,但这些基因的功能却会改变。与wt细胞相比较,suc2 secrete突变体在含有蔗糖的培养基上呈现出改变的生长速率,即当基序强度降低时生长减少,而当基序强度升高时则生长更好(图5a)。该结果分别对应于转化酶合成和分泌两者的减少或增加(图5a、b)。hsp150 secrete突变体的行为表现也不同,即与wt细胞相比较,hsp150(-)secrete细胞对cfw呈现出更高的敏感性,而hsp150(+)secrete细胞具有更高的抗性(图5c)。类似地,ccw12(-)secrete细胞对hb呈现出超敏性(图5e)。
[0055]
这些发现加强secrete在调控从细胞分泌的蛋白量中起重要生物学作用的观点。使用外源性底物ss(gas1)-gfp对此进行验证,添加含有secrete基序的gas1 3
’
utr后,其分泌显著增强(图5f)。此外,加强secrete不仅增加蛋白的产生和分泌,其还增强suc2转录物定位于er (图6)。
[0056]
因此,本教导提示该基序可用于改善重组蛋白的产生。
[0057]
因此,本发明的第一方面提供一种包含转录单位的分离的多核苷酸,其中转录单位包含:(i) 编码目标分泌蛋白的核酸序列;(ii) 如seq id no: 2中所示的内质网(er)靶向序列,所述er靶向序列与所述目标分泌蛋白异源;(iii) 启动子;和(iv) 转录终止位点,其中编码目标蛋白的所述核酸序列和所述er靶向序列位于所述启动子和所述转录终止位点之间;其中当所述er靶向序列包含在编码所述目标蛋白的所述核酸序列中时,所述核酸序列已被密码子优化以包含所述er靶向序列。
[0058]
短语“分离的多核苷酸”是指以分离的dna分子(即包含脱氧核糖核苷酸)的形式提供的单链或双链核酸序列。
[0059]
术语“转录单位”是指编码单个rna分子的dna序列及其转录必需的序列。一般地,转录单位含有启动子、编码目标蛋白的序列和终止子。
[0060]
这些元件中的每一个将在下文单独描述。
[0061]
编码目标蛋白的核酸序列:目标蛋白一般地为分泌蛋白。在一个实施方案中,蛋白为人类蛋白,尽管本发明也考虑来自其他物种的蛋白。
[0062]
可通过采用主题组合物和方法产生的目标示例性蛋白包括(但不限于)某些天然和重组人类激素(例如胰岛素、生长激素、胰岛素样生长因子1、促卵泡激素和绒毛膜促性腺激素)、造血蛋白(例如促红细胞生成素、c-csf、gm-csf和il-11)、血栓形成和止血蛋白(例如组织纤溶酶原激活剂和活化蛋白c)、免疫蛋白(例如白细胞介素)、抗体和其他酶(例如脱氧核糖核酸酶i)。可通过主题组合物和方法产生的示例性疫苗包括(但不限于)针对各种流感病毒(例如甲、乙和丙型以及每种类型的各种血清型,比如甲型流感病毒的h5n2、h1n1、h3n2)、hiv、肝炎病毒(例如甲、乙、丙或丁型肝炎)、莱姆病和人类乳头瘤病毒(hpv)的疫苗。异源产生的蛋白诊断剂的实例包括(但不限于)促胰液素、甲状腺刺激激素(tsh)、hiv抗原和丙型肝炎抗原。
[0063]
其他示例性的目标蛋白可包括(但不限于)细胞因子、趋化因子、淋巴因子、配体、受体、激素、酶、抗体和抗体片段以及生长因子。受体的非限制性实例包括i型tnf受体、ii型il-1受体、il-1受体拮抗剂、il-4受体以及任何化学或遗传修饰的可溶性受体。酶的实例包括乙酰胆碱酯酶、乳糖酶、活化蛋白c、因子vii、胶原酶(例如由advance biofactures corporation以名称santyl销售);β-半乳糖苷酶(例如由genzyme以名称fabrazyme销售);阿法链道酶(例如由genentech以名称pulmozyme销售);阿替普酶(alteplase) (例如由genentech以名称activase销售);聚乙二醇化天冬酰胺酶(例如由enzon以名称oncaspar销售);天冬酰胺酶(例如由默克公司以名称elspar销售);和伊米苷酶(imiglucerase) (例如由genzyme以名称ceredase销售)。特定多肽或蛋白的实例包括(但不限于)胶原蛋白、粒细胞巨噬细胞集落刺激因子(gm-csf)、粒细胞集落刺激因子(g-csf)、巨噬细胞集落刺激因子(m-csf)、集落刺激因子(csf)、干扰素β(ifn-β)、干扰素γ(ifnγ)、干扰素γ诱导因子i (igif)、转化生长因子β (igf-β)、rantes (激活时调节、正常t细胞表达和假定分泌(regulated upon activation, normal t-cell expressed and presumably secreted))、巨噬细胞炎性蛋白(例如mip-1α和mip-1β)、利什曼原虫延伸起始因子(leishmnania elongation initiating factor) (leif)、血小板衍生生长因子(pdgf)、肿瘤坏死因子(tnf)、生长因子(例如表皮生长因子(egf)、血管内皮生长因子(vegf)、成纤维细胞生长因子(fgf)、神经生长因子(ngf))、脑源性神经营养因子(bdnf)、神经营养因子-2 (nt-2)、神经营养因子-3 (nt-3)、神经营养因子-4 (nt-4)、神经营养因子-5 (nt-5)、胶质细胞系源性神经营养因子(gdnf)、睫状神经营养因子(ciliary neurotrophic factor) (cntf)、ii型tnfα受体、促红细胞生成素(epo)、胰岛素和可溶性糖蛋白,例如gp120和gp160糖蛋白。gp120糖蛋白为人类免疫缺陷病毒(wiv)包膜蛋白,而gp160糖蛋白为gp120糖蛋白的已知前体。 其他实例包括促胰液素、奈西立肽(人类b型利钠肽(b-type natriuretic peptide) (hbnp))和gyp-1。
[0064]
其他示例性的目标蛋白可包括gpcr,包括(但不限于)a类视紫红质样受体(class a rhodopsin like receptors),比如毒蕈碱型(muse.)乙酰胆碱脊椎动物1型(muscatinic (muse.) acetylcholine vertebrate type 1)、毒蕈碱型乙酰胆碱脊椎动物2型、毒蕈碱型
乙酰胆碱脊椎动物3型、毒蕈碱型乙酰胆碱脊椎动物4型;肾上腺素受体(α肾上腺素受体1型、α肾上腺素受体2型、β肾上腺素受体1型、β肾上腺素受体2型、β肾上腺素受体3型)、多巴胺脊椎动物1型、多巴胺脊椎动物2型、多巴胺脊椎动物3型、多巴胺脊椎动物4型、组胺1型、组胺2型、组胺3型、组胺4型、5-羟色胺1型、5-羟色胺2型、5-羟色胺3型、5-羟色胺4型、5-羟色胺5型、5-羟色胺6型、5-羟色胺7型、5-羟色胺8型、其他5-羟色胺类型、痕量胺(trace amine)、血管紧张素1型、血管紧张素2型、蛙皮素、缓激肽(bradykffin)、c5a过敏毒素(c5a anaphylatoxin)、finet-leu-phe、apj样物质、白细胞介素-8a型、白细胞介素-8b型、白细胞介素-8其他型、c-c趋化因子1型至11型和其他类型、c
--
x
--
c趋化因子(2至6型和其他类型)、c-x3-c趋化因子、胆囊收缩素cck、a型cck、b型cck、其他cck、内皮素、黑皮质素(黑素细胞刺激素、促肾上腺皮质激素、黑皮质素激素)、达菲抗原(duffy antigen)、催乳素释放肽(prolactin-releasing peptide) (gpr10)、神经肽y (1至7型)、神经肽y、其他神经肽y、神经降压素(neurotensin)、阿片类物质(d、k、m、x型)、生长抑素(somatostatin) (1至5型)、速激肽(tachykinin) (物质p (nk1)、物质k (nk2)、神经介素k (neuromedin k) (nk3)、速激肽样 1 (tachykinin like 1)、速激肽样2 (tachykinin like 2)、血管加压素(vasopressin)/加压催产素(vasotocin) (1至2型)、加压催产素(vasotocin)、催产素(oxytocin)/中催产素(mesotocin)、芋螺升压素(conopressin)、甘丙肽样(galanin like)、蛋白酶激活样、食欲素(orexin)和神经肽ff (neuropeptides ff)、qrfp、趋化因子受体样(chemokine receptor-like)、神经介素u样(neuromedin u like) (神经介素u (neuromedin u),prxamide)、激素蛋白(促卵泡激素、绒毛膜促性腺激素(lutropin-choriogonadotropic hormone)、促甲状腺激素、i型促性腺激素(gonadotropin type i)、ii型促性腺激素(gonadotropin type ii))、(rhod)视蛋白、视紫红质脊椎动物(1-5型)、视紫红质脊椎动物5型、视紫红质节肢动物、视紫红质节肢动物1型、视紫红质节肢动物2型、视紫红质节肢动物3型、视紫红质软体动物、视紫红质、嗅觉(嗅觉11家族1至13)、前列腺素(前列腺素e2亚型ep 1、前列腺素e2/d2亚型ep2、前列腺素e2亚型ep3、前列腺素e2亚型ep4、前列腺素f2α、前列环素、血栓烷素)、腺苷1至3型、嘌呤受体、嘌呤受体p2ry1-4,6,11 gpr91、嘌呤受体p2ry5,8,9,10 gpr35,92,174、嘌呤受体p2ry12-14 gpr87 (jdp-葡萄糖)、大麻素、血小板活化因子、促性腺激素释放激素、i型促性腺激素释放激素、ii型促性腺激素释放激素、脂动激素样(adipokinetic hormone like)、黑化诱导神经肽(corazonin)、促甲状腺激素释放激素和促分泌素(thyrotropin-releasing hormone &secretagogue)、促甲状腺激素释放激素(thyrotropin-releasing hormone)、生长激素促分泌素(growth hormone secretagogue)、生长激素促分泌素样(growth hormone secretagogue like)、蜕皮触发激素(ecdysis-triggering hormone) (ethr)、褪黑激素、溶血鞘脂(lysosphingolipid)和lpa (edg)、鞘氨醇1-磷酸edg-1 (sphingosine 1-phosphate edg-1)、溶血磷脂酸edg-2 (lysophosphatidic acid edg-2)、鞘氨醇1-磷酸edg-3 (sphingosine 1-phosphate edg-3)、溶血磷脂酸edg4(lysophosphatidic acid edg4)、鞘氨醇1-磷酸edg-5 (sphingosine 1-phosphate edg-5)、鞘氨醇1-磷酸edg-6 (sphingosine 1-phosphate edg-6)、溶血磷脂酸edg-7(lysophosphatidic acid edg-7)、鞘氨醇1-磷酸edg-8 (sphingosine 1-phosphate edg-8)、其他edg白三烯b4受体(edg other leukotriene b4 receptor)、白三烯b4受体blt1、白三烯b4受体blt2、a类孤儿(class a orphan)/其他、推定的神经递质
(putative neurotransmitters)、sreb、mas原癌基因和mas相关(mas proto-oncogene & mas-related) (mrg)、gpr45样、半胱氨酰白三烯(cysteinyl leukotriene)、g蛋白偶联胆汁酸受体(g-protein coupled bile acid receptor)、游离脂肪酸受体(gp40、gp41、gp43)、b类促胰液素样(class b secretin like)、降钙素、促肾上腺皮质激素释放因子(corticotropin releasing factor)、抑胃肽(gastric inhibitory peptide)、胰高血糖素、生长激素释放激素、甲状旁腺激素(parathyroid hormone)、pacap、促胰液素、血管活性肠多肽(vasoactive intestinal polypeptide)、蛛毒素受体(latrophilin)、蛛毒素受体1型(latrophilin type 1)、蛛毒素受体2型(latrophilin type 2)、蛛毒素受体3型(latrophilin type 3)、etl受体、脑特异性血管生成抑制因子(bai)、methuselah样蛋白(mth)、钙黏着蛋白(cadherin)egf lag (celsr)、非常大的g蛋白偶联受体、c类代谢型谷氨酸(class c metabotropic glutamate)/信息素(pheromone)、代谢型谷氨酸i至iii组(metabotropic glutamate group i through iii)、钙感知样(calcium-sensing like)、细胞外钙感知(extracellular calcium-sensing)、信息素(pheromone)、其他钙感知样(calcium-sensing like other)、推定的信息素受体(putative pheromone receptor)、gaba-b、gaba-b亚型1、gaba-b亚型2、gaba-b样(gaba-b like)、孤儿gprc5 (orphan gprc5)、孤儿gpcr6 (orphan gpcr6)、无七的新娘蛋白(bride of sevenless proteins) (boss)、味觉受体(tir)、d类真菌信息素(class d fungal pheromone)、真菌信息素a因子样(fungal pheromone a-factor like) (ste2、ste3)、真菌信息素b样(fungal pheromone b like) (bar、bbr、rcb、pra)、e类camp受体(class e camp receptor)、眼白化病蛋白(ocular albinism protein)、卷曲/平滑家族((frizzled/smoothened family)、卷曲a组(frizzled group a) (fz 1&2&4&5&7-9)、卷曲b组(frizzled group b) (fz 3&6)、卷曲c组(fizzled group c) (其他)、犁鼻受体(vomeronasal receptor)、线虫化学感受器(nematode chemoreceptor)、昆虫气味受体(insect odorant receptor)和z类古细菌/细菌/真菌视蛋白。
[0065]
目标多肽也可为生物活性肽。实例包括:botox、myobloc、肉毒毒素制剂(neurobloc)、丽舒妥(dysport) (或其他血清型肉毒杆菌神经毒素)、阿糖苷酶α (alglucosidase alfa)、达托霉素(daptomycin)、yh-16、绒毛膜促性腺激素α、非格司亭(filgrastim)、西曲瑞克(cetrorelix)、白细胞介素-2、阿地白介素(aldesleukin)、替西白介素(teceleulin)、地尼白介素-毒素连接物(denileukin diftitox)、干扰素α-n3 (注射剂)、干扰素α-n1、dl-8234、干扰素、suntory (γ-1a)、干扰素γ、胸腺素α1 (thymosin alpha 1)、他索纳明(tasonermin)、digifab、viperatab、echitab、crofab、奈西立肽(nesiritide)、阿巴西普(abatacept)、阿来法塞(alefacept)、利比(rebif)、依托特明α (eptoterminalfa)、特立帕肽(teriparatide) (骨质疏松症)、可注射降钙素(骨病)、降钙素(鼻,骨质疏松症)、依那西普(etanercept)、谷他血红蛋白250 (hemoglobin glutamer 250) (牛)、屈曲可金α (drotrecogin alfa)、胶原酶、卡培立肽(carperitide)、重组人表皮生长因子(局部用凝胶剂,伤口愈合)、dwp401、达贝泊汀α (darbepoetin alfa)、依泊汀ω(epoetin omega)、依泊汀β (epoetin beta)、依泊汀α (epoetin alfa)、地西卢定(desirudin)、来匹卢定(lepirudin)、比伐卢定(bivalirudin)、诺那凝血素α (nonacog alpha)、凝血因子
ⅸ
粉针剂(mononine)、依他凝血素α (eptacog alfa) (活化的)、重组因
子viii + vwf、浓缩的重组抗血友病因子(recombinate)、重组因子viii、因子viii (重组)、alphnmate、辛凝血素α (octocogalfa)、因子viii、帕利夫明(palifermin)、印地激酶(indikinase)、替奈普酶(tenecteplase)、阿替普酶(alteplase)、帕米普酶(pamiteplase)、瑞替普酶(reteplase)、那替普酶(nateplase)、孟替普酶(monteplase)、促滤泡素α (follitropin alfa)、rfsh、hpfsh、米卡芬净(micafungin)、培非格司亭(pegfilgrastim)、来格司亭(lenograstim)、那托司亭(nartograstim)、舍莫瑞林(sermorelin)、胰高血糖素、艾塞那肽(exenatide)、普兰林肽(pramlintide)、伊米苷酶(imiglucerase)、加硫酶(galsulfase)、留可曲平(leucotropin)、莫拉司亭(molgramostirn)、醋酸曲普瑞林(triptorelin acetate)、组氨瑞林(histrelin) (皮下植入物,hydron)、地洛瑞林(deslorelin)、组氨瑞林(histrelin)、那法瑞林(nafarelin)、亮丙瑞林缓释贮库(leuprolide sustained release depot) (atrigel)、亮丙瑞林植入物(leuprolide implant) (duros)、戈舍瑞林(goserelin)、促生长激素(somatropin)、尤得盼(eutropin)、kp-102程序(kp-102 program)、促生长激素(somatropin)、促生长激素(somatropin)、美卡舍明(mecasermin) (生长不足)、恩夫韦替(enlfavirtide)、org-33408、甘精胰岛素(insulin glargine)、赖谷胰岛素(insulin glulisine)、胰岛素(吸入)、赖脯胰岛素(insulin lispro)、地特胰岛素(insulin deternir)、胰岛素(颊,rapidmist)、美卡舍明-林菲培(mecasermin rinfabate)、阿那白滞素(anakinra)、西莫白介素(celmoleukin)、99mtc-阿西肽注射液(99 mtc-apcitide injection)、麦罗匹德(myelopid)、倍泰龙(betaseron)、醋酸格拉替雷(glatiramer acetate)、gepon、沙格司亭(sargramostim)、奥普瑞白介素(oprelvekin)、人类白细胞衍生的α干扰素、倍尔来福(bilive)、胰岛素(重组)、重组人类胰岛素、门冬胰岛素(insulin aspart)、美卡舍明(mecasenin)、罗扰素(roferon)-a、干扰素-α2、阿尔法弗隆(alfaferone)、复合α干扰素(interferon alfacon-1)、干扰素α、阿温耐克斯重组人类黄体化激素(avonex
’
recombinant human luteinizing hormone)、阿法链道酶(dornase alfa)、曲弗明(trafermin)、齐考诺肽(ziconotide)、他替瑞林(taltirelin)、地博特明α(diboterminalfa)、阿托西班(atosiban)、贝卡普勒明(becaplermin)、依替巴肽(eptifibatide)、zemaira、ctc-111、shanvac-b、hpv疫苗(四价)、奥曲肽(octreotide)、兰瑞肽(lanreotide)、安瑟斯替(ancestirn)、β-半乳糖苷酶(agalsidase beta)、α-半乳糖苷酶(agalsidase alfa)、拉罗尼酶(laronidase)、蓝铜胜肽(prezatide copper acetate) (局部凝胶剂)、拉布立酶(rasburicase)、兰尼单抗(ranibizumab)、actimmune、peg-intron、曲可明(tricomin)、重组屋尘螨过敏脱敏注射剂、重组人类甲状旁腺激素(pth)1-84 (sc,骨质疏松症)、依泊汀δ (epoetin delta)、转基因抗凝血酶iii (transgenic antithrombin iii)、格兰蒂曲平(granditropin)、vitrase、重组胰岛素、干扰素-α(口服锭剂)、gem-21s、伐普肽(vapreotide)、艾度硫酸酯酶(idursulfase)、奥马曲拉(omnapatrilat)、重组血清白蛋白、赛妥珠单抗(certolizumab pegol)、谷卡匹酶(glucarpidase)、人类重组c1酯酶抑制剂(血管性水肿)、拉诺替普酶(lanoteplase)、重组人类生长激素、恩夫韦肽(enfuvirtide) (无针注射剂,生物喷射器2000 (biojector 2000))、vgv-1、干扰素(α)、芦西纳坦(lucinactant)、阿肽地尔(aviptadil) (吸入,肺部疾病)、艾替班特(icatibant)、艾卡拉肽(ecallantide)、奥米加南(omiganan)、奥罗格雷
(aurograb)、醋酸培西加南(pexigananacetate)、adi-peg-20、ldi-200、地加瑞克(degarelix)、贝辛白介素(cintredelinbesudotox)、favld、mdx-1379、isatx-247、利拉鲁肽(liraglutide)、特立帕肽(teriparatide) (骨质疏松症)、替法可近(tifacogin)、aa4500、t4n5脂质体洗剂、卡妥索单抗(catumaxomab)、dwp413、art-123、克里萨林(chrysalin)、去氨普酶(desmoteplase)、安地普酶(amediplase)、绒促卵泡素α (corifollitropinalpha)、th-9507、替度鲁肽(teduglutide)、diamyd、dwp-412、生长激素(缓释注射剂)、重组g-csf、胰岛素(吸入,air)、胰岛素(吸入,technosphere)、胰岛素(吸入,aerx)、rgn-303、diapep277、干扰素β(丙型肝炎病毒感染) (hcv))、扰素α-n3(口服)、贝拉西普(belatacept)、透皮胰岛素贴剂、amg-531、mbp-8298、西雷西普(xerecept)、奥培巴坎(opebacan)、aidsvax、gv-1001、lymphoscan、豹蛙酶(ranpirnase)、利普散(lipoxysan)、卢舒普肽(lusupultide)、mp52 (β-磷酸三钙载体,骨再生)、黑色素瘤疫苗、sipuleucel-t、ctp-37、印瑟吉(insegia)、维特斯朋(vitespen)、人类凝血酶(冷冻,手术出血)、凝血酶、transmid、蛇毒纤溶酶(alfimeprase)、普瑞凯希(puricase)、特利加压素(terlipressin) (静脉注射,肝肾综合征)、eur-1008m、重组fgf-i (可注射,血管疾病)、bdm-e、罗替加肽(rotigaptide)、etc-216、p-113、mbi-594an、耐久霉素(duramycin) (吸入,囊性纤维化)、scv-07、opi-45、内皮抑素(endostatin)、血管抑制素(angiostatin)、abt-510、鲍曼-比尔克抑制剂浓缩物(bowman birk inhibitor concentrate)、xmp-629、99mtc-hynic-膜联蛋白v (99 mtc-hynic-annexin v)、卡哈拉德f (kahalalide f)、ctce-9908、替维瑞克(teverelix) (延长释放)、奥扎里克(ozarelix)、罗米德普(rornidepsin)、bay-504798、白细胞介素4、prx-321、佩斯坎(pepscan)、埃布他德金(iboctadekin)、rh乳铁蛋白(rhlactoferrin)、tru-015、il-21、atn-161、西仑吉肽(cilengitide)、白蛋白干扰素(albuferon)、biphasix、irx-2、ω干扰素、pck-3145、cap-232、帕西瑞肽(pasireotide)、hun901-dmi、卵巢癌免疫治疗疫苗、sb-249553、oncovax-cl、oncovax-p、blp-25、cervax-16、多表位肽黑色素瘤疫苗(mart-1,gp100,酪氨酸酶)、奈米非肽(nemifitide)、raat (吸入)、raat (皮肤病)、cgrp (吸入,哮喘)、培那西普(pegsunercept)、胸腺素β4 (thymosinbeta4)、普利德普(plitidepsin)、gtp-200、雷莫拉宁(ramoplanin)、graspa、obi-1、ac-100、鲑鱼降钙素(salmon calcitonin) (口服,艾力更(eligen))、降钙素(口服,骨质疏松症)、艾沙瑞林(examorelin)、卡普瑞林(capromorelin)、卡德法(cardeva)、维拉弗明(velafermin)、131i-tm-601、kk-220、t-10、乌拉立肽(ularitide)、地来司他(depelestat)、赫马肽(hematide)、克里萨林(chrysalin) (局部)、rnapc2、重组因子v111 (聚乙二醇化脂质体)、bfgf、聚乙二醇化重组葡萄球菌激酶变体(pegylated recombinant staphylokinase variant)、v-10153、sonolysis prolyse、neurovax、czen-002、胰岛细胞新生疗法(islet cell neogenesis therapy)、rglp-1、bim-51077、ly-548806、艾塞那肽(exenatide) (控制释放,medisorb)、ave-0010、ga-gcb、阿伏瑞林(avorelin)、acm-9604、醋酸利那洛肽(linaclotid eacetate)、ceti-1、赫莫斯盘(hemospan)、val (可注射)、速效胰岛素(可注射,viadel)、鼻内胰岛素、胰岛素(吸入)、胰岛素(口服、艾力更(eligen))、重组甲硫氨酰人瘦素(recombinant methionyl human leptin)、皮崔金拉(pitrakinra) (皮下注射,湿疹)、皮崔金拉(吸入干粉,哮喘)、白细胞介素注射剂(multikine)、rg-1068、mm-093、nbi-6024、at-001、pi-0824、org-39141、cpn10 (自身免疫性疾病/炎症)、
talactoferrin (局部)、rev-131 (眼科)、rev-131(呼吸系统疾病)、口服重组人类胰岛素(糖尿病)、rpi-78m、奥普瑞白介素(oprelvekin) (口服)、cyt-99007 ctla4-ig、dty-001、伐拉司特(valategrast)、干扰素α-n3 (局部)、irx-3、rdp-58、涛弗隆(tauferon)、胆汁盐刺激的脂肪酶、梅里斯普酶(merispase)、碱性磷酸酶、ep-2104r、美拉诺坦-ii (melanotan-ii)、布雷默浪丹(bremelanotide)、atl-104、重组人类微纤溶酶(recombinant human microplasmin)、ax-200、semax、acv-1、xen-2174、cjc-1008、强啡肽a (dynorphin a)、si-6603、lab ghrh、aer-002、bgc-728、疟疾疫苗(病毒体(virosomes),pevipro)、altu-135、细小病毒b19疫苗、流感疫苗(重组神经氨酸酶)、疟疾/hbv疫苗、炭疽疫苗、vacc-5q、vacc-4x、hiv疫苗(口服)、hpv疫苗、达特类毒素(tat toxoid)、yspsl、chs-13340、pth (1-34)脂质体乳膏(novasome)、奥斯布尔(ostabolin-c)、pth类似物(局部,牛皮癣)、mbri-93.02、mtb72f疫苗(结核病)、mva-ag85a疫苗(结核病)、fara04、ba-210、重组鼠疫fiv疫苗、ag-702、oxsodrol、rbetv1、der-p1/der-p2/der-p7过敏原靶向疫苗(尘螨过敏)、pr1肽抗原(白血病)、突变体ras疫苗、hpv-16e7脂肽疫苗、labyrinthin疫苗(腺癌)、cml疫苗、wt1-肽疫苗(癌症)、idd-5、cdx-110、明曲斯(pentrys)、诺雷林(norelin)、cytofab、p-9808、vt-111、艾罗卡肽(icrocaptide)、替柏明(telbermin) (皮肤病、糖尿病足溃疡)、芦平曲韦(rupintrivir)、雷替库罗(reticulose)、rgrf、p1a、α-半乳糖苷酶a (alpha-galactosidase a)、ace-011、altu-140、cgx-1160、血管紧张素治疗性疫苗、d-4f、etc-642、app-018、rhmbl、scv-07 (口服,结核病)、drf-7295、abt-828、erbb2特异性免疫毒素(抗癌)、dt3ssil-3、tst-10088、pro-1762、库姆波托(combotox)、胆囊收缩素-b (cholecystokinin-b)/胃泌素受体结合肽、111in-hegf、ae-37、曲妥珠单抗(trasnizumab)-dm1、拮抗剂g、il-12 (重组)、pm-02734、imp-321、rhigf-bp3、blx-883、cuv-1647 (局部)、基于l-19的放射性免疫治疗剂(癌症)、re-188-p-2045、amg-386、dc/1540/klh疫苗(癌症)、vx-001、ave-9633、ac-9301、ny-eso-1疫苗(肽)、na17.a2肽、黑色素瘤疫苗(脉冲抗原治疗剂)、前列腺癌疫苗、cbp-501、重组人类乳铁蛋白(干眼症)、fx-06、ap-214、wap-8294a (可注射)、acp-hip、sun-11031、肽yy [3-36] (肥胖症,鼻内)、fgll、阿塞西普(atacicept)、br3-fc、bn-003、ba-058、人类甲状旁腺激素1-34 (鼻,骨质疏松症)、f-18-ccr1、at-1100 (乳糜泻/糖尿病)、jpd-003、pth (7-34)脂质体乳膏(novasome)、耐久霉素(眼科,干眼症)、cab-2、ctce-0214、糖基化聚乙二醇化促红细胞生成素、epo-fc、cnto-528、amg-114、jr-013、因子xiii、氨基康定(aminocandin)、pn-951、716155、sun-e7001、th-0318、bay-73-7977、替维瑞克(teverelix) (立即释放)、ep-51216、hgh (控制释放,biosphere)、ogp-i、西夫韦肽(sifuvirtide)、tv4710、alg-889、org-41259、rhcc10、f-991、胸腺五肽(thymopentin) (肺部疾病)、r(m)crp、肝脏选择性胰岛素、速碧林(subalin)、l19-il-2融合蛋白、弹力素(elafin)、nmk-150、altu-139、en-122004、rhtpo、促血小板生成素受体激动剂(血小板减少障碍)、al-108、al-208、神经生长因子拮抗剂(疼痛)、slv-317、cgx-1007、inno-105、口服特立帕肽(teriparatide) (艾力更(eligen))、gem-os1、ac-162352、prx-302、lfn-p24融合疫苗(therapore)、ep-1043、肺炎链球菌儿科疫苗、疟疾疫苗、脑膜炎奈瑟菌b组疫苗、新生儿b组链球菌疫苗、炭疽疫苗、hcv疫苗(gpe1+gpe2+mf-59)、中耳炎治疗、hcv疫苗(核心抗原+iscomatrix)、hpth (1-34) (透皮,viaderm)、768974、syn-101、pgn-0052、阿维库明(aviscumnine)、bim-23190、结核病疫苗、多表位酪氨酸酶肽、
癌症疫苗、恩卡斯替母(enkastim)、apc-8024、gi-5005、acc-001、tts-cd3、血管靶向的tnf (实体肿瘤)、去氨加压素(desmopressin) (颊控制释放)、奥那西普(onercept)和tp-9201。
[0066]
在某些实施方案中,目标蛋白为酶或其生物活性片段。合适的酶包括(但不限于):氧化还原酶、转移酶、水解酶、裂解酶、异构酶和连接酶。在某些实施方案中,异源产生的蛋白为酶学委员会(enzyme commission) (ec) 1类的酶,例如来自ec 1.1至1.21或1.97中任何一种的酶。酶也可为来自ec 2、3、4、5或6类的酶。例如,酶可选自ec 2.1至2.9、ec 3.1至3.13、ec 4.1至4.6、ec 4.99、ec 5.1至5.11、ec 5.99或ec 6.1-6.6中的任何一种。
[0067]
在另一个实施方案中,目标蛋白为抗体。
[0068]
本文使用的术语“抗体”是指基本上完整的抗体分子。
[0069]
本文使用的短语“抗体片段”是指能够结合于抗原的表位的抗体的功能片段(比如fab、f(ab')2、fv或单结构域分子,比如vh和vl)。
[0070]
启动子本文使用的术语“启动子”是指在转录起始期间被dna依赖性rna聚合酶识别并结合(直接或间接),导致与转录的dna互补的rna分子的产生的任何核酸序列,比如dna序列。启动子通常位于要转录的蛋白编码序列之前的5'非翻译区(utr)的上游,并具有充当rna聚合酶ii和其他蛋白(比如转录因子)结合位点的区域,以启动可操作地连接的序列的转录。启动子本身可含有子元件(即启动子基序),比如调控可操作地连接的基因的转录的顺式元件或增强子结构域。启动子和连接的5' utr也称为“启动子区域”。
[0071]
本发明该方面的启动子可为组成型或诱导型的。
[0072]
适用于本发明该实施方案的组成型启动子包括在大多数环境条件和大多数细胞类型下具有功能(即能够指导转录)的序列(比如巨细胞病毒(cmv)、sv-40早期启动子、sv-40晚期启动子、金属硫蛋白启动子、鼠乳腺肿瘤病毒启动子、劳斯肉瘤病毒启动子和多角体蛋白启动子)。
[0073]
适用于本发明该实施方案的诱导型启动子包括例如四环素诱导型启动子(srour, m.a.,等人, 2003. thromb. haemost. 90: 398-405)或iptg。
[0074]
在酵母中,可使用多种组成型或诱导型启动子,如美国专利申请号5932447中所公开的。或者,可使用促进外源dna序列整合到酵母染色体中的载体。
[0075]
在其中需要在植物中表达的情况下,编码序列的表达可由多种启动子驱动。例如,可使用病毒启动子,比如camv的35s rna和19s rna启动子[brisson等人 (1984) nature 310:511-514]或tmv的外壳蛋白启动子[takamatsu等人 (1987) embo j. 6:307-311]。或者,可使用植物启动子比如rubisco的小亚基[coruzzi等人 (1984) embo j. 3:1671-1680和brogli等人, (1984) science 224:838-843]或热激启动子,例如大豆hsp17.5-e或hsp17.3-b [gurley等人 (1986) mol. cell. biol. 6:559-565]。
[0076]
转录终止位点:本文使用的术语“转录终止位点”是指通过rna聚合酶指导转录终止的dna序列。所述序列还可指导经转录的rna的转录后切割和多聚腺苷酸化。在一个特定的实施方案中,转录终止序列包含多聚腺苷酸化信号,称为多聚腺苷酸化/终止序列。在一个优选的实施方案中,终止序列源自sv40病毒。
[0077]
如seq id no: 2中所示的内质网(er)靶向序列:
本发明该方面的er靶向序列助于使附接的序列定位于er。在一个实施方案中,er靶向序列促进附接的序列摄入到er中。
[0078]
该序列的nny重复重复至少7次(如在seq id no: 1中)、8次、9次、10次、11次、12次、13次、14次、15次、16次、17次、18次、19次、20次或更多次。
[0079]
根据一个特定的实施方案,nny重复重复至少10次(如在seq id no: 2中)。
[0080]
在一个特定的实施方案中,nny重复的n为嘧啶。在另一个实施方案中,nny重复的n为嘌呤。在所有实施方案中,nny重复的y为嘧啶。
[0081]
根据一个特定的实施方案,er靶向序列不包含编码目标蛋白的核苷酸。
[0082]
根据仍然另一个实施方案,er靶向序列不包含编码如seq id no: 5 (kdel)中所示的序列的核苷酸。
[0083]
优选地,er靶向序列不包含如seq id no: 6 (agc tacacccacc acctcatcta cctctac)中所示的序列。
[0084]
此外,在一个实施方案中,er靶向序列不包含序列tg的超过5个连续的重复。
[0085]
优选地,er靶向序列不包含超过10、15、20、25、30或更多个连续的胸腺嘧啶。
[0086]
优选地,er靶向序列不包含超过10、15、20、25、30或更多个连续的胞嘧啶。
[0087]
er靶向序列与目标分泌蛋白异源(即不是内源性的)-即其不是编码目标蛋白(或调控其表达)的天然序列的一部分。
[0088]
这些元件中每一个的定位使得编码目标蛋白的核酸序列和er靶向序列位于启动子和转录终止位点之间。这样,产生mrna转录物,其编码目标蛋白并进一步包含er靶向序列。
[0089]
在一个实施方案中,本发明该方面的er靶向序列位于编码目标蛋白的序列的3
’
。在另一个实施方案中,本发明该方面的er靶向序列位于编码目标蛋白的序列的5
’
。在仍然进一步的实施方案中,er靶向序列被编码在编码目标蛋白的序列中。
[0090]
优选地,当er靶向序列包含在编码目标蛋白的核酸序列中时,将蛋白的核酸序列进行密码子优化以包含er靶向序列。因此,目标蛋白的氨基酸序列与天然氨基酸序列相同。
[0091]
短语“密码子优化”是指选择在结构基因或其片段内使用的合适的dna核苷酸,使得er靶向序列在dna序列内编码而不影响蛋白的氨基酸序列。因此,优化的基因或核酸序列是指其中天然或天然存在的基因的核苷酸序列已被修饰以便利用包含er靶向序列的密码子的基因。
[0092]
本发明该方面的转录单位可进一步包含编码信号肽序列的序列。
[0093]
本文使用的短语“信号肽”是指与多肽的氨基末端在框内连接的肽并指导编码的多肽进入细胞的分泌途径。
[0094]
信号序列一般地位于蛋白序列的n-末端。通常不存在来自成熟蛋白的信号序列。蛋白运输之后,一般地会通过信号肽酶从蛋白上切割信号序列。
[0095]
根据一个实施方案,该多肽编码具有如seq id no: 3 (atgttgtttaaatccctttcaaagttagcaaccgctgctgctttttttgctggcgtcgcaactgcggac)中所示的序列的信号肽。
[0096]
在一个实施方案中,信号肽序列对目标蛋白为内源性的。在另一个实施方案中,信号肽序列对于目标蛋白为异源的(即不是天然的,或者为外源性的、非内源性的)。
[0097]
多种原核或真核细胞可用作宿主表达系统以表达本发明的多肽。这些包括(但不
限于)细菌细胞(例如大肠杆菌)、真菌细胞(例如酿酒酵母细胞)、植物细胞(例如烟草)、昆虫细胞(鳞翅目细胞)和其他哺乳动物细胞(中国仓鼠卵巢细胞)。
[0098]
细胞可为细胞培养物的一部分、整个生物体或生物体的一部分。
[0099]
如本文使用的术语“植物”涵盖整个植物、植物的祖先和后代以及植物部分,包括种子、芽、茎、根(包括块茎)以及植物细胞、组织和器官。植物可以任何形式存在,包括悬浮培养物、胚、分生组织区域、愈伤组织、叶片、配子体、孢子体、花粉和小孢子。在本发明的方法中特别有用的植物包括属于绿色植物(viridiplantae)总科的所有植物,特别是单子叶和双子叶植物,包括饲料或草料豆科植物、观赏植物、粮食作物、树木或灌木。藻类和其他非绿色植物也可用于本发明的方法。
[0100]
考虑用于表达人类干扰素β1a的细胞包括例如中国仓鼠卵巢(cho)细胞。
[0101]
考虑用于表达人类干扰素β1b的细胞包括例如大肠杆菌细胞。
[0102]
考虑用于表达人类干扰素γ的细胞包括例如大肠杆菌细胞。
[0103]
考虑用于表达人类生长激素的细胞包括例如大肠杆菌细胞。
[0104]
考虑用于表达人类胰岛素的细胞包括例如大肠杆菌细胞。
[0105]
考虑用于表达白细胞介素ii的细胞包括例如大肠杆菌细胞。
[0106]
考虑用于表达促卵泡激素的细胞包括例如cho细胞。
[0107]
为了在细胞系统中从本发明的多核苷酸表达多肽,将多核苷酸连接到核酸表达载体中。
[0108]
本发明该实施方案的表达载体可包括使该载体适合于在原核生物、真核生物或优选地两者(例如穿梭载体)中复制和整合的另外序列。典型的克隆载体含有转录和翻译起始序列(例如启动子、增强子)以及转录和翻译终止子(例如多聚腺苷酸化信号)。
[0109]
真核启动子一般地含有两种类型的识别序列,tata框和上游启动子元件。tata框位于转录起始位点的上游25-30个碱基对,被认为参与指导rna聚合酶开始rna合成。其他上游启动子元件决定转录起始的速率。
[0110]
增强子元件可从连接的同源或异源启动子刺激转录高达1000倍。当置于转录起始位点的下游或上游时,增强子具有活性。许多源自病毒的增强子元件具有广泛的宿主范围,并在多种组织中具有活性。例如,sv40早期基因增强子适合于许多细胞类型。适合于本发明的其他增强子/启动子组合包括源自多瘤病毒、人或鼠巨细胞病毒(cmv)、来自各种逆转录病毒比如鼠白血病病毒、鼠或劳斯肉瘤病毒和hiv的长末端重复(term repeat)的那些。参见enhancers and eukaryotic expression, cold spring harbor press, cold spring harbor, n.y. 1983,其通过参考结合至本文中。
[0111]
也可将多聚腺苷酸化序列添加到表达载体中,以增加从本发明的表达载体表达的多肽的翻译效率。准确有效的多聚腺苷酸化需要两种不同的序列元件:位于多聚腺苷酸化位点下游的富含gu或u的序列以及位于上游11-30个核苷酸的6个核苷酸的高度保守序列aauaaa。适合于本发明的终止和多聚腺苷酸化信号包括源自sv40的那些。
[0112]
除了已经描述的元件之外,本发明的表达载体一般地可含有其他专门元件,旨在增加克隆的核酸的表达水平或促进携带重组dna的细胞的鉴定。例如,许多动物病毒含有在允许的细胞类型中促进病毒基因组的额外染色体复制的dna序列。只要在质粒上携带或与宿主细胞的基因组一起的基因提供适当的因子,就可附加型地复制携带有这些病毒复制子
crc press, ann arbor, mich. (1995), vega等人, gene targeting, crc press, ann arbor mich. (1995), vectors: a survey of molecular cloning vectors and their uses, butterworths, boston mass. (1988)和gilboa et at. [biotechniques 4 (6): 504-512, 1986]中进行了一般性描述,并且包括例如稳定或瞬时转染、脂质转染、电穿孔和使用重组病毒载体的感染。另外,对于正负选择方法(positive-negative selection method)请参见美国专利第5464764和5487992号。
[0121]
在允许表达大量重组多肽的有效条件下培养转化的细胞。有效的培养条件包括(但不限于)允许蛋白产生的有效培养基、生物反应器、温度、ph和氧气条件。有效培养基是指其中培养细胞以产生本发明的重组多肽的任何培养基。这种培养基一般地包括具有可同化的碳、氮和磷酸盐源以及适当的盐、矿物质、金属和其他营养物(比如维生素)的水溶液。可在常规发酵生物反应器、摇瓶、试管、微量滴定盘和培养皿中培养本发明的细胞。培养可在适合于重组细胞的温度、ph和氧气含量下进行。这种培养条件在本领域普通技术人员的专业知识范围内。
[0122]
培养预定时间后,进行重组多肽的回收。
[0123]
本文使用的短语“回收重组多肽”是指收集含有多肽的整个发酵培养基,并且不需要意指分离或纯化的另外步骤。
[0124]
因此,本发明的多肽可使用多种标准蛋白纯化技术来纯化,比如(但不限于)亲和色谱、离子交换色谱、过滤、电泳、疏水相互作用色谱、凝胶过滤色谱、反相色谱、伴刀豆球蛋白a色谱、色谱聚焦和差异增溶。
[0125]
本文使用的术语“约”是指
±
10%。
[0126]
术语“包含(comprises)”、“包含(comprising)”、“包括(includes)”、“包括(including)”、“具有(having)”及其词形变化意指“包括(但不限于)”。
[0127]
术语“由
……
组成”意指“包括并限于”。
[0128]
术语“基本上由...组成”意指组合物、方法或结构可包括另外的成分、步骤和/或部分,但前提是另外的成分、步骤和/或部分不会实质性地改变要求保护的组合物、方法或结构的基本和新颖特征。
[0129]
本文使用的单数形式“一个(a)”、“一种(an)”和“该(the)”包括复数指涉,除非上下文另外明确规定。例如,术语“化合物”或“至少一种化合物”可包括多种化合物,包括其混合物。
[0130]
在整个本申请中,本发明的各种实施方案可以范围格式呈现。应当理解,以范围格式的描述仅是为了方便和简洁起见,而不应解释为对本发明范围不灵活的限制。因此,范围的描述应被认为具有具体公开的所有可能的子范围以及该范围内的单个数值。例如,对范围比如1-6的描述应被认为具有具体公开的子范围(比如1-3、1-4、1-5、2-4、2-6、3
ꢀ-
6等)以及该范围内的单个数字(例如1、2、3、4、5和6)。无论范围的广度如何,这都适用。
[0131]
每当本文指示数值范围时,其意在包括所示范围内的任何引用数值(分数或整数)。短语“在”第一指示数字和第二指示数字“之间的范围内/的范围”和从第一指示数字“到”第二指示数字的“范围内/的范围”本文可互换使用,并且意指包括第一和第二指示数字以及其间的所有分数和整数数字。
[0132]
本文使用的术语“方法”是指用于完成给定任务的方式、手段、技术和程序,包括
(但不限于)化学、药理学、生物学、生物化学和医学领域的从业人员已知或者从已知的方式、手段、技术和程序易于开发的那些方式、手段、技术和程序。
[0133]
当提及特定的序列表时,应当理解这种指涉还包括基本上对应于其互补序列的序列,如包括由例如测序错误、克隆错误或导致碱基取代、碱基缺失或碱基添加的其他改变引起的微小序列变化,条件是这种变化的频率小于1/50个核苷酸,或者小于1/100个核苷酸,或者小于1/200个核苷酸,或者小于1/500个核苷酸,或者小于1/1000个核苷酸,或者小于1/5000个核苷酸,或者小于1/10000个核苷酸。
[0134]
应当理解,本申请中公开的任何序列识别号(seq id no)均可指dna序列或rna序列,这取决于其中提及该seq id no的上下文,即使该seq id no仅以dna序列格式或rna序列格式表达也是如此。
[0135]
应当意识到,为了清楚起见在单独的实施方案的上下文中描述的本发明的某些特征也可在单个实施方案中组合提供。相反,为了简洁起见在单个实施方案的上下文中描述的本发明的各种特征,也可单独地或以任何合适的子组合或适当地在本发明的任何其他所述实施方案中提供。在各种实施方案的上下文中描述的某些特征不应认为是那些实施方案的必要特征,除非实施方案在没有那些要素的情况下不可操作。
[0136]
如上文描述的以及如以下部分权利要求所要求保护的本发明的各种实施方案和方面在以下实施例中得到实验支持。
实施例
[0137]
现参考以下实施例,其与以上描述一起以非限制性方式说明本发明的一些实施方案。
[0138]
通常,本文所用的命名法和本发明中所用的实验室程序包括分子、生物化学、微生物学和重组dna技术。这种技术在文献中有详尽的解释。参见例如"molecular cloning: a laboratory manual" sambrook等人, (1989); "current protocols in molecular biology" 第i-iii卷 ausubel, r. m.,编辑 (1994); ausubel等人, "current protocols in molecular biology", john wiley and sons, baltimore, maryland (1989); perbal, "a practical guide to molecular cloning", john wiley & sons, new york (1988); watson等人, "recombinant dna", scientific american books, new york; birren等人 (编辑) "genome analysis: a laboratory manual series", 第1-4卷, cold spring harbor laboratory press, new york (1998); 如美国专利第4666828、4683202、4801531、5192659和5272057号中所示的方法学; "cell biology: a laboratory handbook", 第i-iii卷 cellis, j. e.,编辑 (1994); "culture of animal cells
ꢀ-ꢀ
a manual of basic technique",freshney, wiley-liss, n. y. (1994), 第三版; "current protocols in immunology" 第i-iii卷 coligan j. e.,编辑 (1994); stites等人 (编辑), "basic and clinical immunology" (第8版), appleton & lange, norwalk, ct (1994); mishell和shiigi (编辑), "selected methods in cellular immunology", w. h. freeman and co., new york (1980); 可利用的免疫测定在专利和科学文献中有广泛的描述,参见例如美国专利第3791932、3839153、3850752、3850578、3853987、3867517、3879262、3901654、3935074、3984533、3996345、4034074、4098876、
(ye等人, 2012)设计引物对,以仅产生一个扩增子(60-70 bp)。为每对引物生成标准曲线,并测量引物效率。所有反应组均一式三份进行,并且每组均包括阴性对照(h2o)。使用lightcycler
®
480设备和sybr
®ꢀ
green pcr master mix (applied biosystems
®
, waltham, massachusetts, usa)进行qrt-pcr。按照制造商的规定使用两步法qrt-pcr热循环参数。解链曲线的分析评价单个实时pcr产物的特异性,并揭示每个实时pcr产物的单个峰。使用act1或ubc6 rna进行标准化,并计算相对于wt细胞的倍数变化。
[0141]
跌落测试生长测定通过使酵母菌株在ypd培养基中生长至对数中期,并然后在新鲜培养基中进行5次连续稀释(每次10倍)来进行跌落测试测定。将细胞点样到具有不同条件的板上并温育48小时,之后进行照相记录。按照上述方案,通过将细胞点样到含有25 μg/ml hb或50 μg/ml cfw (溶解于dmso中,如在ram和klis (2006)中那样制备)的ypd板上,测试calcofluor white (cfw)或潮霉素b(hb)敏感性。
[0142]
hsp150和gfp分泌测定为了诱导hsp150分泌,使菌株在ypd中于26℃下生长过夜,在ypd培养基中稀释至0.2 o.d.
600
单位,并然后在37℃下温育且生长直至对数期。对于gfp分泌,使酵母在含有棉子糖作为碳源的合成选择性培养基中,于30℃下生长o/n至0.2 o.d.
600
,然后在yp-gal中稀释至0.2 od o.d.
600
单位,并在30℃下生长至对数中期(0.6-0.8 o.d.
600
)。接下来,从每个菌株中取1.8 ml培养物,并在室温下以1900 x g离心3分钟。对上清液进行三氯乙酸(100% w/v)蛋白沉淀,并对沉淀使用0.1 m naoh进行蛋白提取(zhang等人, 2011)。在sds-page凝胶上分离样品,电泳印迹到硝化纤维素膜上,并通过与兔抗hsp150 [1:10000稀释度;来自jussi j
ä
ntti (vtt research, helsinki)的赠品]或单克隆小鼠抗gfp (roche applied science, penzberg, germany)抗体一起温育,然后使用增强化学发光(ecl)检测系统与抗兔过氧化物酶缀合抗体(1:10000, amersham biosciences)可视化进行检测。使用蛋白标记(excelband 3-color broad range protein marker pm2700,smobio technology, inc., hsinchu, taiwan)来评价蛋白分子量。
[0143]
转化酶测定如前所述(goldstein和lampen, 1975)测量转化酶的分泌。如(novick和schekman, 1979)中所述进行用于转化酶测定的细胞制备。方案基于(troy aa, 2014)进行优化。内部和外部活性以基于540 nm处的吸收为单位表示(1 u = 1 μmol释放的葡萄糖/分钟/od单位)。
[0144]
单分子fisf使表达sec63-gfp的酵母细胞生长至对数中期,并转移至含有低葡萄糖的培养基[0.1%葡萄糖]上保持1.5 h以诱导suc2表达。加入甲醛(最终浓度为3.7%)45分钟后,将细胞固定在相同培养基中。细胞用0.1 m磷酸钾缓冲液(ph 7.4,含有1.2 m山梨醇)轻轻洗涤两次,之后将细胞在1 ml新鲜制备的原生质球缓冲液[0.1 m磷酸钾缓冲液, ph 7.4, 1.2 m山梨醇,20 mm氧钒核糖核苷复合物(ribonucleoside vanadyl complex) (sigma-aldrich, st. louis, mo), 1
×
完全蛋白酶抑制剂混合物(complete protease inhibitor cocktail),28 mm β-巯基乙醇, 120 u/ml rnasin核糖核酸酶抑制剂和消解酶(10 ku/ml)]中,于30℃下原生质球化30分钟。将原生质球在4℃下以1300
ꢀ×
g离心4分钟,并在含有
1.2 m山梨醇的0.1 m磷酸钾缓冲液(ph 7.4)中洗涤两次。然后将原生质球重悬于70%乙醇中,并在4℃下温育1小时。之后,将细胞在4℃下以1300
ꢀ×ꢀ
g离心4分钟,用wash缓冲液(0.3 m氯化钠,30 mm枸橼酸钠和10%甲酰胺)洗涤,并在30℃下于黑暗中与含有0.3 m氯化钠、30 mm枸橼酸钠、10%硫酸葡聚糖、10%甲酰胺、2 mm氧钒核糖核苷复合物以及tamra标记的suc2的stellaris探针混合物(biosearch technologies, novato, ca)的杂交混合物一起温育过夜。在探针杂交之后,将标记的原生质球以1300
ꢀ×ꢀ
g离心,吸出杂交溶液,并将原生质球在30℃下于wash缓冲液中温育30分钟。然后将细胞离心并重悬于含有0.3 m氯化钠和30 mm枸橼酸钠的溶液中。使用deltavision成像系统(applied precision, issaquah, wa, usa)使suc2 mrna与er共定位可视化。通过去卷积处理图像。
[0145]
计算分析:secrete得分计算使用perl编程语言进行secrete得分的计算。为了计算基序数,对3个不同位置(即ynn、nyn、nny,其中n为任何核苷酸和y为嘧啶)计数高于某个阈值的nny重复数。
[0146]
基因本体论根据(ast等人, 2013)定义分泌蛋白质组,该组包括所有含有tmd和/或信号序列且不是线粒体的基因。使用tmhmm工具定义含有tmd的蛋白。根据uniprot定义细胞壁和尾锚定性基因。来自(jan等人, 2014)的数据用于定义其他组基因以及定义人类go术语。使用go slim mapper工具(sgd) (worldwidewebdotyeastgenomedotorg/cgi-bin/go/goslimmapperdotpl)对ertm10-和ertm15-阳性基因进行分类。
[0147]
排列测试分析为了进行排列分析,将每个基因序列随机改组1000次,并对每个改组序列的secrete进行评分。为了评估secrete随机出现的可能性,根据下式计算每个基因的z得分:z = (观测值-平均值)/std。观测值为从基因序列测量的值(例如基因的secrete得分)。平均值为基因的所有改组序列的平均secrete得分。std为来自基因的所有改组序列的secrete得分的标准偏差。
[0148]
细胞壁基序的鉴定基序搜索通过meme套件(bailey等人, 2009)在meme-suitedotorg/tools/meme中进行。
[0149]
结果编码酵母分泌蛋白质组蛋白的mrna中的嘧啶重复基序的鉴定因为编码疏水性残基的密码子在其第二位富含嘧啶(prilusky和bibi, 2009),所以本发明人检查了酵母中编码分泌蛋白质组蛋白的mrna在编码和utr区中是否存在连续的每3个核苷酸的嘧啶重复(即ynn、nyn或nny)。首先,我们确定了多少嘧啶重复可以最好地区分分泌蛋白质组蛋白编码mrna与非分泌蛋白质组蛋白编码mrna。为此,根据定义的阈值(例如5、7、10、12和15个重复)对沿着mrna转录物的重复数进行评分。为了确定基因长度与重复的存在之间是否存在相关性,本发明人比较了这两个参数(图1a)。基于使用定义的阈值进行的序列分析,他们暂时将这些重复定义为
ꢀ“
分泌增强型顺式调控靶向元件(secretion-enhancing cis regulatory targeting elements)”(secrete),称为:secrete5、7、10、12和15。如所示(图1a),secrete5和secrete7的secrete数与基因长度之间存在直接相关性。
然而,对基因长度的依赖性在secrete10以上明显减弱(图1a)。这意味着存在≥10个连续的重复不是随机现象,并且可能重要。
[0150]
如果10以上的secrete重复(例如secrete10)在蛋白分泌中起作用,则可预计它们在编码分泌蛋白质组蛋白的mrna中更加丰富,如根据astet等人(ast等人, 2013)定义的。为了测试这种可能性,本发明人将全部酵母基因组分为两组:分泌蛋白质组和非分泌蛋白质组,并计算每组中含有secrete的转录物的分数。他们发现,编码分泌蛋白质组蛋白的转录物富含secrete基序> 7 (图1b),与编码非分泌蛋白质组蛋白的转录物相对。为了测试在分泌蛋白质组与非分泌蛋白质组转录物之间提供最显著分离的重复数,本发明人使用接收者操作特征(receiver operator characteristics) (roc)分析评估了不同阈值对msmp进行分类的能力(hanley和mcneil, 1982)。真实的编码分泌蛋白质组蛋白的转录物用作真阳性集和编码非分泌蛋白质组蛋白的转录物定义为真阴性。如所示(图1c),secrete10阈值最大程度地区分了分泌蛋白质组转录物与非分泌蛋白质组转录物。由于secrete10不显示对基因长度的依赖性,并且在分泌蛋白质组与非分泌蛋白质组转录物之间提供最显著的分离,因此本发明人将其用作在随后的分析中借以定义基序存在的阈值。
[0151]
msmp中的secrete丰度不依赖于tmd的存在编码tmd的mrna序列富含尿嘧啶(u),主要位于密码子(nyn)的第二位(wolfenden等人, 1979; prilusky和bibi, 2009)。由于大多数分泌蛋白质组蛋白均含有tmd,因此仅其存在就可能是分泌蛋白质组转录物中基序富集的原因。为了确定msmp中的secrete富集是否不仅是由于编码的tmd的存在,本发明人确定了在secrete10元件中嘧啶(y)位于三联体的哪个位置:第一(ynn);第二(nyn);或第三(nny)。他们仅使用编码序列(即从起始密码子到终止密码子)而没有使用utr分别计算每个位置的secrete10丰度。尽管不出所料,信号存在于第二位(图2a;nyn),但在密码子的第三位其也很丰富(图2a;nny)。后一个发现意味着,tmd可能不是影响msmp中secrete富集的唯一因素。相比之下,secrete10元件在第一位的表现不佳(图2a;ynn)。
[0152]
接下来,他们分别检查了编码含有tmd的蛋白和可溶性分泌蛋白的mrna中secrete10的存在。不出所料,比起编码可溶性分泌蛋白的转录物,更多的编码含有tmd的分泌蛋白质组蛋白的转录物在第二位(nyn)含有secrete10 (图2b)。然而,编码可溶性分泌蛋白的含有secrete10的转录物在第三位(nny)的分数甚至更高。这为与编码的tmd区域无关的转录物中的secrete10富集提供令人信服的证据。相应地,当从编码膜蛋白的mrna序列中人工去除tmd时,分泌蛋白质组基因不再富含第二位的secrete10 (图2c;nyn),尽管第三位的secrete10富集仍然高度丰富(图2c;nny)。
[0153]
secrete丰度不依赖于密码子组成secrete富集可能是由转录物的密码子组成引起。为了检查这种可能性,本发明人进行了排列测试分析。在这种情况下,将每个基因序列随机改组x 1000,而密码子组成保持不变。然后,他们为每个基因计算secrete10的z得分(即与平均值的标准偏差数),以评估信号随机出现的可能性。通过查看分泌蛋白质组和非分泌蛋白质组基因的z得分分布,可以得出结论,msmp中的secrete富集不是随机现象,也不依赖于密码子组成(图9a)。该结论对于编码膜蛋白和可溶性蛋白两者的msmp均为有效的(图9b)。本发明人还分别对每个密码子位置进行了分析。为此,他们分别计算了每个位置具有显著z得分(≥1.96)的基因分数。在密码
子的第二和第三位两者处,分泌蛋白质组基因中具有显著z得分的基因分数要大于非分泌蛋白质组基因中的(图9c),从而加强这样一种观点,即secrete在这些位置中明显更加富集。这一发现不依赖于tmd的存在,因为具有显著z得分的基因分数对于可溶性和含有tmd的分泌蛋白质组转录物两者均较大,而对于可溶性和含有tmd的非分泌蛋白质组转录物则不是(图9d)。
[0154]
基因本体论(go)分析为了确定在含有secrete的基因群体中过度表现的那些基因类别,进行了基因本体论(go)富集分析。当针对go富集搜索secrete10阳性基因时(使用所有酵母基因作为背景),毫不奇怪的是,发现膜蛋白具有高富集得分(富集倍数= 1.67) (图3a)。secrete最富集的基因类别为包含细胞壁蛋白的基因(富集倍数= 1.8) (图3a)。当15个nny重复用作阈值时,细胞壁蛋白类别的富集倍数变化增加到4.8倍(图3b)。为了进一步表征富含secrete的mrna,本发明人将分泌蛋白质组和非分泌蛋白质组分为亚组,并计算每个类别中含有secrete10的转录物的分数。与go分析一致,编码细胞壁蛋白的mrna中多于90%具有secrete10元件,并且细胞壁蛋白是secrete最丰富的(图3c)。他们发现,编码tmd和信号序列(ss)区域两者的蛋白的mrna中86%以及编码tmd的分泌蛋白质组mrna中84%均含有secrete10 (图3c)。其中,编码尾锚定性(ta)蛋白的mrna在分泌蛋白质组中含有最少数量的具有secrete10的转录物(图3c)。已知ta蛋白在胞质溶胶中翻译之后会通过备选途径(get)易位至er (sharp和li, 1987; stefanovic和hegde, 2007; denic, 2012),并且它们的转录物不会在er膜上富集(jan等人, 2014; chartron等人, 2016)。这可能意味着在er上进行翻译的mrna中secrete更为丰富。相比之下,非分泌蛋白质组蛋白的转录物(即线粒体和细胞核)具有最低的secrete元件丰度(图3c)。
[0155]
由于secrete在编码细胞壁蛋白的mrna中高度富集,因此本发明人希望知道是否可使用无偏倚基序搜索工具(unbiased motif search tool)来发现它。为此,他们使用meme分析了细胞壁蛋白的mrna序列以鉴定mrna基序。获得的最显著的结果与具有u或c的secrete10重复高度相似(图3d)。重要的是,他们没有检测到该mrna基序内的蛋白基序,从而消除了secrete元件依赖于蛋白序列的可能性。
[0156]
在原核生物和高等真核生物两者中均发现msmp中的secrete富集进化中的保守性或趋同性均为具有意义的强指征。为了检查在高等和低等生物体(例如人类和枯草芽孢杆菌)中是否发现在msmp中的secrete富集,本发明人分析了这些基因组。在人类中,如在酿酒酵母中一样,基于roc分析,secrete10在编码分泌蛋白质组和非分泌蛋白质组蛋白的rna之间提供最显著的分离(图4a)。在确认secrete10与基因长度不相关之后,将10个nny重复用作阈值来定义secrete基序的存在。如在酵母中一样,与非分泌蛋白质组转录物相比较,secrete在分泌蛋白质组转录物的第二和第三密码子位置富集(图4b)。同样,与带有或缺少tmd的非分泌蛋白质组转录物相比较,缺少tmd的分泌蛋白质组转录物中有较大分数含有secrete (图4c)。有趣的是,发现编码gpi锚定蛋白(等同于细胞壁蛋白)的转录物高度富含secrete。相比之下,如酵母中所见示,尾锚定性基因以及线粒体和细胞核基因具有低的secrete丰度(图4d)。与编码非分泌蛋白质组蛋白的那些基因相比较,在编码枯草芽孢杆菌的分泌蛋白质组蛋白的基因中检测到高丰度的secrete10 (图4e)。
[0157]
secrete中的突变影响内源性分泌蛋白质组蛋白的分泌
为了进一步理解secrete的意义并确证其对酵母细胞生理学的重要性,本发明人通过升高或降低所选基因中的信号来检查其相关性。基于其相对短的基因长度、其缺失后的可检测表型以及其在不同生理途径中的功能,选择了3个代表性基因。这些基因包括:suc2,其编码可溶性分泌型周质酶;hsp150,其编码可溶性培养基蛋白;和ccw12,其编码gpi锚定的细胞壁蛋白。通过分别用t或c取代存在于第三密码子位置上的任何a或g,从而沿着整个基因富含secrete的存在,来增加基因的整体secrete信号[(+)secrete]。将t转换为a或将c转换为g的反向取代降低了整体secrete信号[(-)secrete]。至关重要的是,将这些修饰设计成确保仅改变mrna序列的secrete属性,而不对编码的氨基酸序列进行任何改变。此外,mrna二级结构的稳定性变化保持在可接受的范围内,并且密码子适应指数(codon adaptation index) (cai)保持在0.8-1.0的最佳范围内(sharp和li, 1987)。使用1个nny重复或10个nny重复的最小阈值,沿着基因长度显示suc2、hsp150和ccw12中的secrete突变,如图10所示(a-c;分别为上部和下部)。
[0158]
suc2中的secrete突变改变转化酶的分泌suc2编码从两种不同的mrna (短和长,其仅在它们的5
’
末端不同)翻译而成的不同形式的转化酶。尽管较长的mrna编码含有信号序列的分泌蛋白,但从短同工型则省略了信号序列,其编码细胞质蛋白。分泌的suc2表达受到葡萄糖抑制;然而,在诱导条件(即葡萄糖耗竭)下,suc2通过分泌途径运输到细胞的周质空间。在那里,其催化蔗糖水解为葡萄糖和果糖,这种酶促活性负责酵母利用蔗糖作为碳源的能力,并可通过生化测定(即转化酶活性)在细胞的内部和外部进行测量。通过经跌落测试检查突变体在含有蔗糖的培养基上生长的能力来测试secrete突变对suc2功能的影响。有趣的是,即使在ypd板上未检测到生长变化,但与wt细胞相比较,蔗糖板上suc2(-)secrete的生长速率也降低,而suc2(+)secrete突变体却呈现出更好的生长(图5a)。这些发现表明secrete强度影响suc2的分泌。suc2分泌的这些变化可能是由于suc2转录、suc2产生的变化和/或分泌速率的改变引起的。为了区分这些可能性,对wt细胞、suc2δ和suc2 secrete突变体进行转化酶测定。转化酶测定通过计算由蔗糖产生的葡萄糖的量,使得能够定量分泌的suc2以及内部suc2。不出所料,在葡萄糖抑制条件(例如2%葡萄糖)下,分泌的和内部suc2两者的水平均非常低。当细胞在含有低葡萄糖(例如0.05%葡萄糖)的培养基上生长以促进所分泌的酶的表达时,分泌的suc2水平由于secrete的变化而发生改变。与跌落测试结果相对应,与wt细胞相比较,对suc2(-)secrete细胞检测到分泌的转化酶显著减少,而对suc2(+)secrete细胞检测到显著增加。从suc2δ细胞中未检测到suc2分泌(图5b,分泌的)。如果secrete突变影响suc2分泌的效率但不影响其合成,那么预计会在suc2(-)secrete细胞中发生suc2积累。同样地,预计会在suc2(+)secrete细胞中发生内部转化酶的减少。然而,情况并非如此,因为suc2(-)secrete细胞中suc2的内部量减少,而suc2(+)secrete细胞中suc2的内部量略微增加(图5b,内部)。这些发现表明,suc2中的secrete改变可能影响蛋白的产生。
[0159]
secrete突变改变hsp150分泌和细胞壁稳定性接下来,本发明人希望研究secrete在hsp150中的重要性。hsp150为外细胞壁的组成部分,并且尽管尚不清楚hsp150的确切功能,但其对于细胞壁稳定性和对细胞壁扰动剂(cell wall-perturbing agent) (比如calcofluor white (cfw)和刚果红(cr))的抗性而言是需要的。尽管hsp150
∆
细胞对细胞壁应激更为敏感,但hsp150的过量产生会提高细胞壁完整
性(hsu等人, 2015)。hsp150被有效地分泌到生长培养基中,并且在热激时其表达增加(russo等人, 1992, 1993)。通过测试hsp150(-)secrete和hsp150(+)secrete细胞与wt和hsp150
∆
细胞相比较对添加的cfw的敏感性,经跌落测试来检查修饰hsp150中的secrete的效果。从图5c可以看出,尽管与wt细胞相比较,hsp150(-)secrete菌株对cfw更为敏感,但是hsp150(+)secrete菌株对cfw更具有抗性。不出所料,hsp150
∆
细胞最易受到cfw的影响(图5c)。还对hsp150菌株进行了western印迹分析以测量突变蛋白的水平。由于热激后hsp150的分泌升高(russo等人, 1992, 1993),因此在蛋白提取之前使细胞在37℃下生长。分别从生长培养基和细胞两者中提取蛋白以检测外部和内部蛋白水平两者。与wt细胞相比较,分泌到培养基中的hsp150的量在hsp150(-)secrete细胞中减少,而在hsp150(+)secrete细胞中升高(图5d)。与suc2相似,与wt细胞相比较,hsp150(-)secrete细胞中hsp150的内部量也减少(图5d)。这可能意味着分泌本身并未由于secrete强度的降低而显著减弱。由于hsp150(+)secrete细胞中hsp150的内部量与wt细胞相似,因此可以得出结论,hsp150中secrete的改变也可能影响蛋白的产生。
[0160]
ccw12中的secrete突变改变细胞壁稳定性ccw12编码糖磷脂酰肌醇(gpi)锚定的细胞壁蛋白,该蛋白定位于新合成的细胞壁区域,并在出芽和shmoo形成期间保持壁的稳定性。已表明缺失ccw12会引起对细胞壁去稳定剂(如潮霉素b (hb))的超敏性(ragni等人, 2007, 2011)。由于ccw12中的secrete得分非常高,因此无法进一步增加信号。因此,本发明人仅产生ccw12(-)secrete细胞,并测试其在含有hb的板上生长的能力。如用hsp150(-)secrete所见(图5c),发现与wt细胞相比较, ccw12(-)secrete突变使细胞对细胞壁扰动敏感(图5e)。
[0161]
secrete的添加影响外源性天然蛋白的分泌secrete添加改善外源性蛋白分泌的能力不仅是其重要性的实质证据,而且还可为一种有用的低成本的工业工具,以在不改变蛋白序列的情况下改善重组蛋白的分泌。为了测试这一点,本发明人采用在5
’
末端带有gas1的编码的ss (ssgas1)的gfp转录物构建体。ssgasi使得能够将gfp蛋白分泌到培养基中,尽管与其他ss融合的gfp蛋白(比如sskar2)相比较其分泌不那没有有效(图5f)。为了潜在地改善ssgas1的分泌,本发明人添加含有secrete的gas1的改变的3
’
utr序列[即其中所有的a和g分别被t和c置换;ssgasi-3
’
utrgasi(+)secrete]。然后他们测试了添加secrete对gfp分泌到培养基中的影响。他们发现,与ssgasi-gfp相比较,将secrete添加到gasi-gfp的3
’
utr提高了gfp分泌至培养基中的分泌,并且与sskar2-gfp相似(图5f)。
[0162]
secrete突变对mrna水平的影响由于蛋白水平可能会因(-)secrete和(+)secrete突变而改变(图5b、d和f),因此,本发明人检查是否涉及基因转录或mrna稳定性的变化。定量实时(qrt) pcr用于检查suc2、hsp150和ccw12的mrna水平是否受secrete强度影响。发现suc2(-)secrete mrna水平比在suc2 wt细胞中的几乎低30%,而suc2(+)ertm水平比wt高~50% (图s3a)。mrna水平的这种变化可能是suc2(+)secrete突变体增加蛋白产生并因此在含有蔗糖的培养基上生长得更好的能力的原因(图5a,b)。
[0163]
还研究了secrete突变对hsp150 mrna水平的影响。有趣的是,发现hsp150(-)secrete的mrna水平与wt相似,而hsp150(+)secrete的mrna水平则略微降低(图11b)。因此,
recognition particle receptor. j. cell biol. 95, 470-477.goldstein, a.,和lampen, j.o. (1975). beta-d-fructofuranoside fructohydrolase from yeast. methods enzymol. 42, 504-511.haim, l.和gerst, j.e. (2009) m-tag: a pcr-based genomic integration method to visualize the localization of specific endogenous mrnas in vivo in yeast. nat. protocols 4,1274-1284.hamilton, r.s.,和davis, i. (2011). identifying and searching for conserved rna localisation signals. methods mol. biol. 714, 447-466.hanley, j.a.和mcneil, b.j. (1982) the meaning and use of the area under a receiver operating characteristic. radiology 143, 29-36.hasegawa, y., irie, k.,和gerber, a.p. (2008). distinct roles for khd1p in the localization and expression of bud-localized mrnas in yeast. rna 14, 2333-2347.hogan, d.j., riordan, d.p., gerber, a.p., herschlag, d.,和brown, p.o. (2008). diverse rna-binding proteins interact with functionally related sets of rnas, suggesting an extensive regulatory system. plos biol. 6, 2297-2313.houshmandi, s.s.,和olivas, w.m. (2005). yeast puf3 mutants reveal the complexity of puf-rna binding and identify a loop required for regulation of mrna decay. rna 11, 1655-1666.hsu, p.-h., chiang, p.-c., liu, c.-h.,和chang, y.-w. (2015). characterization of cell wall proteins in saccharomyces cerevisiae clinical isolates elucidates hsp150p in virulence. plos one 10, e0135174.irie, k., tadauchi, t., takizawa, p.a., vale, r.d., matsumoto, k.,和herskowitz, i. (2002). the khd1 protein, which has three kh rna-binding motifs, is required for proper localization of ash1 mrna in yeast. embo j. 21, 1158-1167.ito, w., li, x., irie, k., mizuno, t.,和irie, k. (2011). rna-binding protein khd1 and ccr4 deadenylase play overlapping roles in the cell wall integrity pathway in saccharomyces cerevisiaeeukaryot. cell 10, 1340-1347.jagannathan, s., reid, d.w., cox, a.h., jagannathan, s., reid, d.w., cox, a.h.,和nicchitta, c. v (2014). de novo translation initiation on membrane-bound ribosomes as a mechanism for localization of cytosolic protein mrnas to the endoplasmic reticulum. rna 20, 1489-1498.jan, c.h., williams, c.c.,和weissman, j.s. (2014). principles of er cotranslational translocation revealed by proximity-specific ribosome profiling. science 346, 1257521.jan, c.h., williams, c.c.,和weissman, j.s. (2015). response to comment on
ꢀ“
principles of er cotranslational translocation revealed by proximity-specific ribosome profiling.
”ꢀ
science (80-. ). 348.
directional synonymous codon usage bias, and its potential applications. nucleic acids res. 15, 1281-1295.stefanovic, s.,和hegde, r.s. (2007). identification of a targeting factor for posttranslational membrane protein insertion into the er. cell 128, 1147-1159.tang, h., song, m., he, y., wang, j., wang, s., shen, y., hou, j.,和bao, x. (2017). engineering vesicle trafficking improves the extracellular activity and surface display efficiency of cellulases in saccharomyces cerevisiae. biotechnol. biofuels 10, 53.troy aa, h. (2014). a simplified method for measuring secreted invertase activity in saccharomyces cerevisiae. biochem. pharmacol. open access 3.verg
é
s, e., colomina, n., gar
í
, e., gallego, c.,和aldea, m. (2007). cyclin cln3 is retained at the er and released by the j chaperone ydj1 in late g1 to trigger cell cycle entry. mol. cell 26, 649-662.walter, p.,和blobel, g. (1981). translocation of proteins across membranes iii. signal recognition protein (srp) causes signal sequence-dependent and site specific arrest of chain elongation that is released by microsomal membranes. j. cell biol. 91, 557-561.weis, b.l., schleiff, e.,和zerges, w. (2013). protein targeting to subcellular organelles via mrna localization. biochim. biophys. acta
ꢀ-ꢀ
mol. cell res. 1833, 260-273.wolfenden, r. v, cullis, p.m.,和southgate, c.c. (1979). water, protein folding, and the genetic code. science 206, 575-577.ye, j., coulouris, g., zaretskaya, i., cutcutache, i., rozen, s.,和madden, t.l. (2012). primer-blast: a tool to design target-specific primers for polymerase chain reaction. bmc bioinformatics 13, 134.zhang, t., lei, j., yang, h., xu, k., wang, r.,和zhang, z. (2011). an improved method for whole protein extraction from yeast saccharomyces cerevisiae. yeast 28, 795-798。
[0167]
尽管本发明已经结合其特定实施方案进行了描述,但是显然许多备选、修改和变化对于本领域技术人员将是显而易见的。因此,旨在包括落入所附权利要求的精神和广泛范围内的所有这种备选、修改和变化。
[0168]
本说明书中提及的所有出版物、专利和专利申请本文均通过参考以其全部结合至说明书中至好像每个单独的出版物、专利或专利申请被具体地和单独地表明通过参考结合至本文中的相同程度。另外,在本申请中对任何参考文献的引用或标识均不应解释为承认这种参考文献可用作本发明的现有技术。就使用小节标题而言,其不应解释为必然的限制。
[0169]
另外,本申请的任何优先权文件特此通过参考以其全部结合至本文中。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除
相关标签:

 热门咨询
热门咨询




tips